语言模型-大语言模型(LLM)token解读
推荐 原创1. 什么是token?
人们经常在谈论大模型时候,经常会谈到模型很大,我们也常常会看到一种说法:
参数会让我们了解神经网络的结构有多复杂,而token的大小会让我们知道有多少数据用于训练参数。
什么是token?比较官方的token解释:
Token是对输入文本进行分割和编码时的最小单位。它可以是单词、子词、字符或其他形式的文本片段。
看完是不是一脸懵逼?为此我们先补充点知识。
2. 大模型工作原理
本质上就是神经网络。但是训练这么大的神经网络,肯定不能是监督学习,如果使用监督学习,必然需要大量的人类标记数据,这几乎是不可能的。那么,如何学习?
当然,可以不用标记数据,直接训练,这种学习方法称为自监督学习。引用学术点的描述:
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息训练模型,从而学习到对下游任务有价值的表征。
自监督学习无标签数据和辅助信息,这是定义自监督学习的两个关键依据。它会通过构造辅助任务来获取监督信息,这个过程中有学习到新的知识;而无监督学习不会从数据中挖掘新任务的标签信息。
例如,在英语考试中,通过刷题可以提高自己的能力,其中的选项就相当于标签。当然,也可以通过听英文音频、阅读英文文章、进行英文对话交流等方式来间接提高英语水平,这些都可以视为辅助性任务(pretext),而这些数据本身并不包含标签信息。
那么,GPT是如何在人类的文本数据上实现自监督学习的呢?那就是用文本的前文来预测后文。
此处引用知乎大佬的案例,例如在下面这段文本中:
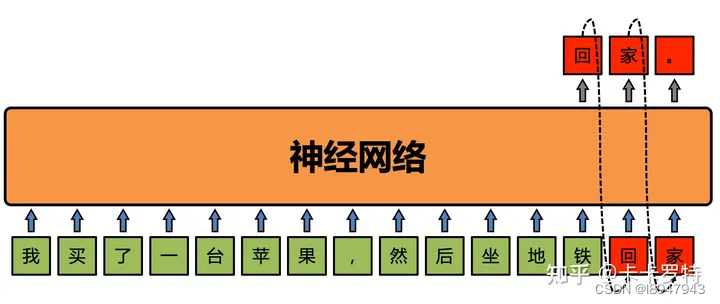
我买了一台苹果,然后坐地铁回家。
GPT 模型会将回家两个字掩盖住。将我买了一台苹果,然后坐地铁视为数据,将回家。视为待预测的内容。 GPT 要做的就是根据前文我买了一台苹果,然后坐地铁来预测后文回家。
这个过程依靠神经网络进行,简单操作过程如图:
3. 谈谈语言模型中的token
GPT 不是适用于某一门语言的大型语言模型,它适用于几乎所有流行的自然语言。所以这告诉我们 GPT 实际的输入和输出并不是像上面那个图中那个样子。计算机要有通用适配或者理解能力,因此,我们需要引入 token 的概念。token 是自然语言处理的最细粒度。简单点说就是,GPT 的输入是一个个的 token,输出也是一个个的 token。
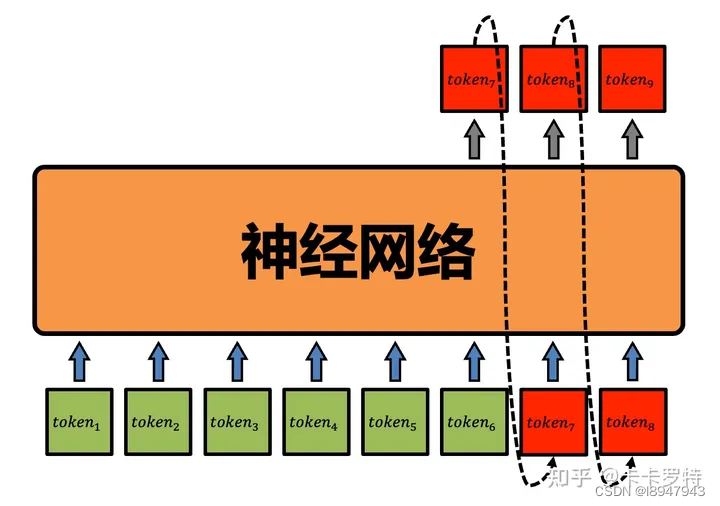
GPT 不是适用于某一门语言的大型语言模型,它适用于几乎所有流行的自然语言。所以 GPT 的 token 需要兼容几乎人类的所有自然语言,那意味着 GPT 有一个非常全的 token 词汇表,它能表达出所有人类的自然语言。如何实现这个目的呢?
