elasticsearch-【面试题】ES文档写入和读取流程详解
推荐 原创
前言:在回答这个问题之前我们先要搞清楚一个问题那就是什么是文档,避免不知所云!

一、什么是文档?
在Elasticsearch中,文档(Document)是最基本的信息单元,用于表示和存储数据。文档是以JSON格式表示的结构化数据对象,类似于关系型数据库中的行。
补充:在Elasticsearch中,文档由以下几个关键部分组成:
索引(Index):文档必须属于一个索引,索引是用于组织和存储文档的逻辑容器。索引是Elasticsearch中数据的顶层概念,它类似于关系型数据库中的数据库。
类型(Type):在较早的版本中,文档可以在索引中定义不同的类型。但是从Elasticsearch 7.0版本开始,类型的概念已经被弃用,一个索引只能包含一个文档类型。文档类型主要用于逻辑上对文档进行分类。
ID:每个文档都有一个唯一标识符,称为文档ID。文档ID可以由用户指定,也可以由Elasticsearch自动生成。通过文档ID,可以唯一标识和检索特定的文档。
字段(Fields):文档包含多个字段,字段是文档中存储的实际数据。字段可以是不同的数据类型,如文本、数字、日期等。每个字段在文档中都有一个名称和对应的值。
映射(Mapping):映射定义了索引中文档的字段及其类型和属性。它类似于关系型数据库中的表结构。映射规定了字段的数据类型、分析器、索引选项等,以及字段是否可搜索、可排序等属性。
二、 ES文档写入流程

1.单个文档写入流程
先看图:
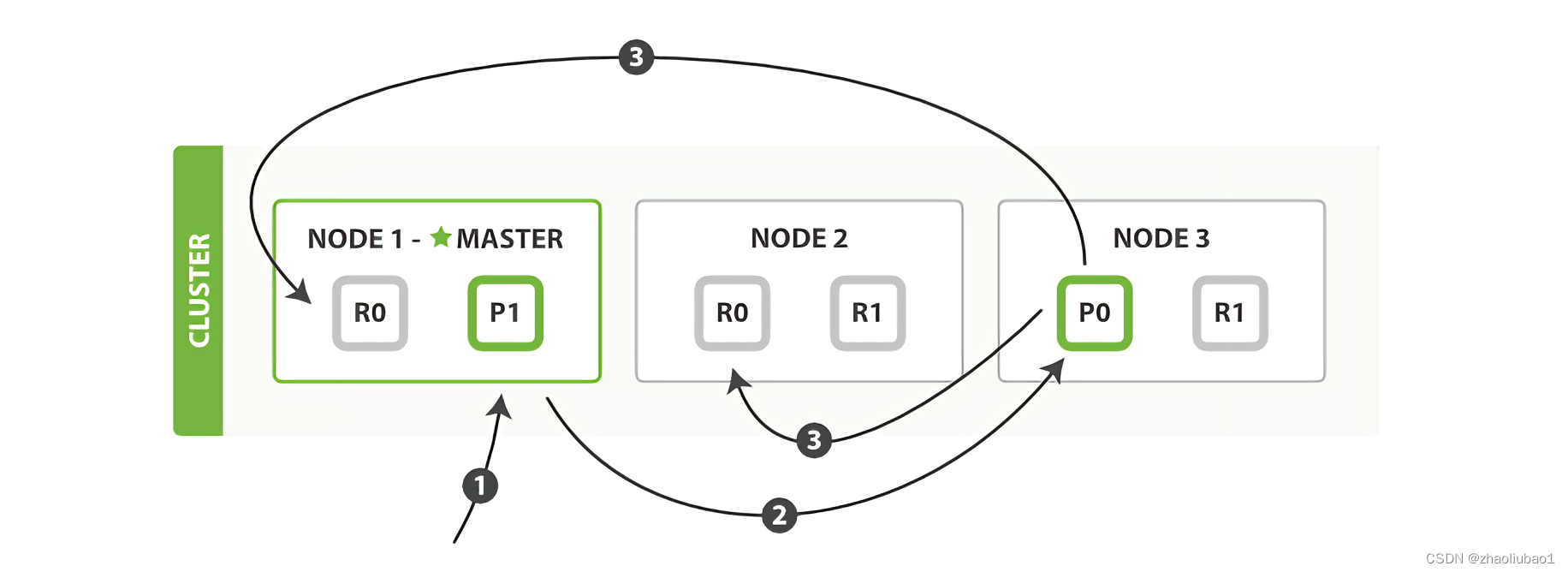
解释: 这个是一个ES的集群架构图,node1是主节点,其他为从节点。
P0、P1代表索引的分片
R0、R1代表副本
写单个文档的流程:
-
客户端向 Node 1 发送写入请求。
-
节点使用文档的 _id 确定文档属于分片 0 。请求会被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上。
-
Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功。
写多个文档的流程
继续看图:
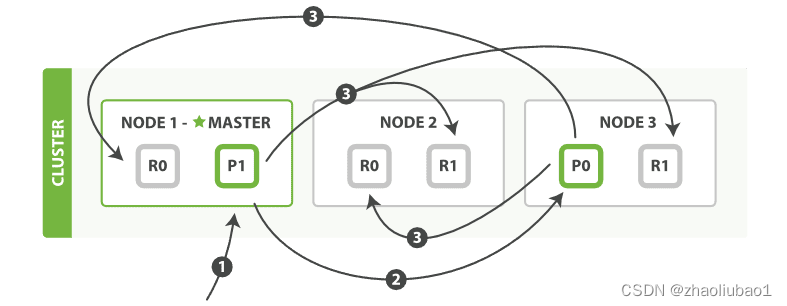
- 客户端向 Node 1 发送 bulk 请求。
- Node 1 为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主机。
- 主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。 一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端
总结:删除文档也是一样的流程,同时还可以得出一个结论,写入和删除请求只能由主节点接受。
三、文档的查询流程


