Android安全-定制bcc/ebpf在android平台上实现基于dwarf的用户态栈回溯
推荐 原创ebpf是个非常强大的内核级跟踪机制,不仅可以用于性能分析,在逆向分析中也是非常强大的工具,对此介绍性的文章可以参照evilpan大佬的一文。
而bcc就是其中最著名的上层封装框架,本文就是提供一种定制bcc源码并在android平台上实现基于dwarf的用户态栈回溯的方案,并讨论其中涉及的代码原理及机制。
首先引出如下问题: bcc/ebpf提供了什么形式的栈回溯? 这种栈回溯有什么缺点它是基于什么原理?
首先栈回溯分为基于stack frame(fp)的和基于dwarf的,dwarf(Debugging With Attributed Record Formats)是许多编译器和调试器用来支持源码级调试的文件格式。dwarf的调试信息位于.debug_frame节或者.eh_frame节,其中.eh_frame节是现代Linux操作系统在LSB(Linux Standard Base)标准中定义的。.debug_frame节不会加载到内存,而.eh_frame会被加载到内存中。
关于栈回溯网上有很多文章,这里就不再详述了。
本文使用的环境是pixel 3XL, linux kernel 4.9,aosp 10。由于ebpf是个发展迅速的技术,越新的内核功能越丰富,4.9内核其实算是比较旧的内核了。
本文采用的bcc代码为目前最新的(2022年8月11日release) v0.25.0版本。
一. bcc环境:
bcc的编译运行环境采用的是debootstrap自制debian 10 arm64镜像,并且使用adeb工具将镜像push到手机中,在手机中通过chroot方式运行一个轻量级容器化环境,在这个环境中安装编译所需软件。
编译ebpf程序需要kheader,如果没有会报错:Unable to find kernel headers. Try rebuilding kernel with CONFIG_IKHEADERS=m (module) or installing the kernel development package for your running kernel version.
官方推荐在编译内核的时候加上CONFIG_IKHEADERS选项,但是这个选项在4.9内核上还没有。其实在官方提供的内核android-msm-crosshatch-4.9编译完以后会出生kheader文件:out/android-msm-pixel-4.9/dist/kernel-headers.tar.gz
将这个文件push到手机上,然后解压至/tmp/kheaders-`uname -r`目录即可,因为bcc程序会读取这个目录做为kheaders,具体的逻辑在loader.cc调用的get_proc_kheaders函数中。
二. bcc提供的用户态栈回溯:
ebpf可以很方便的打印出系统调用参数,如果能同时打印出堆栈信息那么对排查问题和逆向分析来说就非常有用了,比如得知是哪个代码路径打开了某个文件,哪个so建立了网络连接,连接到哪个地址,端口号多少等等。最关键的是这种方式是无侵入性的,不论你怎么混淆,都可以跟踪到你所有的系统调用。
其实bcc程序trace.py提供了选项-U用于打印用户态堆栈。
先准备一个小程序,在libnative-lib.so中有如下代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
void func_a(
int
arg) {
__android_log_print(ANDROID_LOG_INFO, LOG_TAG,
"func_a: %d"
, arg);
func_b(
"test"
);
}
void func_b(std::string arg) {
__android_log_print(ANDROID_LOG_INFO, LOG_TAG,
"func_b: %s"
, arg.c_str());
func_c(
10.0f
);
}
void func_c(
float
arg) {
__android_log_print(ANDROID_LOG_INFO, LOG_TAG,
"func_c: %f"
, arg);
func_d(true);
}
void func_d(
bool
arg) {
__android_log_print(ANDROID_LOG_INFO, LOG_TAG,
"func_d: %d"
, arg);
func_e(
10.0f
);
}
void func_e(double arg) {
int
fd;
fd
=
open
(
"/data/local/tmp/test"
, O_RDONLY);
__android_log_print(ANDROID_LOG_INFO, LOG_TAG,
"args is %f, fd is : %d"
, arg, fd);
close(fd);
}
|
程序很简单,就是调用pthread_create创建一个线程并且从func_a一路调用到func_e,在func_e中打开一个文件/data/local/tmp/test。
调用trace.py跟踪该程序(uid 10121)的do_sys_open:python3 trace --uid 10121 'do_sys_open "%s", arg2@user' -U --address -v
可以看到能打印出一些栈调用信息,但是结果不是很理想,比如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
5791
5791
com.mypack.test do_sys_open b
'/proc/self/task/12421/comm'
74f7854388
__openat
+
0x8
[libc.so]
7465f59d28
[unknown]
7fd4be9740
[unknown]
5791
5843
test_unwind do_sys_open b
'/data/local/tmp/test'
7e1b223388
__openat
+
0x8
[libc.so]
7d8a34ec58
[unknown] [base.apk]
7d8a34ec00
[unknown] [base.apk]
7d8a34eac0
[unknown] [base.apk]
7d8a34ea14
[unknown] [base.apk]
7d8a34edb8
[unknown] [base.apk]
7e1b237b44
__pthread_start(void
*
)
+
0x28
[libc.so]
7e1b1da2d4
__start_thread
+
0x44
[libc.so]
|
栈回溯其实包括两部分:获取调用堆栈信息以及符号化
第一个打印堆栈大部分信息都缺失了。
第二个打印是func_a函数发起的打开文件/data/local/tmp/test的堆栈,堆栈信息似乎是好的,但是符号化却出了问题。可以看到符号信息全是unknown,且调用位置是位于base.apk中,并没有显示出libnative-lib.so,且堆栈前面的地址是运行地址,如果能显示出在so中的偏移地址就好了,这样才有利于使用ida分析。
原因在哪呢?这就得去源码里找答案了。
三. bcc程序运行原理
先来看一下Brendan Gregg网站的框架图:
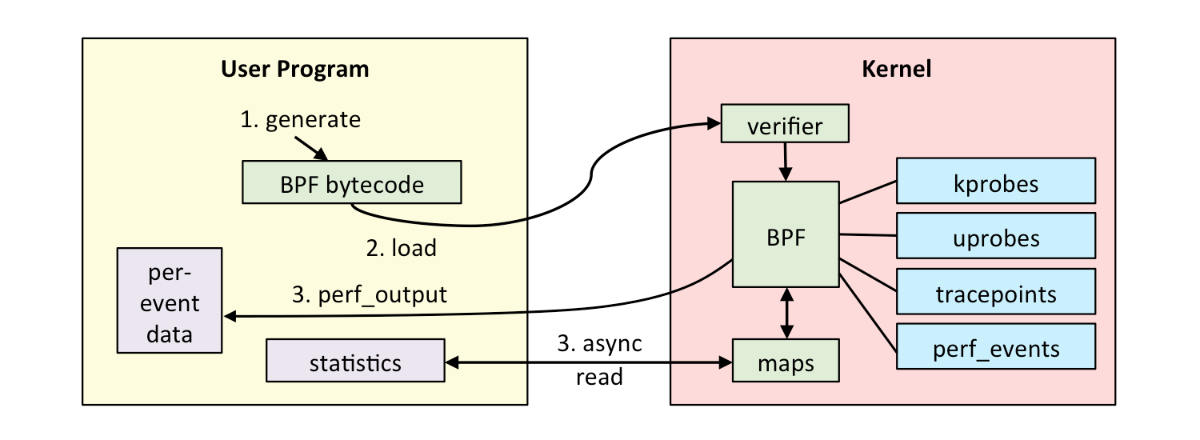
