django-Elasticsearch进阶篇(二):Elasticsearch查询原理
推荐 原创Elasticsearch查询原理
Elasticsearch查询原理
本文档深入探讨了Elasticsearch的查询原理,包括单个ID查询文档和多个ID查询文档的流程。在搜索查询方面,通过两阶段查询,首先在各个分片拷贝中搜索匹配的文档标识符,然后在协调节点合并结果并获取完整文档。此外,全文检索的执行流程也得到了详细解释,从分析器处理查询词到构建查询语法树、匹配文档、评分和排序等步骤,分析其复杂的工作流程。
1. ES配置
本文的介绍使用三节点的集群配置,索引分片配置为7.x版本默认的一主一副
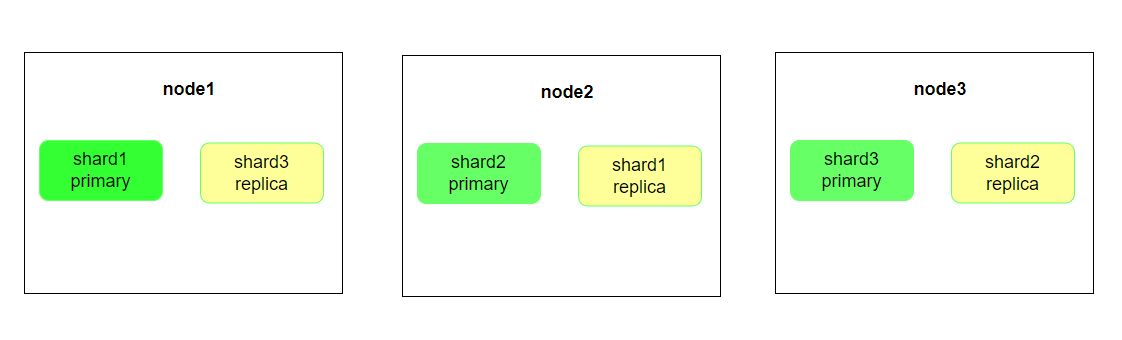
2. 文档ID查询
Elasticsearch中的查询主要分为两类,Get请求:通过ID查询特定Doc;Search请求:通过Query查询匹配Doc。
2.1 单个ID查询文档
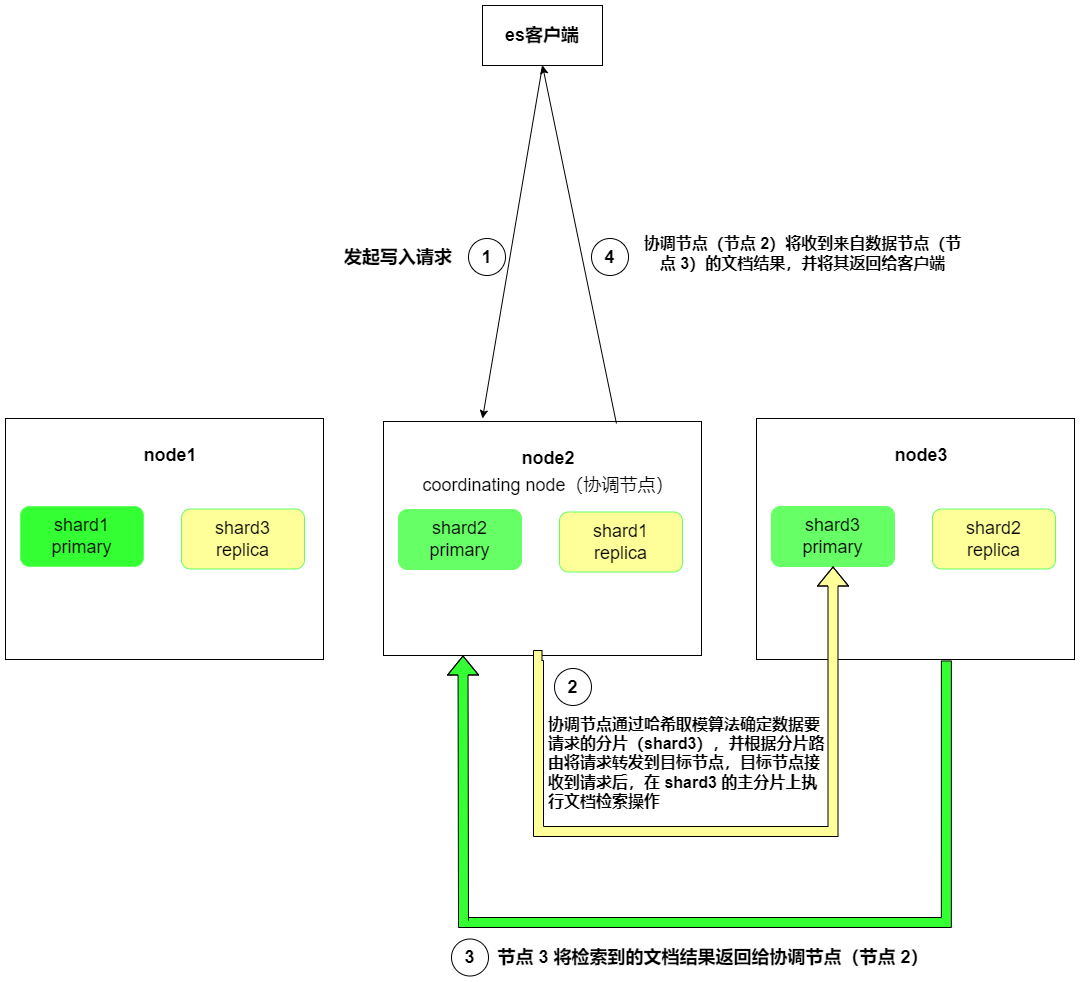
例如:当 ES客户端 将 单文档id Get请求发送到节点 2 时,节点 2 将作为协调节点来处理查询请求。由于哈希取模运算确定了文档所在的分片为 shard3,因此查询流程如下:
- 协调节点处理:节点 2(协调节点)接收到查询请求后,它将确定文档所在的分片为 shard3。
- 分片路由:节点 2 根据分片路由 知道 shard3 的主分片在节点 3 上,因此它将查询请求转发到节点 3。
- 文档检索:一旦查询请求到达节点 3,它将在 shard3 的主分片上执行文档检索操作并将检索到的文档结果返回给协调节点(节点 2)
- 最终返回:最后协调节点(节点 2)将收到来自数据节点(节点 3)的文档结果,并将其返回给客户端。
所以,查询流程如下:
ES客户端 -> Node 2 (协调节点) -> Node 3 (数据节点) -> Node 2 (协调节点) -> ES客户端
2.2 多个ID查询文档
对于 mget 请求,Elasticsearch 客户端会一次性发送多个文档ID,并且在协调节点(这里是节点 2)进行路由和汇总查询结果。
