python-【Neo4j系列】Neo4j之CQL语句和函数介绍
推荐 原创本文将对Neo4j中的CQL语句和CQL函数进行详细介绍。
作者:后端小肥肠
目录
1. 前言
CQL是Neo4j的查询语言,专为图数据库设计,使得对图形数据的操作变得简单而直观。本文我们将深入研究CQL的基本语法和一些强大的函数,为读者提供全面的了解,让大家能够更好地利用Neo4j构建和查询图数据库。
2. CQL语句
2.1. CQL简介
Neo4j的Cypher语言是为处理图形数据而构建的,CQL代表Cypher查询语言。像Oracle数据库具有查询 语言SQL,Neo4j具有CQL作为查询语言。CQL是Neo4j图形数据库的查询语言,是一种声明性模式匹配语言,遵循SQL语法,其语法是非常简单且人性化、可读的格式。
| CQL命令 | 用法 |
| CREATE | 创建节点,关系和属性 |
| MATCH | 检索有关节点,关系和属性数据 |
| RETURN | 返回查询结果 |
| WHERE | 提供条件过滤检索数据 |
| DALETE | 删除节点和关系 |
| REMOVE | 删除节点和关系的属性 |
| ORDER BY | 排序检索数据 |
| SET | 添加或更新标签 |
2.2. CREATE命令
CQL中的CREATE命令可以实现以下操作:
1. 创建没有属性的节点
2. 使用属性创建节点
3. 在没有属性的节点之间创建关系
4. 使用属性创建节点之间的关系
5. 为节点或关系创建单个或多个标签
语法格式:
CREATE (<node-name>:<label-name>)语法说明 :
| 语法元素 | 描述 |
| CREATE | 一个Neo4j CQL命令 |
| <node-name> | 我们要创建的节点名称 |
| <label-name> | 一个节点标签名称 |
注意事项 -
1. Neo4j数据库服务器使用此<node-name>将此节点详细信息存储在Database中作为Neo4j DBA或Developer,我们不能使用它来访问节点详细信息。
2. Neo4j数据库服务器创建一个<label-name>作为内部节点名称的别名。作为Neo4j DBA或Developer,我们应该使用此标签名称来访问节点详细信息。
2.3. MATCH命令
CQL中的MATCH命令可以实现以下操作:
1. 从数据库获取有关节点和属性的数据
2. 从数据库获取有关节点,关系和属性的数据
语法格式:
MATCH (<node-name>:<label-name>)语法说明:
| 语法元素 | 描述 |
| <node-name> | 节点名称 |
| <label-name>0 | 标签名称 |
2.4. RETURN命令
CQL中的RETURN命令可以实现以下操作:
1. 检索节点的某些属性
2. 检索节点的所有属性
3. 检索节点和关联关系的某些属性
4. 检索节点和关联关系的所有属性
语法格式:
RETURN
<node-name>.<property1-name>,
........