bcc提供的是python语言的前端,python会和后边的c/c++语言的后端进行通信,调用llvm编译生成ebpf程序字节码,调用bpf系统调用经过验证器验证以后会经过jit存放编译后的可执行代码,ebpf程序想得到执行还需要挂载到内核trace/event上,事件发生时ebpf程序得到执行,ebpf程序可以通过bpf map或者perf_output和用户空间通信,ebpf程序执行完以后用户空间读取生成的数据,因此用户空间是异步读取。
其中ebpf所使用的perf_output是本文实现基于dwarf的用户态栈回溯的关键所在。
来看bcc文档docs/tutorial_bcc_python_developer.md中的Lesson 7. hello_perf_output.py这个程序:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
from
bcc
import
BPF
# define BPF program
prog
=
"""
#include <linux/sched.h>
// define output data structure in C
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
};
BPF_PERF_OUTPUT(events);
int hello(struct pt_regs *ctx) {
struct data_t data = {};
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
bpf_get_current_comm(&data.comm, sizeof(data.comm));
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
# load BPF program
b
=
BPF(text
=
prog)
b.attach_kprobe(event
=
b.get_syscall_fnname(
"clone"
), fn_name
=
"hello"
)
# header
print
(
"%-18s %-16s %-6s %s"
%
(
"TIME(s)"
,
"COMM"
,
"PID"
,
"MESSAGE"
))
# process event
start
=
0
def
print_event(cpu, data, size):
global
start
event
=
b[
"events"
].event(data)
if
start
=
=
0
:
start
=
event.ts
time_s
=
(
float
(event.ts
-
start))
/
1000000000
print
(
"%-18.9f %-16s %-6d %s"
%
(time_s, event.comm, event.pid,
"Hello, perf_output!"
))
# loop with callback to print_event
b[
"events"
].open_perf_buffer(print_event)
while
1
:
b.perf_buffer_poll()
|
这个程序的作用是跟踪clone系统调用,并且打印出发生调用的时间,调用者的进程名和pid。
注意prog变量括起来的字符串代码是c语言代码,它之后会被llvm编译,除此之外全是python代码.其中c语言的函数hello是最终会在内核中执行的ebpf程序,它会以kprobes形式挂载到系统调用函数sys_clone。
prog变量中除了hello函数的其他代码属于帮助性代码,用于将ebpf输出和python代码获取的输入数据结构统一起来,这些代码并不会被包含在ebpf最终加载的程序中去
比如上面的BPF_PERF_OUTPUT(events)就定义了用于在ebpf程序中输出的perf缓冲区名称,python程序就可以使用b["events"]关联同一个缓冲区,并从中获取结构化的数据struct data_t。
ebpf程序需要包括相应的头文件,这是为了调用clang的时候能编译通过,也是为了保证ebpf可以加载到api一致的内核中去。
其实上面hello函数中的events.perf_submit(ctx, &data, sizeof(data))并不是一个合法的ebpf程序,ebpf执行的字节码是严格受限的:
- 只有512字节大小的栈空间
- 不能随意调用内核函数,只能调用预定义好的bpf helper函数或者tail call其他的bpf程序
- 程序最大长度是有限的
- 禁止循环
所有这些限制都是为了保证系统的安全性与稳定性,因为bpf程序在内核中执行,一旦有问题会导致整个系统崩溃。
其实最终events.perf_submit(ctx, &data, sizeof(data))会被替换成对应的bpf helper函数,这是通过调用clang修改编译后程序的ast来实现的。
分析一下程序:
b = BPF(text=prog):
可以在调用它的时候添加debug参数:b = BPF(text=prog,debug=DEBUG_PREPROCESSOR|DEBUG_SOURCE),
可以打印出预处理后的程序代码与显示出反编译后的ebpf程序,加上以后再运行hello_perf_output.py程序可以看到程序预处理以后添加了一些宏定义,前面添加上:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#if defined(BPF_LICENSE)
#error BPF_LICENSE cannot be specified through cflags
#endif
#if !defined(CONFIG_CC_STACKPROTECTOR)
#if defined(CONFIG_CC_STACKPROTECTOR_AUTO) \
|| defined(CONFIG_CC_STACKPROTECTOR_REGULAR) \
|| defined(CONFIG_CC_STACKPROTECTOR_STRONG)
#define CONFIG_CC_STACKPROTECTOR
#endif
#endif
#define bpf_probe_read_kernel bpf_probe_read
#define bpf_probe_read_kernel_str bpf_probe_read_str
#define bpf_probe_read_user bpf_probe_read
#define bpf_probe_read_user_str bpf_probe_read_str
|
最后添加上:#include <bcc/footer.h>
hello函数添加了__attribute__((section(".bpf.fn.hello")))指定输出section为.bpf.fn.hello。
而events.perf_submit(ctx, &data, sizeof(data))则修改成了bpf helper函数:bpf_perf_event_output(ctx, bpf_pseudo_fd(1, -1), CUR_CPU_IDENTIFIER, &data, sizeof(data));
只不过其中的参数bpf_pseudo_fd(1, -1)还是个伪参数,后面还会做进一步的处理。
继续回到b = BPF(text=prog)函数,它所做的事情主要如下:
- 编译bpf程序
- 加载bpf程序
- attach bpf程序
1.编译bpf程序:
python程序中表示bpf程序的为BPF类,c/c++中表示bfp程序的类为ebpf::BPFModule,两者的关联依靠于python中的ctypes,这是类似于jni的一种机制 : python中的BPF类加载libbcc.so.0共享库并且调用其中的bpf_module_create_c_from_string()函数从而创建出ebpf::BPFModule对象。
