数据仓库-ETL的数据挖掘方式
推荐 原创ETL的基本概念
-
数据抽取(Extraction):从不同源头系统中获取所需数据的步骤。比如从mysql中拿取数据就是一种简单的抽取动作,从API接口拿取数据也是。
-
数据转换(Transformation):清洗、整合和转化原始数据以适应目标存储或分析系统的阶段。从mysql中拿到数据之后对数据进行处理,像对数据的一些修改,删除,新增都算是,学过编程的同学应该很容易理解。
-
数据加载(Loading):将经过处理的数据载入到数据仓库或其他目标平台的过程。这个就更简单了,就是将数据加载到目标系统里去,这个系统可以是一个接口,可以是一个数据库,可以是一个平台。
ETL在数据挖掘中的作用
-
预处理与清洗:去除无关数据,填充缺失值,统一数据格式等。
-
结构化处理:通过ETL将非结构化或半结构化数据转化为便于挖掘的结构化数据。
其中非结构化或半结构化数据是指那些不符合传统关系数据库严格定义格式的数据类型。非结构化数据通常没有预定义的数据模型,如文本文件、电子邮件、社交媒体帖子、图片、音频和视频等,这些数据的内部结构各异,难以直接通过数据库表格进行管理和分析。而半结构化数据则具有某种层次性或自我描述性的结构,但不遵循固定模式,例如XML、JSON文件,它们包含标签或者键值对形式的数据,比非结构化数据更易于处理,但仍需要特殊的方法和技术来提取和解析其中的有效信息。
-
数据集成:跨多个源系统集成相关数据,为后续的数据挖掘提供全面信息。
ETL数据挖掘的具体实现方式
数据抽取阶段的数据挖掘准备
-
