算法-R语言ggplot2 | 热图+随机森林重要性!升级版~
推荐 原创今天推出一个升级版: ggrf_ggcor_plot的函数。只需要输入 响应变量的矩阵和 解释变量的矩阵,就能轻松一键生成随机森林重要性+相关性热图。
原图
所需复现的随机森林变量重要性+相关性热图:
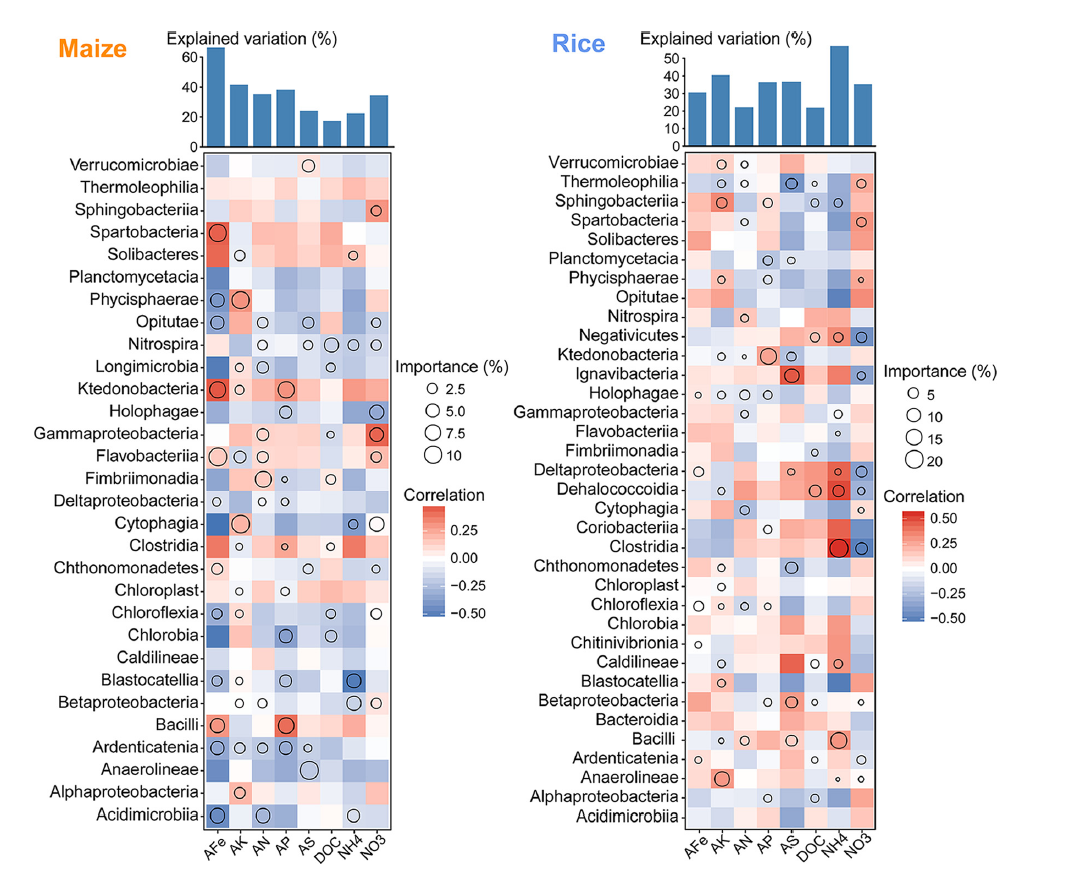
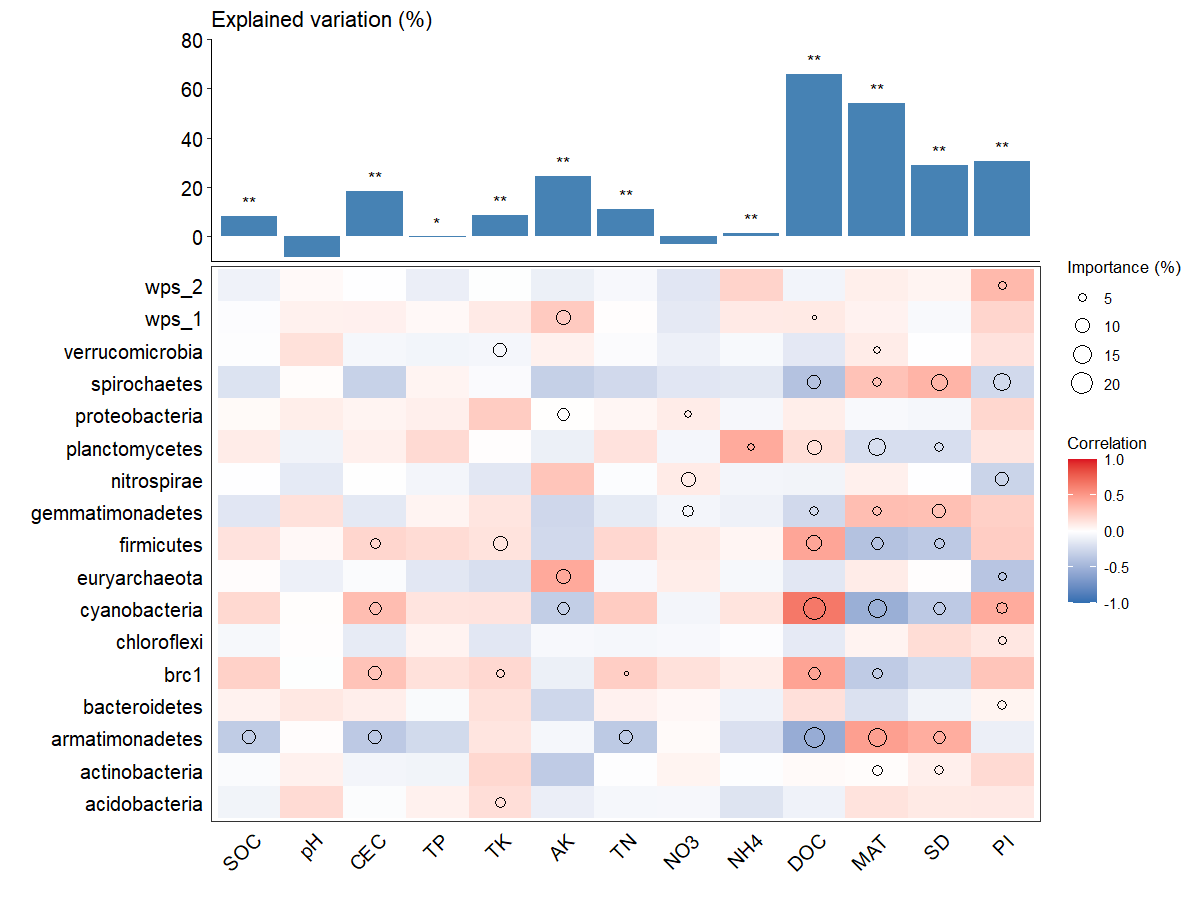
这整张图由两张结构相似的子图组成,分别代表玉米和水稻。以左侧图为例,它分为两个主要部分。上方的柱状图显示了各个土壤环境变量在随机森林模型中的解释量,下方的热图表示微生物物种丰度与土壤环境变量之间的相关性。其中,热图中每列x轴特定的土壤环境变量作为随机森林模型中的因变量,每个微生物物种的丰度作为随机森林模型中的特征变量。热图中的小圆圈的大小则表示每个特征变量在随机森林模型中的重要性(对应的%MSE值,且p<0.05)。总体来说,这张图旨在揭示不同土壤环境变量如何影响微生物群落的丰度,以及这些微生物群落在随机森林模型中对各个土壤环境变量的重要性。
复现
定义ggrf_ggcor_plot()函数
source("ggrf_ggcor_plot.R")
重新定义了ggrf_ggcor_plot()函数,该函数能够做到一键生图。

需要注意的是:这个函数是在R版本4.2.2基础上定义的。此外,只保证在响应变量和特征变量的数据集样本量相同下进行运行。
主要参数*:
response_data:响应变量的数据集,格式为数据框。(因变量)feature_data:解释变量的数据集,格式为数据框。(自变量)seed:种子数,保证每次运行结果一致,必须为整数。
其余参数可以默认,主要包括相关性分析的参数、随机森林及特征变量重要性等细节参数。函数的三个点"…"表示传参用法,这里主要在进行可视化随机森林模型解释量的柱状图中使用到。
输出结果
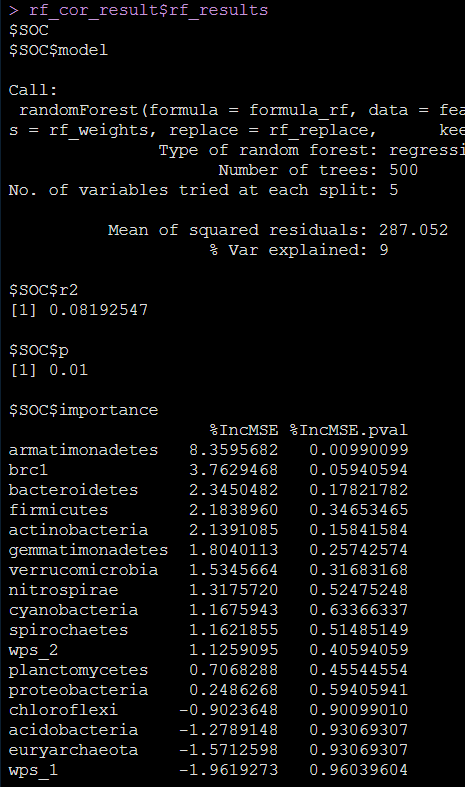
list列表;rf_results包括每个随机森林模型的摘要及解释量和p值;cor_df是两个数据集的相关性分析结果,包括对应名称、相关性系数及p值;rf_plot是每个随机森林模型的解释量及p值是否显著的ggplot可视化结果;cor_plot是响应变量和解释变量两个数据集的相关性热图,颜色表示正负,深浅表示大小,圆圈表示的随机森林中不同特征变量对因变量的重要性(只展示%MSE对应p<0.05的)
加载数据集
- 加载微生物数据
OTU <- openxlsx::read.xlsx("OTU.xlsx", 1)
head(OTU)
行为样本,列为微生物群落种类。
- 加载土壤环境数据
ENV <- openxlsx::read.xlsx("ENV.xlsx", 1)
head(ENV)
行为样本,列为土壤环境变量。
一键出图
rf_cor_result <- ggrf_ggcor_plot(ENV, OTU, seed = 123, rfp_num_cores = 12, limits = c(-10, 80), breaks = seq(0, 80, 20))
