flink-Flink应用场景
推荐 原创1、介绍
(1) Apache Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。
(2)在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
2、事件驱动型应用
什么是事件驱动型应用?
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。在传统架构中,应用需要读写远程事务型数据库。
相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
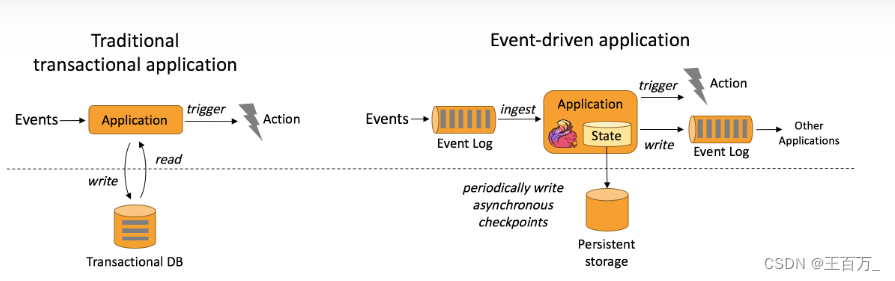
事件驱动型应用的优势?
事件驱动型应用无须查询远程数据库,本地数据访问使得它具有更高的吞吐和更低的延迟。而由于定期向远程持久化存储的 checkpoint 工作可以异步、增量式完成,因此对于正常事件处理的影响甚微。事件驱动型应用的优势不仅限于本地数据访问。传统分层架构下,通常多个应用会共享同一个数据库,因而任何对数据库自身的更改(例如:由应用更新或服务扩容导致数据布局发生改变)都需要谨慎协调。反观事件驱动型应用,由于只需考虑自身数据,因此在更改数据表示或服务扩容时所需的协调工作将大大减少。
Flink 如何支持事件驱动型应用?
事件驱动型应用会受制于底层流处理系统对时间和状态的把控能力,Flink 诸多优秀特质都是围绕这些方面来设计的。它提供了一系列丰富的状态操作原语,允许以精确一次的一致性语义合并海量规模(TB 级别)的状态数据。此外,Flink 还支持事件时间和自由度极高的定制化窗口逻辑,而且它内置的 ProcessFunction 支持细粒度时间控制,方便实现一些高级业务逻辑。同时,Flink 还拥有一个复杂事件处理(CEP)类库,可以用来检测数据流中的模式。
Flink 中针对事件驱动应用的明星特性当属 savepoint。Savepoint 是一个一致性的状态映像,它可以用来初始化任意状态兼容的应用。在完成一次 savepoint 后,即可放心对应用升级或扩容,还可以启动多个版本的应用来完成 A/B 测试。
3、数据分析应用
什么是数据分析应用?
数据分析任务需要从原始数据中提取有价值的信息和指标。传统的分析方式通常是利用批查询,或将事件记录下来并基于此有限数据集构建应用来完成。为了得到最新数据的分析结果,必须先将它们加入分析数据集并重新执行查询或运行应用,随后将结果写入存储系统或生成报告。
借助一些先进的流处理引擎,还可以实时地进行数据分析。和传统模式下读取有限数据集不同,流式查询或应用会接入实时事件流,并随着事件消费持续产生和更新结果。这些结果数据可能会写入外部数据库系统或以内部状态的形式维护。仪表展示应用可以相应地从外部数据库读取数据或直接查询应用的内部状态。
如下图所示,Apache Flink 同时支持流式及批量分析应用。
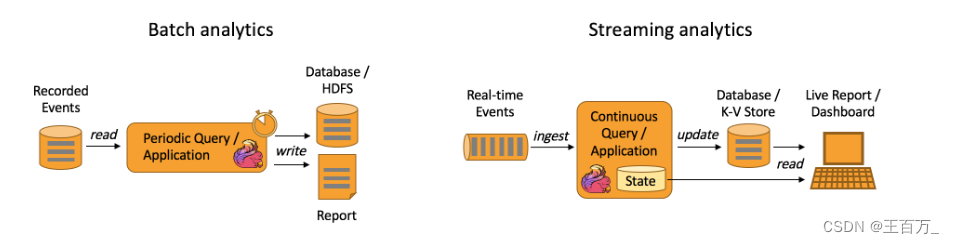
流式分析应用的优势?