ebpf::BPFModule的构造函数中会初始化llvm运行环境,为编译ebpf程序做好准备:
|
1
2
3
4
5
6
7
8
9
10
11
|
initialize_rw_engine();
LLVMInitializeBPFTarget();
LLVMInitializeBPFTargetMC();
LLVMInitializeBPFTargetInfo();
LLVMInitializeBPFAsmPrinter();
#if LLVM_MAJOR_VERSION >= 6
LLVMInitializeBPFAsmParser();
if
(flags & DEBUG_SOURCE)
LLVMInitializeBPFDisassembler();
#endif
LLVMLinkInMCJIT();
/
*
call empty function to force linking of MCJIT
*
/
|
接下来会调用ebpf::BPFModule的load_string()函数执行编译操作,它所做的事情可总结如下:
- 编译ebpf程序需要kheaders文件,寻找kheaders文件所处路径,一般linux发行版中位于
/lib/modules目录,如果配置了CONFIG_IKHEADERS=m的内核,kheaders文件路径为/proc/kheaders.tar.xz.否则就在/tmp/kheaders-`uname -r`目录下寻找。 - 下面开始拼接出clang的编译选项,位于flags_cstr变量中,由于指定了-emit-llvm选项,因此编译出来产物为llvm IR文件.注意一些编译选项使用的文件是虚拟文件:-
include /virtual/include/bcc/bpf_workaround.h -include /virtual/include/bcc/helpers.h,编译的虚拟目标是/virtual/main.c. 编译选项中使用-I参数指定了内核的kheaders目录。 - 初始化clang编译库,进行预处理操作,首先调用
clang::CompilerInvocation的getPreprocessorOpts().addRemappedFile()函数进行remapping操作,将上面涉及到的虚拟文件映射成真实的文件,其中/virtual/main.c映射为内存中源代码的表示llvm::MemoryBuffer对象。 - 接着进行三轮基于抽象语法树ast处理,分别是:
TracepointFrontendAction,BFrontendAction,EmitLLVMOnlyAction,这种处理可以进行源代码的转换,其中BFrontendAction相当复杂,处理的类型很多,理解它需要对clang相关api和ast很熟悉才行,不过可以直接将处理后的源代码打印出来只看对目前程序的处理即可.BFrontendAction有一步重要的处理:Catch the map declarations and open the fd's。 - 经过上面的处理以后就会生成LLVM的IR表示llvm::Module对象,接着调用finalize()函数,针对IR进行bpf程序的编译,并且执行PassManager将涉及到的函数都变成内联函数.编译出的指令存放在prog_funcinfo对象中,其中FuncInfo代表着每个编译出来的函数,函数执行指令在内存中地址为FuncInfo对象的start_指针。
- 调用load_maps函数通过bpf系统调用创建出bpf maps。
来重点看一下第6条的load_maps,hello_perf_output.py程序有一行代码 : BPF_PERF_OUTPUT(events);BPF_PERF_OUTPUT是一个宏,定义在文件src/cc/export/helpers.h文件中,BPF_PERF_OUTPUT(events)其实等价于:
|
1
2
3
4
5
6
7
8
9
10
|
struct events_table_t {
int
key;
u32 leaf;
/
*
map
.perf_submit(ctx, data, data_size)
*
/
int
(
*
perf_submit) (void
*
, void
*
, u32);
int
(
*
perf_submit_skb) (void
*
, u32, void
*
, u32);
u32 max_entries;
};
__attribute__((section(
"maps/perf_output"
)))
struct events_table_t events
=
{ .max_entries
=
0
}
|
__attribute__((section("maps/perf_output")))这个编译属性指定的section为maps/perf_output,上面的编译过程中BFrontendAction扫描到了这个编译属性以后会生成一个生成map的fake id,并存放在fake_fdmap成员变量中.
这个map的类型为BPF_MAP_TYPE_PERF_EVENT_ARRAY,key大小对应于events_table_t结构的key类型int,value大小对应于events_table_t结构的leaf类型u32,max_entries大小为cpu的个数。
当执行到上面第6步的load_maps函数时,该函数会遍历fake_fd_map_,调用bpf系统调用,简化版代码可以认为是这样调用的:
|
1
2
3
4
5
6
7
8
9
|
union bpf_attr attr
=
{
.map_type
=
BPF_MAP_TYPE_PERF_EVENT_ARRAY,
.key_size
=
sizeof(
int
),
.value_size
=
sizeof(u32),
.max_entries
=
get_possible_cpus().size(),
.map_name
=
"events"
,
};
int
bpf_map_fd
=
bpf(BPF_MAP_CREATE, &attr, sizeof(attr));
|
总结一下上面的过程:
- 编译bpf程序,编译产物存放在BPFModule类的prog_funcinfo成员变量中
- 因为有了这一行代码:BPF_PERF_OUTPUT(events);就会调用bpf系统调用创建出一个bpf maps,类型为BPF_MAP_TYPE_PERF_EVENT_ARRAY
2.加载bpf程序:
这一步就是调用bpf系统调用,cmd为BPF_PROG_LOAD,将上面编译的ebpf程序加载到内核中。
3. attach bpf程序:
加载完ebpf程序以后,还得将它以kprobes形式挂载到系统调用函数sys_clone,这种attach操作依赖于内核中已经存在机制:perf或者ftrace。
bcc会优先使用perf的系统调用perf_event_open进行attach,如果它失败了则使用ftrace进行attach。
使用perf_event_open进行attach的时候是这么调用的:
|
1
2
3
4
5
6
7
8
9
10
|
perf_event_attr attr;
attr.sample_period
=
1
;
attr.wakeup_events
=
1
;
attr.config |
=
(
0
<<
32
);
attr.config2
=
0
;
attr.size
=
sizeof(attr);
attr.