多文档ID查询(mget 请求)的流程:
-
协调节点处理:节点 2(协调节点)接收到
mget请求后,会根据每个文档ID的哈希值确定对应的分片。 -
分片路由:协调节点会根据每个文档ID的哈希值确定其所在的分片,并将查询请求路由到负责相应分片的节点上。
-
并行查询:每个数据节点接收到查询请求后,并行地搜索相应的文档。每个节点将同时处理其负责的文档ID的查询请求。
-
结果汇总:每个数据节点将查询结果返回给协调节点。
-
结果返回:协调节点收到来自数据节点的查询结果后,会将它们汇总并返回给 Elasticsearch 客户端。
3.搜索(Search)查询
3.1 索引建立
进行全文检索前,先回顾一下索引文档时的如何对全文进行分析处理
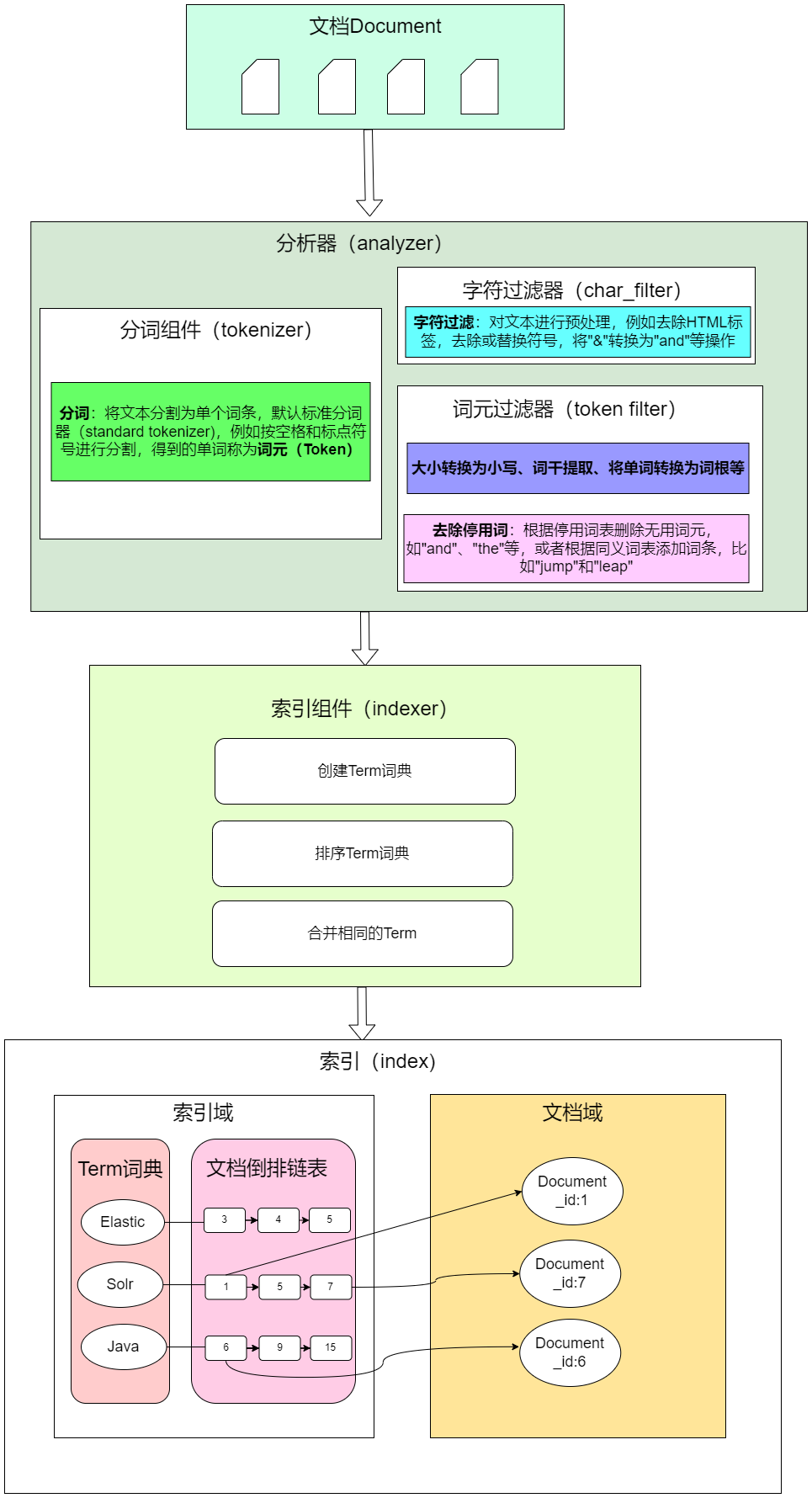
建立索引的过程中,对全文数据进行分析在Elasticsearch(ES)中通过分词组件和语言处理组件来完成。作用包括:
- 分词器:将文本分割为单个词条,例如按空格和标点符号进行分割,得到的单词称为词元(Token)。
- 字符过滤器:对文本进行预处理,例如去除HTML标签,替换符号,将"&"转换为"and"等操作。
- Token过滤器:根据停止词表删除无用词元,如"and"、“the"等,或者根据同义词表添加词条,比如"jump"和"leap”。
- 过滤器语言处理:对词元(Token)进行与语言相关的处理,例如转换为小写、词干提取、将单词转换为词根等形式。这些处理后的结果称为词(Term)。
完成分析后,将分析器输出的词传递给索引组件,生成倒排索引和正排索引,并将其存储到文件系统中。
下面图示参考:https://blog.csdn.net/weixin_41947378/article/details/109405386 3.6 创建索引流程总结
注意,以下表示一个es节点
在Elasticsearch中,配置分词器(Tokenizer)和语言处理组件(Token Filter)是通过创建或修改索引的分析器(Analyzer)来实现的。下面是一个简单的配置示例:
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
// 这里是自定义的分析器名称
"type": "custom", // 自定义分析器
"tokenizer": "standard", // 使用标准分词器作为分词器
"char_filter": ["remove_symbols"], // 使用字符过滤器去除无用符号
"filter": [
"lowercase", // 将所有词元转换为小写
"english_stop" // 停用词过滤器
]
}
},
"filter": {
"english_stop": {
// 停用词过滤器的配置
"type": "stop", // 停用词类型
"stopwords": "_english_" // 使用内置的英文停用词表
}
},
"char_filter": {
"remove_symbols": {
"type": "mapping",
"mappings": ["=>", ",", ".", "!"] // 需要移除的符号列表
}
}
}
}
}
要应用此配置,可以在创建索引时指定该分析器,或者在已有索引上修改分析器配置。例如:
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "my_analyzer" // 指定使用自定义分析器
}
}
}
}
当文档的content字段被索引时,将会使用my_analyzer分析器进行文本分析和处理。
3.2 文档读取过程
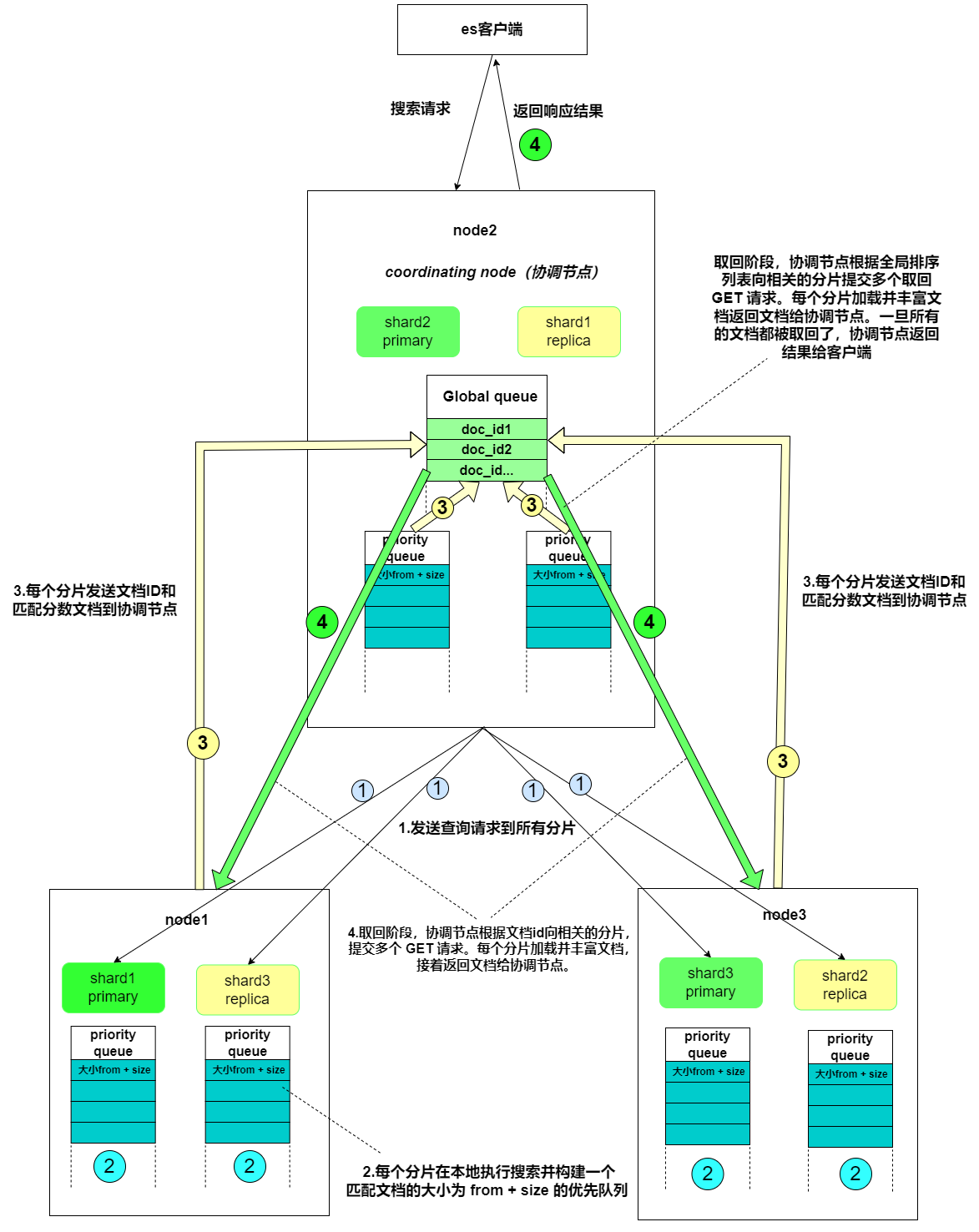
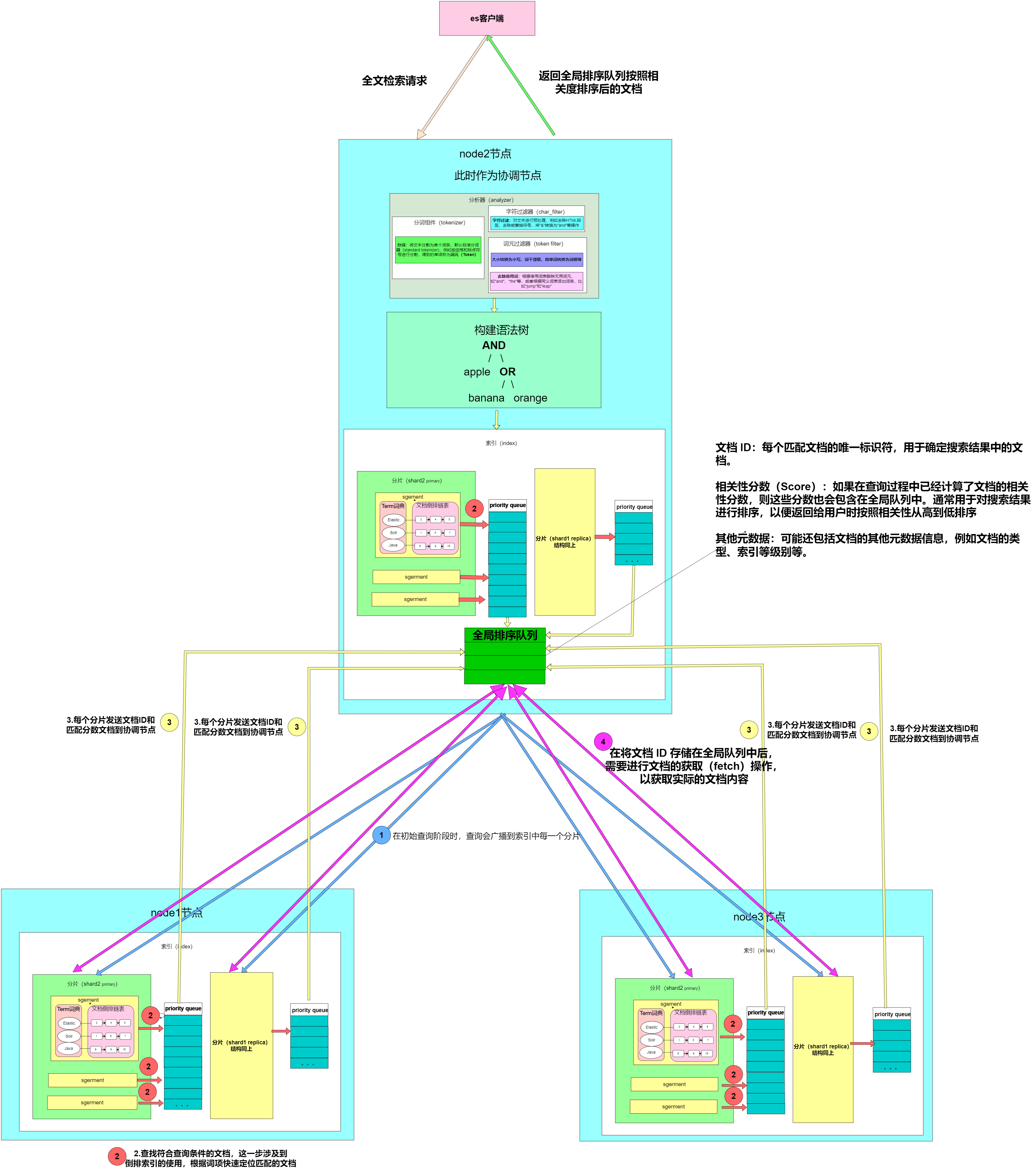
- 搜索系统通常采用两阶段查询(query_then_fetch):首先在第一阶段查询到匹配的文档标识符(DocID),然后在第二阶段查询这些标识符对应的完整文档。