答案是通过 unicode 编码。
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
例如,我们在输入你,对应的unicode 编码为:\u4f60,转换成16进制为0100 1111 0110 0000,转换成10进制对应20320。直接将 unicode 的编码作为 GPT 中 token 的词表,会存在一些问题。 一方面直接使用 unicode 作为词汇表太大了,另一方面 unicode 自身的粒度有时候太细了,例如 unicode 中的英文编码是以字母粒度进行的。
于是我们会将 unicode 的2进制结果以8个二进制位为单位进行拆分。用0100 1111和0110 0000表示你8个二进制位只有256种可能,换句话说,只需要256个 token 的词汇表就能表示所有 unicode。
然而这种方法的词汇表又太小了,编码方法太粗糙了。实际上 GPT 是使用一种称为 BPE (Byte Pair Encoding)的算法,在上面的基础上进一步生成更大的词汇表。
它的基本思想如下,将上述的基础 token (256种可能)做组合,然后统计文本数据中这些组合出现的频率,将频率最大的那些保留下来,形成新的 token 词汇表。因此,通过此方法得到的 token 和文字的映射不一定是一对一的关系。

4.再深入理解一下什么是token
Token是LLM处理文本数据的基石,它们是将自然语言转换成机器可理解格式的关键步骤。几个基本概念:
- 标记化过程(Tokenization):这是将自然语言文本分解成token的过程。在这个过程中,文本被分割成小片段,每个片段是一个token,它可以代表一个词、一个字符或一个词组等。
- 变体形式:根据不同的标记化方案,一个token可以是一个单词,单词的一部分(如子词),甚至是一个字符。例如,单词"transformer"可能被分成"trans-", “form-”, "er"等几个子词token。
- 模型模型限制:大型语言模型通常有输入输出token数量的限制,比如2K、4K或最多32K token。这是因为基于Transformer的模型其计算复杂度和空间复杂度随序列长度的增长而呈二次方增长,这限制了模型能够有效处理的文本长度。
- token可以作为数值标识符:Token在LLM内部被赋予数值或标识符,并以序列的形式输入或从模型输出。这些数值标识符是模型处理和生成文本时实际使用的表示形式,说白了可以理解成一种索引,索引本身又是一种标识符。
5. 为什么token会有长度限制?
有以下3方面的相互制约:文本长短、注意力、算力,这3方面不可能同时满足。也就是说:上下文文本越长,越难聚焦充分注意力,难以完整理解;注意力限制下,短文本无法完整解读复杂信息;处理长文本需要大量算力,从而提高了成本。(这是因为GPT底层基于Transformer的模型,Transformer模型的Attention机制会导致计算量会随着上下文长度的增加呈平方级增长)
参考
更多【语言模型-大语言模型(LLM)token解读】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-liunx的启动过程 - 其他
- rust-Rust教程7:Gargo包管理、创建并调用模块 - 其他
- c#-顶顶通语音识别使用说明 - 其他
- stm32-FPGA与STM32_FSMC总线通信实验 - 其他
- spring-springboot集成redis -- spring-boot-starter-data-redis - 其他
- ios-LibXL 4.2.0 for c++/net/win/mac/ios Crack - 其他
- unity-Unity DOTS系列之System中如何使用SystemAPI.Query迭代数据 - 其他
- 网络-openssl+SM2开发实例一(含源码) - 其他
- spring-Redis的内存淘汰策略分析 - 其他
- 单一职责原则-01.单一职责原则 - 其他
- 分布式-Java架构师分布式搜索词库解决方案 - 其他
- 电脑-京东数据分析:2023年9月京东笔记本电脑行业品牌销售排行榜 - 其他
- 云计算-什么叫做云计算? - 其他
- 编程技术-基于springboot+vue的校园闲置物品交易系统 - 其他
- 零售-OLED透明屏在智慧零售场景的应用 - 其他
- 交互-顶板事故防治vr实景交互体验提高操作人员安全防护技能水平 - 其他
- unity-原型制作神器ProtoPie的使用&Unity与网页跨端交互 - 其他
- python-Django知识点 - 其他
- 前端-js实现定时刷新,并设置定时器上限 - 其他
- 需求分析-2023-11-11 事业-代号s-duck-官网首页需求分析 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