<node-name>.<propertyn-name>语法说明:
| 语法元素 | 描述 |
| <node-name> | 节点名称 |
| <propertyn-name> | 属性名称 |
2.5. MATCH和RETURN
CQL中我们不能单独使用MATCH或RETURN命令,因此我们应该合并这两个命令以从数据库检索数据:
1. 检索节点的某些属性
2. 检索节点的所有属性
3. 检索节点和关联关系的某些属性
4. 检索节点和关联关系的所有属性
语法格式:
MATCH Command
RETURN Command语法说明:
| 语法元素 | 描述 |
| MATCH命令 | 无 |
| RETURN命令 | 无 |
2.6. CREATE+MATCH+RETURN命令
现在演示一下CREATE+MATCH+RETURN命令组合用的场景:
1.创建一个标签为xfc的节点,name为小肥肠,age为18

2.查询小肥肠节点对应信息
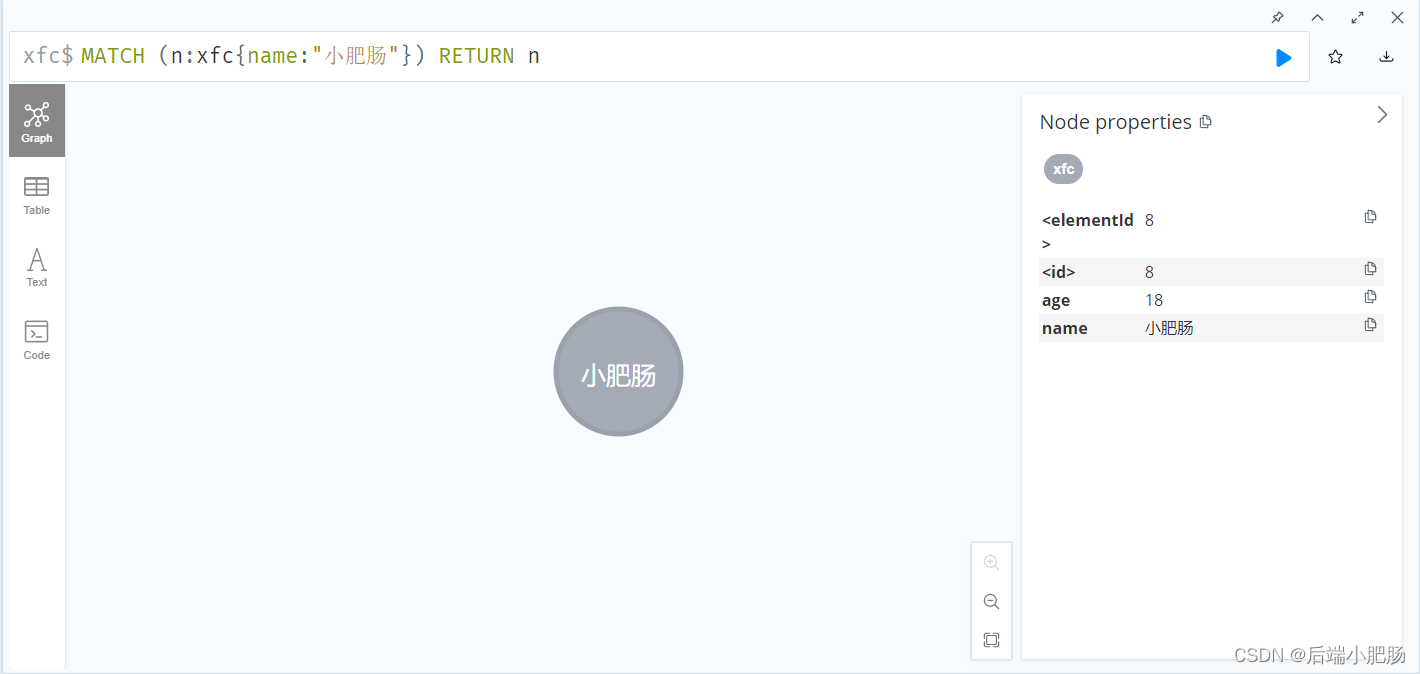
2.7. 关系基础
Neo4j图数据库遵循属性图模型来存储和管理其数据。根据属性图模型,关系应该是定向的, 否则,Neo4j将抛出一个错误消息。基于方向性,Neo4j关系被分为两种主要类型。
-
单向关系
-
双向关系
在以下场景中,我们可以使用Neo4j CQL CREATE命令来创建两个节点之间的关系。 这些情况适用于Uni和双向关系。
-
在两个现有节点之间创建无属性的关系
-
在两个现有节点之间创建有属性的关系
-
在两个新节点之间创建无属性的关系
-
在两个新节点之间创建有属性的关系
-
在具有WHERE子句的两个退出节点之间创建/不使用属性的关系
下图为在两个节点之间创建关系例子:
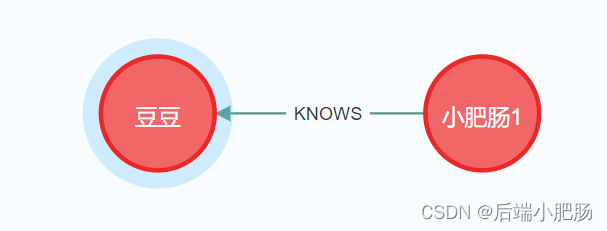
2.8. CREATE创建标签
CQL中CREATE命令可以用来进行一下操作:
1. 可以创建单个标签或者多个标签
2. 可以根据CREATE语句来创建标签之间的关系
语法格式:
CREATE (node1-name:lable1-name) - [relationship-name:relationship-lable-name]->(node2-name:lable2-name)语法说明:
| 语法元素 | 描述 |
| CREATE | 创建命令 |
| node1-name | from节点名称 |
| lable1-name | from节点标签 |
| node2-name | to节点名称 |
| lable2-name | to节点标签 |
| relationship-name | 关系名称 |
| relationship-lable-name | 关系标签 |
2.9. WHERE子句
像SQL一样,Neo4j CQL在CQL MATCH命令中提供了WHERE子句来过滤MATCH查询的结果。
语法格式:
WHERE <condition>复杂语法格式:
WHERE <condition> <boolean-operator> <condition>Neo4j支持以下布尔运算符在Neo4j CQL WHERE子句中使用以支持多个条件。
| 布尔运算符 | 描述 | 示例 |
| ADN | 逻辑与操作符,用于组合两个或多个条件,只有当所有条件为真时,整个表达式才为真。 | MATCH (n:Person) WHERE n.age > 25 AND n.name = 'John' RETURN n; |
| OR | 逻辑或操作符,用于组合两个或多个条件,只要至少有一个条件为真,整个表达式就为真。 | MATCH (n:Person) WHERE n.age > 25 OR n.name = 'John' RETURN n; |
| NOT | 逻辑非操作符,用于取反一个条件的真假。 | MATCH (n:Person) WHERE NOT n.name = 'John' RETURN n; |
Neo4j 支持以下的比较运算符,在 Neo4j CQL WHERE 子句中使用来支持条件。
| 比较运算符 | 描述 | 示例 |
