r语言-42 ajax 下载文件未配置 responseType blob 导致的文件异常
推荐 原创文章分类 其他 r语言 前端 ajax javascript ecmascript 阅读数 : 209 阅读时长 : 9分钟
前言
这是一个最近的关于文件下载碰到的一个问题
主要的情况是, 基于 xhr 发送请求, 获取下载的文件
然后 之后 xhr 这边拿到 字节序列之后, 封装 blob 来进行下载
然后 最开始我们这边没有配置 responseType 为 blob, arraybuffer, 然后 导致下载出来的 文件大小超过了一倍,m 并且解压出现了问题
然后 增加了 responseType 配置为 blob 之后, 文件下载的功能就正常了
这里来大致看一下 大体的一个情况, 因为 xhr 这边具体的 编码 response, responseText, responseXml 的代码查看不了, 因此看不到 字节序列 转换为 字符串的过程, 因此 这里的结论仅仅是一个 大致的推导
另外 js 这边 new Blob 的具体的代码 也是查看不了, 因此 查看不了 字符串 转换为 字节序列 的这个过程
测试用例
客户端这边发送请求的 demo 代码如下
ajax({
method: 'post',
url: '/xxx/file/batchDownload',
data: data,
// responseType: 'arraybuffer'
}).then(res => {
let blob = new Blob([res], {type: "application/zip"});
const link = document.createElement("a");
link.download = 'file.zip';
link.style.display = "none";
link.href = URL.createObjectURL(blob);
document.body.appendChild(link);
link.click();
URL.revokeObjectURL(link.href);
document.body.removeChild(link);
}).finally(() => {
this.setdownLoading(row, false)
})
正常的情况
如下是一个列表展示, 原始正确的 zip 文件大小为 811667 字节
// 原始文件大小
blob
811667
// 原始字节序列 使用给定的编码编码为字符序列, 然后再使用相同的编码解码为字节序列
new String(baos.toByteArray(), $charset).getBytes($charset)
gbk : 810632
utf8 : 1475674
// 前端 xhr 代码中不配置 responseType 为 arraybuffer/blob 的情况
xhr, without responseType blob, new Blob([res], {type: "application/zip"});
1476964
服务器这边响应的正常的 zip 文件大小如下, 是正确的, 可以正常打开
