flink-大数据之Flink(一)
推荐 原创1、简介
flink是一个分布式计算/处理引擎,用于对无界和有界数据流进行状态计算。
flink处理流程
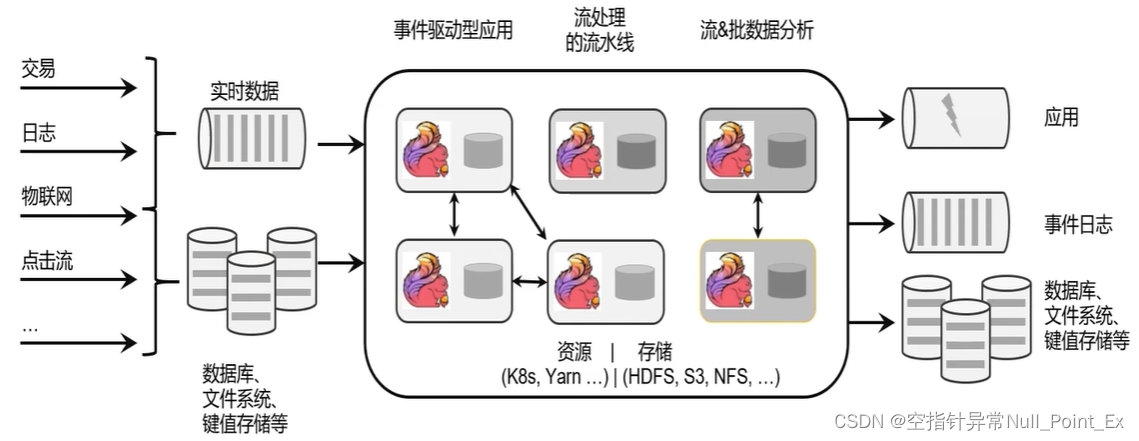
应用场景:
- 电商销售:实时报表、广告投放、实时推荐
- 物联网:实时数据采集、实时报警
- 物流配送、服务:订单状态跟踪、信息推送
- 银行、金融:实时结算、风险检测
有状态的流式处理
用内存的本地状态替代传统的数据库
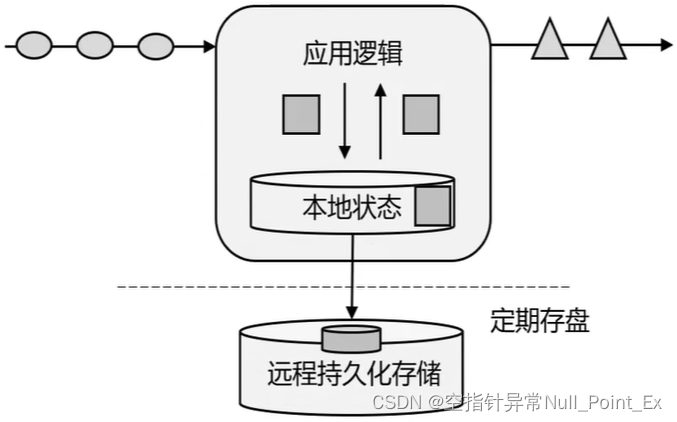
flink核心特点:高吞吐低延迟、结果准确性、精确一次的状态一致性保证、兼容性好、高可用和动态扩展。
分层API:
- SQL-最高层语言
- Table API-声明式领域专用语言
- DataStream/ DataSet API-核心API
- 有状态流处理-底层API
Flink与Spark对比
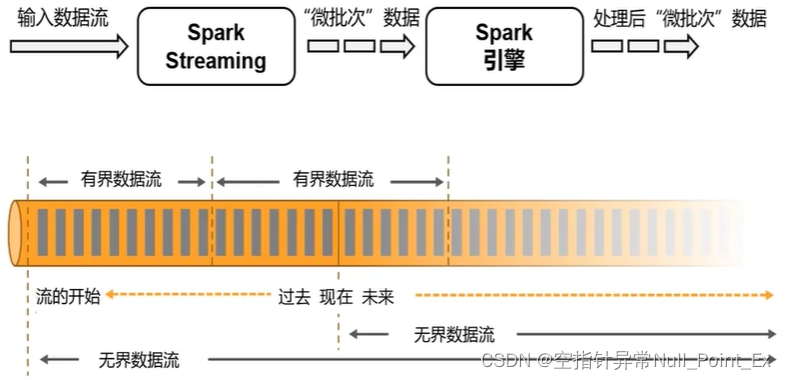
-
数据模型
spark采用RDD模型,spark streaming的DStream实际上也是一组小批量数据集(RDD的集合)
flink基本数据模型是数据流以及时间序列
-
运行时架构
spark是批计算,将DAG划分为不同的stage,一个完成后才计算下一个
flink是标准的流执行模式,一个事件在一个节点处理完后直接发往下一个节点进行处理
2、测试wordcount
maven的pom文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.lizhe</groupId>
<artifactId>flinkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<!-- <plugin>-->
<!-- <groupId>net.alchim31.maven</groupId>-->
<!-- <artifactId>scala-maven-plugin</artifactId>-->
<!-- <version>3.4.6</version>-->
<!-- <executions>-->
<!-- <execution>-->
<!-- <!– 声明绑定到maven的compile阶段 –>-->
<!-- <goals>-->
<!-- <goal>compile</goal>-->
<!-- </goals>-->
<!-- </execution>-->
<!-- </executions>-->
<!-- </plugin>-->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
</dependencies>
</project>
java代码(批处理)
package FlinkDemo;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @Title: FlinkWordCount
* @Author lizhe
* @Package FlinkDemo
* @Date 2024/2/24 22:03
* @description: FLinkDemo
*/
public class FlinkWordCount {
public static void main(String[] args) throws Exception {
//初始化环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> dataSource = env.readTextFile("input/words.txt");
