语言模型-LLM - 大语言模型(LLM) 概述
推荐 原创欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/136617643
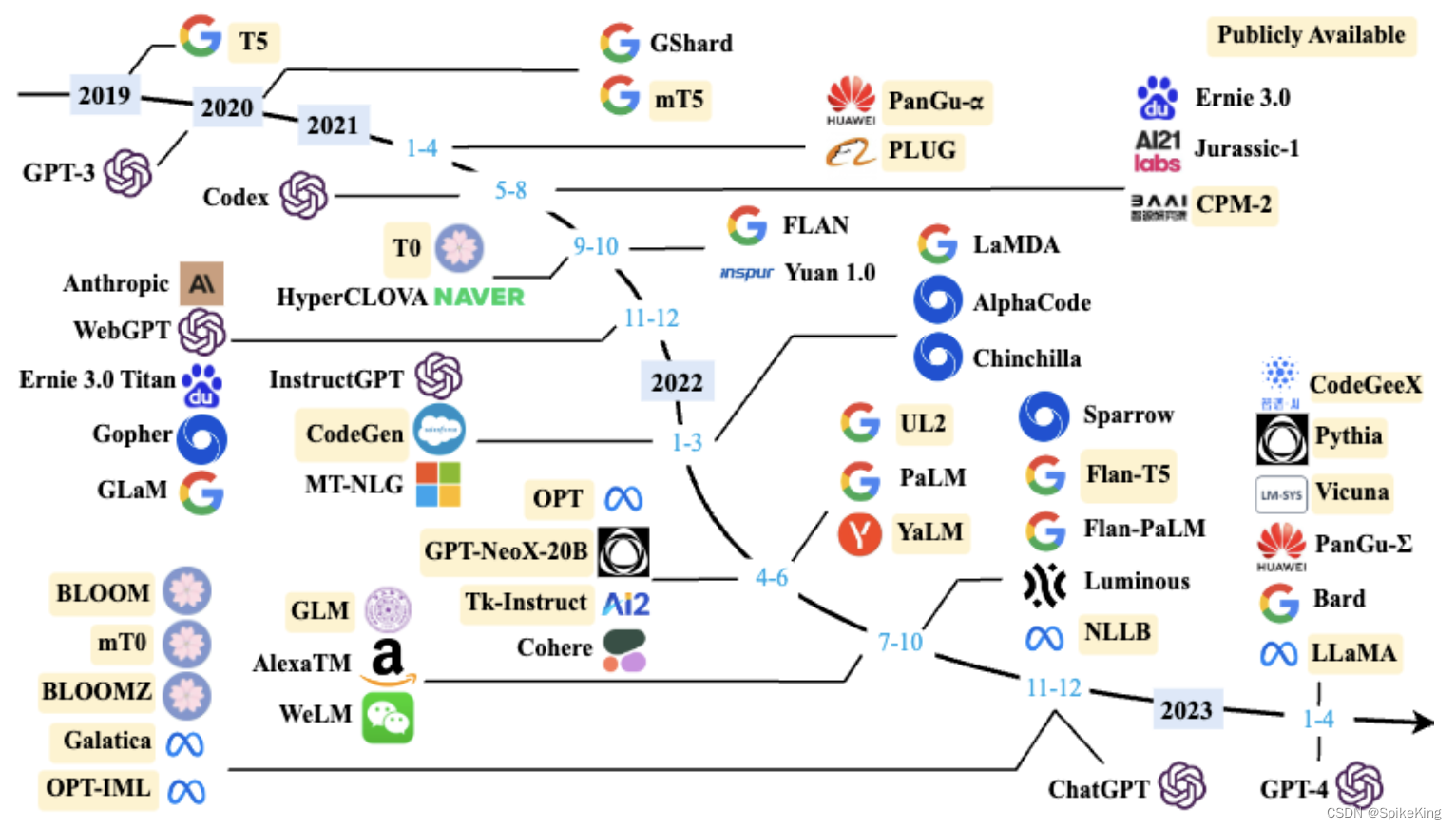
大语言模型(LLM, Large Language Model)的发展和应用是一个非常广泛的领域,涉及从早期的统计模型到现代基于深度学习的模型。在自然语言处理领域的应用非常广泛,包括但不限于聊天机器人、内容生成、情感分析、自动摘要、问答系统等。强大的文本生成能力,使其在内容创作领域具有巨大潜力,可以用于撰写文章、创作诗歌、生成新闻报道等。也可以为教育提供丰富的资源和工具,如自动评分、个性化学习辅导等,还可以用于构建智能客服系统,提高客户服务的响应速度和准确性。
以下是语言模型发展的4个阶段:
- 早期发展: 最初的语言模型基于统计方法和简单的神经网络,如循环神经网络(RNN)。这些模型在文本生成、机器翻译和语音识别等领域有所应用。
- Transformer架构: 随着Transformer架构的提出,语言取得了重大进展。Transformer提供了一种有效的方法来处理长距离依赖问题,并且在处理大量数据时表现出色。