然后 我们看一下 正常的情况, 即 ajax 增加 responseType 为 blob/arraybuffer 的情况
这里是 axios 中的基于 xhr 的一个适配器, 这里是具体的基于 XmlHttpRequest 发送请求的地方
我们可以看到 response 为 blob, 然后 字节数为 811667 拿到的是正常的数据
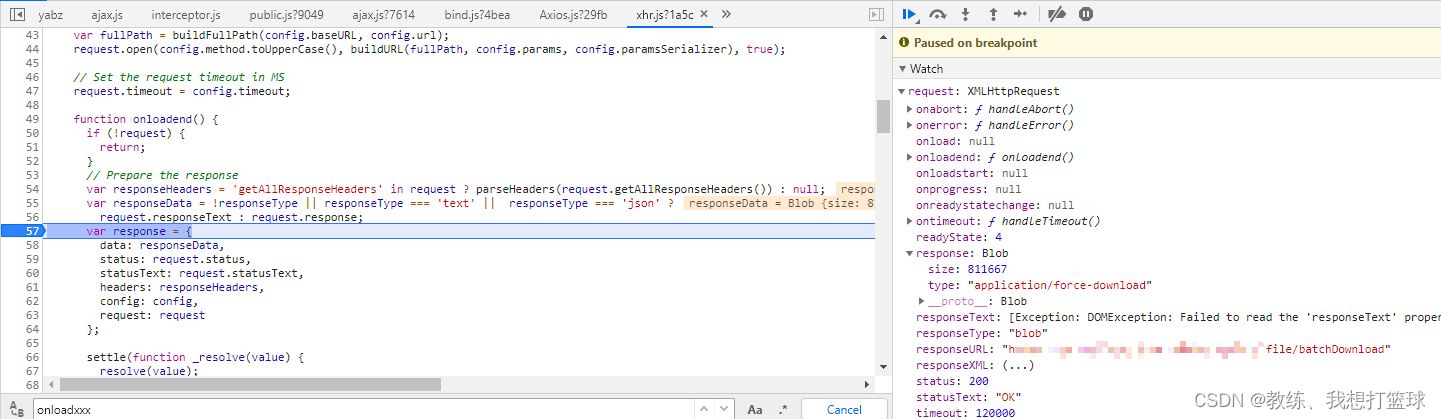
然后 进而再外层 业务 handle 处理的时候 也是拿到的正确的数据
然后 最终下载的压缩包, 正常

异常的情况
然后 这里可以看到的是 responseData 是一个字符串, 说明 他已经被转换过了
因为 服务器那边传输的是原始的字节序列, 然后 这里被转换过了之后 可能会造成 字节序列 的数据丢失, 错误
可以看到 这里数据大小是 1.5M 大概是原始数据的两倍, 字节转字符的编码可能是 gbk 或者 utf8

然后 业务这边再根据 字符串传唤为字节序列, 存放到 blob, 拿到的也是一个错误的数据
可以看到这里数据量大小为 1476944 和上面表格统计的大小基本一致, 之所以说基本一致, 是因为多次下载 会有少许不同, 大小差距在 20字节左右

所以 综上问题就在于在这个 字节序列 转 字符序列 再转 字节序列 的过程中造成了数据的错误
这个过程 会经过两次字符编码体系的处理
- 如果这两次都是 相同的单字节编码, 那么不会出现问题
- 如果是两次都是 相同的多字节编码 则可能存在问题, 因为 目标字节序列 可能未必复合目标编码的格式约束, 然后 造成了数据的不可逆丢失
- 如果是两次是 不同的编码, 并且存在兼容的 codepoint, 而且 字节序列 中的数据均在这些兼容的 codepoint 范围内, 则不会出现问题, 否则 会出现数据错误
但是 目标字节序列, 是 zip 格式, 任何一个字节的错误 都可能造成整体文件 不符合 zip 的规范, 或者 最开始 验签的时候 就校验不通过
字节序列 使用 utf8编码转换为字符串, 然后再依据utf8编码转换为字节序列, 数据会不会丢失?
// 原始文件大小
blob
811667
// 原始字节序列 使用给定的编码编码为字符序列, 然后再使用相同的编码解码为字节序列
new String(baos.toByteArray(), $charset).getBytes($charset)
gbk : 810632
utf8 : 1475674
这里我们先来看下 这里例子中的文件的情况, 这里就解释了 不配置 responseType 为 arraybuffer/blob 的情况下下载出来的数据是错误的问题
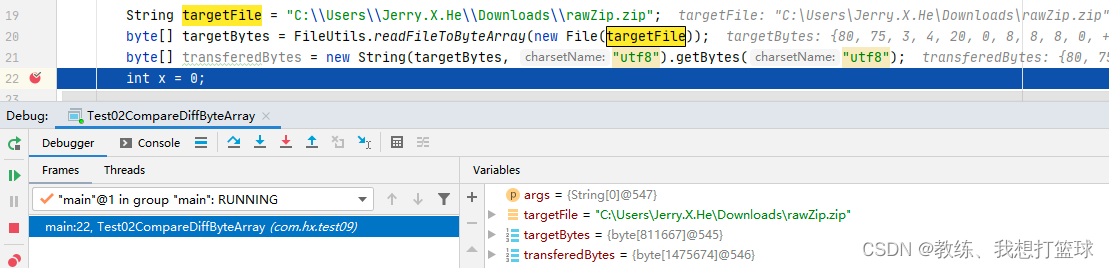
使用 utf8 的时候, 整个过程最终结果的字节序列长度为 1475674
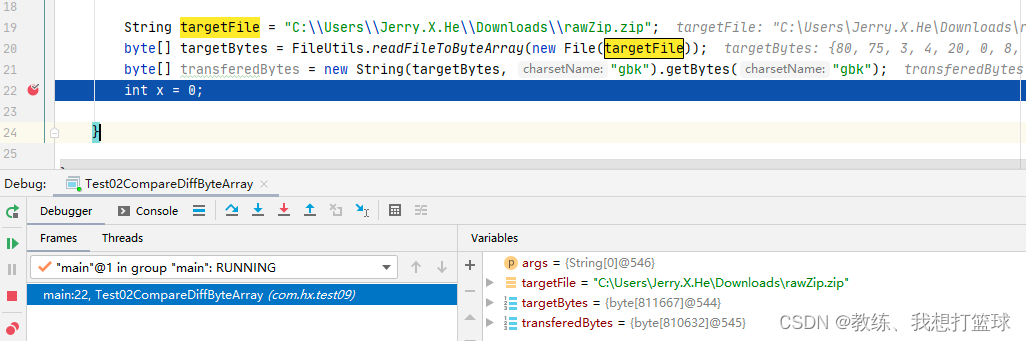
使用 gbk 的时候, 整个过程最终结果的字节序列长度为 810632
然后 我们这里来看拿一下 上面的转换之后, 什么情况下 数据会丢失? 什么情况下 数据不丢失?