查询单个文档时,可以按照以下步骤进行:
-
客户端发送请求:客户端向任意一个节点(coordinate node)发送获取文档的请求。
-
路由到对应的分片:coordinate node根据文档的唯一ID(doc id)进行哈希计算,确定该文档所属的分片(primary shard)。根据分片路由表,coordinate node将请求转发到包含该分片的节点上。
-
从分片中获取文档:接收请求的节点从对应的分片中获取文档数据。
-
返回文档数据:节点将获取到的文档数据返回给coordinate node。
-
coordinate node返回给客户端:coordinate node将文档数据返回给客户端。
在文档查询中,Elasticsearch使用哈希路由来确定文档所属的分片,并使用轮询算法在主分片和其所有副本之间进行负载均衡。这样做可以分散读取请求的负载,提高系统的读取性能和可扩展性。

在Elasticsearch中进行数据搜索的过程如下:
-
客户端发送搜索请求:客户端向任意一个节点(coordinate node)发送搜索请求,指定搜索条件和相关参数。
-
路由到对应的分片:coordinate node将搜索请求转发到所有包含相关索引的分片(primary shard或replica shard)上。每个分片都会独立进行搜索操作。
-
查询阶段(query phase):每个分片在接收到搜索请求后,根据指定的搜索条件在本地执行搜索操作,并返回与搜索条件匹配的文档的相关信息(如文档ID)给coordinate node。
-
数据合并、排序和分页(query phase):coordinate node收集来自所有分片的搜索结果,并在此阶段进行数据的合并、排序和分页操作。它将根据相关参数(如排序规则、分页偏移量和大小)对搜索结果进行处理,以生成最终的结果集。
-
获取阶段(fetch phase):coordinate node根据最终的结果集中的文档ID,向各个包含匹配文档的节点发送获取文档的请求。
-
返回搜索结果:各个节点根据文档ID从本地分片中获取相应的文档数据,并将数据返回给coordinate node。
-
coordinate node返回给客户端:coordinate node将最终的搜索结果集(包含匹配的文档数据)返回给客户端。
更多【elasticsearch-【面试题】ES文档写入和读取流程详解】相关视频教程:www.yxfzedu.com
相关文章推荐
- 贪心:Huffman树 - 其他
- 论文阅读-kimera论文阅读 - 其他
- java-JavaScript使用正则表达式 - 其他
- c#-钉钉企业微应用开发C#+VUE - 其他
- makefile-c - 其他
- 人工智能-Adobe:受益于人工智能,必被人工智能反噬 - 其他
- asp.net-vue+asp.net Web api前后端分离项目发布部署 - 其他
- 编程技术-程序员怎样才能学好算法?这本书送几本给大家! - 其他
- node.js-Node.js如何处理多个请求? - 其他
- golang-【二、http】go的http基本请求设置(设置查询参数、定制请求头)get和post类似 - 其他
- 算法-平面和射线交点 - 其他
- 编程技术-从白日梦到现实:推出 Elastic 的管道查询语言 ES|QL - 其他
- 前端-Redisson实现延迟队列 - 其他
- 编程技术-MATLAB|怎么将散点图替换成图片 - 其他
- 科技-第二证券:消费电子概念活跃,博硕科技“20cm”涨停,天龙股份斩获10连板 - 其他
- 科技-思谋科技进博首秀:工业多模态大模型IndustryGPT V1.0正式发布 - 其他
- 科技-智能井盖传感器功能,万宾科技产品介绍 - 其他
- 科技-专访虚拟人科技:如何利用 3DCAT 实时云渲染打造元宇宙空间 - 其他
- 机器学习-Azure 机器学习 - 使用 ONNX 对来自 AutoML 的计算机视觉模型进行预测 - 其他
- 缓存-Redisson中的对象 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——NullPointerDereference
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——TypeConfusion
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——IntegerOverflow
- 软件逆向-LMCompatibilityLevel 安全隐患
- Android安全-记一次完整的Android native层动态调试--使用avd虚拟机
- 二进制漏洞-零基础入门V8——CVE-2021-38001漏洞利用
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——UAF
- Pwn-glibc高版本堆题攻击之safe unlink
- 二进制漏洞-CVE-2020-1054提权漏洞学习笔记
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——BufferOverflowNonPagedPool