定义数据源及抽取策略:选择对数据挖掘有价值的数据源并制定合理的抽取规则
-
特征选取:在抽取过程中识别和提取关键业务指标作为挖掘特征
数据转换阶段的数据预处理与优化
-
数据质量评估与提升:实施数据去重、异常值检测与处理等操作
-
特征工程:构建衍生变量、进行特征编码、降维等技术以优化数据集用于挖掘任务
数据加载阶段的数据组织与利用
-
目标数据集市构建:基于挖掘目标设计数据模型并组织加载后的数据
-
数据索引与分区:提高大规模数据查询和挖掘效率

ETLCloud数据挖掘方式实操
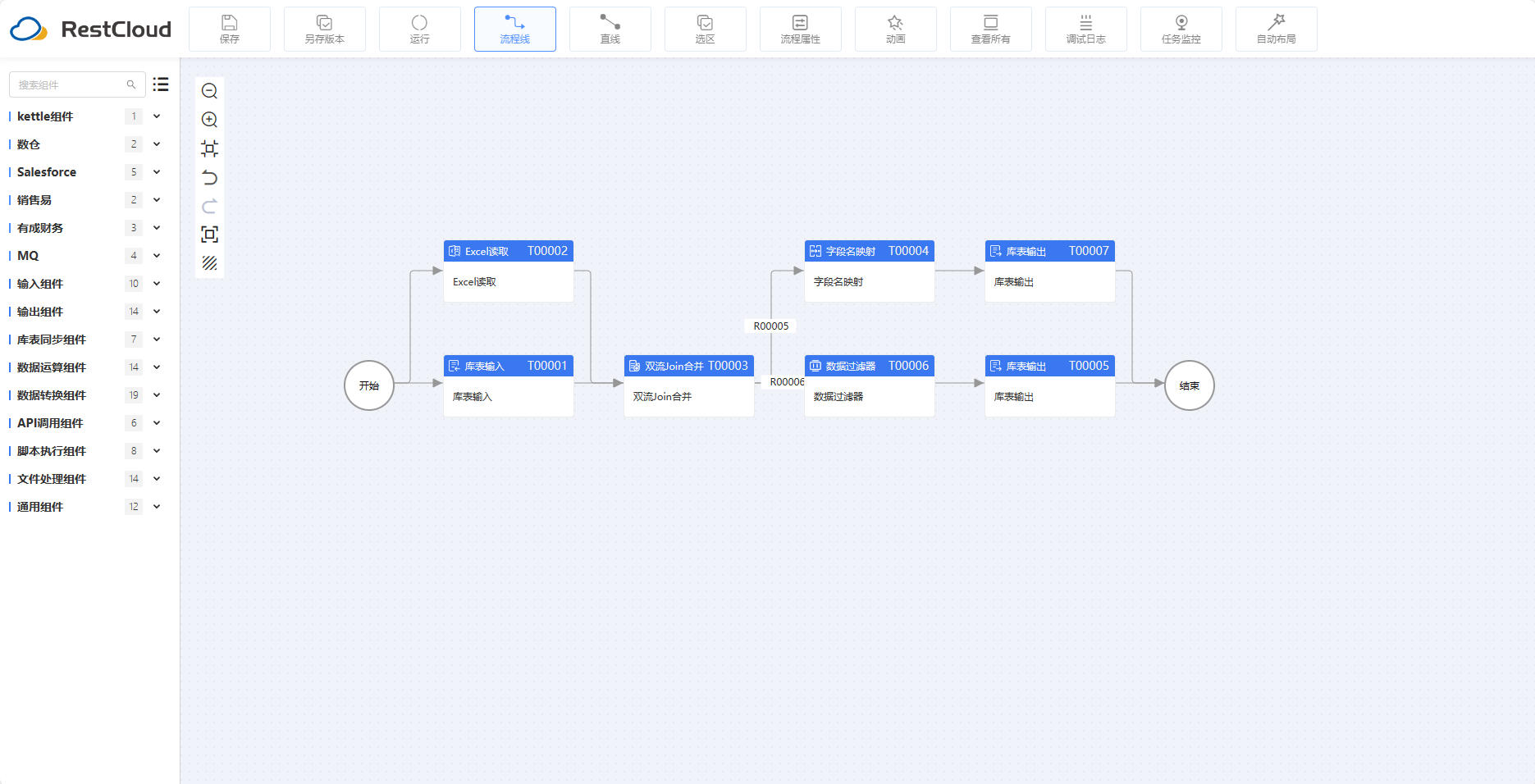
从Excel和MySQL中抽取数据然后清洗转换、分离,分别输出到两个数据库里
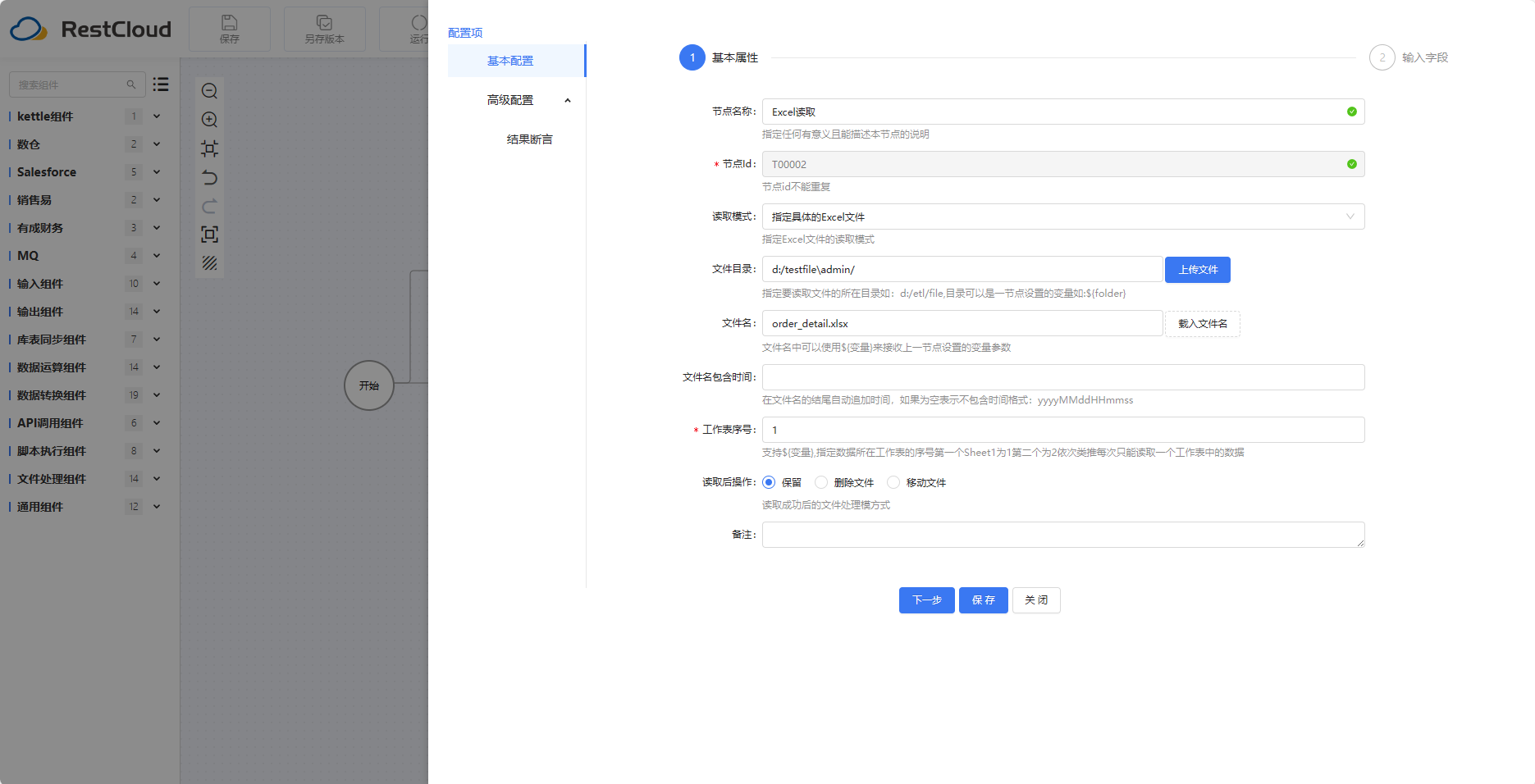