type
=
type
;
/
/
cat
/
sys
/
bus
/
event_source
/
devices
/
kprobe
/
type
attr.config1
=
ptr_to_u64((void
*
)
"sys_clone"
);
int
pfd
=
perf_event_open(&attr,
-
1
,
0
,
-
1
,PERF_FLAG_FD_CLOEXEC)
ioctl(pfd, PERF_EVENT_IOC_SET_BPF, progfd);
/
/
progfd为bpf(BPF_PROG_LOAD)后的返回值
|
这是第一次遇到perf_event_open这个系统调用,本文实现的dwarf的用户态栈回溯正是基于这个系统调用。
如果失败了则使用ftrace进行attach:
将attach字符串写入文件/sys/kernel/debug/tracing/kprobe_events即可。
bpf程序的执行与数据获取:
hello_perf_output.py程序的hello函数中的`events.perf_submit(ctx, &data, sizeof(data));
已经被替换成了如下函数:bpf_perf_event_output(ctx, bpf_pseudo_fd(1, -1), CUR_CPU_IDENTIFIER, &data, sizeof(data));
bpf_perf_event_output第二个参数类型为struct bpf_map *map,而上面为bpf_pseudo_fd(1, -1),可以看到生成的bpf程序的字节码:; bpf_perf_event_output(ctx, bpf_pseudo_fd(1, -1), CUR_CPU_IDENTIFIER, &data, sizeof(data)); // Line 35 14: 18 12 00 00 ff ff ff ff 00 00 00 00 00 00 00 00 ld_pseudo r2, 1, 4294967295
其实上BPFModule::load_maps函数中会对涉及到bpf_pseudo_fd(1, -1)形式的指令进行改写,将这个指令的立即数改写成events所对应的bpf maps文件描述符,也就是上面的bpf_map_fd。
为什么bpf_perf_event_output第二个参数是struct bpf_map *map,但是调用它的时候传递的却是文件描述符呢,事实上在加载bpf程序的时候内核的verifier.c会调用replace_map_fd_with_map_ptr将bpf_map_fd映射为bpf_map *。
上面虽然调用了int bpf_map_fd = bpf(BPF_MAP_CREATE, &attr, sizeof(attr));创建出了一个BPF_MAP_TYPE_PERF_EVENT_ARRAY类型的bpf maps,但是这个maps并没有关联实际的perf存储,因此还无法往其中写入数据,需要用户空间调用perf_event_open()函数,将perf和bpf maps关联才行,我们在代码中看这是如何做的:
看一下python程序中的这一句:b["events"].open_perf_buffer(print_event)
它做的事情如下:
- 根据"events"名称找到events所对应的bpf_map_fd,创建出PerfEventArray对象并且调用它的open_perf_buffer函数,print_event是用于接收数据的回调。
- PerfEventArray对象的open_perf_buffer函数会针对每个在线的cpu都调用perf_event_open系统调用创建针对该cpu的perf_event:
可以看到perf_event_open是个相当复杂的系统调用,有很多的参数配置。1234567struct perf_event_attr attr={};attr.config=10;//PERF_COUNT_SW_BPF_OUTPUT;attr.type=PERF_TYPE_SOFTWARE;attr.sample_type=PERF_SAMPLE_RAW;attr.sample_period=1;attr.wakeup_events=opts->wakeup_events;pfd=syscall(__NR_perf_event_open, &attr, pid, cpu,-1, PERF_FLAG_FD_CLOEXEC); - 调用mmap将pfd映射到当前用户空间,用于和内核通信,读取内核发送的perf记录。
- ioctl(pfd, PERF_EVENT_IOC_ENABLE, 0)启用事件。
- 回到table.py的_open_perf_buffer函数中调用:
self[self.Key(cpu)] = self.Leaf(fd)将所有的perf_event与bpf maps关联.这一步的原理其实是调用了bpf(BPF_MAP_UPDATE_ELEM)更新bpf maps中的键值对,键为cpu的下标,值为perf_event_open系统调用的返回值。
bpf maps和perf_event关联以后,当clone系统调用被调用时,bpf程序会调用helper函数bpf_perf_event_output,往bpf maps所关联的perf_event中写数据,bcc会通过读取之前mmap的perf内存获取这些数据,调用python端的回调函数print_event从而打印出ebpf程序发送的数据。
下面来看一下perf_event_open系统调用,perf_event_open的配置是相当复杂的,返回的信息也是五花八门。
一开始这只是一个性能监测所使用的系统调用,现代的cpu都有被称为PMU(performance monitoring unit )的硬件模块,PMU有几个硬件计数器,用于给诸如以下的事件计数:cpu运转了多少个时钟周期,执行了多少指令以及有多少缓存丢失等等。
Linux内核将这些硬件计数器包装成了硬件perf events, 同时也有和硬件无关的软件perf events,后来软件perf events越来越多,比如和bpf相关的软件perf events为PERF_COUNT_SW_BPF_OUTPUT。
perf事件有两种模式:计数和采样,配置了sample_period就是采样模式:
|
1
2
3
4
|
static inline
bool
is_sampling_event(struct perf_event
*
event)
{
return
event
-
>attr.sample_period !
=
0
;
}
|
在采样模式下每达到一定的采样数量会将事件相关信息写入内核和用户空间共享的环形缓冲区中,而用户空间则通过mmap来读取这些数据。
上面可以看到不仅attach ebpf程序的时候可以通过perf_event_open(被称为perf_kprobe PMU),ebpf程序和用户空间程序进行通信也可以使用它,而且效率很高,也是bcc推荐的通信方式。
四.trace.py的栈打印
trace.py会自动根据传入的参数帮我们生成一个bpf程序:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
#include <linux/ptrace.h>
#include <linux/sched.h> /* For TASK_COMM_LEN */
struct probe_do_sys_open_1_data_t
{
u32 tgid;
u32 pid;
char comm[TASK_COMM_LEN];
char v0[
80
];
int
user_stack_id;
u32 uid;
};
BPF_PERF_OUTPUT(probe_do_sys_open_1_events);
BPF_STACK_TRACE(probe_do_sys_open_1_stacks,
1024
);
int
probe_do_sys_open_1(struct pt_regs
*
ctx)
{
u64 __pid_tgid
=
bpf_get_current_pid_tgid();
u32 __tgid
=
__pid_tgid >>
32
;
u32 __pid
=
__pid_tgid;
/
/
implicit cast to u32
for
bottom half
u32 __uid
=
bpf_get_current_uid_gid();
if
(__tgid
=
=
22803
) {
return
0
; }
if
(__uid !
=
10121
) {
return
0
; }
if
(!(
1
))
return
0
;
struct probe_do_sys_open_1_data_t __data
=
{
0
};
__data.tgid
=
__tgid;
__data.pid
=
__pid;
__data.uid
=
__uid;
bpf_get_current_comm(&__data.comm, sizeof(__data.comm));
if
(PT_REGS_PARM2(ctx) !
