语言模型-【论文综述+多模态】腾讯发布的多模态大语言模型(MM-LLM)综述(2024.02)
推荐 原创论文链接:24.02.MM-LLMs: Recent Advances in MultiModal Large Language | 国内-链接
实时网站:https://mm-llms.github.io
参考说明1-readpaper:https://mp.weixin.qq.com/s/ESUVe1aTYFLVJ10S9c1dBg
一、什么是MM-LLM ?
多模态大语言模型:Multimodal Large Language Models
MM-LLM = 预训练单模态模型( 含LLMs) + 微调对齐所有模态 + 输出调整
MM-LLMs 利用现成的预训练单模态基础模型,
特别是强大的大型语言模型(LLMs), 作为认知核心,赋予各种多模态任务能力。
LLMs 提供了稳健的语言生成、zero-shot 迁移能力和上下文学习(ICL)等可取特性
在这一领域中,主要关注点是通过多模态预训练(MM PT, Pre-Training)+ 多模态指令调整(MM IT)pipeline 来优化模态之间的对齐,以及与人类意图的对齐(aligning with human intent)。
1.1 发展历程
-
最初的研究
图像-文本理解(例如 BLIP-2,LLaVA,MiniGPT-4 和 OpenFlamingo 等工作);
视频-文本理解(例如 VideoChat,Video-ChatGPT 和 LLaMA-VID 等工作);
音频-文本理解(例如 Qwen-Audio)等任务。 -
随后,MM-LLMs 的能力扩展到支持特定模态生成。
这包括具有图像-文本输出的任务,例如 GILL,Kosmos-2,Emu 和 MiniGPT-5 等;
以及具有语音/音频-文本输出的任务,例如 SpeechGPT 和 AudioPaLM 等工作 -
最近的研究努力集中在模仿
类人任意-任意模态转换
将 LLMs 与外部工具结合起来,实现,现接近任意-任意的多模态理解和生成,
例如 Visual-ChatGPT,HuggingGPT 和 AudioGPT 等
二、模型框架
我们将一般模型架构分解为五个组件:
- 模态编码器(Modality Encoder) : 直接使用
- 输入映射器 (Input projector): 将其他模态的编码特征与文本特征空间对齐
