学习-StarRocks学习笔记
推荐 原创介绍
StarRocks是一款经过业界检验、现代化,面向多种数据分析场景的、兼容MySQL协议的、高性能分布式关系型分析数据库。
StarRocks充分吸收关系型 OLAP 数据库和分布式存储系统在大数据时代的优秀研究成果,并在业界实践的基础上,进一步改进优化,架构升级和添加新功能,形成了全新的企业级产品。
StarRocks致力于满足企业用户的多种数据分析场景,支持多种数据模型(明细模型、聚合模型、更新模型、主键模型), 多种导入方式, 可整合和接入多种现有系统(Spark、Flink、Hive、ElasticSearch、Iceberg、Hudi等)。
StarRocks兼容MySQL协议,可使用MySQL客户端和常用BI工具对接StarRocks来进行数据分析。
StarRocks采用分布式架构,对table进行水平划分并以多副本存储。集群规模可以灵活伸缩,能够支持10PB级别的数据分析;支持MPP,并行加速计算;支持多副本,具有弹性容错能力。
StarRocks采用关系模型,使用严格的数据类型,使用列式存储引擎,通过编码和压缩技术,降低读写放大。使用向量化执行方式,充分挖掘多核CPU的并行计算能力,从而显著提升查询性能。
场景
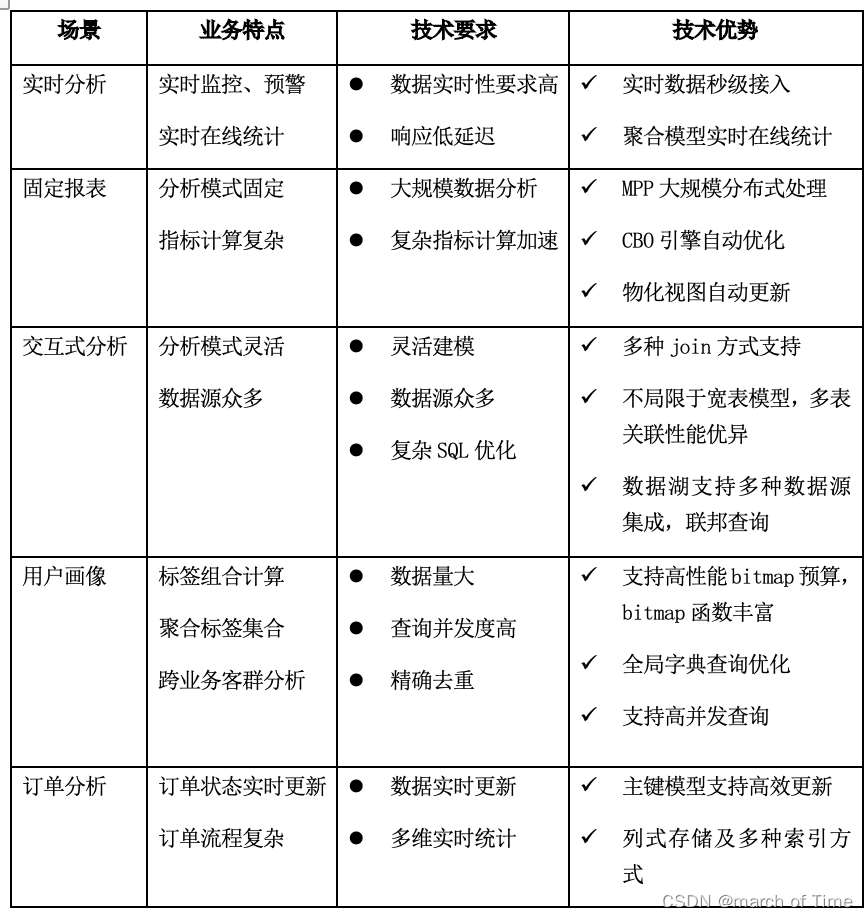
建表
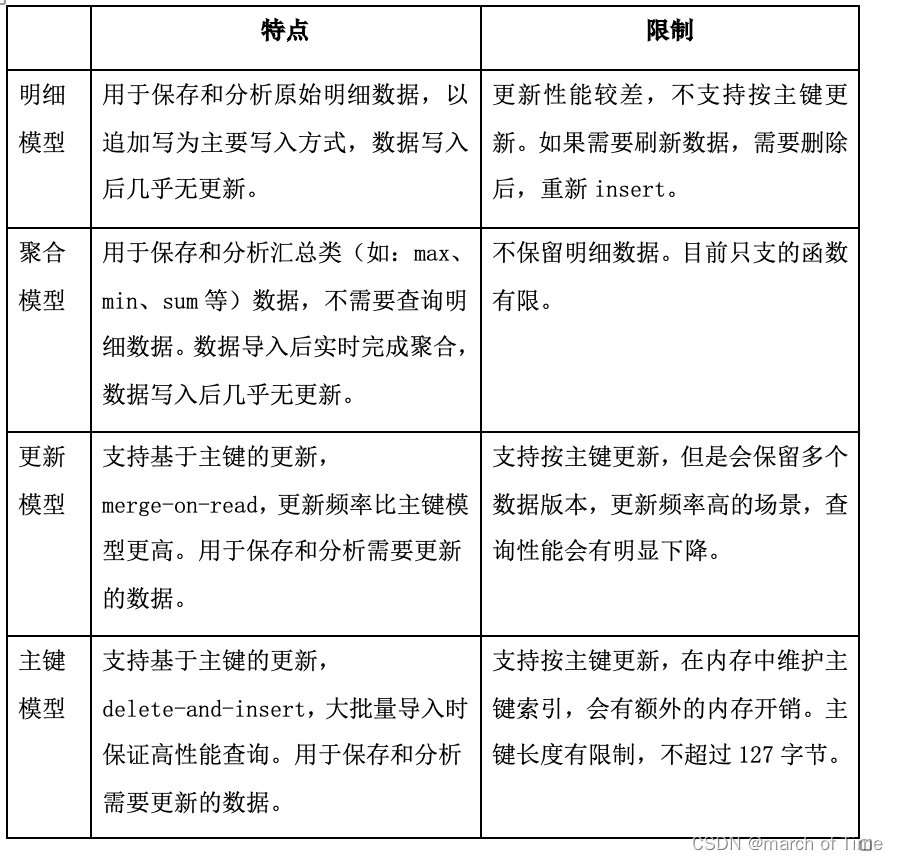
StarRocks 共有四类数据模型,明细模型、聚合模型、更新模型、主键模型。
分别适用于不同的业务场景。
建表语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [database.]table_name
(column_definition1[, column_definition2, ...]
[, index_definition1[, index_definition2,]])
[ENGINE = [olap|mysql|elasticsearch|hive]]
[key_desc (key1,key2...)]
[COMMENT "table comment"];
[partition_desc]
[distribution_desc]
[rollup_index][PROPERTIES ("key"="value", ...)]
[BROKER PROPERTIES ("key"="value", ...)]
duplicate key :排序字段
数据按照指定的key列进行排序,创建时应选择经常过滤的列放在key列,提高查询效率。
partition_desc:分区字段
通常选取常用的日期过滤字段作为分区字段,查询时可以进行分区裁剪,减少数据扫描量。实际应用中,用户一般选取时间列作为分区键,具体划分的粒度视数据量而定,单个分区原始数据量建议维持在100G以内。
distribution_desc:分桶字段
选取基数较高的字段做为分桶字段,可以选择多个列进行分桶。尽量将数据打散,避免出现数据倾斜。
把经常需要作为查询过滤条件的列作为分桶键,可以在查询时裁剪掉大量无关分桶。但如果只利用该分桶键,数据分布可能会出现严重的数据倾斜, 导致系统局部的性能瓶颈。这个时候,用户需要适当调整分桶的字段,以将数据打散,利用分布式集群的整体并发性能,提高吞吐。
分桶的数据的压缩方式使用的是Lz4。建议压缩后磁盘上每个分桶数据文件大小在100MB-1GB左右。这种模式在多数情况下足以满足业务需求。