=
0
) {
void
*
__tmp
=
(void
*
)PT_REGS_PARM2(ctx);
bpf_probe_read_user(&__data.v0, sizeof(__data.v0), __tmp);
}
__data.user_stack_id
=
probe_do_sys_open_1_stacks.get_stackid(
ctx, BPF_F_USER_STACK
);
probe_do_sys_open_1_events.perf_submit(ctx, &__data, sizeof(__data));
return
0
;
}
|
经过处理以后
|
1
2
|
__data.user_stack_id
=
probe_do_sys_open_1_stacks.get_stackid(ctx, BPF_F_USER_STACK);
probe_do_sys_open_1_events.perf_submit(ctx, &__data, sizeof(__data));
|
变为:
|
1
2
|
__data.user_stack_id
=
bpf_get_stackid(ctx,bpf_pseudo_fd(
1
,
-
2
), BPF_F_USER_STACK);
bpf_perf_event_output(ctx, bpf_pseudo_fd(
1
,
-
1
), CUR_CPU_IDENTIFIER, &__data, sizeof(__data));
|
其中bpf_perf_event_output和hello_perf_output.py的流程一样就不再赘述了,这里还多了一个bpf_get_stackid()函数,它也是一个bpf helper函数。
来看一下上面的程序的这一句:BPF_STACK_TRACE(probe_do_sys_open_1_stacks, 1024);BPF_STACK_TRACE这个宏同样的定义在src/cc/export/helpers.h文件中,它被扩展为:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
struct probe_do_sys_open_1_stacks_table_t {
int
key;
struct bpf_stacktrace leaf;
struct bpf_stacktrace
*
(
*
lookup) (
int
*
);
struct bpf_stacktrace
*
(
*
lookup_or_init) (
int
*
, struct bpf_stacktrace
*
);
struct bpf_stacktrace
*
(
*
lookup_or_try_init) (
int
*
, struct bpf_stacktrace
*
);
int
(
*
update) (
int
*
, struct bpf_stacktrace
*
);
int
(
*
insert) (
int
*
, struct bpf_stacktrace
*
);
int
(
*
delete) (
int
*
);
void (
*
call) (void
*
,
int
index);
void (
*
increment) (
int
, ...);
void (
*
atomic_increment) (_key_inttype, ...);
int
(
*
get_stackid) (void
*
, u64);
void
*
(
*
sk_storage_get) (void
*
, void
*
,
int
);
int
(
*
sk_storage_delete) (void
*
);
void
*
(
*
inode_storage_get) (void
*
, void
*
,
int
);
int
(
*
inode_storage_delete) (void
*
);
void
*
(
*
task_storage_get) (void
*
, void
*
,
int
);
int
(
*
task_storage_delete) (void
*
);
u32 max_entries;
int
flags;
};
__attribute__((section(
"maps/stacktrace"
)))
struct probe_do_sys_open_1_stacks_table_t probe_do_sys_open_1_stacks
=
{ .flags
=
(
0
), .max_entries
=
(roundup_pow_of_two(
1024
)) };
struct ____btf_map_probe_do_sys_open_1_stacks {
int
key;
struct bpf_stacktrace value;
};
struct ____btf_map_probe_do_sys_open_1_stacks
__attribute__ ((section(
".maps.probe_do_sys_open_1_stacks"
), used))
____btf_map_probe_do_sys_open_1_stacks
=
{ }
|
当BFrontendAction在处理ast的时候扫描到编译属性__attribute__((section("maps/stacktrace")))时,就会创建出类型为BPF_MAP_TYPE_STACK_TRACE的bpf maps,这个maps的key大小为probe_do_sys_open_1_stacks_table_t结构的key大小int,value大小为probe_do_sys_open_1_stacks_table_t结构的leaf大小struct bpf_stacktrace。
struct bpf_stacktrace结构定义为:
|
1
2
3
|
struct bpf_stacktrace {
u64 ip[BPF_MAX_STACK_DEPTH];
};
|
可以看到它其实就是个u64数组,事实上每一个u64都对应着一个调用栈的pc指针,bcc就是靠这个数据来进行栈回溯的。
当ebpf程序执行的时候,它会通过bpf_perf_event_output()往用户空间输出bpf_get_stackid()的返回值long stack_id,用户空间程序拿到这个stack_id以后把它作为bpf maps中的key,调用bpf(BPF_MAP_LOOKUP_ELEM)得到类型为struct bpf_stacktrace结构的调用栈数据,然后bcc就可以按照自己的方式进行符号化了。具体的代码在table.py的class StackTrace类中。
打印调用栈的逻辑为:
|
1
2
3
4
5
6
|
for
addr
in
stack:
stackstr
+
=
' '
if
Probe.print_address:
stackstr
+
=
(
"%16x "
%
addr)
symstr
=
bpf.sym(addr, tgid, show_module
=
True
, show_offset
=
True
)
stackstr
+
=
(
'%s\n'
%
(symstr.decode(
'utf-8'
)))
|
其中addr就是通过stack_id调用bpf(BPF_MAP_LOOKUP_ELEM)得到的地址列表。
bpf_get_stackid()是怎么实现的?直接给出结论:通过基于fp的栈回溯来实现的,感兴趣的话可以查看一下内核的perf_callchain_user函数,这里就不细述了。
到这里,上面使用trace.py打印出程序的堆栈信息缺失的原因就揭晓了,基于fp的栈回溯虽然比较快,但是编译时如果指定了"-fomit-frame-pointer"就不会生成fp指针,堆栈信息就会缺失.如果用bcc分析某些大厂app,很多调用除了第一行以外其他全是unknown。
而对于func_a调用的堆栈信息符号化缺失是因为bcc它的符号化是读取/proc/pid/maps并解析其中的so的elf符号表来实现的,由于zipalign的原因:
如果apk中所有未归档文件相对于文件开头是对齐的,那么so文件就不会被解压至/data/app目录下,而是直接在apk文件中进行mmap。
bcc对apk的支持不好,所以无法正确处理这种情况.而且bcc读取/proc/pid/maps只读取一次,除非整个可执行文件被替换不然bcc不会重新读取/proc/pid/maps,这也就导致了无法更新到后加载的so的情况。
五.问题的解决
在bcc的issue列表中其实已经有人提了这样的问题:
上面提到了一个工具simpleperf
trace.py无法打印的,simpleperf却可以,这是因为simpleperf是基于dwarf的.eh_frame节进行栈回溯的, 就算so编译的时候指定了"-fomit-frame-pointer"也能正确打印出堆栈信息.那么如果将simpleperf的栈回溯机制和bcc结合不就可以解决问题了吗?
