【深度优先-利用Spark将Kafka数据流写入HDFS】此文章归类为:[ "深度优先", "linq", "spark", "kafka", "大数据" ]。 利用Spark将Kafka数据流写入HDFS
原创 周杰伦 7个月前 阅读: 183 阅读时长: 9分钟
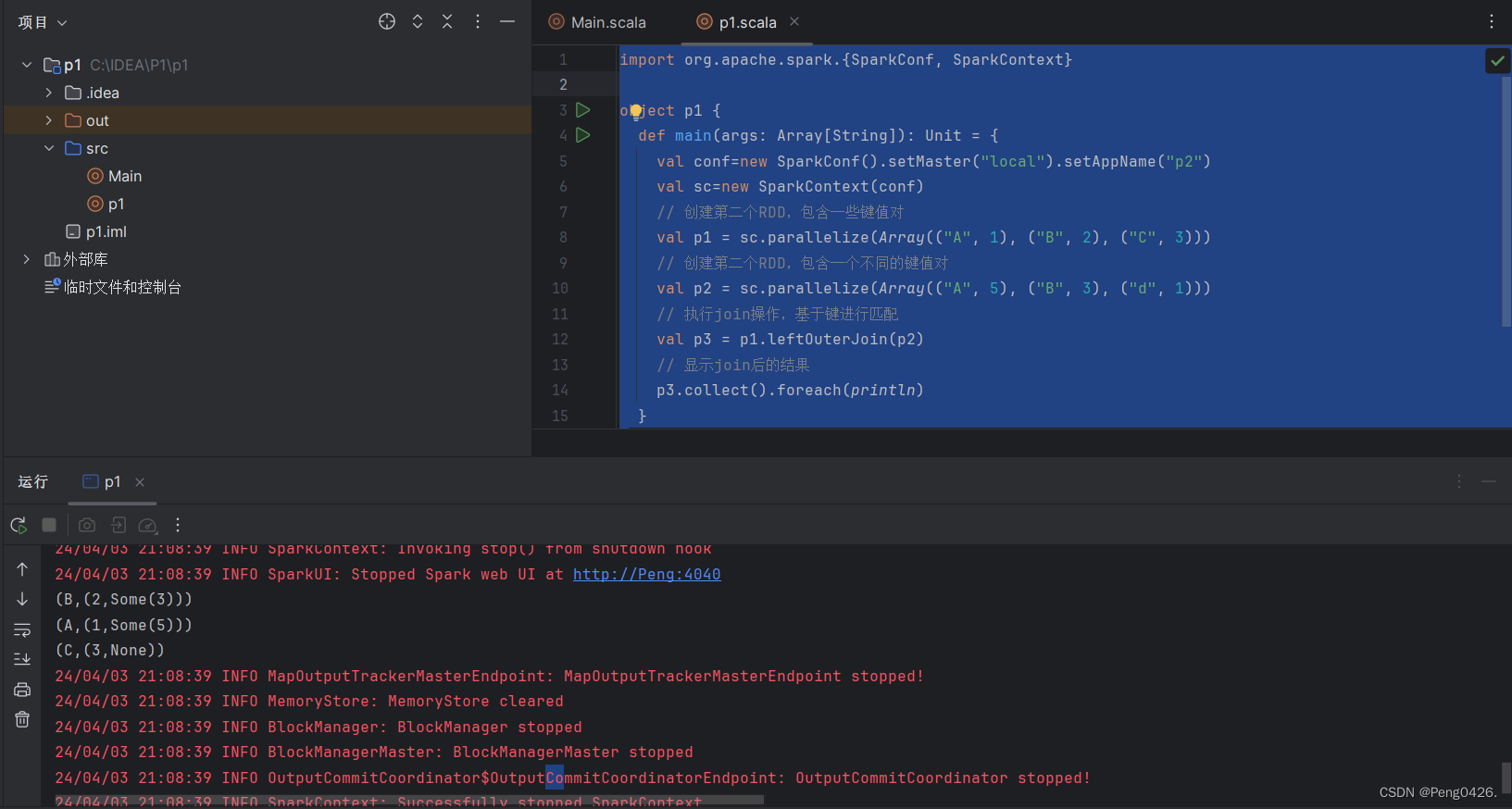
【spark-Spark-Scala语言实战(11)】此文章归类为:[ "spark", "分布式", "大数据" ]。 在之前的文章中,我们学习了如何在spark中使用RDD中的cartesian,subtract最终两种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章
原创 周杰伦 7个月前 阅读: 172 阅读时长: 9分钟
【activemq-Kafka、ActiveMQ、RabbitMQ 及 RocketMQ区别比较】此文章归类为:[ "activemq", "kafka", "rabbitmq", "分布式" ]。 消息队列中间件是分布式系统中重要的组件,主要解决应用耦合、异步消息、流量削锋等问题。它可以实现高性能、高可用、可伸缩和最终一致性架
原创 周杰伦 7个月前 阅读: 182 阅读时长: 9分钟