如果 字节序列是满足 utf8 的编码规范, 则数据不会丢失, 否则 可能会有数据丢失
比如这里是原始字节序列 不满足 utf8 的编码规范, 然后 造成了数据的丢失, 原始 仅仅有 6 个字节, 转换之后却有 18 个字节, 并且 数据还存在错误
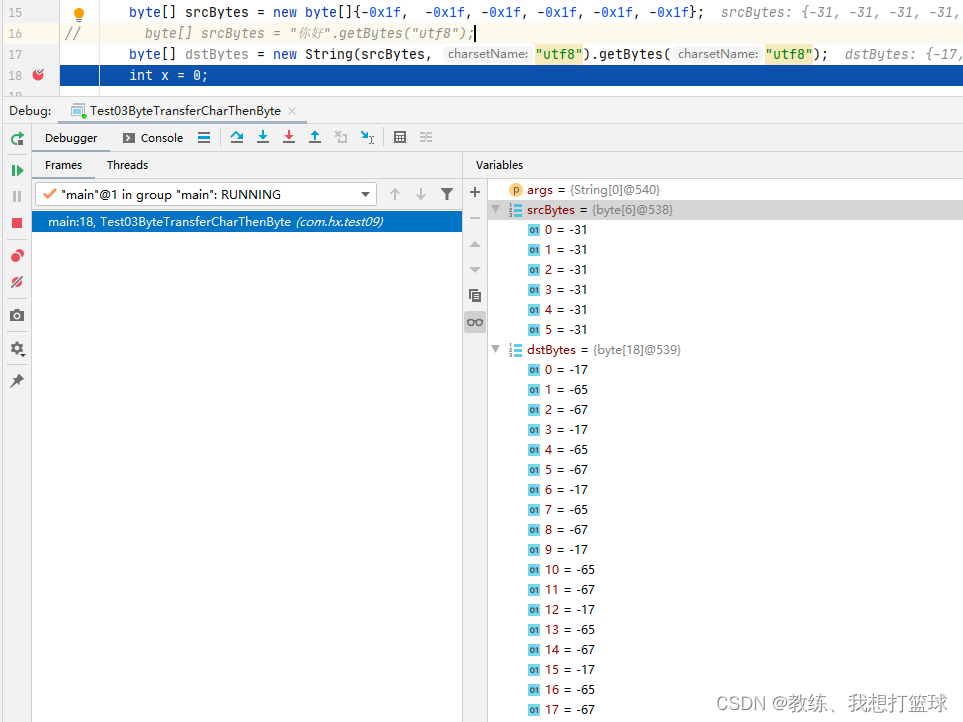
比如这里是原始字节序列 满足 utf8 的编码规范, 然后 可以看到的是 原始字节序列 和 目标字节序列 是相同的
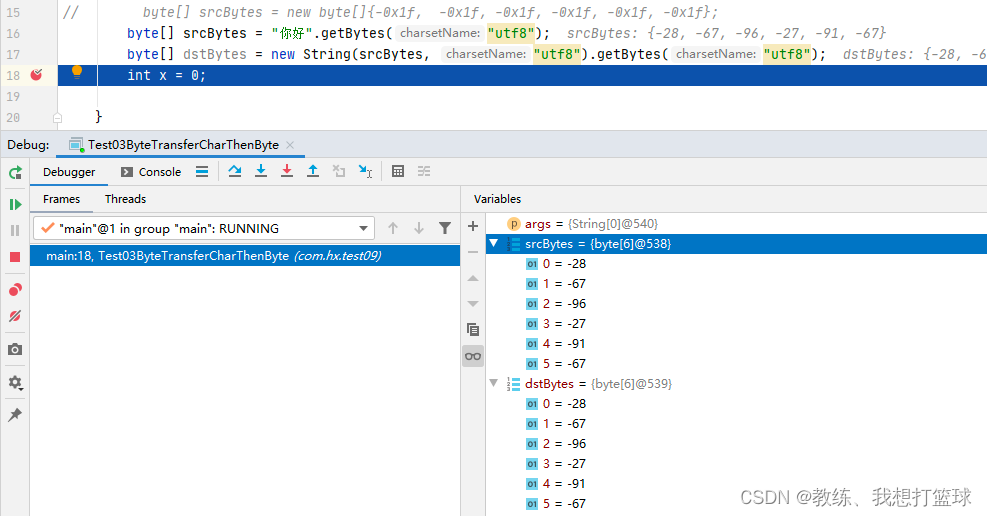
但是我们的目标文件是一个 zip 格式的二进制文件, 我们不能确保它的字节序列满足 固定的字符编码[假设浏览器这边是以 utf8 进行编码解码]
所以 如果是存在一个这个转换过程的话, 是可能存在 字节序列的数据的错误, 丢失
进而 导致 下载下来的文件, zip 解压缩软件 识别出错
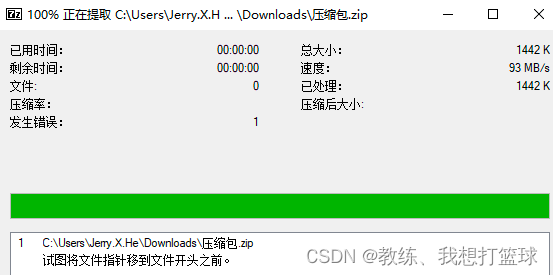
完
更多【r语言-42 ajax 下载文件未配置 responseType blob 导致的文件异常】相关视频教程:www.yxfzedu.com
相关文章推荐
- 人工智能-Adobe:受益于人工智能,必被人工智能反噬 - 其他
- asp.net-vue+asp.net Web api前后端分离项目发布部署 - 其他
- 编程技术-程序员怎样才能学好算法?这本书送几本给大家! - 其他
- node.js-Node.js如何处理多个请求? - 其他
- golang-【二、http】go的http基本请求设置(设置查询参数、定制请求头)get和post类似 - 其他
- 算法-平面和射线交点 - 其他
- 编程技术-从白日梦到现实:推出 Elastic 的管道查询语言 ES|QL - 其他
- 前端-Redisson实现延迟队列 - 其他
- 编程技术-MATLAB|怎么将散点图替换成图片 - 其他
- 科技-第二证券:消费电子概念活跃,博硕科技“20cm”涨停,天龙股份斩获10连板 - 其他