//对每行进行分词,并转换成元组类型
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = dataSource.flatMap((String line, Collector<Tuple2<String, Long>> col) -> {
String[] words = line.split(" ");
for (String word : words) {
col.collect(Tuple2.of(word, 1L));
}
}) .returns(Types.TUPLE(Types.STRING,Types.LONG));//returns 方法指定的返回数据类型Tuple2,就是 Flink 自带的二元组数据类型。
//按照第一个字段进行聚合
UnsortedGrouping<Tuple2<String, Long>> group = wordAndOneTuple.groupBy(0);
//按照第二个字段进行求和
AggregateOperator<Tuple2<String, Long>> sum = group.sum(1);
sum.print();
}
}
java代码(流处理)
package FlinkDemo;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* @Title: BoundedStreamWordCount
* @Author lizhe
* @Package FlinkDemo
* @Date 2024/2/25 18:57
* @description: BoundedStreamWordCount
*/
public class BoundedStreamWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env=StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> streamSource = env.readTextFile("input/words.txt");
SingleOutputStreamOperator<Tuple2<String, Long>> singleOutputStreamOperator = streamSource.flatMap((String line, Collector<Tuple2<String, Long>> col) -> {
String[] words = line.split(" ");
for (String word : words) {
col.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
KeyedStream<Tuple2<String, Long>, Object> keyedStream = singleOutputStreamOperator.keyBy(new KeySelector<Tuple2<String, Long>, Object>() {
@Override
public Object getKey(Tuple2<String, Long> stringLongTuple2) throws Exception {
return stringLongTuple2.f0;
}
});
SingleOutputStreamOperator<Tuple2<String, Long>> sum = keyedStream.sum(1);
sum.print();