【scala-深入解析大数据Scala面试题及参考答案(持续更新)】此文章归类为:[ "scala", "后端", "大数据", "开发语言" ]。 Scala,作为一种多范式编程语言,因其强大的功能性和与Java的互操作性,在大数据和并发编程领域备受青睐。本文将深入探讨10个常见的Scala面试题,并提供详尽的参考答案,以期帮助读者在面试中
原创 周杰伦 7个月前 阅读: 214 阅读时长: 1分钟
【算法-大数据主要组件HDFS Iceberg Hadoop spark介绍】此文章归类为:[ "算法", "深度优先", "spark", "hadoop", "大数据" ]。 HDFS
原创 周杰伦 7个月前 阅读: 185 阅读时长: 9分钟
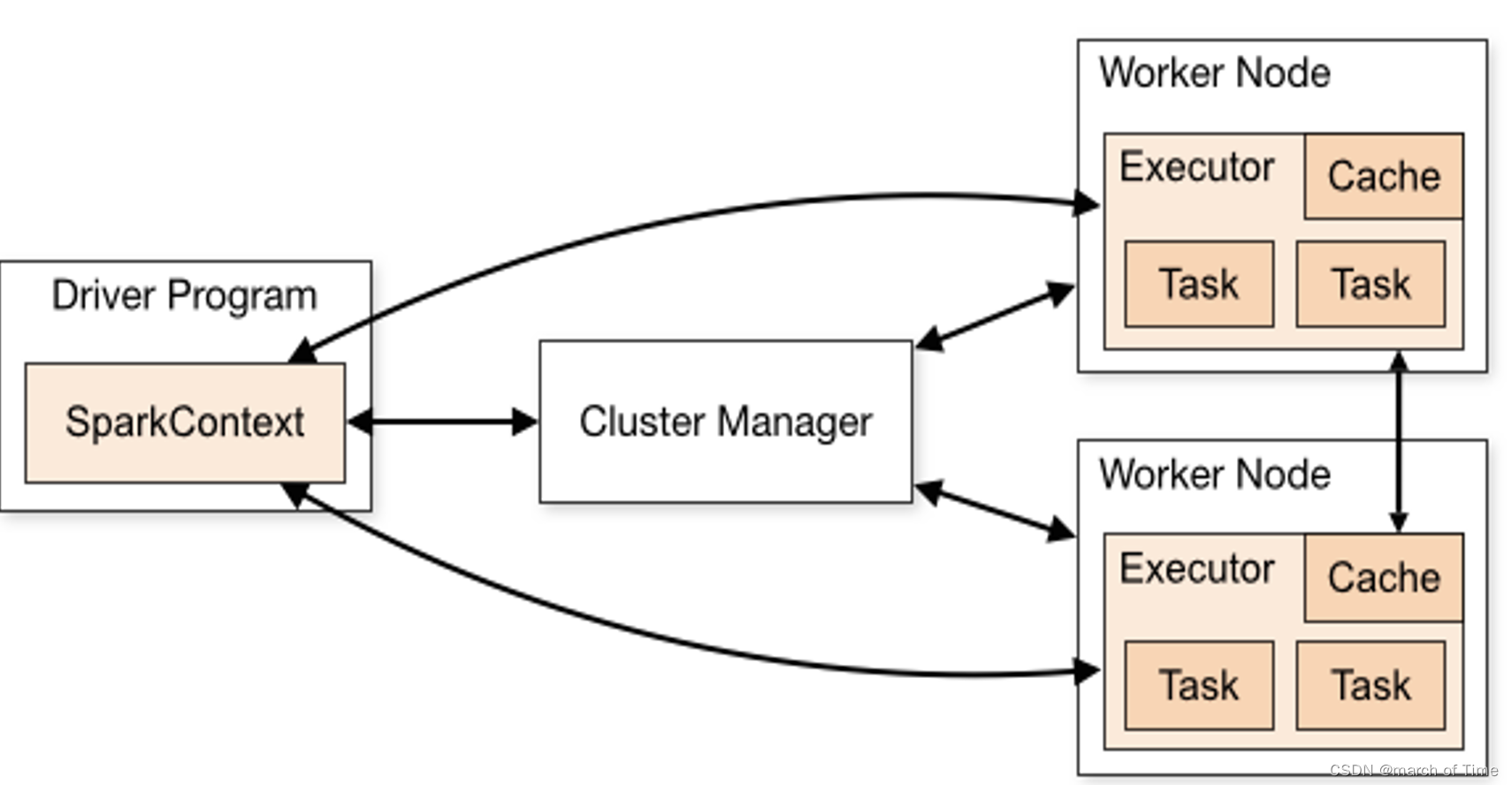
【spark-Spark 安装(集群模式)】此文章归类为:[ "spark", "分布式", "大数据" ]。 Spark 安装(集群模式) 实际生产环境一般不会用本地模式搭建Spar
原创 周杰伦 7个月前 阅读: 200 阅读时长: 9分钟
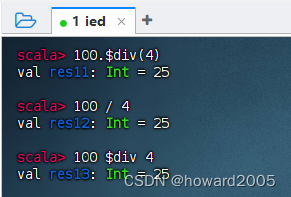
【scala-查看Scala类的方法】此文章归类为:[ "scala", "后端", "大数据", "开发语言" ]。 文章目录 一、概述如何查看Scala类的方法二、使用Scala文档查看类的方
