机器学习-Azure 机器学习 - 设置 AutoML 训练时序预测模型
推荐 原创目录
本文将介绍如何使用 Azure 机器学习自动化 ML 为时序预测模型设置 AutoML 训练。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

一、环境准备
在本文中,你需要:
- Azure 机器学习工作区。 若要创建工作区,请参阅创建工作区资源。
二、训练和验证数据
自动化 ML 中预测回归任务类型与回归任务类型之间最重要的区别是,前者包含训练数据中一个表示有效时序的特征。 常规时序具有明确定义的一致频率,并且在连续时间范围内的每个采样点上都有一个值。
在训练用于预测未来值的模型时,请确保在针对预期范围运行预测时可使用训练中用到的所有特征。 例如,在创建需求预测时,包含当前股票价格的特征可能大幅提升训练准确度。 但是,如果你打算使用较长的时间范围进行预测,则可能没法准确预测与未来的时序点相对应的未来股价值,模型准确性也会受到影响。
可以直接在 AutoMLConfig 对象中指定单独的训练数据和验证数据。
对于时序预测,默认情况下仅使用滚动原点交叉验证 (ROCV) 进行验证。 ROCV 使用原始时间点将时序分成训练数据和验证数据。 在时间内滑动原点会生成交叉验证折叠。 此策略保留了时序数据完整性并消除了数据泄露风险。
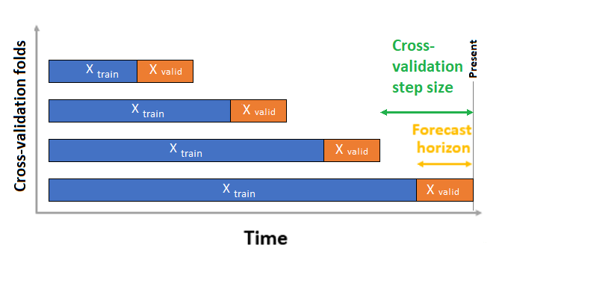
将训练和验证数据作为一个数据集传递给参数 training_data。 使用参数 n_cross_validations 设置交叉验证折叠数,并使用 cv_step_size 设置两个连续交叉验证折叠之间的时段数。 也可以将其中一个或两个参数留空,AutoML 会自动设置它们。
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
你还可以自带验证数据,详情请参阅在 AutoML 中配置数据拆分和交叉验证。
详细了解 AutoML 如何应用交叉验证来防止过度拟合模型。
三、配置试验
AutoMLConfig 对象定义自动化机器学习任务所需的设置和数据。 预测模型的配置与标准回归模型的设置相似,但存在专门针对时序数据的某些模型、配置选项和特征化步骤。
支持的模型
在模型创建和优化过程中,自动化机器学习会自动尝试各种模型和算法。 用户不需要指定算法。 对于预测试验,本机时序模型和深度学习模型都是推荐系统的一部分。
配置设置
与回归问题类似,你要定义标准训练参数,例如任务类型、迭代次数、训练数据和交叉验证次数。 预测任务需要 time_column_name 和 forecast_horizon 参数来配置试验。 如果数据包含多个时序,例如多个商店的销售数据或不同州中的能源数据,自动化 ML 会自动检测此情况,并为你设置 time_series_id_column_names 参数(预览版)。
| 参数名称 | 说明 |
|---|---|
time_column_name |
用于指定输入数据中用于生成时序的日期时间列并推断其频率。 |
forecast_horizon |
定义要预测的未来的时段数。 范围以时序频率为单位。 单位基于预测器应预测出的训练数据的时间间隔,例如每月、每周。 |
以下代码
- 利用
ForecastingParameters类为试验训练定义预测参数 - 将
time_column_name设置为数据集中的day_datetime字段。 - 将
forecast_horizon设置为 50 以针对整个测试集进行预测。