先配置Excel文件读取,注意输入字段配置
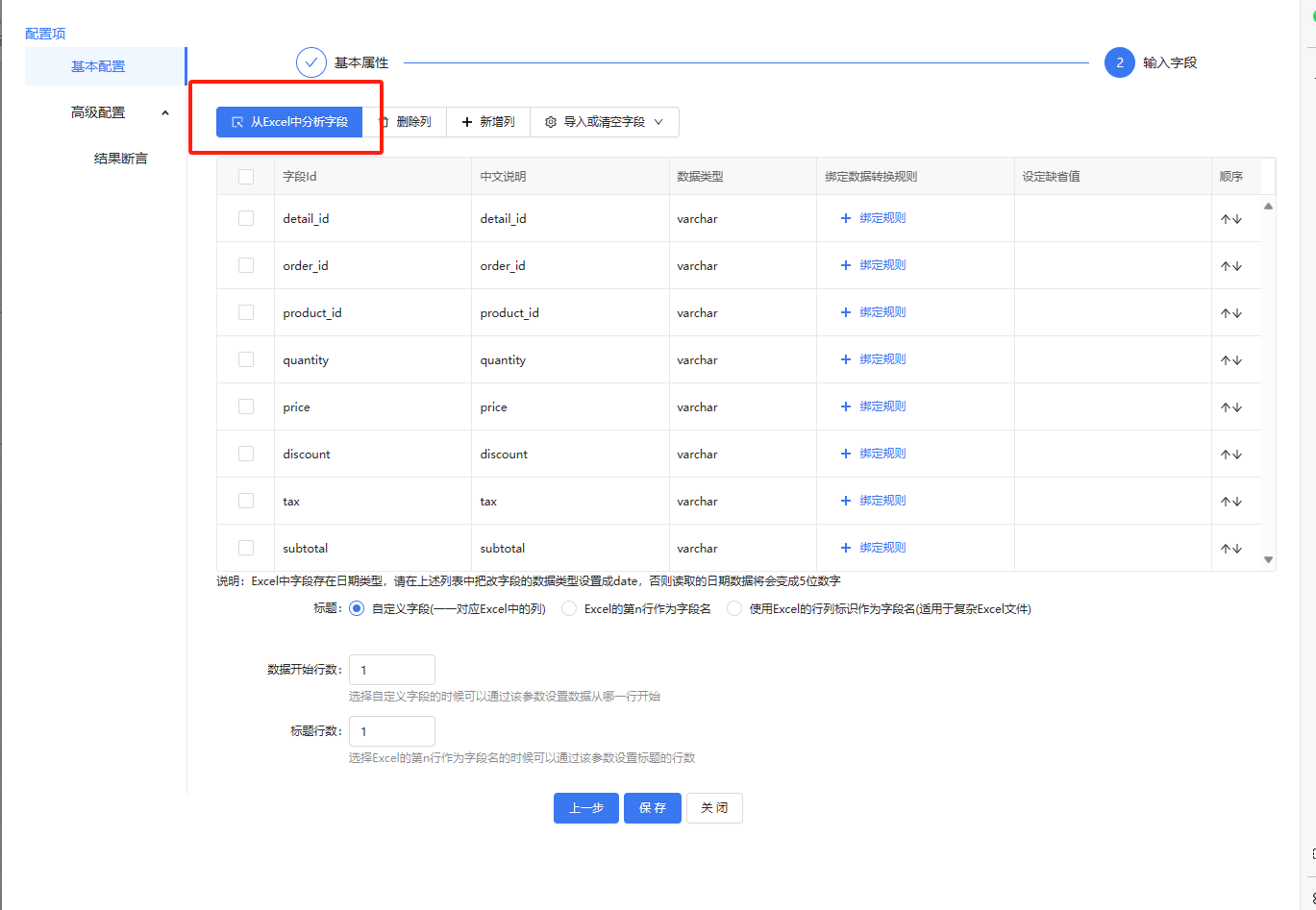
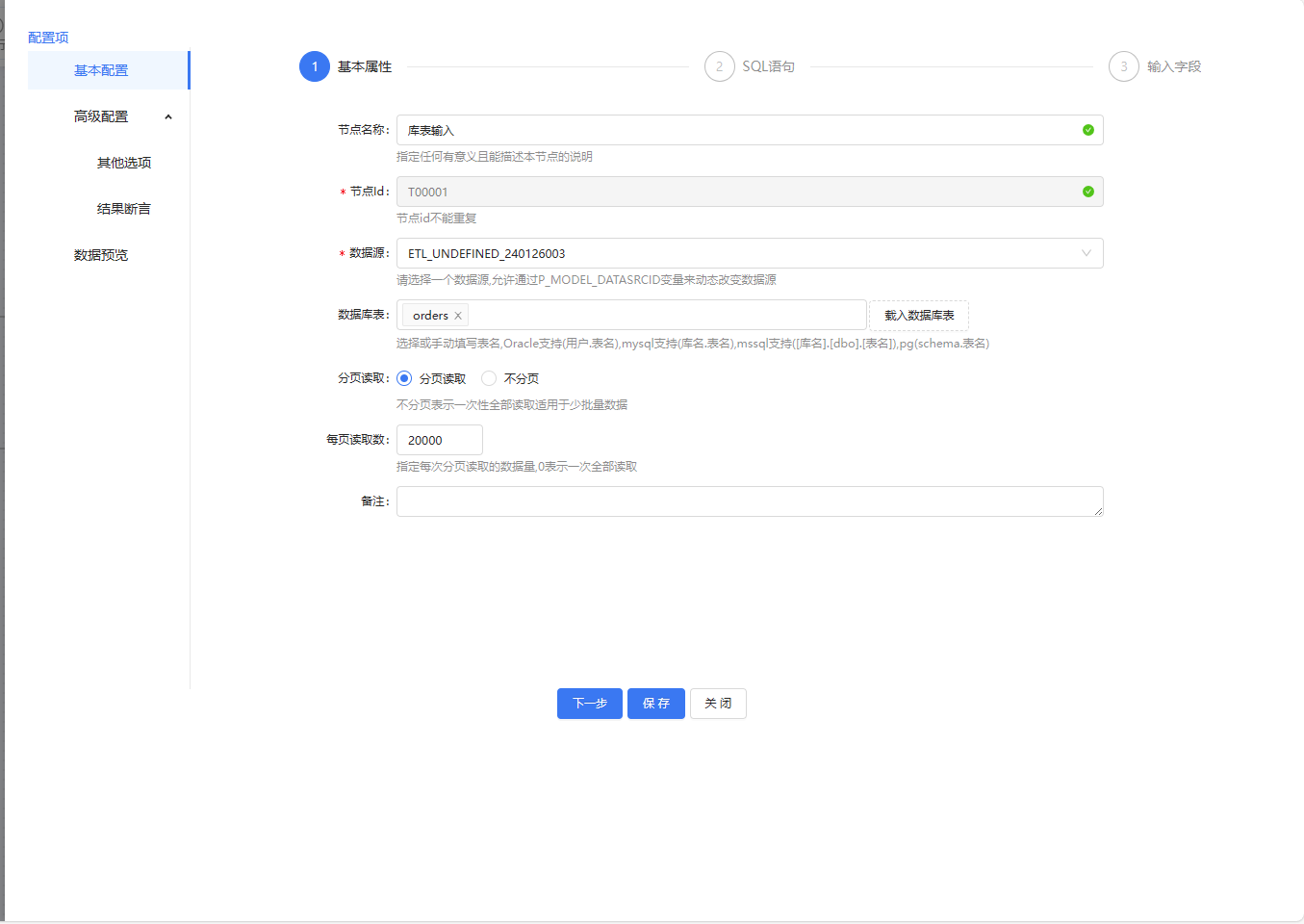
库表输入组件,sql语句可以自定义,输入字段可以自行增多或减少
比如增加一个test字段,设定缺省值,后面节点就可以拿到该字段的值,新增的字段并不会修改数据库

双流合并基础配置,需注意关联条件配置,最后两个是对字段名的数量进行设置,选择想要的字段

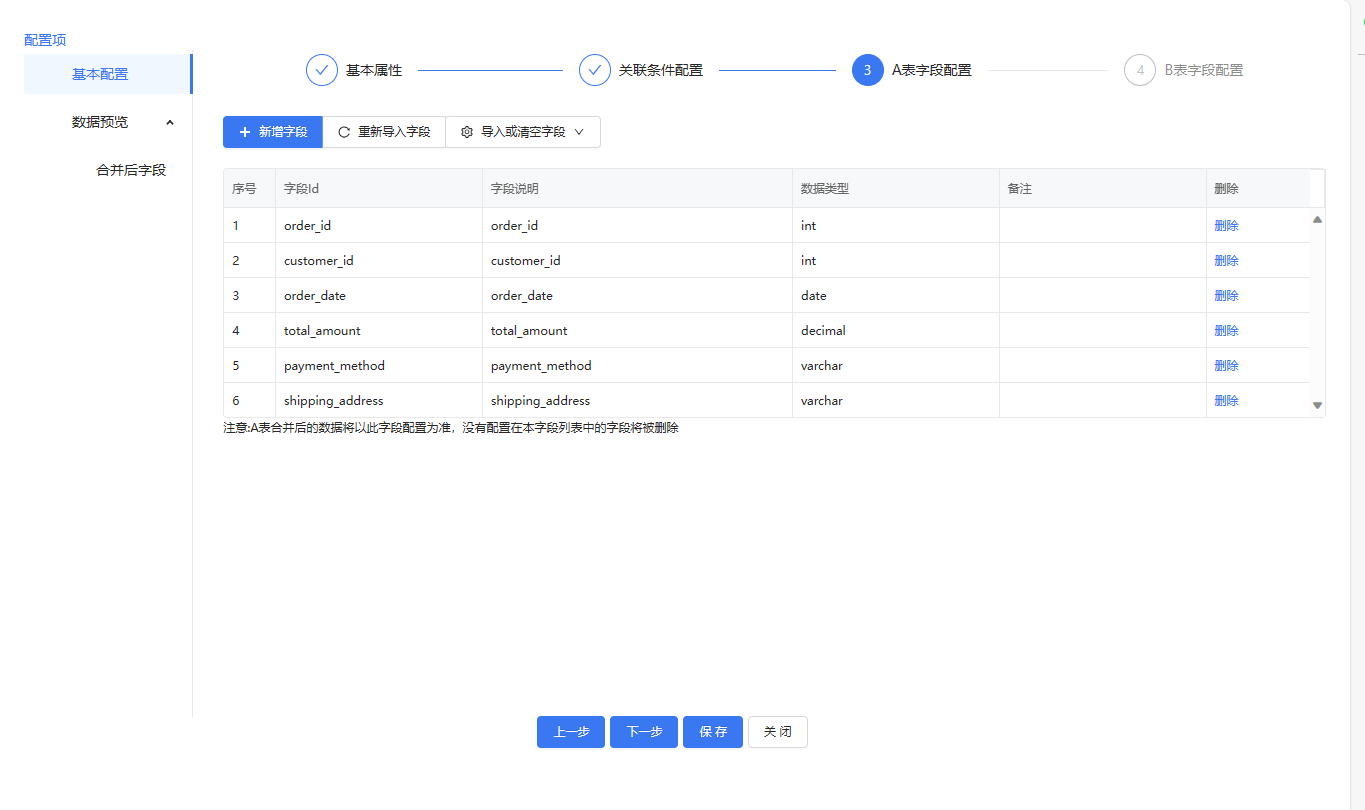
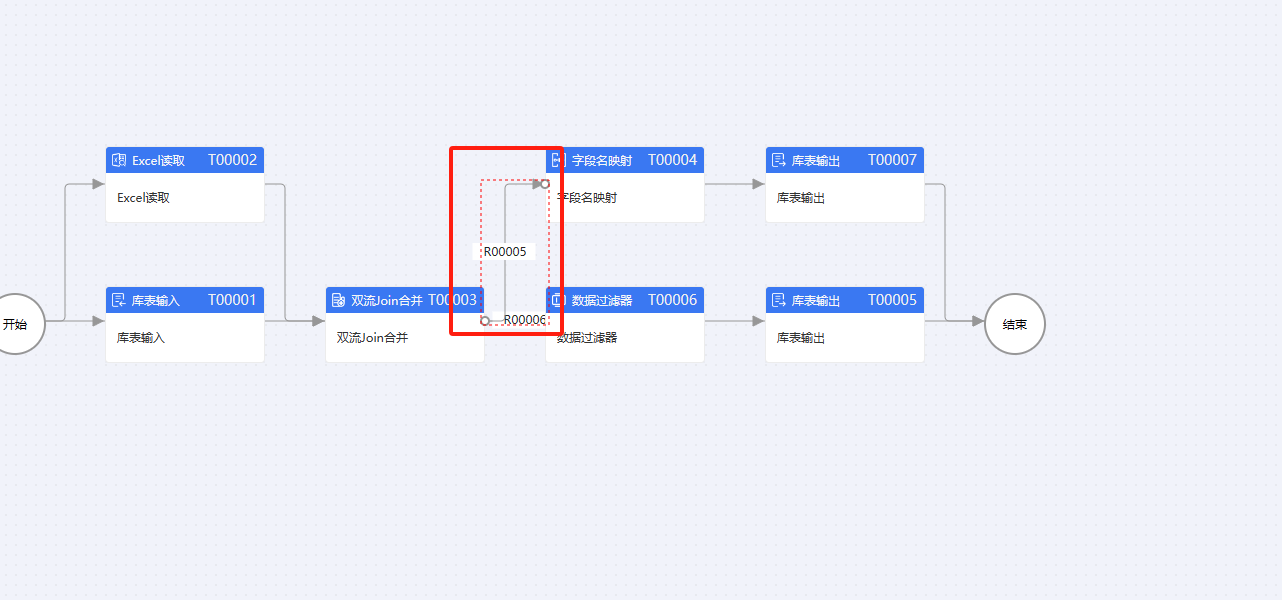
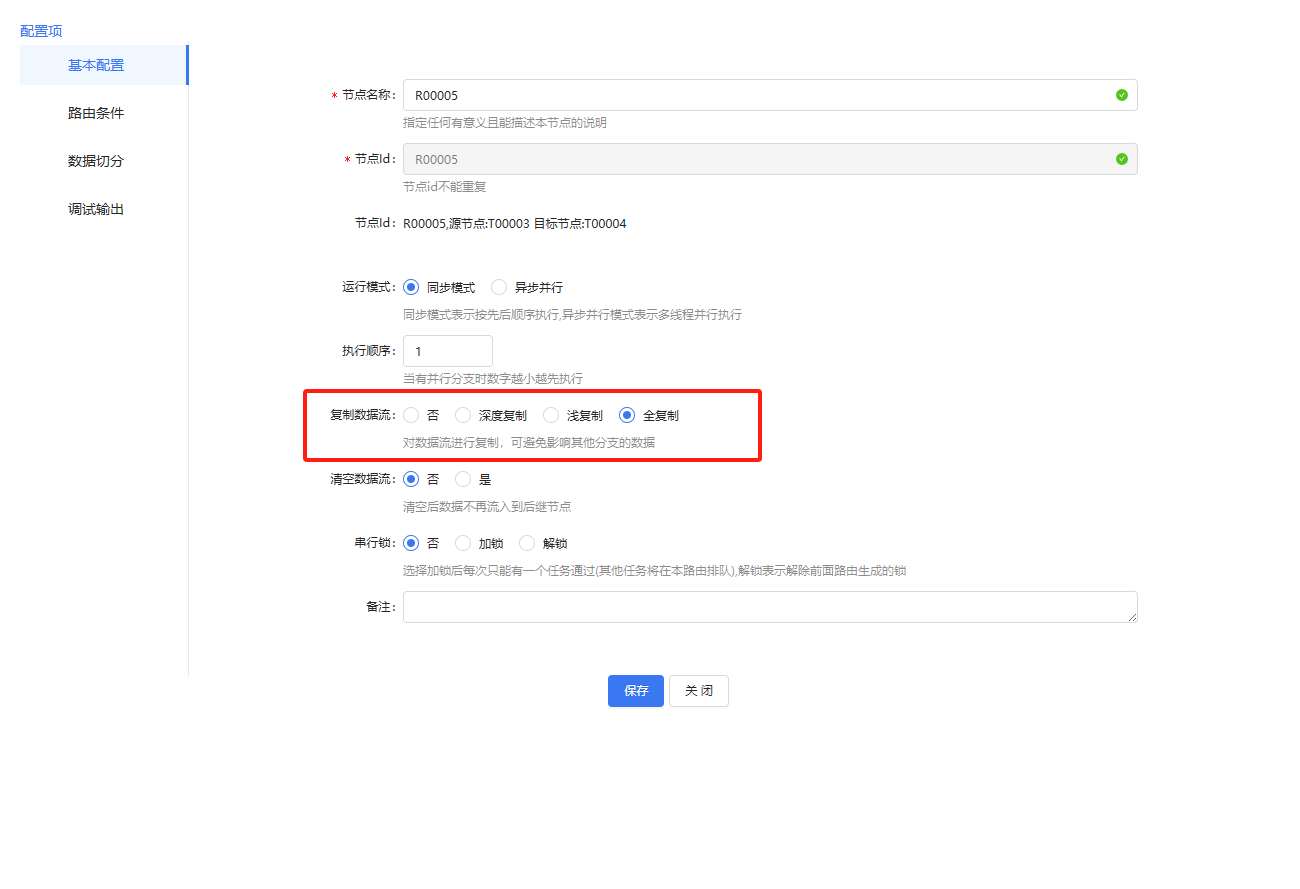