env.execute();
}
}
输出结果:线程号>(单词,个数)
7> (flink,1)
8> (hadoop,1)
3> (hello,1)
5> (world,1)
3> (hello,2)
3> (hello,3)
监听socket流
-
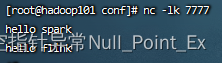
启动netcat
nc -lk 7777 -
编写代码
package FlinkDemo; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.functions.KeySelector; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; /** * @Title: StreamWordCount * @Author lizhe * @Package FlinkDemo * @Date 2024/2/25 20:34 * @description: StreamWordCount */ public class StreamWordCount { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<String> dataStreamSource = env.socketTextStream("192.168.132.101", 7777); SingleOutputStreamOperator<Tuple2<String, Long>> singleOutputStreamOperator = dataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> col) -> { String[] words = line.split(" "); for (String word : words) { col.collect(Tuple2.of(word, 1L)); } }).returns(Types.TUPLE(Types.STRING, Types.LONG)); KeyedStream<Tuple2<String, Long>, Object> keyedStream = singleOutputStreamOperator.keyBy(new KeySelector<Tuple2<String, Long>, Object>() { @Override public Object getKey(Tuple2<String, Long> stringLongTuple2) throws Exception { return stringLongTuple2.f0; } }); SingleOutputStreamOperator<Tuple2<String, Long>> sum = keyedStream.sum(1); sum.print(); env.execute(); } } -
netcat发送
-
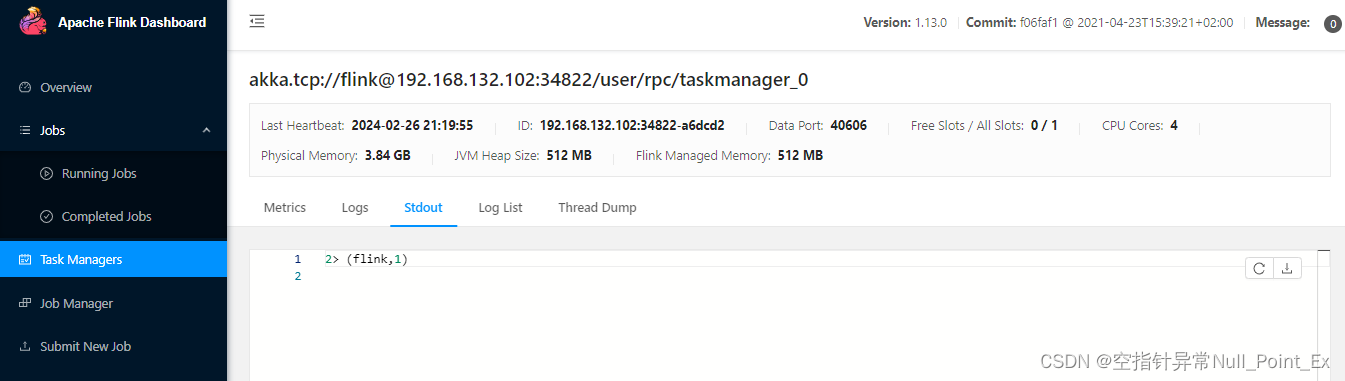
查看结果
3> (hello,1) 7> (flink,1) 5> (world,1) 3> (hello,2) 3> (hello,3) 8> (hadoop,1)
3、flink快速部署
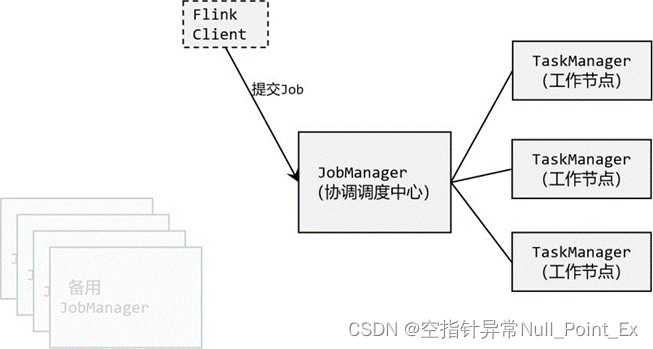
fink提交作业和执行任务需要:客户端(Client)、作业管理器(JobManager)、任务管理器(TaskManager)
JobManager对作业进行调度管理,把任务分发给TaskManager,TaskManager对数据进行处理。