对于StarRocks而言,分区和分桶的选择是非常关键的。在建表时选择好的分区分桶列,可以有效提高集群整体性能。当然,在使用过程中,也需考虑业务情况,根据业务情况进行调整。
以下是针对特殊应用场景下,对分区和分桶选择的一些建议:
- 数据倾斜:业务方如果确定数据有很大程度的倾斜,那么建议采用多列组合的方式进行数据分桶,而不是只单独采用倾斜度大的列做分桶。
- 高并发:分区和分桶应该尽量覆盖查询语句所带的条件,这样可以有效减少扫描数据,提高并发。
- 高吞吐:尽量把数据打散,让集群以更高的并发扫描数据,完成相应计算。
明细模型
一般用明细模型来处理的场景有如下特点:
需要保留原始的数据(例如原始日志,原始操作记录等)来进行分析;
查询方式灵活, 不局限于预先定义的分析方式, 传统的预聚合方式难以命中;
数据更新不频繁。导入数据的来源一般为日志数据或者是时序数据, 以追加写为主要特点, 数据产生后就不会发生太多变化。
建议:排序列使用shortkey index, 可快速过滤数据. 用户可以考虑将过滤条件中频繁使用的维度列的定义放置其他列的定义之前,这样能够提升查询速度
注意:明细模型中, 可以指定部分的维度列为排序键; 而聚合模型和更新模型中, 排序键只能是全体维度列。
聚合模型
采用聚合模型来分析的场景具有如下特点:
业务方进行的查询为汇总类查询,比如sum、count、max等类型的查询;
不需要召回原始的明细数据;
老数据不会被频繁更新,只会追加新数据。
聚合表中数据会分批次多次导入,每次导入会形成一个版本。相同排序键的数据行聚合有三种触发方式:
数据导入时,数据落盘前的聚合;
数据落盘后,后台的多版本异步聚合;
数据查询时,多版本多路归并聚合。
注意:数据查询时,指标列采用先聚合后过滤的方式,把没必有做指标的列存储为维度列。
更新模型
适合更新模型的场景特点:
已经写入的数据有大量的更新需求;
需要进行实时数据分析。
注意:
1、导入数据时需要将所有字段补全才能够完成更新操作。
2、对于更新模型的数据读取,需要在查询时完成多版本合并,当版本过多时会导致查询性能降低。所以在向更新模型导入数据时,应该适当降低导入频率,从而提升查询性能。
3、将经常过滤字段且不会被修改的字段放在主键上, 能够在合并之前就将数据过滤掉,从而提升查询性能。
4、避免放置过多的主键字段,以免降低查询性能。如果某个字段只是偶尔会作为查询中的过滤条件存在,不需要放在主键中。
主键模型
相较更新模型,主键模型(Primary Key)可以更好地支持实时/频繁更新的功能。该类型的表要求有唯一的主键,支持对表中的行按主键进行更新和删除操作。
由于存储引擎会为主键建立索引,而在导入数据时会把主键索引加载在内存中,所以主键模型对内存的要求比较高,还不适合主键特别多的场景。目前primary主键存储在内存中,为防止滥用造成内存占满,限制主键字段长度全部加起来编码后不能超过127字节。目前比较适合的两个场景是:
1、数据有冷热特征,即最近几天的热数据才经常被修改,老的冷数据很少被修改。典型的例子如MySQL订单表实时同步到StarRocks中提供分析查询。其中,数据按天分区,对订单的修改集中在最近几天新创建的订单,老的订单完成后就不再更新,因此导入时其主键索引就不会加载,也就不会占用内存,内存中仅会加载最近几天的索引。
2、大宽表(数百到数千列)。主键只占整个数据的很小一部分,其内存开销比较低。比如用户状态/画像表,虽然列非常多,但总的用户数不大(千万-亿级别),主键索引内存占用相对可控。
注意:
主键列仅支持类型: boolean, tinyint, smallint, int, bigint, largeint, string/varchar, date, datetime, 不允许NULL。
