hive-【Hive】HIVE运行卡死没反应
推荐 原创Hive运行卡死
再次强调
hive:小兄弟,没想到吧,咱可不是随便的人。😄
那么,这次又遇见了hadoop问题,问题描述是这样的。
hive> insert into test values(1, 'nucty', '男');
Query ID = atguigu_20240324175437_2cd7db4a-6216-40f8-88c0-cf828af66f7e
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
[2]+ 已停止 bin/hive
等待了几分钟,无果,被迫Ctrl+z了哈哈哈哈哈。
同时,我也查阅了相关的博主,有一篇是这样说的。
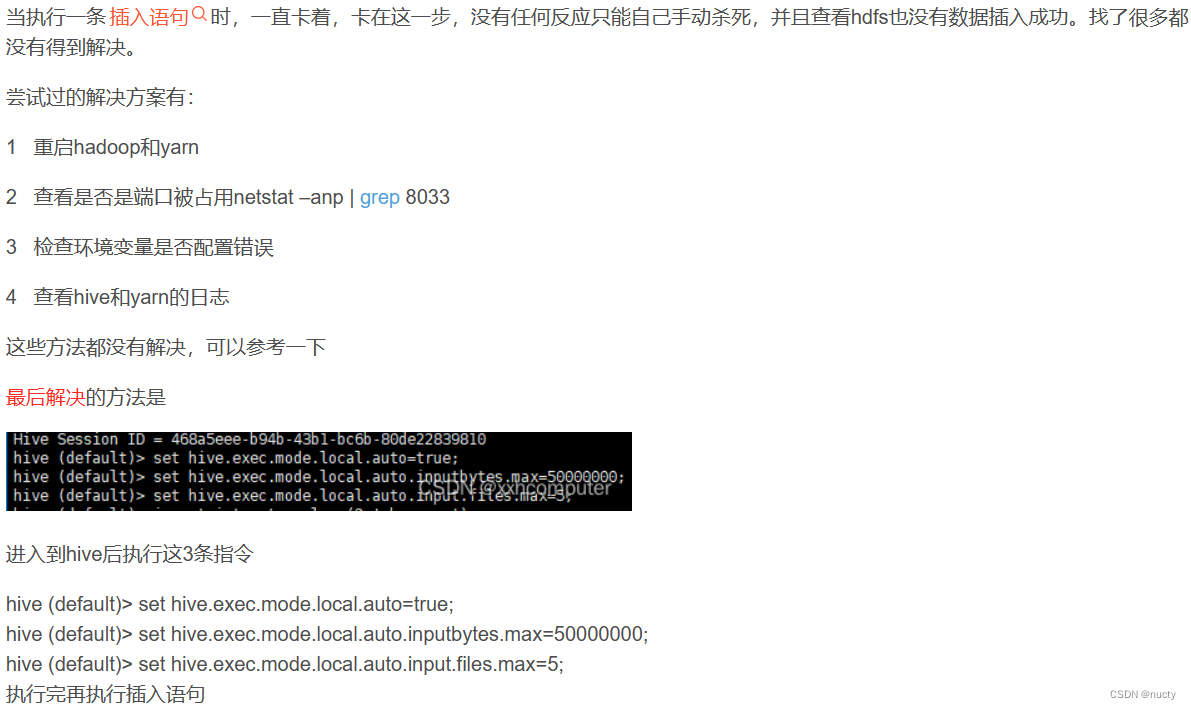
我也是直接进行了最后的3条指令,宝贝,结果还是卡着了。
最后,我发现这位博主写的其实没错,没有解决是因为我没进行前面的操作(1,2,3,4)。
其实呢,我最开始就开始尝试打开yarn客户端界面了,但是没有打开,其实我发觉到我用的地址错误了,因为yarn并没有部署在了hadoop102上面,而我发觉之后立马改正,可还是打不开,我不由得觉得我的地址是不是真的输错了,哈哈哈哈,挺逗的,卡了好几分钟,最后在部署yarn的虚拟机(hadoop103)上面jps了一下,发现真的没有启动集群。因为之前虚拟机都是处于挂起的状态,所以每次我没有直接启动集群,小伙伴们之后也不要犯这个错误了。
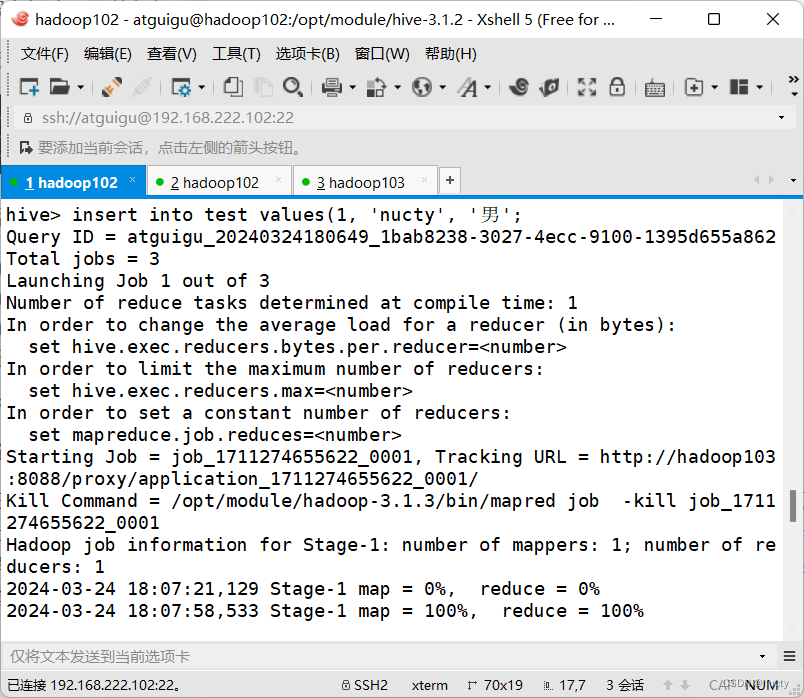
最后也是如期完成了插入操作。
以此记录我因未开启集群环境而发生错误的第二篇博客。
更多【hive-【Hive】HIVE运行卡死没反应】相关视频教程:www.yxfzedu.com
相关文章推荐