其中路由线的设置,这个要注意一点,两条线都需要数据可选择全复制
数据过滤组件,选择过滤payment_method值为Credit Card的数据

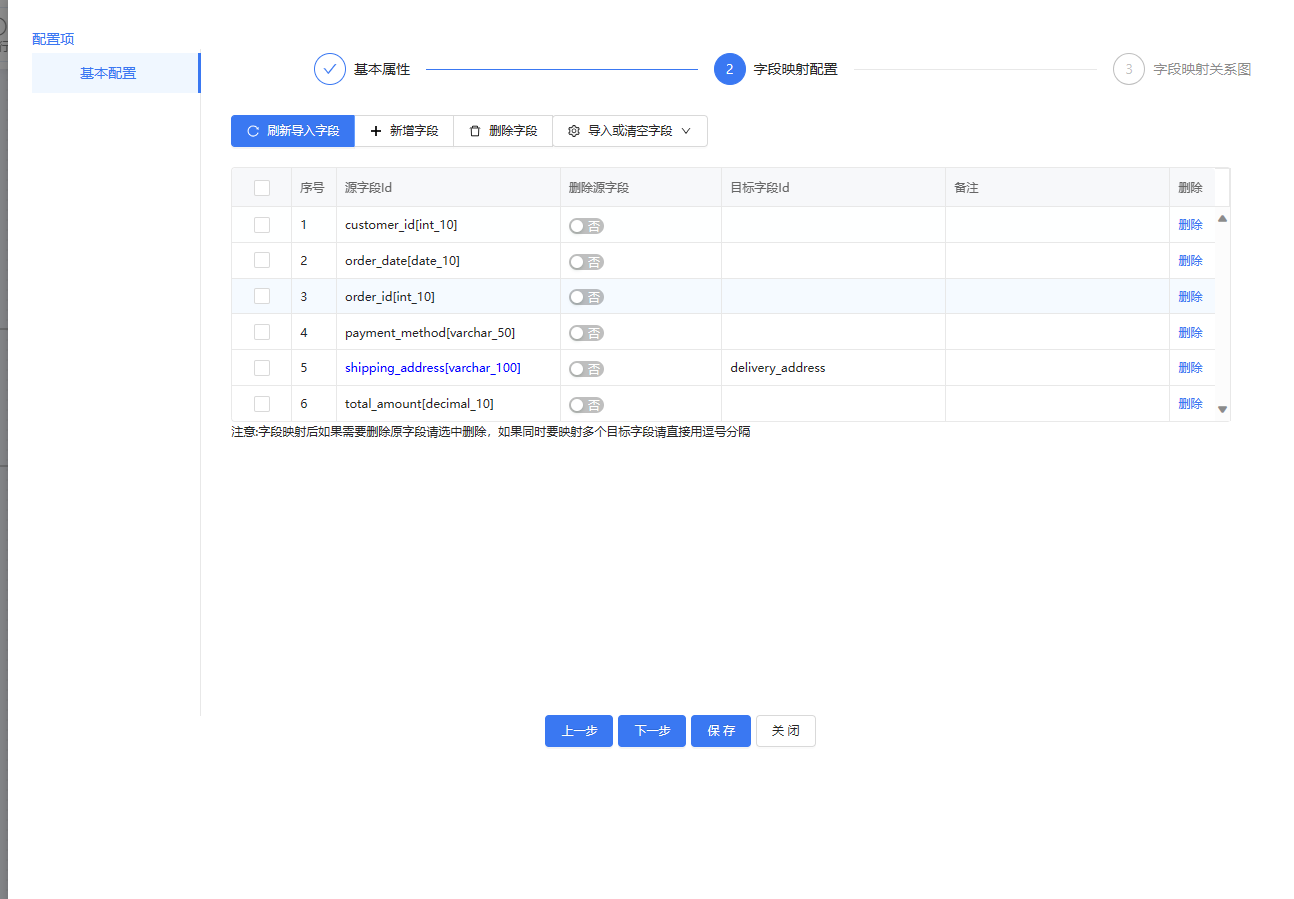
字段映射组件,目标字段是我表里没有的,是一个新增字段
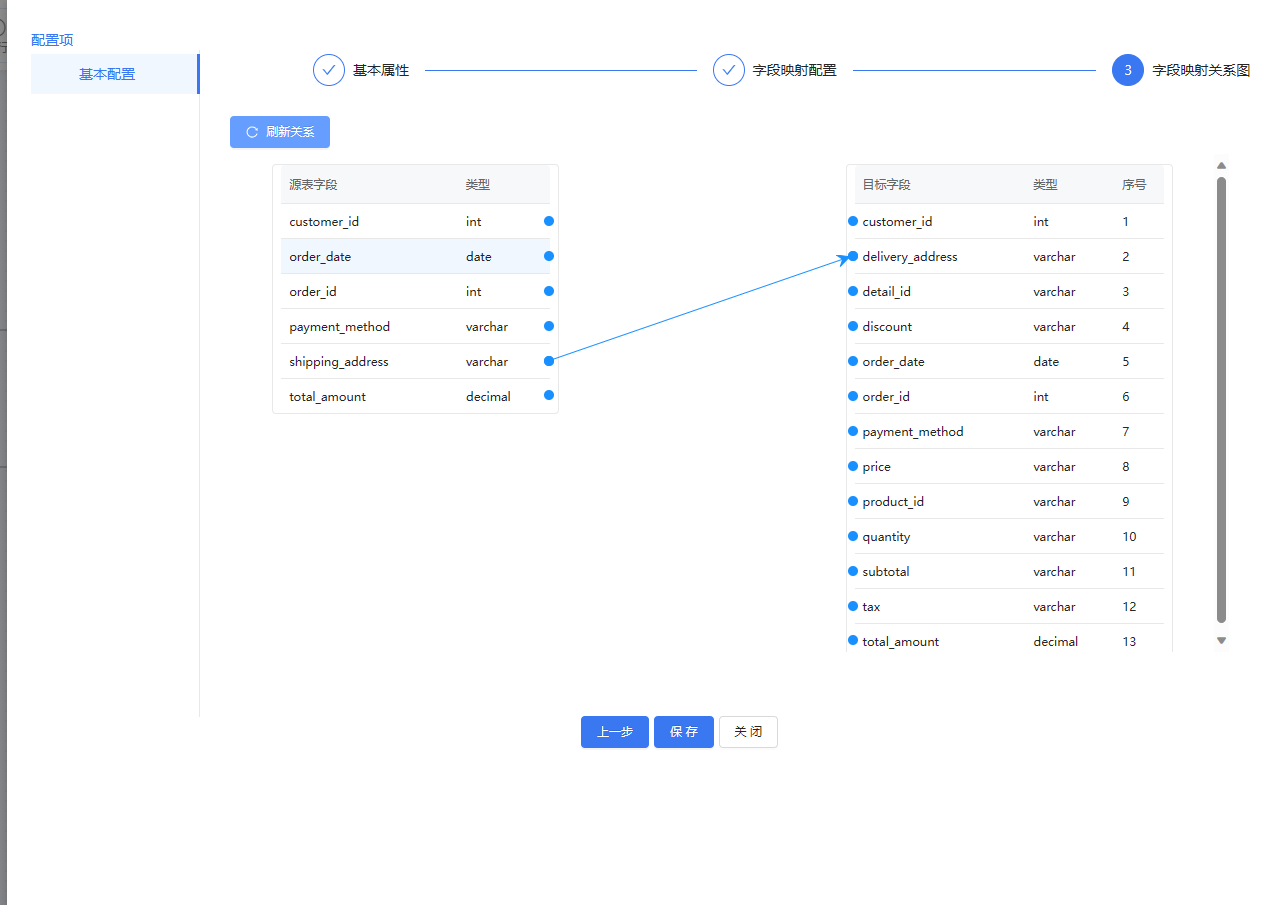
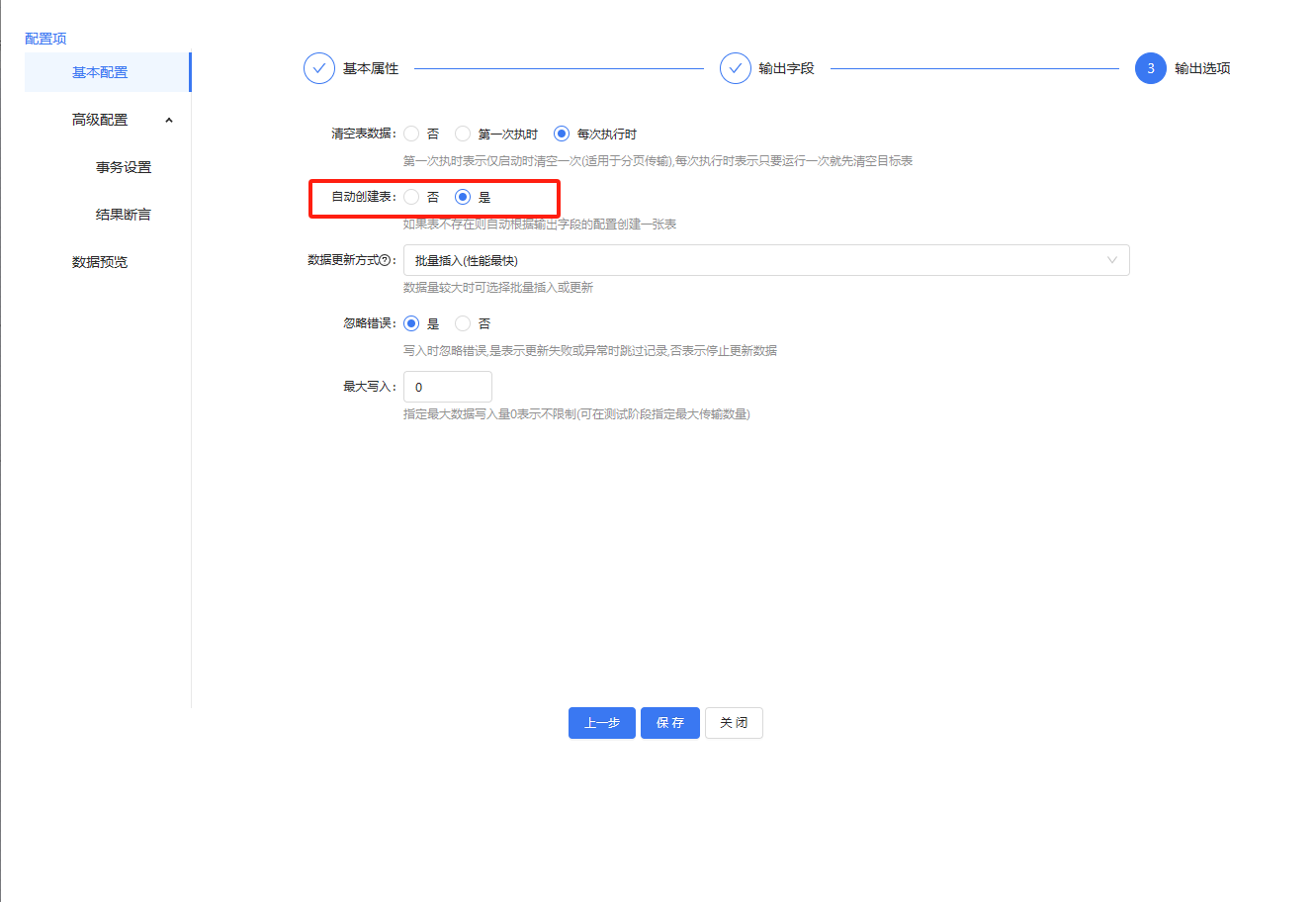
库表输出,输出字段从其他组件那边获取就行,选择自动建表,数据会直接入库
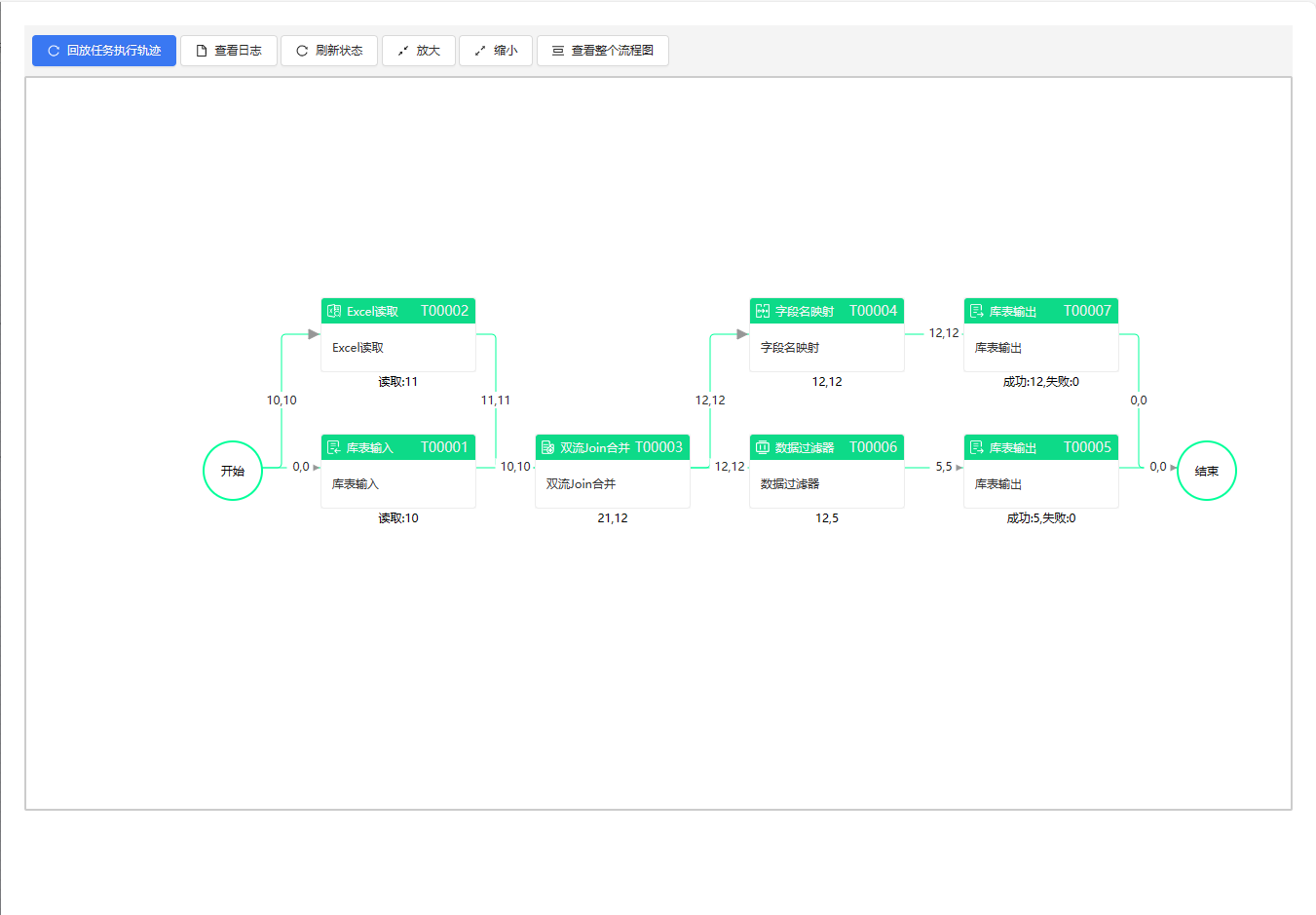
有分支的流程在结束节点要选择

流程成功运行