原创 周杰伦 8个月前 阅读: 149 阅读时长: 7分钟
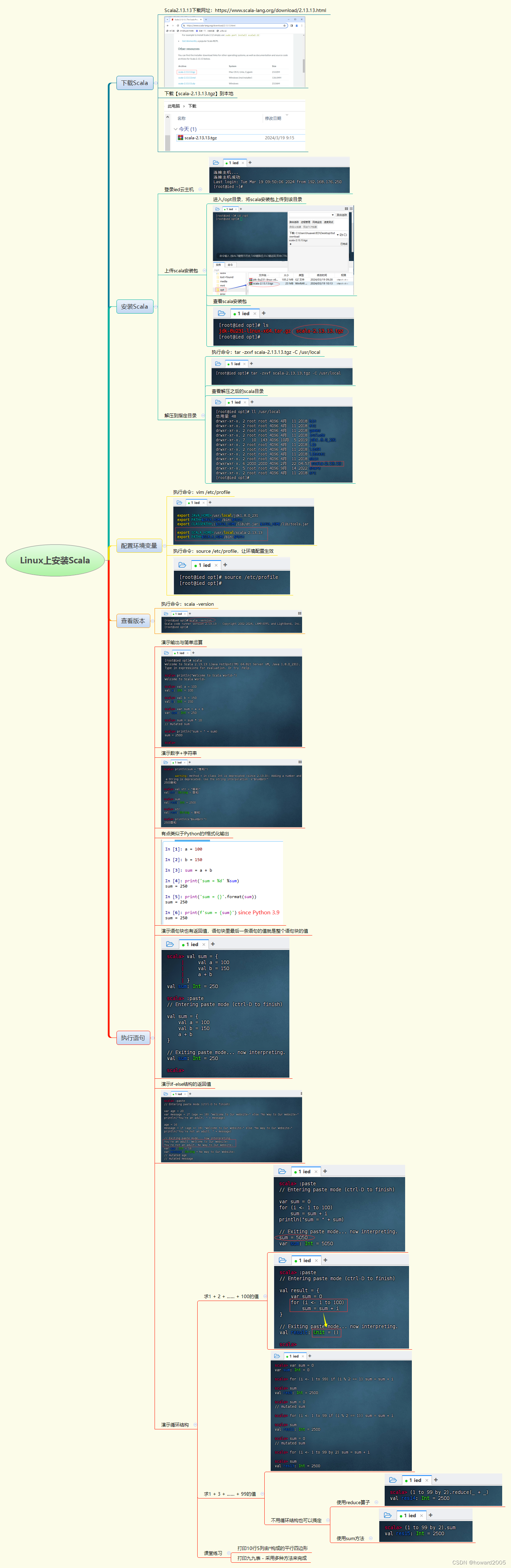
【运维-Linux上安装Scala】此文章归类为:[ "运维", "linux", "服务器" ]。 Linux上安装Scala并演示基础功能 大家好,今天我们将一起在L
原创 周杰伦 8个月前 阅读: 92 阅读时长: 5分钟
【阿里云-阿里云发布 AI 编程助手 “通义灵码”——VSCode更强了 !!】此文章归类为:["阿里云","vscode","人工智能","云计算"]。 文章目录 什么是 通义灵码(TONGYI Lingma) 快速体验“通义灵码” 什么是“通义灵码”(TONGYI Lingma) 通义灵码(TONGYI Lingma),是阿里云出品的一款基于通义大模型
原创 周杰伦 8个月前 阅读: 182 阅读时长: 3分钟
【flink-大数据之Flink(一)】此文章归类为:["flink","大数据"]。 1、简介 flink是一个分布式计算/处理引擎,用于对无界和有界数据流进行状态计算。 flink处理流程 应用场景: 电商销售:实时报表、广告投放、实时推荐 物联网:实时数据采集、实时报警 物流配送、服务:订单状态跟踪、信息推送 银行、金融:实时结算、风险
原创 周杰伦 8个月前 阅读: 249 阅读时长: 9分钟