- python-python用pychart库,实现将经纬度信息在地图上显示 - 其他
- node.js-Electron-vue出现GET http://localhost:9080/__webpack_hmr net::ERR_ABORTED解决方案 - 其他
- web安全-APT攻击的特点及含义 - 其他
- 51单片机-51单片机应用从零开始(二) - 其他
- objective-c-【Objective-C】Objective-C汇总 - 其他
- 云原生-SpringCloud微服务:Eureka - 其他
- react.js-react+星火大模型,构建上下文ai问答页面(可扩展) - 其他
- node.js-taro(踩坑) npm run dev:weapp 微信小程序开发者工具预览报错 - 其他
- 云原生-Paas-云原生-容器-编排-持续部署 - 其他
- 网络-漏洞扫描工具的编写 - 其他
- 组合模式-二十三种设计模式全面解析-组合模式与迭代器模式的结合应用:构建灵活可扩展的对象结构 - 其他
- java-【Proteus仿真】【51单片机】多路温度控制系统 - 其他
- java-【Vue 透传Attributes】 - 其他
- github-在gitlab中指定自定义 CI/CD 配置文件 - 其他
- 编程技术-四、Vue3中使用Pinia解构Store - 其他
- apache-Apache Druid连接回收引发的血案 - 其他
- 编程技术-剑指 Offer 06. 从尾到头打印链表 - 其他
- 编程技术-linux查看端口被哪个进程占用 - 其他
- 编程技术-Linux安装java jdk配置环境 方便查询 - 其他
- hdfs-wpf 命令概述 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