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
然后,将这些 forecasting_parameters 传入到标准 AutoMLConfig 对象中,同时还传入 forecasting 任务类型、主要指标、退出条件和训练数据。
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
通过自动化 ML 成功训练预测模型所需的数据量受在配置 AutoMLConfig 时指定的 forecast_horizon、n_cross_validations 和 target_lags 或 target_rolling_window_size 值影响。
下面的公式计算构建时序功能所需的历史数据量。
所需的最小历史数据:(2x forecast_horizon) + #n_cross_validations + max(max(target_lags), target_rolling_window_size)
数据集中任何不满足指定的相关设置的所需历史数据量的序列,都将引发 Error exception。
特征化步骤
在每一个自动化机器学习试验中,默认情况下都会将自动缩放和规范化技术应用于数据。 这些技术是特征化的类型,用于帮助对不同规模数据的特征敏感的某些算法。 在 AutoML 中的特征化中详细了解默认特征化步骤
但是,仅对 forecasting 任务类型执行以下步骤:
- 检测时序采样频率(例如每小时、每天、每周),并为缺失的时间点创建新记录以使序列连续。
- 通过向前填充估算目标列中缺少的值,通过列值中位数估算特征列中缺少的值
- 创建基于时序标识符的特征,以在不同序列中启用固定效果
- 创建基于时间的特征,以帮助学习季节性模式
- 将分类变量编码为数值数量
- 检测非平稳时序并自动对其进行差分,以减轻单位根的影响。
自动化机器学习特征化步骤(特征规范化、处理缺失数据,将文本转换为数字等)成为了基础模型的一部分。 使用模型进行预测时,将自动向输入数据应用在训练期间应用的相同特征化步骤。
自定义特征化
你还可以自定义特征化设置,以确保用于训练 ML 模型的数据和特征能够产生相关的预测。
forecasting 任务支持的自定义项包括:
| 自定义 | 定义 |
|---|---|
| 列用途更新 | 重写指定列的自动检测到的特征类型。 |
| 转换器参数更新 | 更新指定转换器的参数。 目前支持 Imputer(fill_value 和中值)。 |
| 删除列 | 指定要从特征化中删除的列。 |
若要使用 SDK 来自定义特征化,请在 AutoMLConfig 对象中指定 "featurization": FeaturizationConfig。 详细了解自定义特征化。
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
如果使用 Azure 机器学习工作室进行试验,请参阅如何在工作室中自定义特征化。
四、可选配置
有其他可用于预测任务的可选配置,例如,启用深度学习和指定目标滚动窗口聚合。 ForecastingParameters SDK 参考文档中提供了其他参数的完整列表。
频率和目标数据聚合
利用频率参数 freq 来避免由不规则数据(即不遵循固定频率的数据,例如,每小时或每天的数据)导致的故障。
对于高度不规则的数据或不同的业务需求,用户可以选择设置所需的预测频率 freq 并指定 target_aggregation_function,以便聚合时序的目标列。 在 AutoMLConfig 对象中利用这两个设置有助于节省一些进行数据准备的时间。