- LLM 骨干 (LLM backbone): 直接使用
- 输出映射器 (Output Projector) : 将生成模型与 LLM 的输出指令对齐
- 模态生成器 (Modality Generator):直接使用
结构见下图2:
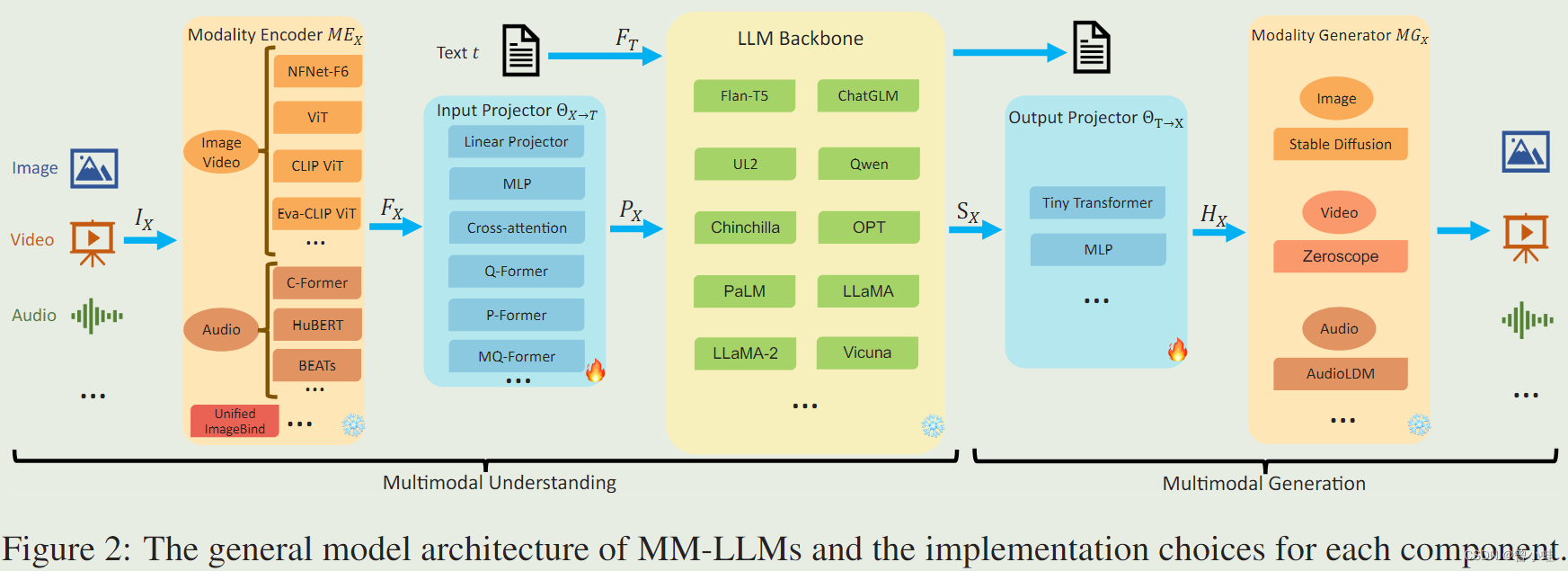
2.1 模态编码器(Modality Encoder):
** 负责对不同的模态输入IX进行编码,得到对应的特征FX。IX可以是图像、视频、音频、3D等不同类型的输入。常用的编码器包括:
图像编码器:NFNet-F6、ViT、CLIP ViT、Eva-CLIP ViT
视频编码器:对视频均匀采样成5帧,进行与图像类似的预处理
音频编码器:C-Former、HuBERT、BEATs、Whisper
3D点云编码器:ULIP-2、PointBERT
统一编码器:ImageBind,支持图像、视频、文本、音频、热图等多种模态
2.2 输入投影器 (Input Projector)
负责将编码后的其他模态特征FX投影到文本特征空间T,得到对齐的特征PX。常用的实现方法有:
直接线性投影或多层感知机
交叉注意力:利用可训练的查询向量与编码特征FX进行压缩,得到固定长度的表示,并直接输入LLM或进行交叉注意力融合
Q-Former:从FX中提取相关特征,作为提示PX
P-Former:生成参考提示,对Q-Former生成的提示进行对齐约束
2.3 LLM骨干网络(LLM Backbone):
用预训练的大型语言模型作为核心,负责对齐后的特征进行语义理解、推理和决策,并输出文本输出t和来自其他模态的信号令牌SX。常用的LLM包括:
- Flan-T5
- ChatGLM
- UL2
- Qwen
- Chinchilla
- OPT
- PaLM
- LLaMA
- LLaMA-2
- Vicuna
三、训练流程
模态编码器、LLM 骨干和模态生成器通常保持冻结状态
MM-LLMs 的训练流程可以划分为两个主要阶段:MM PT 和 MM IT。
3.1 MM PT (任意模态到文字)
在 PT 阶段,通常利用 X-Text 数据集(见附录),通过优化预定义的目标来训练输入和输出映射器,
以实现各种模态之间的对齐。 X-Text 数据集一般包括图像-文本、视频-文本和音频-文本。
3.2 MM IT (指令微调 )
指令微调=监督微调(SFT)和根据人类反馈进行强化学习(RLHF)