- 科技-思谋科技进博首秀:工业多模态大模型IndustryGPT V1.0正式发布 - 其他
- 科技-智能井盖传感器功能,万宾科技产品介绍 - 其他
- 科技-专访虚拟人科技:如何利用 3DCAT 实时云渲染打造元宇宙空间 - 其他
- 机器学习-Azure 机器学习 - 使用 ONNX 对来自 AutoML 的计算机视觉模型进行预测 - 其他
- 缓存-Redisson中的对象 - 其他
- 科技-伊朗黑客对以色列科技和教育领域发起破坏性网络攻击 - 其他
- 科技-SOLIDWORKS 2024新产品发布会暨SOLIDWORKS 创新日活动-硕迪科技 - 其他
- 科技-擎创动态 | 开箱即用!擎创科技联合中科可控推出大模型一体机 - 其他
- 科技-亚马逊云科技大语言模型下的六大创新应用功能 - 其他
- 科技-【亚马逊云科技产品测评】活动征文|亚马逊云科技AWS之EC2详细测评 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 算法-C现代方法(第19章)笔记——程序设计
- git-IntelliJ Idea 撤回git已经push的操作
- c#-html导出word
- excel-使用 AIGC ,ChatGPT 快速合并Excel工作薄
- 开发语言-怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载
- 编程技术-鲁大师电动车智能化测评报告第二十三期:实测续航95km,九号Q90兼顾个性与实用
- 数据库-进阶SQL——数据表中多列按照指定格式拼接,并将多行内容合并为map拼接
- 小程序-社区团购小程序系统源码+各种快递代收+社区便利店 带完整的搭建教程
- spring-Java之SpringCloud Alibaba【八】【Spring Cloud微服务Gateway整合sentinel限流】
- 云原生-云原生周刊:Gateway API 1.0.0 发布 | 2023.11.6