rf_cor_result$rf_plot
rf_cor_result$cor_plot
rf_cor_result$rf_cor_plot
这里,我们处理选择了响应变量和解释变量的两个数据集,还设定了seed种子数=123,并设置了在计算计算每个特征变量的重要性%MSE及p值时的核心数=12,这样可以加快我们的运行速度。
需要注意的是我上面提到了"…"作为传参,我们设定在了ggplot2可视化y轴范围的函数中,因此为了让整个图的比例更协调,我定义了y轴的上下限范围limits = c(-10, 80)以及相应的范围间隔breaks = seq(0, 80, 20)。
图1,显示的是随机森林模型的解释量。
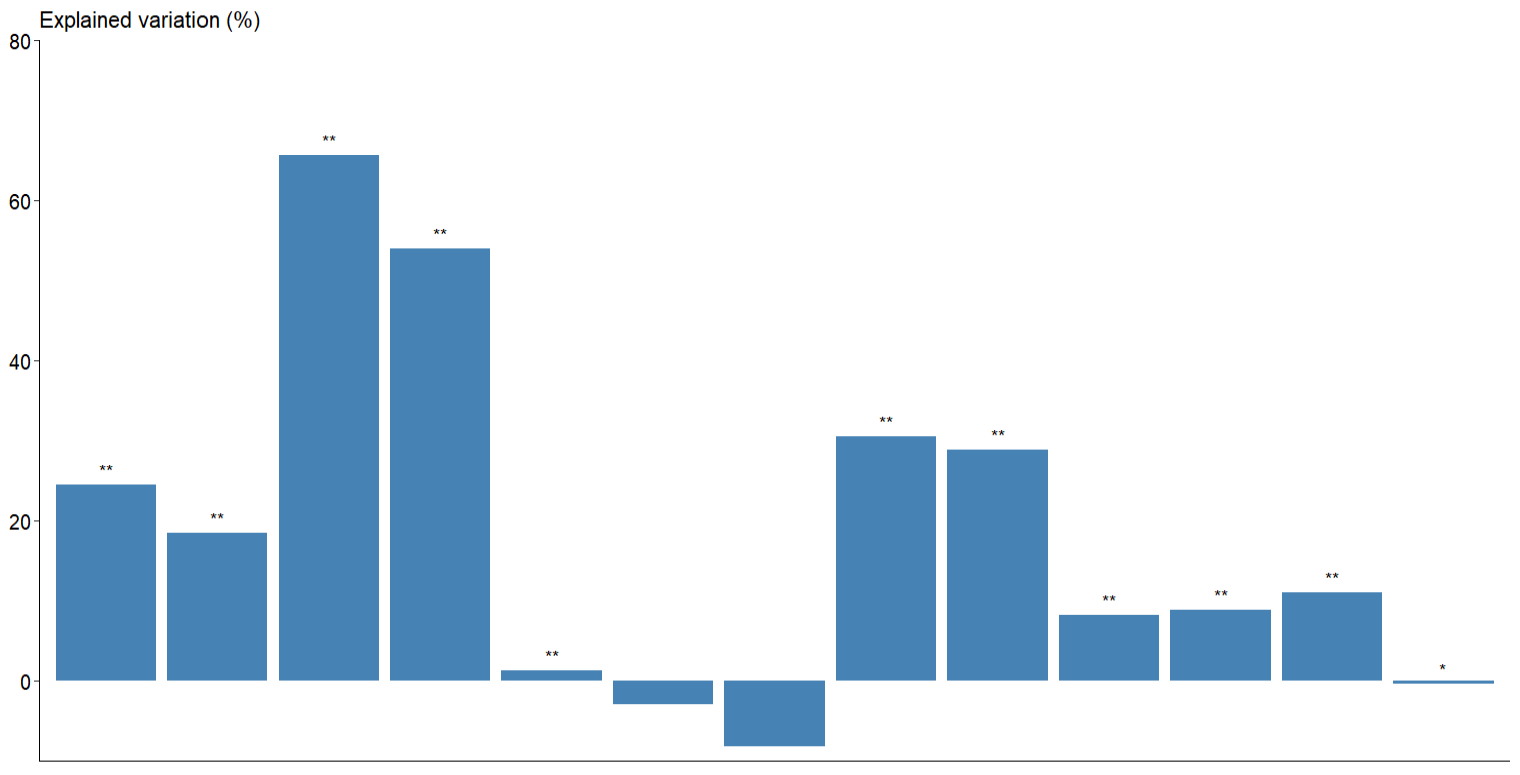
图2,显示的是相关性分析热图。
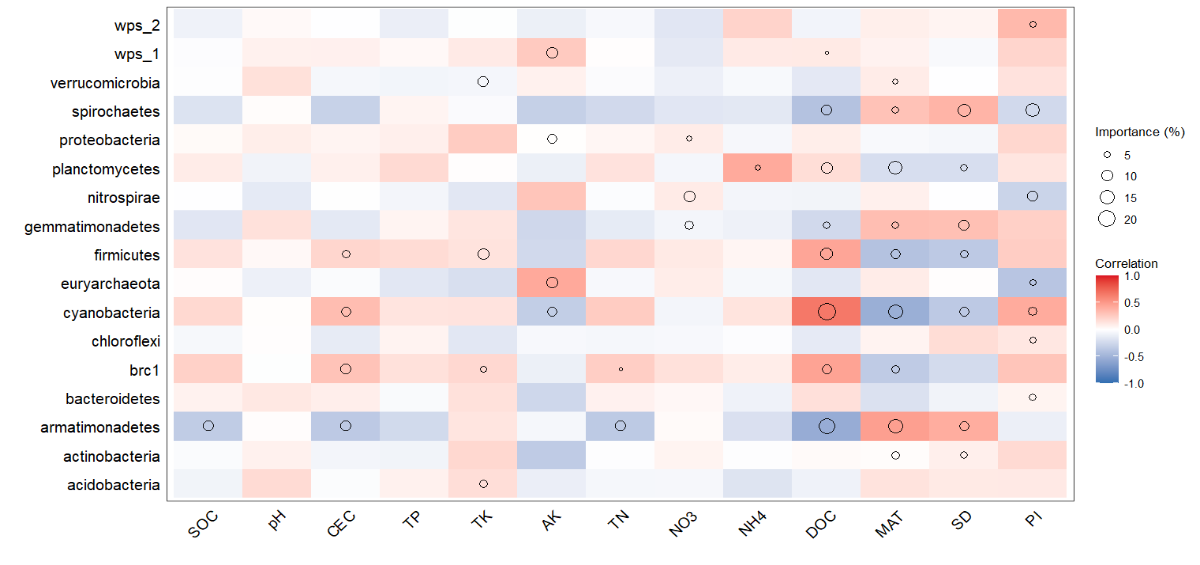
图3,是我们的目标图,随机森林重要性+相关性热图。
至此,一键出图已经完成。考虑到大家可能对图形的展示风格或者类型持有不同想法和意见,所以输出的结果为list,也保留了对应随机森林重要性和相关性热图的数据。
用一下代码就可以调用:
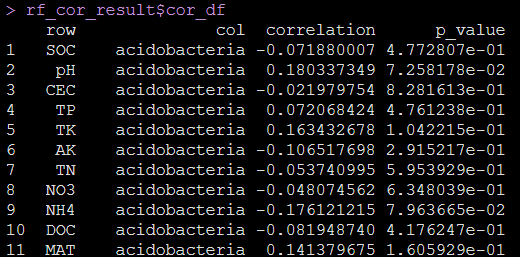
- 相关性分析的数据结果
rf_cor_result$cor_df
- 随机森林模型的数据结果
rf_cor_result$rf_results