MM IT 是一种使用指令格式的数据集对预训练的 MM-LLMs 进行微调的方法
通过这个过程,MM-LLMs 可以通过遵循新的指令来泛化到未见过的任务,从而提高 zero-shot 性能。
SFT 数据集可以构造为单轮 QA 或多轮对话。
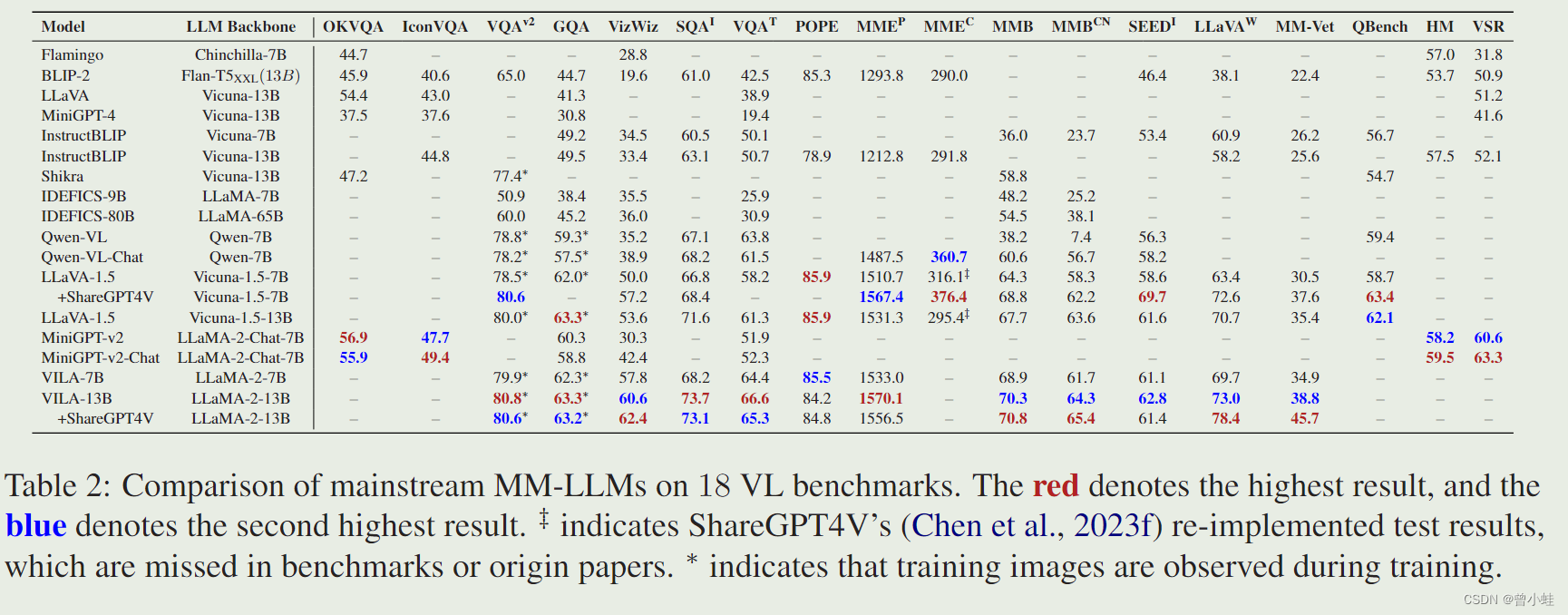
四、部分模型性能测评
红色代表在该项测评最高分,蓝色是第二高分
23.12 VILA: On Pre-training for Visual Language Models
更高的图像分辨率可以为模型提供更多的视觉细节,有利于需要细粒度细节的任务。
例如,LLaVA-1.5 和 VILA 使用了 336336 的分辨率,
而 Qwen-VL 和 MiniGPT-v2 则采用了 448448 的分辨率
总结
当前的 MM-LLMs 主要支持以下模态:图像、视频、音频、3D 和文本
移动/轻量级部署:在资源受限的平台上部署 MM-LLMs 并同时实现最佳性能,比如低功耗移动设备和物联网设备,轻量级实现至关重要。在这方面的一个显著进展是 MobileVLM
最近,有许多类似的研究致力于轻量化 MM-LLMs,在性能相当或几乎没有损失的情况下,实现了高效的计算和推理,包括 TinyGPT-4、Vary-toy、Mobile-Agent、MoE-LLaVA 和 MobileVLM V2。然而,这一途径需要进一步探索以实现进一步的发展
一些发展趋势:
-
从专注于多模态理解到生成特定模态,进一步发展成为任意-任意模态转换(例如,MiniGPT-4 -> MiniGPT-5 -> NExT-GPT);
-
从 MM PT 进展到 SFT,再到 RLHF,训练流程不断完善,努力更好地与人类意图保持一致,并增强模型的对话交互能力(例如,BLIP-2 -> InstructBLIP -> DRESS);
-
接纳多样化的模态扩展(例如,BLIP-2 -> X-LLM 和 InstructBLIP -> X-InstructBLIP);
-
加入更高质量的训练数据集(例如,LLaVA -> LLaVA-1.5);(5)采用更高效的模型架构,从 BLIP-2 和 DLP 中复杂的 Q- 和 P-Former 输入映射模块过渡到 VILA 中更简单但同样有效的线性映射器。
附录
模型按功能分类
I:图像,V:视频,A/S:音频/语音(Audio/Speech),T:文本。