- 预训练-微调范式: 研究者提出了预训练-微调(Pretraining-Finetuning)范式,通过在大量无标签数据上预训练模型,然后在特定任务上进行微调,以提高模型在特定任务上的表现。
- 多模态: 近年来,多模态大语言模型成为研究热点,这类模型不仅处理文本,还能理解图像和声音等其他类型的数据。
总的来说,大语言模型的发展推动了人工智能在理解和生成自然语言方面的能力,为各种应用提供了强大的支持。
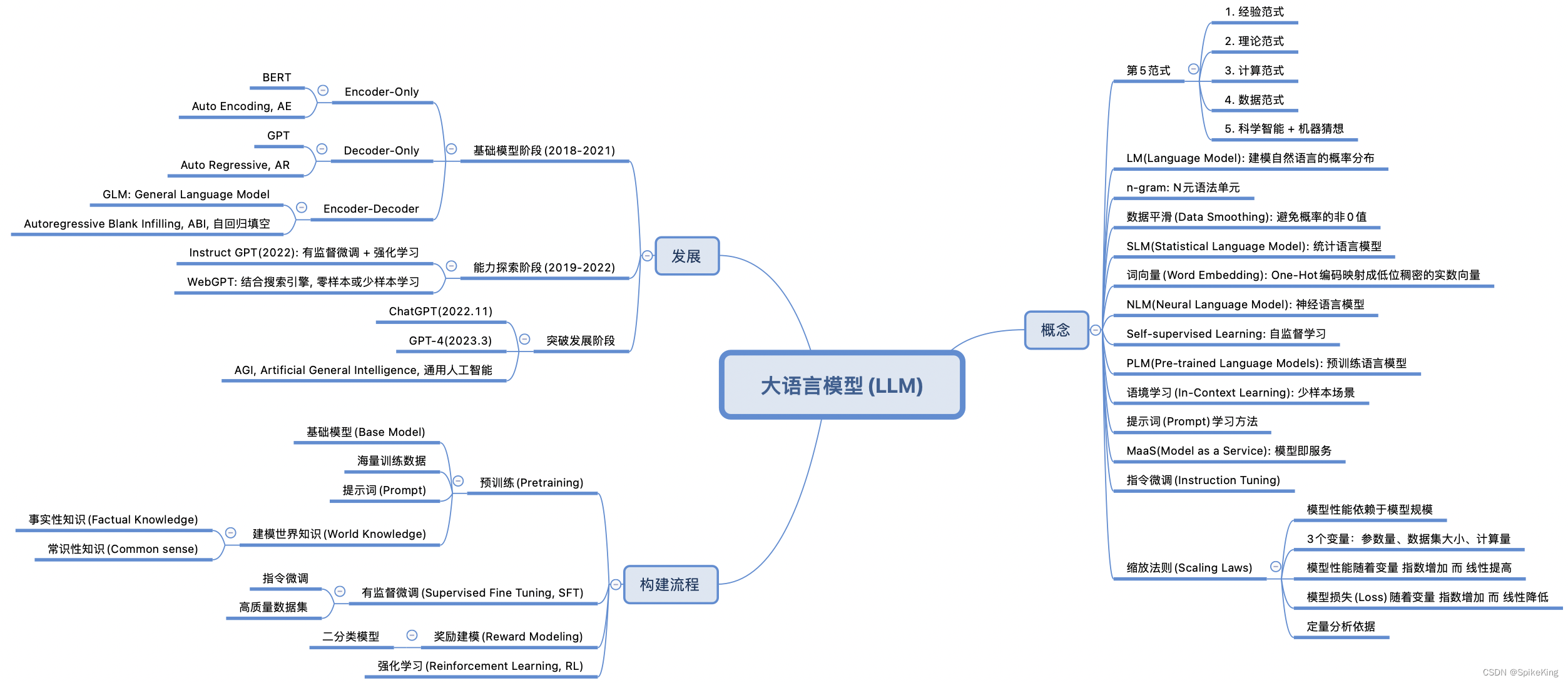
1. 大语言模型概念
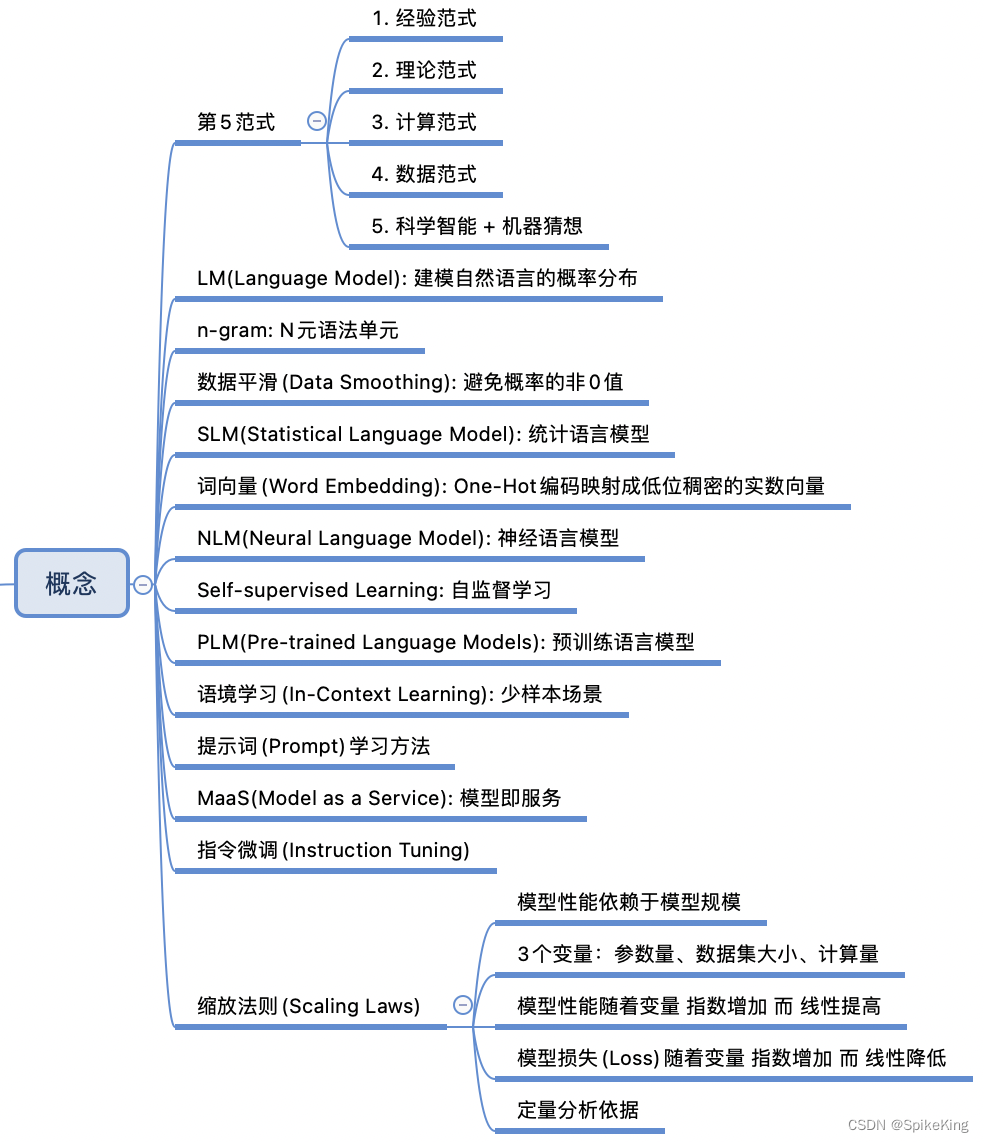
世界科学发展的5个范式是对科学研究方法演变的概括,每个范式代表了一种独特的研究方法和科学理解的方式,即:
- 经验范式:这是最古老的科学范式,依赖于直接观察自然现象并从中获取知识。不依赖于复杂的理论,而是基于实验和经验的积累。
- 理论范式:随着数学和逻辑的发展,科学家开始使用理论模型来解释观察到的现象。这个范式包括了像牛顿运动定律这样的经典理论。
- 计算范式:计算机的出现使得科学家能够解决以前无法手工计算的复杂问题。这个范式依赖于数值模拟和计算机仿真。
- 数据范式:在大数据时代,科学研究开始依赖于收集、存储和分析大量数据。这个范式利用统计和机器学习方法来从数据中提取知识。