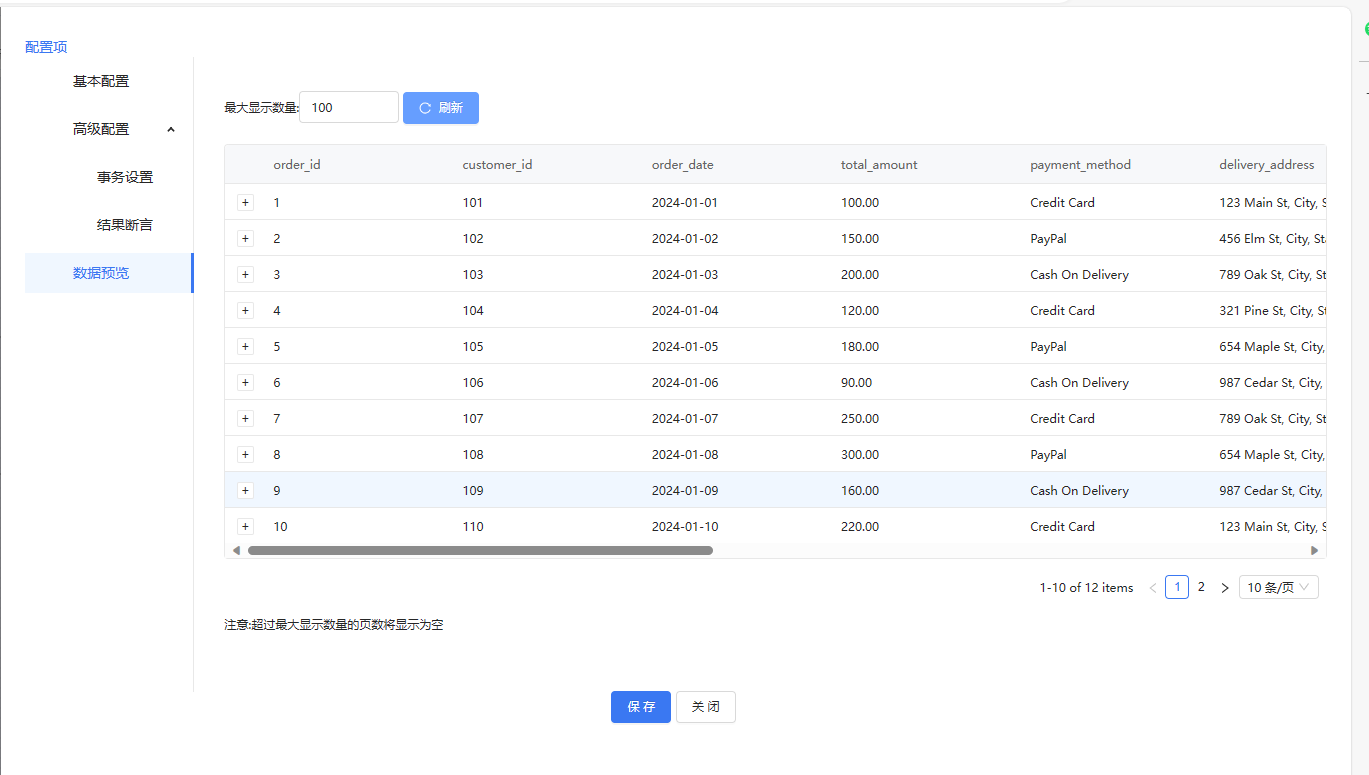
数据预览
最后
在实际应用中,ETLCloud展现了其高效的数据抽取能力,无论是从关系型数据库如MySQL,还是非结构化数据源如Excel文件,都能轻松实现数据提取。其灵活的数据转换功能强大,支持诸如去重、异常值检测、特征构建等深度预处理操作,极大地优化了数据集的质量和挖掘效率。
更多【数据仓库-ETL的数据挖掘方式】相关视频教程:www.yxfzedu.com
相关文章推荐
- java-【Proteus仿真】【51单片机】多路温度控制系统 - 其他
- java-【Vue 透传Attributes】 - 其他
- github-在gitlab中指定自定义 CI/CD 配置文件 - 其他
- 编程技术-四、Vue3中使用Pinia解构Store - 其他