目标列值支持的聚合运算包括:
| 函数 | 说明 |
|---|---|
sum |
求目标值的总和 |
mean |
求目标值的平均值 |
min |
求目标的最小值 |
max |
求目标的最大值 |
启用深度学习
还可以通过深度神经网络 (DNN) 应用深度学习来提高模型的分数。 通过自动化 ML 的深度学习,可预测单变量和多变量时序数据。
深度学习模型具有三个固有功能:
- 可以从任意输入到输出映射进行学习
- 支持多个输入和输出
- 可以从跨越较长序列的输入数据中自动提取模式。
若要启用深度学习,请在 AutoMLConfig 对象中设置 enable_dnn=True。
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
若要为在 Azure 机器学习工作室中创建的 AutoML 试验启用 DNN,请参阅工作室 UI 操作指南中的任务类型设置。
目标滚动窗口聚合
通常,目标的最新值是预测程序能具有的最佳信息。 通过目标滚动窗口聚合,可将数据值的滚动聚合添加为特征。 通过生成和使用这些特征作为额外的上下文数据,帮助提高训练模型的准确性。
例如,假设你想要预测能源需求。 你可能希望添加一项滚动窗口(3 天)特征来解释供暖空间的热变化。 在此示例中,通过在 AutoMLConfig 构造函数中设置 target_rolling_window_size= 3 来创建此窗口。
下表显示了在应用窗口聚合后发生的特征工程。 根据定义的设置针对滑动窗口 3 生成表示最小值、最大值和总和的列。 每一行有计算得出的一个新特征;如果时间戳为 2017 年 9 月 8 日凌晨 4:00,则使用 2017 年 9 月 8 日凌晨 1:00 至 3:00 的需求值计算最大值、最小值和总和值。 3 这个窗口将移位填充其余行的数据。
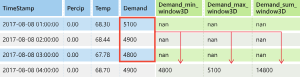
请查看应用目标滚动窗口聚合特征的 Python 代码示例。
短时序处理
如果没有足够的数据点来执行模型开发的训练和验证阶段,自动化 ML 就会将一个时序视为短时序。 数据点的数量因各个试验而异,并且依赖于 max_horizon、交叉验证拆分数以及模型回看的长度,该长度是构建时序功能所需的最长历史记录。
默认情况下,自动化 ML 通过在 ForecastingParameters 对象中使用 short_series_handling_configuration 参数来提供“短时序处理”。
若要启用“短序列处理”,还必须定义 freq 参数。 为了定义每小时频率,我们将设置 freq='H'。 通过访问 pandas 时序页面 DataOffset 对象部分查看频率字符串选项。 若要更改默认行为 short_series_handling_configuration = 'auto',请更新 ForecastingParameter 对象中的 short_series_handling_configuration 参数。
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
下表总结了可用于 short_series_handling_config 的设置。
| 设置 | 说明 |
|---|---|
auto |
短时序处理的默认值。 |
| - 如果所有时序都是短时序,则填充数据。 | |
| - 如果并非所有时序都是短时序,则删除短时序。 | |
pad |
如果 short_series_handling_config = pad,则自动化 ML 会为找到的每个短时序添加随机值。 下面列出了列类型以及用于填充这些列的内容: |