| = | 用于检查两个值是否相等。 | MATCH (n:Person) WHERE n.age = 25 RETURN n; |
| <> | 用于检查两个值是否不相等。 | MATCH (n:Person) WHERE n.name <> 'John' RETURN n; |
| < | 用于检查一个值是否小于另一个值。 | MATCH (n:Person) WHERE n.age < 30 RETURN n; |
| > | 用于检查一个值是否大于另一个值。 | MATCH (n:Person) WHERE n.age > 25 RETURN n; |
| <= | 用于检查一个值是否小于或等于另一个值。 | MATCH (n:Person) WHERE n.age <= 30 RETURN n; |
| >= | 用于检查一个值是否大于或等于另一个值。 | MATCH (n:Person) WHERE n.age >= 25 RETURN n; |
where子句也可以创建关系:
语法格式:
MATCH (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>)
WHERE <condition>
CREATE (<node1-label-name>)-[<relationship-label-name>:<relationship-name>
{<relationship-properties>}]->(<node2-label-name>)语法说明:
上面的语句(语法格式)就是寻找两个已存在节点并在他两直接建立关系,我这里就不用表格拆开讲解了。
2.10. DELETE命令
CQL中DELETE命令可以用来进行以下操作:
1. 删除节点:
MATCH (n:Label)
WHERE n.property = 'value'
DELETE n;这将删除所有符合条件的节点(不包含关系)。替换 "Label" 和 "property" 为你的节点标签和属性。
2. 删除节点的特定关系:
MATCH (n:Label)-[r:RELATIONSHIP]->()
WHERE n.property = 'value'
DELETE r;
这将删除所有符合条件的节点的特定关系。
3. 删除节点及其关系:
MATCH (n:Label)
WHERE n.property = 'value'
DETACH DELETE n;
这将删除节点及其关系。
2.11. REMOVE命令
CQL中,REMOVE命令用于删除图元素的属性和标签:
1. 移除节点(关系)的属性:
MATCH (n:Label)
WHERE n.property = 'value'
REMOVE n.property;
筛选出 n.property = 'value'的节点,移除属性。
2. 移除节点(关系)的标签:
MATCH (n:Label)
REMOVE n:Label;
3. 同时移除节点(关系)的属性和标签:
MATCH (n:Label)
WHERE n.property = 'value'
REMOVE n.property, n:Label;
筛选出 n.property = 'value'的节点,移除属性和标签。
2.12. SET子句
有时,我们需要向现有节点或关系添加新属性,要做到这一点,Neo4j CQL 提供了一个SET子句,可以进行以下操作:
1. 设置节点属性
MATCH (n:标签 {id: 1})
SET n.属性 = '新值'这个查询会匹配具有标签 "标签" 和属性 "id" 值为 1 的节点,并将它的 "属性" 属性设置为 "新值"。
2. 设置关系属性
MATCH (a:节点标签)-[r:关系标签]->(b:节点标签)
WHERE a.id = 1 AND b.id = 2
SET r.属性 = '新值'这个查询会将从节点 a 到节点 b 的关系的 "属性" 设置为 "新值"。
3. 添加新属性或更新多个属性
MATCH (n:标签 {id: 1})
SET n.属性1 = '新值1', n.属性2 = '新值2'
2.13. ORDER BY排序
CQL在MATCH命令中提供了“ORDER BY”子句,对MATCH查询返回的结果进行排序。我们可以按升序或降序对行进行排序。默认情况下,它按升序对行进行排序。 如果我们要按降序对它们进行排序,我们需要使用DESC子句。以下是一些示例用法:
