爬虫-Python 爬虫基础
推荐 原创Python 爬虫基础
1.1 理论
在浏览器通过网页拼接【/robots.txt】来了解可爬取的网页路径范围
例如访问: https://www.csdn.net/robots.txt
User-agent: *
Disallow: /scripts
Disallow: /public
Disallow: /css/
Disallow: /images/
Disallow: /content/
Disallow: /ui/
Disallow: /js/
Disallow: /scripts/
Disallow: /article_preview.html*
Disallow: /tag/
Disallow: /?
Disallow: /link/
Disallow: /tags/
Disallow: /news/
Disallow: /xuexi/
通过Python Requests 库发送HTTP【Hypertext Transfer Protocol “超文本传输协议”】请求
通过Python Beautiful Soup 库来解析获取到的HTML内容
HTTP请求

HTTP响应
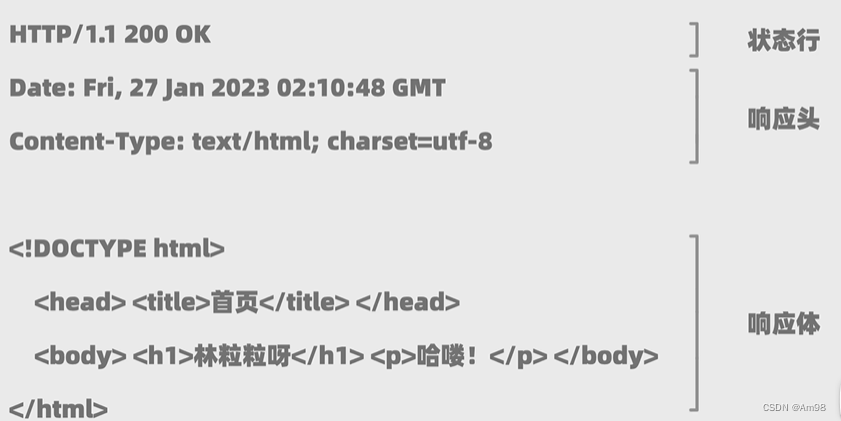
1.2 实践代码 【获取价格&书名】
import requests
# 解析HTML
from bs4 import BeautifulSoup
# 将程序伪装成浏览器请求
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
requests = requests.get("http://books.toscrape.com/",headers= head)
# 指定编码
# requests.encoding= 'gbk'
if requests.ok:
# file = open(r'C:\Users\root\Desktop\Bug.html', 'w')
# file.write(requests.text)
# file.close
content = requests.text
## html.parser 指定当前解析 HTML 元素
soup = BeautifulSoup(content, "html.parser")
## 获取价格
all_prices = soup.findAll("p", attrs={
"class":"price_color"})
for price in all_prices:
print(price.string[2:])
## 获取名称
all_title = soup.findAll("h3")
for title in all_title:
## 获取h3下面的第一个a元素
print(title.find("a").string)
else:
print(requests.status_code)
1.3 实践代码 【获取 Top250 的电影名】
import requests
# 解析HTML
from bs4 import BeautifulSoup
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
# 获取 TOP 250个电影名
for i in range(0,250,25):
response = requests.get(f"https://movie.douban.com/top250?start={
i}", headers= head)
if response.ok:
content = response.text
soup = BeautifulSoup(content, "html.parser")
all_titles = soup.findAll("span", attrs={
"class": "title"})
for title in all_titles:
if "/" not in title.string:
print(title.string)
else:
print(response.status_code)
1.4 实践代码 【下载图片】
import requests
# 解析HTML
from bs4 import BeautifulSoup
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
response = requests.get(f"https://www.maoyan.com/", headers= head)
if response.ok:
soup = BeautifulSoup(response.text, "html.parser")
for img in soup.findAll("img", attrs={
"class": "movie-poster-img"}):
img_url = img.get('data-src')
alt = img.get('alt')
path = 'img/' + alt + '.jpg'
res = requests.get(img_url)
with open(path, 'wb') as f:
f.write(res.content)
else:
print(response.status_code)
1.5 实践代码 【千图网图片 - 爬取 - 下载图片】
import requests
# 解析HTML
from bs4 import BeautifulSoup
# 千图网图片 - 爬取
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
# response = requests.get(f"https://www.58pic.com/piccate/53-0-0.html", headers= head)
# response = requests.get(f"https://www.58pic.com/piccate/53-598-2544.html", headers= head)
response = requests.get(f"https://www.58pic.com/piccate/53-527-1825.html", headers= head)
if response.ok:
soup = BeautifulSoup(response.text, "html.parser")
for img in soup.findAll("img", attrs={
"class": "lazy"}):
img_url = "https:" + img.get('data-original')
alt = img.get('alt')
path = 'imgqiantuwang/' + str(alt) + '.jpg'
res = requests.get(img_url)
with open(path, 'wb') as f:
f.write(res.content)
else:
print(response.status_code)
更多【爬虫-Python 爬虫基础】相关视频教程:www.yxfzedu.com
相关文章推荐
- 分布式-Java架构师分布式搜索词库解决方案 - 其他
- 电脑-京东数据分析:2023年9月京东笔记本电脑行业品牌销售排行榜 - 其他
- 云计算-什么叫做云计算? - 其他
- 编程技术-基于springboot+vue的校园闲置物品交易系统 - 其他
- 零售-OLED透明屏在智慧零售场景的应用 - 其他
- 交互-顶板事故防治vr实景交互体验提高操作人员安全防护技能水平 - 其他
- unity-原型制作神器ProtoPie的使用&Unity与网页跨端交互 - 其他
- python-Django知识点 - 其他
- 前端-js实现定时刷新,并设置定时器上限 - 其他
- 需求分析-2023-11-11 事业-代号s-duck-官网首页需求分析 - 其他
- node.js-【第2章 Node.js基础】2.5 Node.js 的定时器 - 其他
- 编程技术-parasoft Jtest 使用教程:防止和检查内存问题 - 其他
- hive-【Python大数据笔记_day06_Hive】 - 其他
- 算法-【C++入门】构造函数&&析构函数 - 其他
- unity-Unity地面交互效果——4、制作地面凹陷轨迹 - 其他
- python-Django如何创建表关系,Django的请求声明周期流程图 - 其他
- 算法-力扣21:合并两个有序链表 - 其他
- 算法-Leetcode2833. 距离原点最远的点 - 其他
- node.js-Node.js中的回调地狱 - 其他
- 人工智能-AIGC(生成式AI)试用 11 -- 年终总结 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