- 在初始查询阶段时,查询会广播到索引中每一个分片拷贝(主分片或者副本分片)。 每个分片在本地执行搜索并构建一个匹配文档的大小为 from + size 的优先队列。PS:在搜索的时候是会查询Filesystem Cache的,但是有部分数据还在Memory Buffer,所以搜索是近实时的。
- 每个分片返回各自优先队列中 所有文档的 ID 和排序值(例如 _score) 给协调节点,它合并这些值到自己的优先队列中来产生一个全局排序后的结果列表。
- 接下来就是 取回阶段,协调节点辨别出哪些文档需要被取回并向相关的分片提交多个 GET 请求。每个分片加载并丰富文档,如果有需要的话,接着返回文档给协调节点。一旦所有的文档都被取回了,协调节点返回结果给客户端。
Query Then Fetch的搜索类型在文档相关性打分的时候参考的是本分片的数据,这样在文档数量较少的时候可能不够准确,DFS Query Then Fetch增加了一个预查询的处理,询问Term和Document frequency,这个评分更准确,但是性能会变差。
3.3 执行全文检索
-
分析器(Analyzer)处理查询词:首先,针对查询语句中的检索词,使用相同的分析器进行分析。分析器会将查询词拆分成词项(Tokens),这与建立索引时的处理方式相同。
-
构建查询语法树:根据查询语句的语法规则,将其转换成一棵语法树。这棵语法树描述了查询的逻辑结构,包括查询条件之间的逻辑关系以及操作符的作用。
-
匹配文档:根据语法树,在索引中查找符合查询条件的文档。这一步涉及到倒排索引的使用,根据词项快速定位匹配的文档。
-
评分:对匹配到的文档列表进行相关性评分。评分策略通常使用 **TF/IDF(词频-逆文档频率)或 BM25(BM25算法)**等算法,根据查询词项在文档中的出现频率、在索引中的逆文档频率等因素计算文档的相关性分数。
-
排序:根据评分结果,对匹配到的文档列表进行排序。相关性分数高的文档排在前面,以便用户首先看到最相关的结果。
3.4 TF/IDF模型和BM25算法
1.算分逻辑的步骤
Elasticsearch的算分逻辑是基于文档的相关性评分,通常使用**TF/IDF(词频-逆文档频率)或BM25(BM25算法)**等算法来计算。在搜索查询中,算分逻辑可以简单概括为以下几个步骤:
-
词项匹配度计算:首先,根据查询语句中的词项在文档中的出现频率(TF)以及在整个索引中的逆文档频率(IDF),计算每个词项的匹配度得分。
-
字段权重计算:对于查询语句中的每个字段,可以为其指定不同的权重,以反映字段在整个查询中的重要性。字段权重可以通过配置或者默认值进行设置。
-
文档长度归一化:由于文档长度可能不同,需要对匹配到的文档进行长度归一化,以确保长文档和短文档在得分计算中公平竞争。
-
评分公式计算:根据算分模型(如TF/IDF或BM25)以及以上步骤得到的各项参数,计算文档的最终相关性得分。这个得分可以综合考虑词项匹配度、字段权重、文档长度等因素。
-
结果排序:最后,根据得分对匹配到的文档进行排序,通常相关性得分高的文档排在前面,以便用户首先看到最相关的结果。
2.TF/IDF模型和BM25算法的区别
TF/IDF模型和BM25算法都是用于信息检索领域的相关性评分模型,它们在计算文档相关性时有一些区别:
-
基本原理:
- TF/IDF模型:TF/IDF模型基于两个因素:Term Frequency(TF,词频)和Inverse Document Frequency(IDF,逆文档频率)。TF表示一个词项在文档中出现的频率,IDF表示该词项在整个文档集合中的稀有程度。TF/IDF模型的基本思想是,如果一个词项在当前文档中出现频繁,但在整个文档集合中罕见,那么它很可能是一个关键词,应该被赋予较高的权重。
- BM25算法:BM25算法是一种改进的基于统计概率的信息检索算法。它考虑了词项的频率、文档长度以及查询中的词项频率等因素。BM25算法根据==词项的频率和文档长度动态调整权重,==使得算分更加准确且适应不同类型的文档集合。
-
权重计算:
- TF/IDF模型:TF/IDF模型的权重计算通常由两部分组成,即TF和IDF。TF表示一个词项在文档中的出现频率,通常可以通过简单计数或标准化等方式获得。IDF表示一个词项在整个文档集合中的稀有程度,通常使用对数转换的方式计算。
- BM25算法:BM25算法的权重计算包含了多个参数,包括词项的频率、文档长度、查询中的词项频率等。BM25算法使用一种动态调整的方式来计算权重,根据不同的文档长度和查询条件,使得权重更加适应不同的情况。