1. 按节点属性升序排序:
MATCH (n:Label)
RETURN n.property
ORDER BY n.property这将按节点的 "property" 属性的升序顺序返回结果。
2. 按节点属性降序排序:
MATCH (n:Label)
RETURN n.property
ORDER BY n.property DESC
这将按节点的 "property" 属性的降序顺序返回结果。
2.14. UNION和UNION ALL
与SQL一样,Neo4j CQL有两个子句,将两个不同的结果合并成一组结果
-
UNION
-
UNION ALL
UNION子句:
它将两组结果中的公共行组合并返回到一组结果中。 它不从两个节点返回重复的行。
限制:结果列类型和来自两组结果的名称必须匹配,这意味着列名称应该相同,列的数据类型应该相同。
MATCH (cc:CreditCard)
RETURN cc.id as id,cc.number as number,cc.name as name,
cc.valid_from as valid_from,cc.valid_to as valid_to
UNION
MATCH (dc:DebitCard)
RETURN dc.id as id,dc.number as number,dc.name as name,
dc.valid_from as valid_from,dc.valid_to as valid_toUNION ALL子句:
它结合并返回两个结果集的所有行成一个单一的结果集。它还返回由两个节点重复行。
限制:结果列类型和来自两组结果的名称必须匹配,这意味着列名称应该是相同的,列的数据类型应该是相同的。
MATCH (cc:CreditCard)
RETURN cc.id as id,cc.number as number,cc.name as name,
cc.valid_from as valid_from,cc.valid_to as valid_to
UNION ALL
MATCH (dc:DebitCard)
RETURN dc.id as id,dc.number as number,dc.name as name,
dc.valid_from as valid_from,dc.valid_to as valid_to2.15. LIMIT和SKIP子句
CQL中,LIMIT 和 SKIP 用于控制查询结果的数量和偏移。以下是它们的用法:
1. 使用 LIMIT 限制结果数量:
MATCH (n:Label)
RETURN n.property
LIMIT 10
这将返回满足条件的前 10 个节点的 "property" 属性。LIMIT 用于限制结果集的大小。
2. 使用 SKIP 跳过指定数量的结果:
MATCH (n:Label)
RETURN n.property
SKIP 5
这将返回从满足条件的节点中跳过前 5 个节点的 "property" 属性。SKIP 用于指定结果集中要跳过的数量。
3. 结合使用 LIMIT 和 SKIP 进行分页:
MATCH (n:Label)
RETURN n.property
SKIP 10
LIMIT 5
这将从满足条件的节点中跳过前 10 个,并返回接下来的 5 个节点的 "property" 属性。结合使用 SKIP 和 LIMIT 可以实现分页效果
2.16. MERGE
CQL中,MERGE 用于根据指定的模式创建或匹配节点和关系。其作用是确保在图数据库中存在满足指定条件的节点和关系,如果不存在,则创建它们,如果已存在,则不做任何更改。以下是 MERGE 的一些用法示例:
1. 使用 MERGE 创建或匹配节点:
MERGE (n:Label {id: 1})
ON CREATE SET n.property = 'value'
RETURN n
这将创建一个具有标签 "Label" 和属性 "id" 值为 1 的节点,如果这样的节点已存在,则不会创建,并且如果节点是新创建的,将设置属性 "property" 为 'value'。
2. 使用 MERGE 创建或匹配关系:
MATCH (a:Node), (b:Node)
WHERE a.id = 1 AND b.id = 2
MERGE (a)-[r:RELATIONSHIP]->(b)
ON CREATE SET r.property = 'value'
RETURN r
这将创建从节点 a 到节点 b 的关系 "RELATIONSHIP",如果这样的关系已存在,则不会创建,并且如果关系是新创建的,将设置属性 "property" 为 'value'。
2.17. IN操作符
CQL中,IN 关键字用于筛选属性值是否在指定的值列表中。以下是 IN 的用法示例:
1. 使用 IN 进行单个属性的筛选:
MATCH (n:Label)
WHERE n.property IN ['value1', 'value2', 'value3']
RETURN n
这将返回具有标签 "Label" 并且属性 "property" 的值在 ['value1', 'value2', 'value3'] 中的节点。
2. 使用 IN 结合其他条件进行复杂的筛选:
MATCH (n:Label)
WHERE n.type = 'Type1' AND n.status IN ['Active', 'Pending']
RETURN n
这将返回具有标签 "Label"、属性 "type" 为 'Type1' 且属性 "status" 在 ['Active', 'Pending'] 中的节点。
3. CQL函数
3.1. 字符串函数
与SQL一样,Neo4J CQL提供了一组String函数,用于在CQL查询中获取所需的结果。 以下是一些常见的字符串函数及其用法示例:
-
UPPER和LOWER- 将字符串转为大写或小写:RETURN UPPER('hello') AS upper_result, LOWER('WORLD') AS lower_result这将返回字符串 "hello" 的大写形式和字符串 "WORLD" 的小写形式。
-
SUBSTRING- 提取子字符串:RETURN SUBSTRING('Neo4j', 1, 3) AS substring_result这将返回从字符串 "Neo4j" 的位置 1 开始的长度为 3 的子字符串。
-
LENGTH- 获取字符串长度:RETURN LENGTH('Graph Database') AS length_result这将返回字符串 "Graph Database" 的长度。
-
TRIM- 去除字符串两端的空格:RETURN TRIM(' Hello ') AS trimmed_result这将返回去除了字符串两端空格的结果。
-
CONCAT- 连接字符串:RETURN CONCAT('Hello', ' ', 'World') AS concatenated_result这将返回连接了三个字符串的结果。
3.2. AGGEGATION聚合
和SQL一样,Neo4j CQL提供了一些在RETURN子句中使用的聚合函数。 它类似于SQL中的GROUP BY子句。我们可以使用MATCH命令中的RETURN +聚合函数来处理一组节点并返回一些聚合值。以下是一些常见的聚合函数及其用法示例:
-
COUNT- 计算匹配结果的数量:MATCH (n:Label) RETURN COUNT(n) AS node_count这将返回满足条件的节点数量。
-
SUM- 计算数值属性的总和:MATCH (n:Label) RETURN SUM(n.property) AS total_property_sum这将返回满足条件的节点属性 "property" 的总和。
-
AVG- 计算数值属性的平均值:MATCH (n:Label) RETURN AVG(n.value) AS average_value这将返回满足条件的节点属性 "value" 的平均值。
-
MIN和MAX- 计算数值属性的最小值和最大值:MATCH (n:Label) RETURN MIN(n.age) AS min_age, MAX(n.age) AS max_age这将返回满足条件的节点属性 "age" 的最小和最大值。
-
COLLECT- 将结果集中的值收集为列表:MATCH (n:Label) RETURN COLLECT(n.name) AS names这将返回满足条件的节点属性 "name" 的值作为列表。