| - 对象列,其中包含 NAN | |
| - 数值列,其中包含 0 | |
| - 布尔/逻辑列,其中包含 False | |
| - 目标列填充平均值为零且标准偏差为 1 的随机值。 | |
drop |
如果 short_series_handling_config = drop,则自动化 ML 会删除短时序,并且该短时序不会用于训练或预测。 对这些时序的预测将会返回 NAN。 |
None |
不会填充或删除任何时序 |
非稳定时序检测和处理
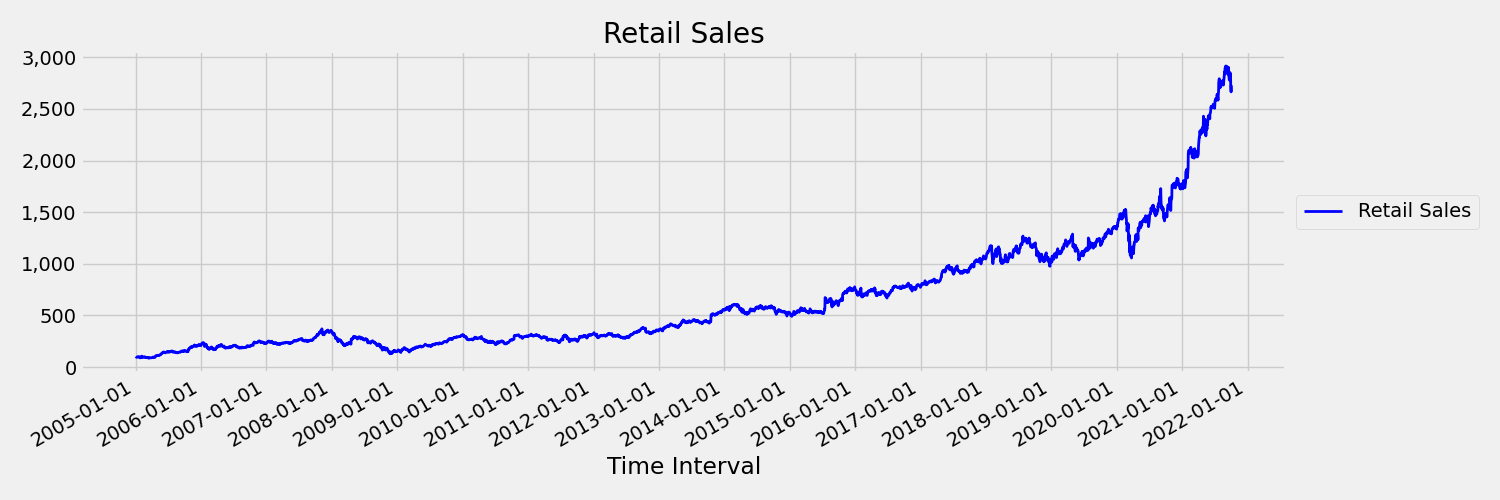
矩(平均值和方差)随时间变化的时序称为非稳定时序。 例如,表现出随机趋势的时序本质上是非稳定的。 为了直观显示这一点,下图绘制了一个通常呈上升趋势的序列。 现在,计算并比较序列的前半部分和后半部分的平均值。 他们是一样的吗? 这里,在图中,前半部分的序列平均值明显小于后半部分。 序列的平均值取决于所观察的时间间隔,这一事实是随时间变化的矩的一个示例。 在这里,序列的平均值是第一个矩。
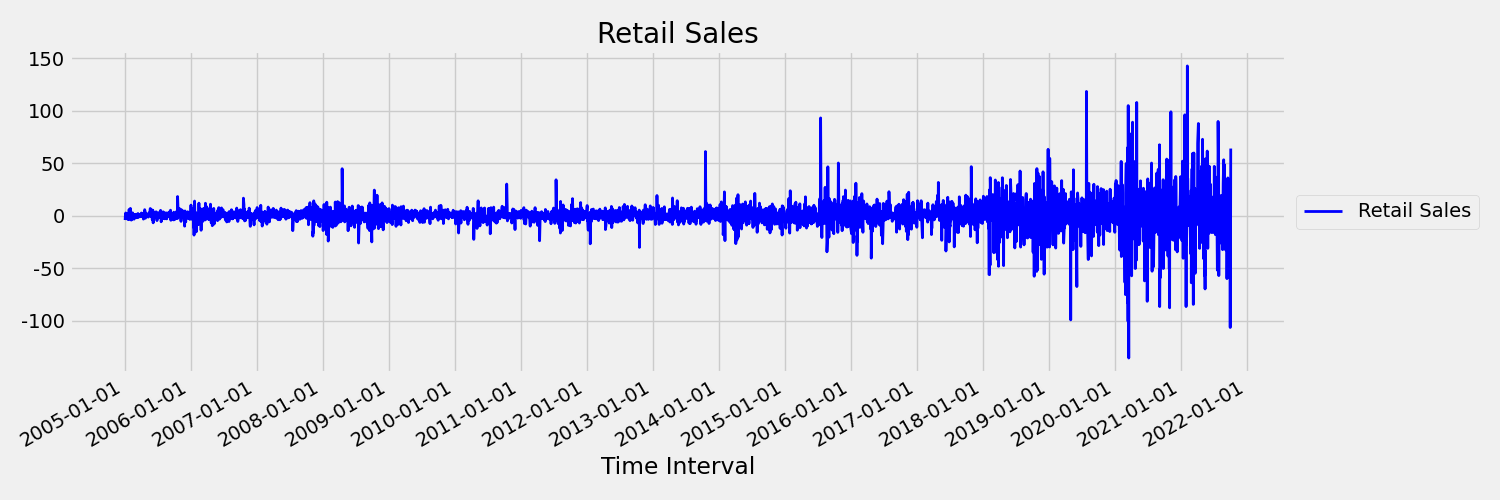
接下来,让我们看看下图,它以第一差分 xt=yt−yt−1 绘制了原始序列,其中 xt 是零售额的变化,yt 和 yt−1 分别表示原始序列和它的第一次滞后。 无论所查看的时间范围如何,序列的平均值大致都是恒定的。 这是一阶静态时序的一个例子。 我们添加了一阶这个术语的原因是,第一个时刻(平均值)不随时间间隔变化,而方差(即第二个时刻)则不适用。
AutoML 机器学习模型本身无法处理随机趋势或与非稳定时序相关的其他已知问题。 因此,如果存在此类趋势,其样本外预测准确度将“较差”。
AutoML 会自动分析时序数据集,看看它是否为静态数据集。 检测到非静态时序时,AutoML 会自动应用差分转换,以减轻非静态时序的影响。
五、运行试验
准备好 AutoMLConfig 对象后,可以提交试验。 模型完成后,检索最佳的运行迭代。
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
六、用最佳模型进行预测
使用最佳模型迭代来预测未用于训练模型的数据的值。
用滚动预测评估模型精度
在将模型投入生产之前,应在训练数据中保留的测试集上评估其准确性。 最佳实践程序是所谓的滚动评估,其在测试集上在时间上向前滚动训练的预测器,在几个预测窗口上平均误差度量,以获得对所选度量的某个集合的统计上稳健的估计。 理想情况下,用于评估的测试集相对于模型的预测范围较长。 否则,预测误差的估计可能在统计上是有干扰的,因此可靠性较低。
例如,假设你根据每日销售额训练一个模型,以预测未来两周(14 天)的需求。 如果有足够的历史数据可用,你可以为测试集保留最后几个月甚至一年的数据。 滚动评估开始于为测试集的前两周生成提前 14 天的预测。 然后,预测程序在测试集中提前了一定天数,你可以从新位置生成另一个提前 14 天的预报。 该过程将继续,直到测试集结束。
要进行滚动评估,可以调用 fitted_model 的 rolling_forecast 方法,然后对结果计算所需的指标。 例如,假设你在名为 test_features_df 的 Pandas DataFrame 中设置了测试特性,并在名为 test_target 的 NumPy 数组中设置了目标的实际值。 下面的代码示例显示了使用均方误差的滚动计算:
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
