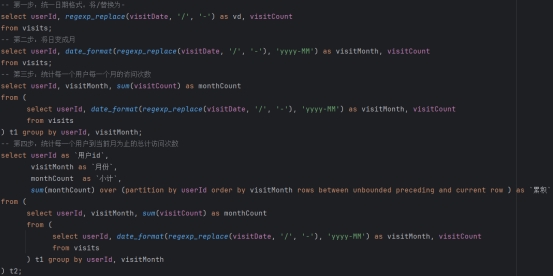
【hive-面试题1(京东)之HiveSql --- 难度:入门初级】此文章归类为:[ "hive", "数据仓库", "hadoop", "大数据", "sql" ]。 第1题 有如下的用户访问数据
原创 周杰伦 7个月前 阅读: 148 阅读时长: 9分钟
【数据仓库-一文了解和区分数据中台、数据平台、数据湖、数据仓库】此文章归类为:[ "数据仓库" ]。 在当今数字化时代,数据已经成为推动科技发展和商业创新的关键要素之一。数据中台、数据平台、数据湖和数据仓库是构建现代数据架构的重要组成部分。然而,这些概念之间往往容易混淆。本文将深入介绍并区分这些概念,通过生动的例
原创 周杰伦 7个月前 阅读: 163 阅读时长: 9分钟
【hive-【Hive】HIVE运行卡死没反应】此文章归类为:[ "hive", "数据仓库", "hadoop", "大数据" ]。 Hive运行卡死 再次强调 hive:小兄弟
原创 周杰伦 8个月前 阅读: 167 阅读时长: 5分钟
【hive-Hive自定义GenericUDF函数】此文章归类为:[ "hive", "数据仓库", "hadoop", "硬件架构", "大数据" ]。 Hive自定义GenericUDF函数 当
原创 周杰伦 8个月前 阅读: 160 阅读时长: 9分钟
【数据仓库-ETL的数据挖掘方式】此文章归类为:["数据仓库","人工智能","etl","数据挖掘"]。 ETL的基本概念 数据抽取(Extraction):从不同源头系统中获取所需数据的步骤。比如从mysql中拿取数据就是一种简单的抽取动作,从API接口拿取数据也是。 数据转换(Transformation):清洗、整合和转化原始数据以适应目标存储或分析系统的阶段。从m
原创 周杰伦 8个月前 阅读: 162 阅读时长: 6分钟
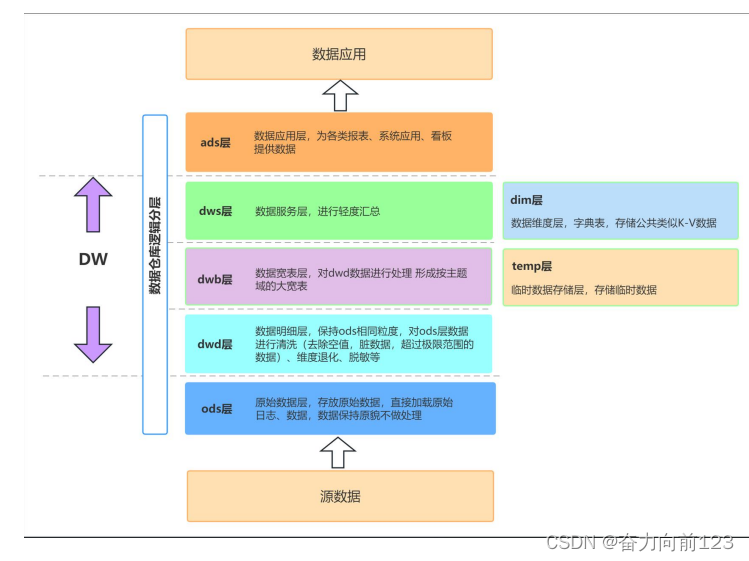
【数据仓库-数据仓库数据分层详解】此文章归类为:["数据仓库"]。 数据仓库中的数据分层是一种重要的数据组织方式,其目的是为了在管理数据时能够对数据有一个更加清晰的掌控。以下是数据仓库中的数据分层详解: 原始数据层(Raw Data Layer):这是数仓中最底层的层级,用于存储从各个数据源获取的原始数据。这些数据通常是未经处理和清洗的,包括来自数据库、日志文件、传感器等的数据。原始