函数优点
便捷使用:一键生成图表,适合快速呈现分析结果。多样输出:提供多种输出选项,以满足不同需求的用户。灵活参数:可根据需要自定义参数,具备推广和定制的潜力。
更多【算法-R语言ggplot2 | 热图+随机森林重要性!升级版~】相关视频教程:www.yxfzedu.com
相关文章推荐
- 运维-RK3568平台 查看内存的基本命令 - 其他
- 算法-深入理解强化学习——多臂赌博机:梯度赌博机算法的数学证明 - 其他
- apache-Apache Doris 是什么 - 其他
- list-Redis数据结构七之listpack和quicklist - 其他
- css-HTML CSS JS 画的效果图 - 其他
- python-Win10系统下torch.cuda.is_available()返回为False的问题解决 - 其他
- python-定义无向加权图,并使用Pytorch_geometric实现图卷积 - 其他
- git-如何使用git-credentials来管理git账号 - 其他
- prompt-Anaconda Powershell Prompt和Anaconda Prompt的区别 - 其他
- python-Dhtmlx Event Calendar 付费版使用 - 其他
- gpt-ChatGPT、GPT-4 Turbo接口调用 - 其他
- ddos-ChatGPT 宕机?OpenAI 将中断归咎于 DDoS 攻击 - 其他
- junit-Lua更多语法与使用 - 其他
- prompt-Presentation Prompter 5.4.2(mac屏幕提词器) - 其他
- css-CSS 网页布局 - 其他
- spring-idea中搭建Spring boot项目(借助Spring Initializer) - 其他
- 网络-# 深度解析 Socket 与 WebSocket:原理、区别与应用 - 其他
- prompt-屏幕提词软件Presentation Prompter mac中文版使用方法 - 其他
- java-AVL树详解 - 其他
- spring-在Spring Boot中使用JTA实现对多数据源的事务管理 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 茶余饭后-newstarCTF2023 week4|REVERSE--简单的跨 writeup
- 企业安全-新型后门病毒伪装常用软件,正通过Google搜索引擎传播
- 编程技术-【wing一款轻量快捷的团队开发工具】
- Android安全-flutter逆向 ACTF native app
- Android安全-Android第一代落地DEX加固实战学习
- 智能设备-通过SD卡给某摄像头植入可控程序
- CTF对抗-python310新特性->Structural Pattern Matching在VM虚拟机逆向中的妙用
- KSA软件-ksa的docker版本部署
- 软件逆向-The Finals SDK与某辅助的驱动注入
- ADB命令