在此示例中,滚动预测的步长设置为 1,这意味着预测者在每次迭代时提前一个周期,或者在我们的需求预测示例中提前一天。 因此,rolling_forecast 返回的预测总数取决于测试集的长度和步长。 有关更多详细信息和示例,请参阅 rolling_forecast() 文档和不依赖训练数据笔记本的预测。
预测未来
forecast_quantiles函数允许指定预测的开始时间,这与通常用于分类和回归任务的方法不同。 默认情况下,forecast_quantiles() 方法生成点预测或平均值/中值预测,而该预测周围没有不确定因素。 有关详细信息,请参阅不使用训练数据进行预测笔记本。
在下例中,先将 y_pred 中的所有值替换为 NaN。 在本例中,预测原点位于训练数据的末尾。 但是,如果只将 y_pred 的后半部分替换为 NaN,则函数不会修改前半部分的数值,而会在后半部分预测 NaN 值。 函数将返回预测值和对齐的特征。
还可以在 forecast_quantiles() 函数中使用 forecast_destination 参数以预测到指定日期为止的值。
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
通常客户想要了解分布的特定分位数处的预测。 例如,当为了控制库存(如杂货或云服务的虚拟机库存)而进行预测时。 在这种情况下,控制点通常类似“我们希望货品有库存,且 99% 的时间都有货”。 下面演示如何指定要针对预测查看的分位数,例如第 50 或第 95 百分位数。 如果不指定分位数(如上述代码示例中所示),则仅生成第 50 百分位数预测。
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
可以计算模型指标(例如,均方根误差 (RMSE) 或平均绝对百分比误差 (MAPE))来帮助估计模型性能。 有关示例,请参阅单车共享需求笔记本的“评估”部分。
确定了模型的整体准确性后,最现实的下一步是使用模型来预测未知的未来值。
提供与测试集 test_dataset 具有相同格式但具有未来日期时间的数据集,生成的预测集就是每个时序步骤的预测值。 假设数据集中最后的时序记录针对的是 2018/12/31。 若要预测次日的需求(或者 <= forecast_horizon 的待预测的多个时间段),请为每个商店创建 2019/01/01 的一条时序记录。
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
重复执行必要的步骤,将此未来数据加载到数据帧,然后运行 best_run.forecast_quantiles(test_dataset) 以预测未来值。
七、大规模预测
在有些方案中,单个机器学习模型是不足的,需要提供多个机器学习模型。 例如,预测各个商店某个品牌的销售额,或者为个人用户定制体验。 为每个实例构建模型可以改善许多机器学习的相关问题。
分组是时序预测中的一种概念,它允许组合时序,以便为每个组训练独立模型。 如果时序需要进行平滑处理、填充或组中包含可从其他实体的历史记录或趋势获益的实体,则此方法可能特别有用。 多模型和分层时序预测是由自动化机器学习提供支持的解决方案,它们针对这些大规模预测方案而提供。
多模型
使用自动化机器学习的 Azure 机器学习多模型解决方案允许用户并行训练和管理数百万模型。 多模型解决方案加速器利用 Azure 机器学习管道来训练模型。 具体而言,将使用管道对象和 ParalleRunStep,并需要通过 ParallelRunConfig 设置的特定配置参数。