- 科学智能范式:这是最新的范式,结合了人工智能技术,特别是深度学习,来加速科学发现。利用AI来模拟和预测复杂系统的行为,有时甚至可以发现新的科学规律。
这些范式并不是相互排斥的,而是相辅相成,共同推动科学进步。
2. 大语言模型发展
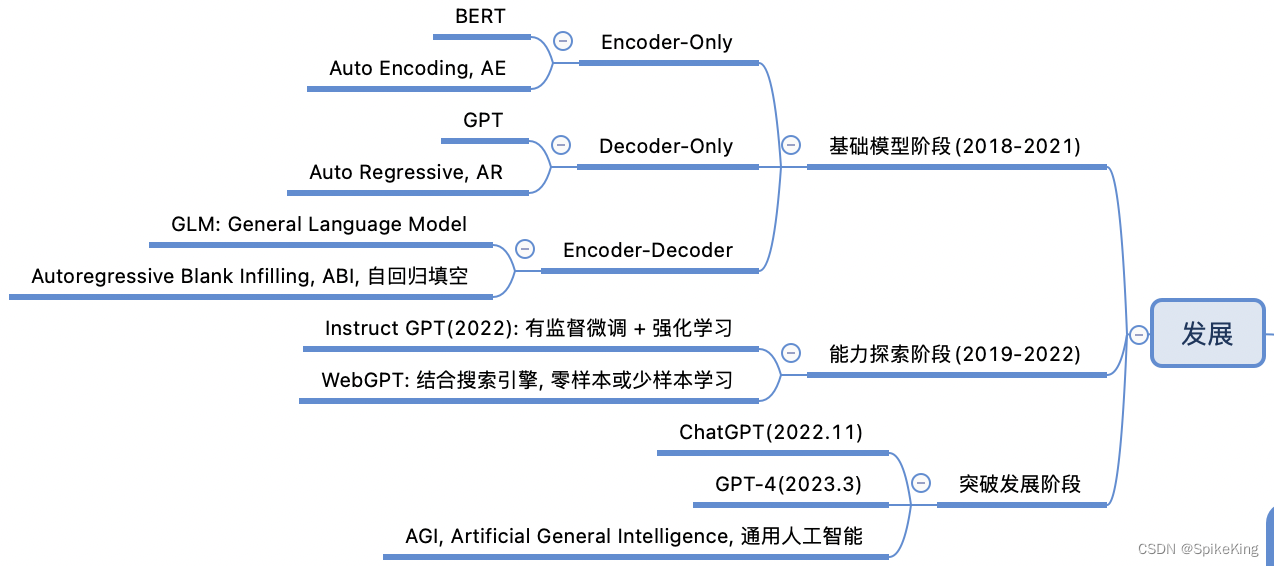
大语言模型的三种主要架构,即Encoder-Only、Decoder-Only、Encoder-Decoder,各有其特点和应用场景:
- Encoder-Only架构:
- 这种架构专注于输入文本的理解,通常用于分类、实体识别或其他需要理解文本含义的任务。
- 通过编码器处理输入文本,提取特征,然后用于下游任务。
- 例如,BERT(Bidirectional Encoder Representations from Transformers)就是一个典型的Encoder-Only模型。
- Decoder-Only架构:
- Decoder-Only架构专注于生成文本,适用于语言生成任务,如文本续写、创作等。
- 通过解码器从给定的上下文中生成下一个单词或序列。
- GPT(Generative Pretrained Transformer)系列模型是Decoder-Only架构的代表。