- 本地启动
下载flink,地址:https://flink.apache.org/downloads/#apache-flink-downloads
解压后直接启动
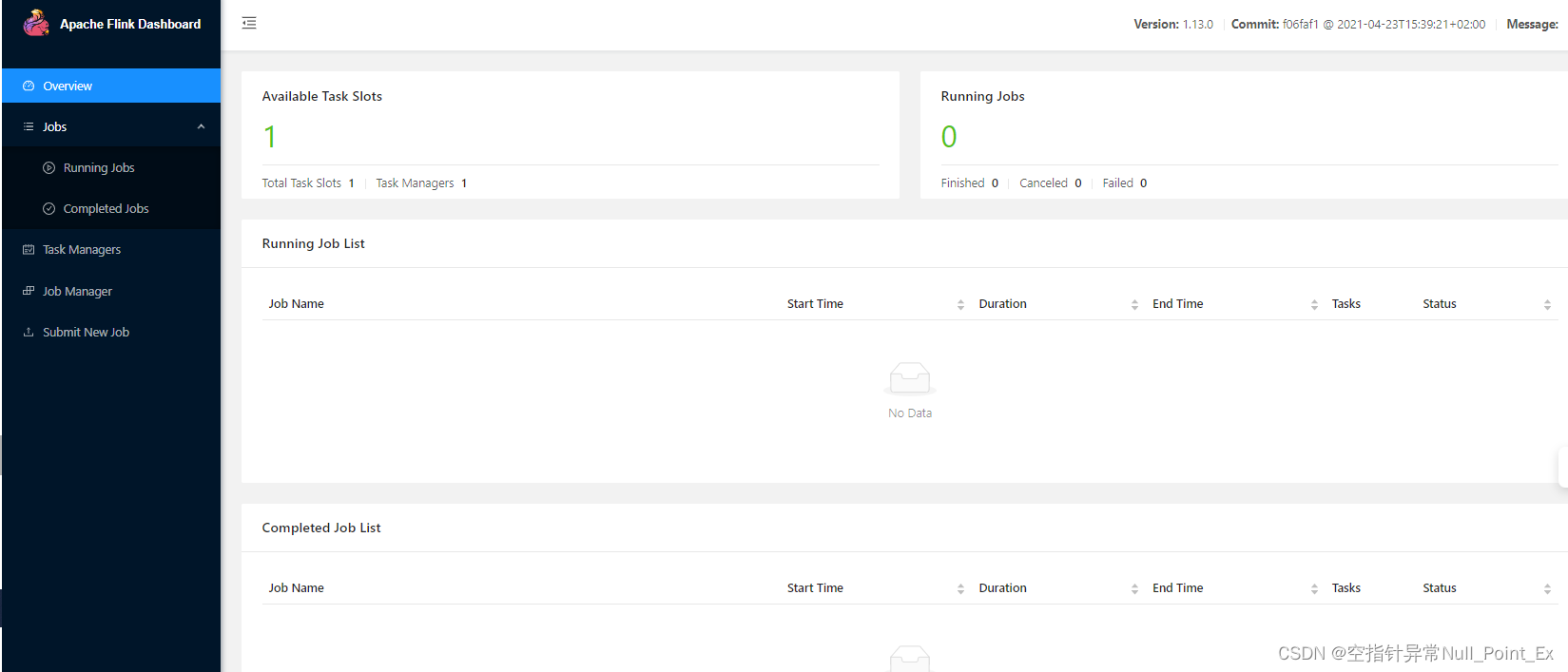
[root@hadoop101 soft] cd /export/soft/flink-1.13.0
[root@hadoop101 flink-1.13.0] bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host hadoop101.
Starting taskexecutor daemon on host hadoop101.
访问webUI:http://hadoop101:8081/
关闭命令
bin/stop-cluster.sh
-
集群启动
修改flink下的conf/flink-conf.yaml,修改jobmanager.rpc.address:hadoop100,并修改works文件,其中添加hadoop101,hadoop102

-
在master节点输入启动命令,得到
[root@hadoop100 flink-1.13.0]# bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host hadoop100. Starting taskexecutor daemon on host hadoop101. Starting taskexecutor daemon on host hadoop102.集群停止同本地启动。
-
向集群提交作业
程序使用maven打包,并提交到web端
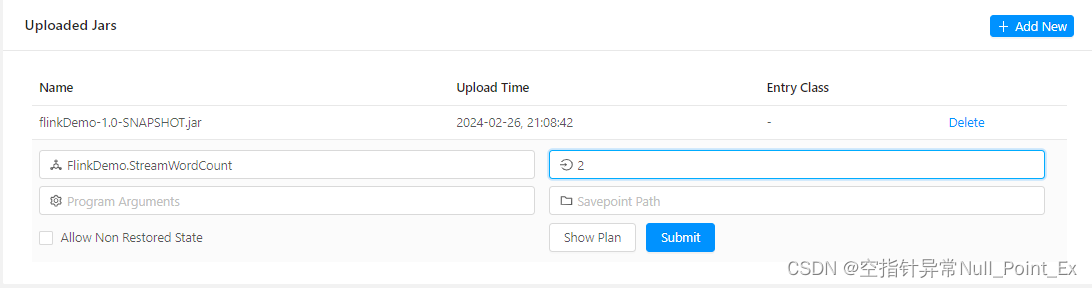
启动netcat,并在netcat中发送数据
更多【flink-大数据之Flink(一)】相关视频教程:www.yxfzedu.com
相关文章推荐
- github-本周Github有趣开源项目:Rspress等6个 - 其他
- node.js-运行npm install卡住不动的几种解决方案 - 其他
- 数据库-2023年开发语言和数据库排行 - 其他
- android-Android Studio导入,删除第三方库 - 其他
- ai编程-VSCode使用插件Github Copilot进行AI编程 - 其他
- node.js-如何上传自己的npm包 - 其他
- android-2023年11月PHP测试覆盖率解决方案 - 其他
- android-android studio 修改图标 - 其他
- 电脑-Mac电脑专业raw图像处理 DxO PhotoLab 7中文最新 for mac - 其他
- ios-Home Assistant使用ios主题更换背景 - 其他
- node.js-更改 npm的默认缓存地址 - 其他
- 编程技术-青岛华晟智能与陇西县政府签约,共同推动东西部协作产业升级 - 其他
- 编程技术-K8S集群调度 - 其他
- 编程技术-POWER APPS:必填项功能 - 其他
- 编程技术-浅析移动端车牌识别技术的工作原理及其过程 - 其他
- 编程技术-证明串口是好的 - 其他
- 编程技术-C++学习第三十七天----第十章--对象和类 - 其他
- 算法-Python输出三角形面积和周长 - 其他
- 算法-C语言 每日一题 牛客网 11.12 Day16 - 其他
- 编程技术-新型的铁塔基站“能源管家” - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