下图显示了多模型解决方案的工作流。
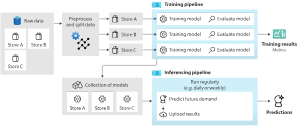
以下代码演示了用户设置和运行多模型所需的关键参数。 有关多模型预测示例,请参阅多模型 - 自动化 ML 笔记本
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
分层时序预测
在大多数应用程序中,客户需要在宏观级别和微观级别了解预测数据,预测不同地理位置的产品销售额,或了解公司不同组织对劳动力的需求。 训练机器学习模型以智能地预测层次结构数据,这是至关重要的。
分层时序是一种结构,其中每个唯一序列都按维度(例如地理或产品类型)排列到层次结构中。 以下示例显示的数据具有构成层次结构的唯一属性。 层次结构通过这些方式定义:产品类型(例如耳机或平板电脑)、产品类别(将产品类型拆分为配件和设备)以及产品销售区域。
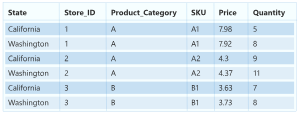
为了进一步直观显示数据,层次结构的叶级别包含具有唯一属性值组合的所有时序。 层次结构中的每个更高级别所考虑的、用于定义时序的维度都会少一个,并且会将较低级别的每个子节点集聚合到一个父节点中。
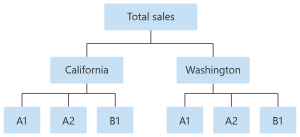
分层时序解决方案建立在多模型解决方案之上,它们共享类似的配置设置。
以下代码演示了用于设置分层时序预测运行的关键参数。 有关端到端示例,请参阅分层时序 - 自动化 ML 笔记本。
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
更多【机器学习-Azure 机器学习 - 设置 AutoML 训练时序预测模型】相关视频教程:www.yxfzedu.com
相关文章推荐
- c#-C#在.NET Windows窗体应用中使用LINQtoSQL - 其他
- flink-flink的CoProcessFunction使用示例 - 其他
- 文心一言-百度上线“文心一言”付费版本,AI聊天机器人市场竞争加剧 - 其他
- 数据库-MongoDB常用的语句 - 其他
- flink-Flink(三)【运行时架构】 - 其他
- java-Windows 安装 Maven - 其他
- 爬虫-使用JavaScript编写游戏平台数据爬虫程序 - 其他
- python-Python(七) 元组 - 其他
- 编程技术-liunx的启动过程 - 其他
- rust-Rust教程7:Gargo包管理、创建并调用模块 - 其他
- c#-顶顶通语音识别使用说明 - 其他
- stm32-FPGA与STM32_FSMC总线通信实验 - 其他
- spring-springboot集成redis -- spring-boot-starter-data-redis - 其他
- ios-LibXL 4.2.0 for c++/net/win/mac/ios Crack - 其他
- unity-Unity DOTS系列之System中如何使用SystemAPI.Query迭代数据 - 其他
- 网络-openssl+SM2开发实例一(含源码) - 其他
- spring-Redis的内存淘汰策略分析 - 其他
- 单一职责原则-01.单一职责原则 - 其他
- 分布式-Java架构师分布式搜索词库解决方案 - 其他
- 电脑-京东数据分析:2023年9月京东笔记本电脑行业品牌销售排行榜 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