- Encoder-Decoder架构:
- 这种架构结合了编码器和解码器的优点,能够理解输入文本并生成相应的输出。
- 通常用于需要理解和生成文本的任务,如机器翻译、文本摘要等。
- GLM(General Language Model)模型就是一个典型的Encoder-Decoder架构。
每种架构都有其独特的优势。
3. 大语言模型构建
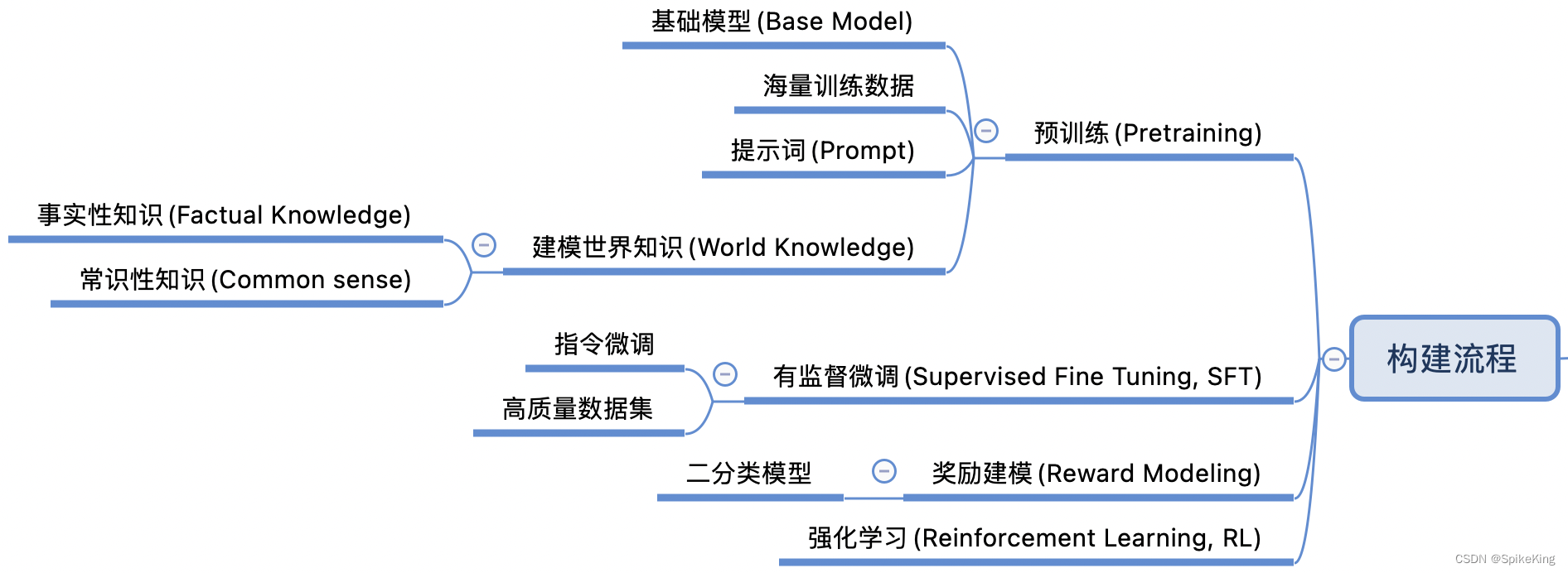
构建大型语言模型(LLM)的过程通常包括以下4个步骤:
- 预训练(Pretraining): 在这一阶段,模型在大规模的数据集上进行训练,以学习语言的基本规则和模式。这些数据集通常包含了广泛的主题和语言风格。
- 有监督微调(Supervised Fine Tuning, SFT): 预训练完成后,模型会在特定任务的数据集上进行微调。这些数据集是有标签的,即每个输入数据都有一个正确的输出,模型通过这些数据学习执行特定的任务。
- 奖励建模(Reward Modeling): 在这个阶段,模型会学习如何根据给定的奖励信号来优化其行为。这通常涉及到从人类反馈中学习,以便模型能够更好地满足用户的需求。
- 强化学习(Reinforcement Learning, RL): 最后,模型通过强化学习进一步优化,这是一种让模型通过试错来学习的方法。模型会在模拟环境中进行实验,根据其行为的结果来调整策略,以最大化奖励。