和批量分析相比,由于流式分析省掉了周期性的数据导入和查询过程,因此从事件中获取指标的延迟更低。不仅如此,批量查询必须处理那些由定期导入和输入有界性导致的人工数据边界,而流式查询则无须考虑该问题。
另一方面,流式分析会简化应用抽象。批量查询的流水线通常由多个独立部件组成,需要周期性地调度提取数据和执行查询。如此复杂的流水线操作起来并不容易,一旦某个组件出错将会影响流水线的后续步骤。而流式分析应用整体运行在 Flink 之类的高端流处理系统之上,涵盖了从数据接入到连续结果计算的所有步骤,因此可以依赖底层引擎提供的故障恢复机制。
Flink 如何支持数据分析类应用?
Flink 为持续流式分析和批量分析都提供了良好的支持。具体而言,它内置了一个符合 ANSI 标准的 SQL 接口,将批、流查询的语义统一起来。无论是在记录事件的静态数据集上还是实时事件流上,相同 SQL 查询都会得到一致的结果。同时 Flink 还支持丰富的用户自定义函数,允许在 SQL 中执行定制化代码。如果还需进一步定制逻辑,可以利用 Flink DataStream API 和 DataSet API 进行更低层次的控制。
4、数据管道应用
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。
数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。
下图描述了周期性 ETL 作业和持续数据管道的差异。
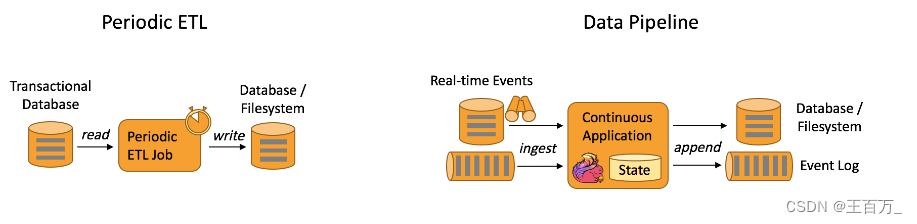
数据管道的优势?
和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。
Flink 如何支持数据管道应用?
很多常见的数据转换和增强操作可以利用 Flink 的 SQL 接口(或 Table API)及用户自定义函数解决。如果数据管道有更高级的需求,可以选择更通用的 DataStream API 来实现。Flink 为多种数据存储系统(如:Kafka、Kinesis、Elasticsearch、JDBC数据库系统等)内置了连接器。同时它还提供了文件系统的连续型数据源及数据汇,可用来监控目录变化和以时间分区的方式写入文件。
更多【flink-Flink应用场景】相关视频教程:www.yxfzedu.com
相关文章推荐
- ddos-ChatGPT 宕机?OpenAI 将中断归咎于 DDoS 攻击 - 其他
- 云原生-云原生周刊:KubeSphere 3.4.1 发布 | 2023.11.13 - 其他
- apache-从零开始Apache2配置php服务并支持网页访问 - 其他
- easyui-【开源三方库】Easyui:基于OpenAtom OpenHarmony ArkUI深度定制的组件框架 - 其他
- 算法-《数据结构、算法与应用C++语言描述》-队列的应用-工厂仿真 - 其他
- 编程技术-蓝桥 1111 第 3 场算法双周赛 深秋的苹果【算法赛】python解析 - 其他
- easyui-ChatRule:基于知识图推理的大语言模型逻辑规则挖掘11.10 - 其他
- hadoop-搭建完全分布式Hadoop - 其他
- 容器-【问题记录】docker pull 镜像的时候 devel 版本和无 devel 版本的差别 - 其他
- spring-spring cloud之服务熔断 - 其他
- 编程技术-理解 JMeter 聚合报告(Aggregate Report) - 其他
- 编程技术-使用vscode的ssh进行远程主机连接 - 其他
- 编程技术-docker部署Prometheus+Cadvisor+Grafana实现服务器监控 - 其他
- 编程技术-虹科示波器 | 汽车免拆检修 | 2021款广汽丰田威兰达PHEV车发动机故障灯异常点亮 - 其他
- 编程技术-Pandas教程(非常详细)(第六部分) - 其他
- 编程技术-没有设计经验的新手如何制作一本电子画册? - 其他
- 编程技术-根据关键词搜索阿里巴巴商品数据列表接口|阿里巴巴商品列表数据接口|阿里巴巴商品API接口|阿里巴巴API接口 - 其他
- 编程技术-JimuReport积木报表 v1.6.5 版本发布—免费报表工具 - 其他
- 编程技术-【Proteus仿真】【Arduino单片机】DHT11温湿度 - 其他
- 编程技术-Linux 下 JDK 安装(tar.gz版) - jdk8 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