I D I_D ID:文档理解, I B I_B IB:输出边界框, I M I_M IM:输出分割掩码和 I R I_R IR:输出检索到的图像。

X-Text 数据集的详细信息见表 3。
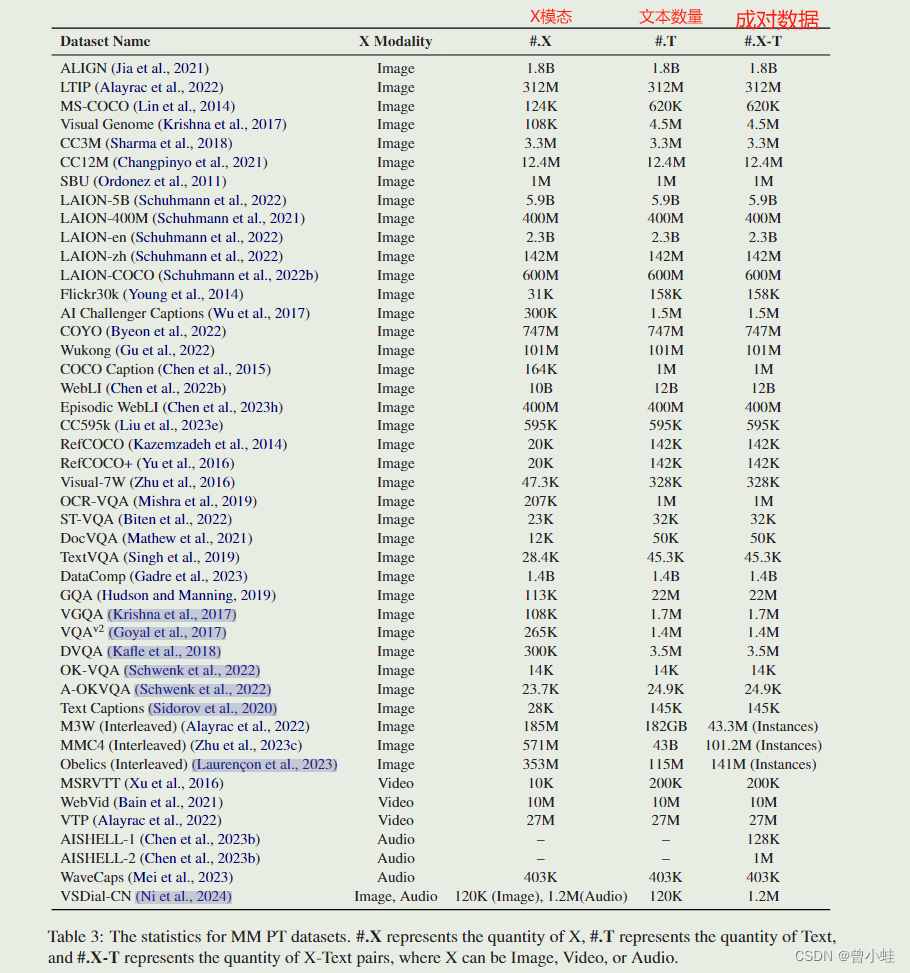
指令微调的数据集

更多【语言模型-【论文综述+多模态】腾讯发布的多模态大语言模型(MM-LLM)综述(2024.02)】相关视频教程:www.yxfzedu.com
相关文章推荐
- 物联网-Xcode15 framework ‘CoreAudioTypes‘ not found - 其他
- 科技-打造高效运营底座,极智嘉一体化软件系统彰显科技威能 - 其他
- golang-深入剖析Golang中单例模式 - 其他
- 网络-工业自动化工厂PLC远程控制网关物联网应用 - 其他
- react.js-React Native自学笔记 - 其他
- android-【Android】Lombok for Android Studio 离线插件 - 其他
- android-Android Studio新建项目下载依赖慢,只需一个操作解决 - 其他
- 后端-使用 Ruby 的 Nokogiri 库来解析 - 其他
- 编程技术-一、配置环境 - 其他
- 算法-03 矩阵与线性变换 - 其他
- android-Android Studio(控件常用属性) - 其他
- 编程技术-ES使用ik分词器查看分词结果及自定义词汇 - 其他
- asp.net-asp.net水资源检测系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio - 其他
- 编程技术-jQuery中遍历元素each - 其他
- 编程技术-rabbitmq下载安装教程 - 其他
- 编程技术-Codeforces Round 908 - 其他
- 编程技术-Leetcode543. 二叉树的直径 - 其他
- 机器学习-IBM Qiskit量子机器学习速成(一) - 其他
- 编程技术-3D模型格式转换工具HOOPS Exchange如何获取模型的特征树? - 其他
- 编程技术-电脑出现“此驱动器存在问题请立即扫描”该怎么办? - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