先来看一下simpleperf的使用:
simpleperf是android提供的性能分析工具,它也是通过调用perf_event_open来实现的,假设我们想追踪4665这个进程的sys_enter_clone系统调用.我们在手机上这么执行持续10秒采样:
|
1
|
$ simpleperf record
-
p
4665
-
-
call
-
graph dwarf
-
e syscalls:sys_enter_clone
-
-
duration
10
-
o
/
data
/
local
/
tmp
/
perf.data
|
然后将/data/local/tmp/perf.data拷贝至aosp/system/extras/simpleperf/scripts目录下,执行report_sample.py即可看到期间的所有sys_enter_clone调用以及堆栈。
虽然simpleperf有时用来做逆向分析的备用工具来使用也凑合,但是它最大的缺陷是无法打印出系统调用的参数,更无法采用一些hack的技巧来修改系统调用参数,而ebpf是可以直接执行定制化代码的,因此如果bcc可以结合simpleperf的栈回溯机制将是完美的组合。
从bcc的官方开发人员的回复来看,短时间内应该不会有基于dwarf的官方实现.而且安卓运行环境比较特殊,感觉bcc更多的是面向linux pc领域,只能自己来动手了。
首先我们需要理解一下simpleperf的原理,对于上面的命令来说,simpleperf其实是构建了以下的perf_event_attr:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
struct perf_event_attr attr;
attr.size
=
sizeof(perf_event_attr);
attr.
type
=
PERF_TYPE_TRACEPOINT;
attr.config
=
id
;
/
/
cat
/
sys
/
kernel
/
debug
/
tracing
/
events
/
syscalls
/
sys_enter_openat
/
id
attr.disabled
=
0
;
attr.read_format
=
PERF_FORMAT_TOTAL_TIME_ENABLED | PERF_FORMAT_TOTAL_TIME_RUNNING | PERF_FORMAT_ID;
attr.sample_type |
=
PERF_SAMPLE_IP | PERF_SAMPLE_TID | PERF_SAMPLE_TIME | PERF_SAMPLE_PERIOD | PERF_SAMPLE_CPU | PERF_SAMPLE_ID | PERF_SAMPLE_RAW;
attr.sample_type |
=
PERF_SAMPLE_CALLCHAIN | PERF_SAMPLE_REGS_USER | PERF_SAMPLE_STACK_USER;
attr.sample_type &
=
~PERF_SAMPLE_BRANCH_STACK;
attr.exclude_callchain_user
=
1
;
attr.sample_regs_user
=
((
1ULL
<< PERF_REG_ARM64_MAX)
-
1
);
attr.sample_stack_user
=
65528
;
attr.inherit
=
0
;
attr.sample_id_all
=
1
;
/
/
SampleIdAll
attr.freq
=
0
;
attr.sample_period
=
DEFAULT_SAMPLE_PERIOD_FOR_TRACEPOINT_EVENT;
/
/
1
attr.mmap
=
1
;
attr.comm
=
1
;
|
可以看到attr.sample_type指定的类型非常多,其中最重要的类型为PERF_SAMPLE_REGS_USER | PERF_SAMPLE_STACK_USER
看一下perf对dwarf栈回溯支持的提交文件:
[]
PERF_SAMPLE_REGS_USER用于指示内核将用户空间发生事件时(这里为系统调用)的寄存器信息以PERF_RECORD_SAMPLE记录类型传送给用户空间。PERF_SAMPLE_STACK_USER用于指示内核将用户空间发生事件时(这里为系统调用)的栈空间片段数据以PERF_RECORD_SAMPLE记录类型传送给用户空间。
simpleperf有了这两个信息以后再加上一个目标进程的maps信息即可指示libunwindstack库进行dwarf的栈回溯:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
UnwindMaps& cached_map
=
cached_maps_[thread.pid];
cached_map.UpdateMaps(
*
thread.maps);
std::shared_ptr<unwindstack::MemoryOfflineBuffer> stack_memory(
new unwindstack::MemoryOfflineBuffer(reinterpret_cast<const uint8_t
*
>(stack),
stack_addr, stack_addr
+
stack_size));
std::unique_ptr<unwindstack::Regs> unwind_regs(GetBacktraceRegs(regs));
if
(!unwind_regs) {
return
false;
}
unwindstack::Unwinder unwinder(MAX_UNWINDING_FRAMES, &cached_map, unwind_regs.get(),
stack_memory);
unwinder.SetResolveNames(false);
unwinder.Unwind();
|
libunwindstack库是谷歌自己开发的栈回溯库,它提供了强大的功能:
支持ARM32,ARM64,X86,X86_64,MIPS,MIPS_64,可以关联ART虚拟机OAT,Jit调试产生的native栈等。
总结起来就是simpleperf拿到目标进程的寄存器信息,栈空间片段数据以及maps信息即可调用libunwindstack库进行dwarf的栈回溯。
libunwindstack库基于gtest写了一些测试用例位于system/core/libunwindstack/tests目录下,阅读这些测试用例可以很好的理解libunwindstack库的api,可以执行如下命令来运行测试用例:
|
1
|
$ atest
-
bt libunwindstack_test
|
既然知道simpleperf的原理,那么如果bcc程序也可以得到寄存器信息和栈空间片段数据,不就一样可以调用libunwindstack库进行dwarf的栈回溯了吗?