原创 周杰伦 8个月前 阅读: 198 阅读时长: 8分钟
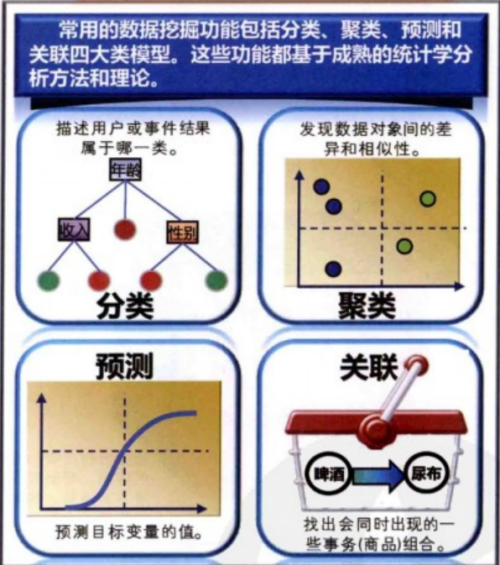
【人工智能-数据挖掘基础(第一章)】此文章归类为:["人工智能","数据挖掘"]。 写在前面的话: 这学期教授《数据挖掘》课程,教材内容略显单薄,故而依据刘鹏教授出版的原书《数据挖掘基础》(第二版)内容归纳重点,并结合畅销书籍易向军所著《大嘴巴漫谈数据挖掘》及袁汉宁版《数据仓库与数据挖掘》扩充相应内容至此,方便学生学习。也方便有需要有教此课的教师进行参考。 我在实际授课
原创 周杰伦 8个月前 阅读: 276 阅读时长: 9分钟
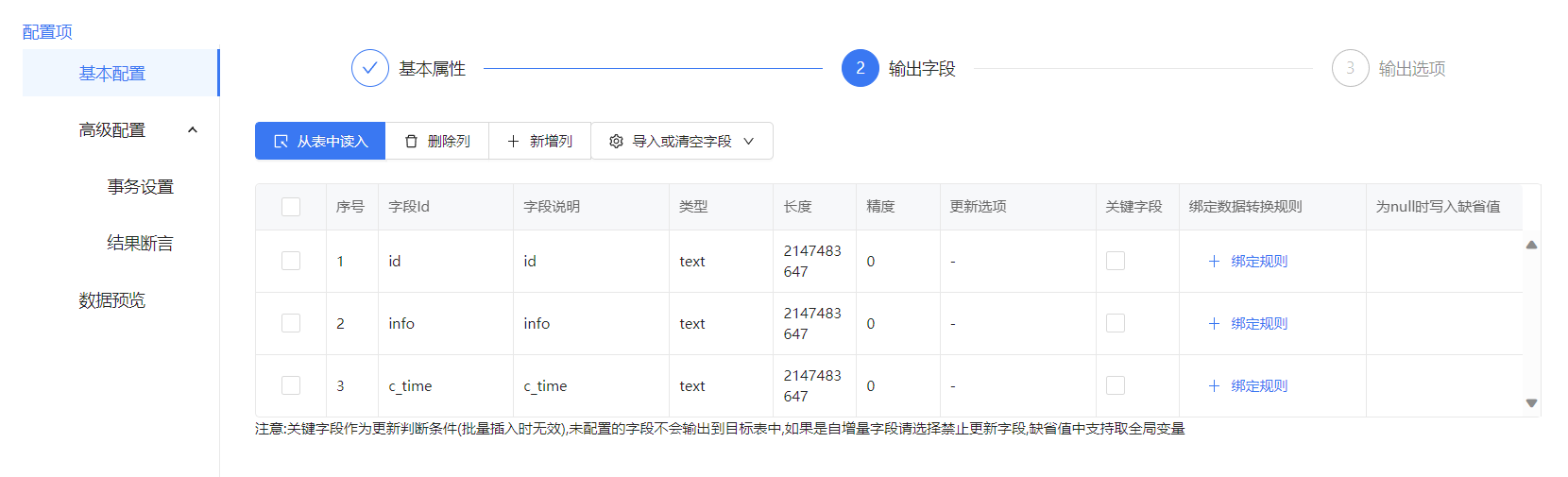
【数据仓库-ETL数据仓库的使用方式】此文章归类为:["数据仓库","etl"]。 一、ETL的过程 在 ETL 过程中,数据从源系统中抽取(Extract),经过各种转换(Transform)操作,最后加载(Load)到目标数据仓库中。以下是 ETL 数仓流程的基本步骤: 抽取(Extract):从各种源系统(如数据库、API、日志文件
原创 周杰伦 8个月前 阅读: 200 阅读时长: 8分钟
【python-关于python的数据可视化与可视化:数据读取】此文章归类为:["python","信息可视化","开发语言"]。 带着问题寻找答案可以使自己不再迷茫或者不知所措! 了解什么python的数据可视化? 数据的读取(一般伴随着课程文件中会进行提供和利用) 数据可视化是将Python应用于大气海洋科学中数据处理及分析过程的重要环节,它可以让复杂晦涩的数据变得鲜活
原创 周杰伦 8个月前 阅读: 199 阅读时长: 9分钟
【hive-Springboot教程(二)——过滤器、拦截器】此文章归类为:["hive","数据仓库","hadoop","分布式","大数据"]。 过滤器 过滤器可以在调用控制器方法之前进行一些操作,过滤器类一般放在filter包下。 配置类注册 使用过滤器时,要实现Filter接口,并重写doFilter方法: class TestFilter : Filter {
原创 周杰伦 8个月前 阅读: 194 阅读时长: 9分钟