3.3. 关系函数
CQL中提供了一组关系函数,以在获取开始节点,结束节点等细节时知道关系的细节。以下是一些常见的关系函数及其用法示例:
-
TYPE- 获取关系的类型:MATCH (a)-[r]->(b) RETURN TYPE(r) AS relationship_type这将返回关系的类型,例如 "relationship_type" 可能是关系的标签。
-
STARTNODE和ENDNODE- 获取关系的起始节点和结束节点:MATCH (a)-[r]->(b) RETURN STARTNODE(r) AS start_node, ENDNODE(r) AS end_node这将返回关系的起始节点和结束节点。
-
NODES- 获取关系路径上的所有节点:MATCH path = (a)-[*]->(b) RETURN NODES(path) AS all_nodes这将返回关系路径上的所有节点的列表。
-
LENGTH- 获取关系路径的长度(即节点之间的关系数量):MATCH path = (a)-[*]->(b) RETURN LENGTH(path) AS path_length这将返回关系路径的长度。
-
RELATIONSHIPS- 获取关系路径上的所有关系:MATCH path = (a)-[*]->(b) RETURN RELATIONSHIPS(path) AS all_relationships这将返回关系路径上的所有关系的列表。
4.结语
本文对Neo4j中的CQL语句和CQL函数进行了概念介绍和用例罗列,下一篇Neo4j系列文章将向大家展示我自己日常项目中积累的Neo4j中的工具类(结合Spring Boot),以及具体使用场景,喜欢这一系列内容的同学动动小手点点关注吧~

更多【python-【Neo4j系列】Neo4j之CQL语句和函数介绍】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-eNSP启动路由器一直出#号、以为是安装配置winpcap的问题。。。。(以为是win10安装winpcap失败的问题。。。) - 其他
- log4j-项目实战:中央控制器实现(2)-优化Controller,将共性动作抽取到中央控制器 - 其他
- 聚类-数据挖掘:分类,聚类,关联关系,回归 - 其他
- objective-c-http客户端简单demo - 其他
- 编程技术-自然语言处理实战项目21-两段文本的查重功能,返回最相似的文本字符串,可应用于文本查重与论文查重 - 其他
- 编程技术-基于教与学算法优化概率神经网络PNN的分类预测 - 附代码 - 其他
- 运维-linux生产者消费者模型 - 其他
- 编程技术-微服务概览 - 其他
- 算法-基于python+TensorFlow+Django卷积网络算法+深度学习模型+蔬菜识别系统 - 其他
- 计算机外设-【PyQt】(自制类)处理鼠标点击逻辑 - 其他
- css-Module build failed (from ./node_modules/postcss-loader/src/index.js): - 其他
- java-【TiDB】TiDB CLuster部署 - 其他
- tidb-KCC@广州与 TiDB 社区联手—广州开源盛宴 - 其他
- pdf-耗时3年写了一本数据结构与算法pdf!开源了 - 其他
- 计算机外设-键盘win键无法使用,win+r不生效、win键没反应、Windows键失灵解决方案(亲测可以解决) - 其他
- 计算机外设-键盘打字盲打练习系列之认识键盘——0 - 其他
- 机器学习-Azure 机器学习 - 有关为 Azure 机器学习配置 Kubernetes 群集的参考 - 其他
- 信息可视化-ESP32网络开发实例-将数据保存到InfluxDB时序数据库 - 其他
- 计算机外设-基于QT使用OpenGL,加载obj模型,进行鼠标交互 - 其他
- 前端框架-React进阶之路(三)-- Hooks - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