事实上还需要解决以下问题:
- 如何和现有的bcc框架集成
- 有没有现有的bpf helper函数可以实现这一目标
- bcc运行环境是debian,如何访问android环境下的libunwindstack库
bcc的开发者在issue列表中提议也许可以通过bpf_probe_read_user调用获取用户栈数据,但是由于ebpf的执行栈只有512字节,获取了用户栈数据需要保存在栈上的变量中(4.16之前的内核),而很多程序的调用栈远远不止512字节,因此我认为这种方式不太好。
我这里的解决方案为:
通过观察bpf_perf_event_output函数的实现可以发现,在它调用的perf_output_sample函数中只要sample_type的PERF_SAMPLE_REGS_USER位被设置,就会发送寄存器数据,只要sample_type的PERF_SAMPLE_STACK_USER位被设置,就会发送用户空间栈数据。
因此只需在bcc程序中调用perf_event_open的时候设置相应的标记即可。不过由于bcc程序没有针对这两种类型数据做处理,因此需要修改读取函数的逻辑。
得到相应的数据以后,可以在android端启动一个进程专门获取bcc端发送的数据,这个进程然后调用libunwindstack库进行栈回溯,将结果再回传给bcc,两者通信可以采用unix domain socket。
为了控制何时打印堆栈,何时不打印堆栈,如果perf变量以_with_stack结尾则打印出堆栈信息:BPF_PERF_OUTPUT(events_with_stack);
在libbpf.c文件的bpf_open_perf_buffer_opts函数中判断如果需要打印堆栈,则修改perf调用参数:
|
1
2
3
4
5
6
7
|
if
(opts
-
>unwind_call_stack
=
=
1
) {
attr.sample_type |
=
PERF_SAMPLE_STACK_USER | PERF_SAMPLE_REGS_USER;
attr.sample_stack_user
=
16384
;
/
/
MAX
=
65528
attr.sample_regs_user
=
((
1ULL
<<
33
)
-
1
);
attr.size
=
sizeof(struct perf_event_attr);
reader
-
>is_unwind_call_stack
=
true;
}
|
接着在perf_reader.c的parse_sw函数中解析获取到的寄存器信息与栈数据:
|
1
2
3
4
5
|
if
(reader
-
>is_unwind_call_stack) {
int
pid
=
*
(
int
*
)raw
-
>data;
int
write_size
=
((uint8_t
*
)data
+
size)
-
ptr;
print_frame_info(pid, ptr, write_size);
}
|
perf的PERF_RECORD_SAMPLE类型的记录是可变结构,对于这里来说它的结构为:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
struct {
struct perf_event_header header;
u32 size;
/
*
if
PERF_SAMPLE_RAW
*
/
char data[size];
/
*
if
PERF_SAMPLE_RAW
*
/
u64 abi;
/
*
if
PERF_SAMPLE_REGS_USER
*
/
u64 regs[weight(mask)];
/
*
if
PERF_SAMPLE_REGS_USER
*
/
u64 size;
/
*
if
PERF_SAMPLE_STACK_USER
*
/
char data[size];
/
*
if
PERF_SAMPLE_STACK_USER
*
/
u64 dyn_size;
/
*
if
PERF_SAMPLE_STACK_USER &&
size !
=
0
*
/
};
|
本来是想在记录中请求PERF_SAMPLE_TID信息用于获取目标进程的/proc/pid/maps文件,但得到的数据总是不正确的,看了一个内核代码,应该和perf_prepare_sample函数并没有处理PERF_SAMPLE_TID相关的逻辑有关,不过从ebpf程序中可以直接得到pid,pid的值为:bpf_get_current_pid_tgid() >> 32;
获取到的信息全部通过unix domaian socket发送给远端android端守护进程,由守护进程解析出信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
static void print_frame_info(
int
pid, uint8_t
*
ptr,
int
write_size) {
int
fd
=
socket(PF_UNIX, SOCK_STREAM | SOCK_CLOEXEC,
0
);
if
(fd
=
=
-
1
) {
fprintf(stderr,
"cannot socket()!\n"
);
}
const char
*
socket_path
=
"/dev/socket/mysock"
;
struct sockaddr_un addr
=
{.sun_family
=
AF_UNIX};
strncpy(addr.sun_path, socket_path, sizeof(addr.sun_path));
int
ret
=
connect(fd, (struct sockaddr
*
)(&addr), sizeof(addr));
if
(ret !
=
0
) {
fprintf(stderr,
"connect() to %s failed: %s\n"
, socket_path,
strerror(errno));
}
else
{
WriteFully(fd, &pid,
4
);
write_size
+
=
4
;
WriteFully(fd, &write_size,
4
);
if
(!WriteFully(fd, ptr, write_size)) {
/
/
fprintf(stderr,
"All data were send.\n"
);
fprintf(stderr,
"prepare to write %d to socket\n"
, write_size);
close(fd);
return
;
}
int
frameinfo_size;
if
(ReadFully(fd, &frameinfo_size,
4
)) {
unsigned char frame_info[frameinfo_size
+
1
];
if
(ReadFully(fd, frame_info, frameinfo_size)) {
frame_info[frameinfo_size]
=
'\0'
;
printf(
"===================================>Frame:\n"
);
printf(
"%s\n"
, frame_info);
}
else
{
fprintf(stderr,
"Read frame_info from socket error.\n"
);
}
}
else
{
fprintf(stderr,
"Read frameinfo_size from socket error. \n"
);
}
close(fd);
}
}
|
Android端守护进程获取数据以后组装起来调用libunwindstack打印:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
bool