-
文档长度考虑:
- TF/IDF模型:TF/IDF模型没有显式考虑文档长度的影响,即无论文档的长度如何,词项的TF和IDF权重都保持不变。
- BM25算法:BM25算法考虑了文档的长度对相关性评分的影响,通过一个长度调节参数对文档长度进行调整,使得长文档和短文档之间的评分更加平衡。
-
适用性:
- TF/IDF模型:TF/IDF模型在较小规模的文档集合中表现良好,但在面对大规模文档集合或文档长度变化较大的情况下,可能会出现一些不足。
- BM25算法:BM25算法对于大规模文档集合和不同长度的文档表现更为稳健,因为它考虑了文档长度和查询条件的影响,能够更准确地评估文档的相关性。
4.参考链接
[1] ES详解 - 原理:ES原理之读取文档流程详解 | Java 全栈知识体系 (pdai.tech)
[2] ElasticSearch 基本原理之全文检索_elasticsearch全文检索原理-CSDN博客
[3] ElasticSearch查询流程详解 - 掘金 (juejin.cn)
[4] 执行分布式检索 | Elasticsearch: 权威指南 | Elastic
本文如有错漏之处,烦请私信或者指出
更多【django-Elasticsearch进阶篇(二):Elasticsearch查询原理】相关视频教程:www.yxfzedu.com
相关文章推荐
- git-如何使用git-credentials来管理git账号 - 其他
- prompt-Anaconda Powershell Prompt和Anaconda Prompt的区别 - 其他
- python-Dhtmlx Event Calendar 付费版使用 - 其他
- gpt-ChatGPT、GPT-4 Turbo接口调用 - 其他
- ddos-ChatGPT 宕机?OpenAI 将中断归咎于 DDoS 攻击 - 其他
- junit-Lua更多语法与使用 - 其他
- prompt-Presentation Prompter 5.4.2(mac屏幕提词器) - 其他