分区列(partition)、分桶列(bucket)必须在主键列中。
1、和更新模型不同,主键模型允许为非主键列创建bitmap等索引,注意需要建表时指定。
2、由于其列值可能会更新,主键模型目前还不支持rollup index和物化视图。暂不支持使用ALTER TABLE修改列类型。
3、在设计表时应尽量减少主键的列数和大小以节约内存,建议使用int/bigint等占用空间少的类型。暂时不建议使用varchar。建议提前根据表的行数和主键列类型来预估内存使用量,避免出现OOM。内存估算举例:
a. 假设表的主键为: dt date (4byte), id bigint(8byte) = 12byte
b. 假设热数据有1000W行, 存储3副本
c. 则内存占用: (12 + 9(每行固定开销) ) * 1000W * 3 * 1.5(hash表平均额外开销) = 945M
4、目前主键模型只支持整行更新,还不支持部分列更新。
更多【学习-StarRocks学习笔记】相关视频教程:www.yxfzedu.com
相关文章推荐
- hive-【Python大数据笔记_day06_Hive】 - 其他
- 算法-【C++入门】构造函数&&析构函数 - 其他
- unity-Unity地面交互效果——4、制作地面凹陷轨迹 - 其他
- python-Django如何创建表关系,Django的请求声明周期流程图 - 其他
- 算法-力扣21:合并两个有序链表 - 其他
- 算法-Leetcode2833. 距离原点最远的点 - 其他
- node.js-Node.js中的回调地狱 - 其他
- 人工智能-AIGC(生成式AI)试用 11 -- 年终总结 - 其他
- sqlite-计算机基础知识49 - 其他
- stable diffusion-AI 绘画 | Stable Diffusion 高清修复、细节优化 - 其他
- spring-SpringBoot中的桥接模式 - 其他
- 编程技术-Halcon WPF 开发学习笔记(2):Halcon导出c#脚本 - 其他
- mysql-【MySQL】视图 - 其他
- 编程技术-1994-2021年分行业二氧化碳排放量数据 - 其他
- 编程技术-SFTP远程终端访问 - 其他
- spring-【Spring】SpringBoot配置文件 - 其他
- 算法-“目标值排列匹配“和“背包组合问题“的区别和leetcode例题详解 - 其他
- java-一个轻量级 Java 权限认证框架——Sa-Token - 其他
- 运维-RK3568平台 查看内存的基本命令 - 其他
- 算法-深入理解强化学习——多臂赌博机:梯度赌博机算法的数学证明 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- Android安全-frida源码编译详解
- 软件逆向- PE格式:新建节并插入代码
- 加壳脱壳- UPX源码学习和简单修改
- 二进制漏洞-win越界写漏洞分析 CVE-2020-1054
- Pwn-2022长城杯决赛pwn
- 软件逆向-Wibu Codemeter 7.3学习笔记——Codemeter服务端
- Pwn-沙箱逃逸之google ctf 2019 Monochromatic writeup
- 软件逆向-Wibu Codemeter 7.3学习笔记——AxProtector壳初探
- 企业安全-学习Kubernetes笔记——暴露站点服务(Ingress)
- 企业安全-学习Kubernetes笔记——部署数据库站点(MySql)