- apache-Apache Druid连接回收引发的血案 - 其他
- 编程技术-剑指 Offer 06. 从尾到头打印链表 - 其他
- 编程技术-linux查看端口被哪个进程占用 - 其他
- 编程技术-Linux安装java jdk配置环境 方便查询 - 其他
- hdfs-wpf 命令概述 - 其他
- 编程技术-降水短临预报模型trajGRU简介 - 其他
- jvm-函数模板:C++的神奇之处之一 - 其他
- ddos-ChatGPT 宕机?OpenAI 将中断归咎于 DDoS 攻击 - 其他
- 云原生-云原生周刊:KubeSphere 3.4.1 发布 | 2023.11.13 - 其他
- apache-从零开始Apache2配置php服务并支持网页访问 - 其他
- easyui-【开源三方库】Easyui:基于OpenAtom OpenHarmony ArkUI深度定制的组件框架 - 其他
- 算法-《数据结构、算法与应用C++语言描述》-队列的应用-工厂仿真 - 其他
- 编程技术-蓝桥 1111 第 3 场算法双周赛 深秋的苹果【算法赛】python解析 - 其他
- easyui-ChatRule:基于知识图推理的大语言模型逻辑规则挖掘11.10 - 其他
- hadoop-搭建完全分布式Hadoop - 其他
- 容器-【问题记录】docker pull 镜像的时候 devel 版本和无 devel 版本的差别 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