- css-CSS 网页布局 - 其他
- spring-idea中搭建Spring boot项目(借助Spring Initializer) - 其他
- 网络-# 深度解析 Socket 与 WebSocket:原理、区别与应用 - 其他
- prompt-屏幕提词软件Presentation Prompter mac中文版使用方法 - 其他
- java-AVL树详解 - 其他
- spring-在Spring Boot中使用JTA实现对多数据源的事务管理 - 其他
- 3d-原始html和vue中使用3dmol js展示分子模型,pdb文件 - 其他
- ddos-DDoS攻击剧增,深入解析抗DDoS防护方案 - 其他
- spring boot-AI 辅助学习:Spring Boot 集成 PostgreSQL 并设置最大连接数 - 其他
- golang-go中的rune类型 - 其他
- python-深度学习之基于Python+OpenCV(DNN)性别和年龄识别系统 - 其他
- 运维-Linux-Docker的基础命令和部署code-server - 其他
- 算法-421. 数组中两个数的最大异或值/字典树【leetcode】 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- mysql-java八股文(mysql篇)
- 计算机视觉-计算机视觉与深度学习 | 基于视觉惯性紧耦合的SLAM后端优化算法
- c++-【C++】从入门到精通第三弹——友元函数与静态类成员
- spring boot-java 企业工程管理系统软件源码+Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
- 科技-企业财务数字化转型的机遇有哪些?_光点科技
- 科技-云计算的大模型之争,亚马逊云科技落后了?
- c语言-C语言 变量
- 物联网-USB PD v1.0快速充电通信原理
- 网络-网络安全与TikTok:年轻一代的数字素养
- 安全-安全防御——四、防火墙理论知识