这个流程是迭代的,模型可能会经过多轮的预训练、微调和优化,以不断提高其性能和适应性。
更多【语言模型-LLM - 大语言模型(LLM) 概述】相关视频教程:www.yxfzedu.com
相关文章推荐
- pdf-耗时3年写了一本数据结构与算法pdf!开源了 - 其他
- 计算机外设-键盘win键无法使用,win+r不生效、win键没反应、Windows键失灵解决方案(亲测可以解决) - 其他
- 计算机外设-键盘打字盲打练习系列之认识键盘——0 - 其他
- 机器学习-Azure 机器学习 - 有关为 Azure 机器学习配置 Kubernetes 群集的参考 - 其他
- 信息可视化-ESP32网络开发实例-将数据保存到InfluxDB时序数据库 - 其他
- 计算机外设-基于QT使用OpenGL,加载obj模型,进行鼠标交互 - 其他
- 前端框架-React进阶之路(三)-- Hooks - 其他
- 运维-python实现炒股自动化,个人账户无门槛量化交易的开始 - 其他
- 网络-各大电商平台API接口调用,对接拼多多开放平台API接口获得商品详情实时数据演示 - 其他
- r语言-gpt支持json格式的数据返回(response_format: ‘json_object‘) - 其他
- pdf-pdf.js不分页渲染(渲染完整内容) - 其他
- 自动驾驶-自动驾驶学习笔记(八)——路线规划 - 其他
- pdf-Word转PDF简单示例,分别在windows和centos中完成转换 - 其他
- spring boot-java 企业工程管理系统软件源码+Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis - 其他
- python-利用 Google Artifact Repository 构建maven jar 存储仓库 - 其他
- python-PyCharm因安装了illuminated Cloud插件导致加载项目失败 - 其他
- list-list复制出新的list后修改元素,也更改了旧的list? - 其他
- 语言模型-论文导读 | 融合大规模语言模型与知识图谱的推理方法 - 其他
- spring-springboot引入外部jar,package打包报错找不到程序包XXX - 其他
- c++-C++之list的用法介绍 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