OfflineUnwinder::UnwindCallChain(DataBuff &buff, std::string &frame_info) {
RegSet regs(buff.mRegs.abi, buff.mRegs.reg_mask, buff.mRegs.regs);
uint64_t sp_reg_value;
if
(!regs.GetSpRegValue(&sp_reg_value)) {
std::cerr <<
"can't get sp reg value"
<< std::endl;
return
false;
}
else
{
#ifdef DEBUG
std::cout <<
"sp_reg_value: 0x"
<< std::
hex
<< sp_reg_value << std::endl;
#endif
}
uint64_t stack_addr
=
sp_reg_value;
const char
*
stack
=
buff.mStack.data;
size_t stack_size
=
buff.mStack.dyn_size;
std::shared_ptr<unwindstack::MemoryOfflineBuffer> stack_memory(
new unwindstack::MemoryOfflineBuffer(reinterpret_cast<const uint8_t
*
>(stack),
stack_addr, stack_addr
+
stack_size));
std::unique_ptr<unwindstack::Regs> unwind_regs(GetBacktraceRegs(regs));
if
(!unwind_regs) {
return
false;
}
std::unique_ptr<unwindstack::Maps> maps;
std::string data;
std::string proc_map_file
=
"/proc/"
+
std::to_string(buff.mTargetPid)
+
"/maps"
;
android::base::ReadFileToString(proc_map_file, &data);
maps.reset(new unwindstack::BufferMaps(data.c_str()));
maps
-
>Parse();
unwindstack::Unwinder unwinder(
512
, maps.get(), unwind_regs.get(), stack_memory);
/
/
unwinder.SetResolveNames(false);
unwinder.Unwind();
frame_info
=
DumpFrames(unwinder);
return
true;
}
|
然后android端守护进程会将得到的打印栈信息通过socket传送给bcc。
程序好了,试一下效果吧,先看看测试程序(已经指定了-fomit-frame-pointer)的堆栈打印:

可以看到,非常的完美。
再来看一下修改bcc的tcpconnect.py对某大厂app分析的结果:
将tcpconnect.py中的ipv4_events修改为ipv4_events_with_stack,ipv6_events修改为ipv6_events_with_stack表示需要打印堆栈。
然后app看看效果:python3 tcpconnect.py -u 10112
可以看到打印出的堆栈信息:
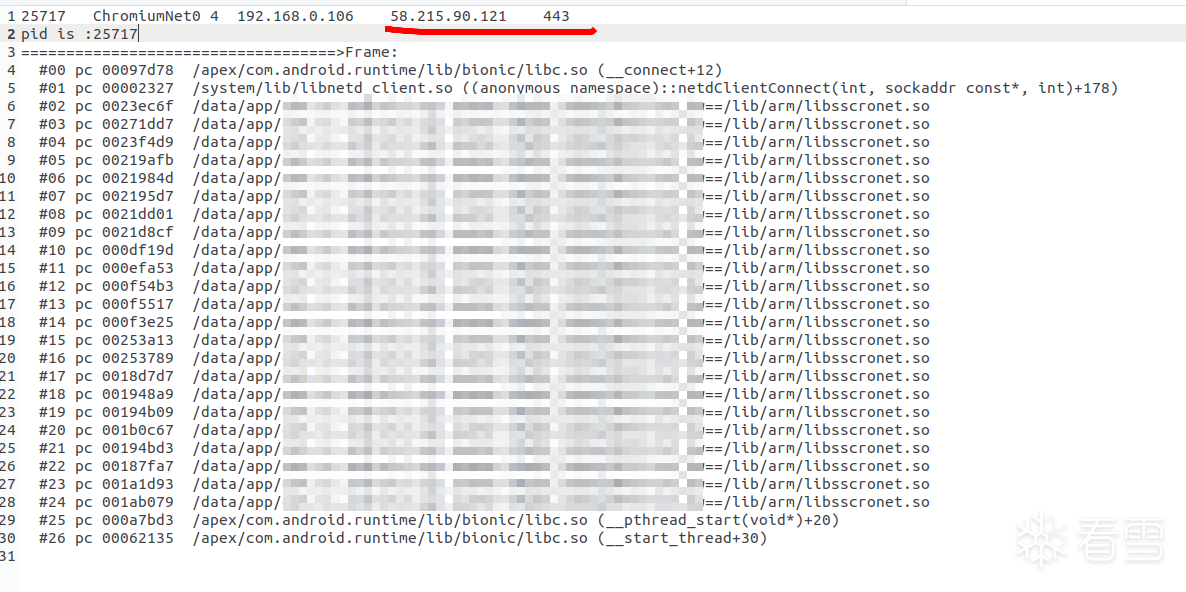
不仅能显示出堆栈偏移量,而且能打印出连接的ip地址和端口号:-)
那么可以将so中的.eh_frame节移除掉吗,这个节会在运行时加载,c++语言中的异常是靠它来实现的,如果移除掉,涉及到C++异常代码的时候程序直接就崩溃了,而且app的crash收集也靠它,所以基于.eh_frame节的栈回溯目前来是个比较可靠的方案。
更多【定制bcc/ebpf在android平台上实现基于dwarf的用户态栈回溯】相关视频教程:www.yxfzedu.com
相关文章推荐
- CTF对抗-Java安全小白的入门心得 - 初见RMI协议 - 游戏基址 二进制漏洞 密码应用 智能设备
- 编程技术-这个崩溃有点意思,你中过招吗 - 游戏基址 二进制漏洞 密码应用 智能设备
- 软件逆向-PE头解析-字段说明 - 游戏基址 二进制漏洞 密码应用 智能设备
- 软件逆向-PE加载过程 FileBuffer-ImageBuffer - 游戏基址 二进制漏洞 密码应用 智能设备
- 加壳脱壳-进程 Dump & PE unpacking & IAT 修复 - Windows 篇 - 游戏基址 二进制漏洞 密码应用 智能设备
- CTF对抗-第五空间 crackme深度分析 - 游戏基址 二进制漏洞 密码应用 智能设备
- Pwn-DAS9月月赛PWN题出题心路 - 游戏基址 二进制漏洞 密码应用 智能设备
- CTF对抗-CSAW-CTF-Web部分题目 - 游戏基址 二进制漏洞 密码应用 智能设备
- CTF对抗-2022MT-CTF Re - 游戏基址 二进制漏洞 密码应用 智能设备
- 编程技术-逆向IoRegisterPlugPlayNotification获取即插即用回调地址,配图加注释超级详细 - 游戏基址 二进制漏洞 密码应用 智能设备
- 软件逆向-针对百度旗下的一个会议软件,简单研究其CEF框架 - 游戏基址 二进制漏洞 密码应用 智能设备
- Android安全-逆向篇三:解决Flutter应用不能点击问题 - 游戏基址 二进制漏洞 密码应用 智能设备
- Android安全-Android - 系统级源码调试 - 游戏基址 二进制漏洞 密码应用 智能设备
- Android安全-逆向分析某软件sign算法 - 游戏基址 二进制漏洞 密码应用 智能设备
- 软件逆向-APT 双尾蝎样本分析 - 游戏基址 二进制漏洞 密码应用 智能设备
- 编程技术-利用GET请求从微软符号服务器下载PDB - 游戏基址 二进制漏洞 密码应用 智能设备
- 编程技术-NtSocket的稳定实现,Client与Server的简单封装,以及SocketAsyncSelect的一种APC实现 - 游戏基址 二进制漏洞 密码应用 智能设备
- 软件逆向-wibu证书 - asn1码流 - 游戏基址 二进制漏洞 密码应用 智能设备
- 软件逆向-关于USB管控的方案,某某USB管控逆向分析 - 游戏基址 二进制漏洞 密码应用 智能设备
- 编程技术-谁会不喜欢一个Windows内核键盘记录器呢(详解) - 游戏基址 二进制漏洞 密码应用 智能设备
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- Pwn-沙箱逃逸之0ctf2020 chromium_rce writeup
- 二进制漏洞-CVE-2017-5754 Meltdown 复现
- 软件逆向-反硬件断点检测附源码
- 编程技术- COM 进程注入技术
- CTF对抗-Realworld CTF 2023 The_cult_of_8_bit详解
- Android安全-通过DVM指令还原壳的抽空类
- CTF对抗-HGame Week1 Reverse WriteUp
- 加壳脱壳- 记录一下从编译的角度还原VMP的思路
- Android安全- 安卓协议逆向 cxdx 分析与实现
- Android安全-HoneyBadger系列二 Android App全量监控也来了

接各种驱动定制如:游戏读写驱动,软件内存保护,防止调试等功能定制。
出租读写驱动,调试驱动,无痕注入支持各种游戏。
邮箱:service@yxfzedu.com
QQ:851920120
特别说明:不接游戏数据分析,外挂编写,登陆协议等类似业务。