阿里云-阿里云A10推理qwen
推荐 原创硬件配置
vCPU:32核
内存:188 GiB
宽带:5 Mbps
GPU:NVIDIA A10 24G
cuda 安装
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-rhel7-12-1-local-12.1.0_530.30.02-1.x86_64.rpm
sudo rpm -i cuda-repo-rhel7-12-1-local-12.1.0_530.30.02-1.x86_64.rpm
sudo yum clean all
sudo yum -y install nvidia-driver-latest-dkmssudo yum -y install cuda
#cudnn
wget https://developer.download.nvidia.com/compute/cudnn/9.0.0/local_installers/cudnn-local-repo-rhel7-9.0.0-1.0-1.x86_64.rpm
sudo rpm -i cudnn-local-repo-rhel7-9.0.0-1.0-1.x86_64.rpm
sudo yum clean all
sudo yum -y install cudnnAnconda
chmod +xwr Anaconda3-2022.10-Linux-x86_64.sh
./Anaconda3-2022.10-Linux-x86_64.sh
Base: Python=3.9
torch
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=12.1 -c pytorch -c nvidiaenv_test.py
import torch # 如果pytorch安装成功即可导入
print(torch.cuda.is_available()) # 查看CUDA是否可用
print(torch.cuda.device_count()) # 查看可用的CUDA数量
print(torch.version.cuda) # 查看CUDA的版本号包
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
pip install csrc/layer_norm
pip install csrc/rotary
pip install modelscope
问题:
1、subprocess.calledprocesserror: command '['which', 'g++']' returned non-zero exit status 1.
解决:
yum install make automake gcc gcc-c++ kernel-devel
yum group install "Development Tools" "Development Libraries"
2、RuntimeError: Error compiling objects for extension
解决:Pytroch和cuda不匹配,重新安装对应的cuda或者pytorch
3、nvidia-smi :Failed to initialize NVML: Driver/library version mismatch
解决:
yum remove nvidia-*
#重装cuda12.1
4、WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu.
内存不够: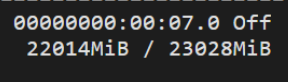
test:
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
# Note: The default behavior now has injection attack prevention off.
#trust_remote_code=True 表示你信任远程的预训练模型,愿意运行其中的代码
tokenizer = AutoTokenizer.from_pretrained("qwen/Qwen-14B", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained("qwen/Qwen-14B", device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-14B", trust_remote_code=True)
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...更多【阿里云-阿里云A10推理qwen】相关视频教程:www.yxfzedu.com
相关文章推荐
- 算法-算法通关村第八关|白银|二叉树的深度和高度问题【持续更新】 - 其他
- 算法-C现代方法(第19章)笔记——程序设计 - 其他
- git-IntelliJ Idea 撤回git已经push的操作 - 其他
- c#-html导出word - 其他
- excel-使用 AIGC ,ChatGPT 快速合并Excel工作薄 - 其他
- 开发语言-怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载 - 其他
- 编程技术-鲁大师电动车智能化测评报告第二十三期:实测续航95km,九号Q90兼顾个性与实用 - 其他
- 数据库-进阶SQL——数据表中多列按照指定格式拼接,并将多行内容合并为map拼接 - 其他
- 小程序-社区团购小程序系统源码+各种快递代收+社区便利店 带完整的搭建教程 - 其他
- spring-Java之SpringCloud Alibaba【八】【Spring Cloud微服务Gateway整合sentinel限流】 - 其他
- 云原生-云原生周刊:Gateway API 1.0.0 发布 | 2023.11.6 - 其他
- java-Ruby语言和VCR库编写代码示例 - 其他
- spring-C#开发的OpenRA游戏之世界存在的属性CombatDebugOverlay(3) - 其他
- 编程技术-Linux文件系统 - 其他
- 电脑-电脑硬盘数据恢复哪个好?值得考虑的 8 个硬盘恢复软件解决方案 - 其他
- jvm-内存管理 - 其他
- 算法-吴恩达《机器学习》7-1->7-4:过拟合问题、代价函数、线性回归的正则化、正则化的逻辑回归模型 - 其他
- 前端-vue项目js原生属性IntersectionObserver实现图片懒加载 - 其他
- 编程技术-Python标准库有哪些 - 其他
- 编程技术-读取W25Q64的设备ID时输出0xff - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- 智能手机-手机是否能登陆国际腾讯云服务器?
- 智能手机-GD32单片机远程升级下载,手机在线升级下载程序,GD32在线固件下载升级,手机下载程序固件方法
- 华为-漏刻有时百度地图API实战开发(1)华为手机无法使用addEventListener click 的兼容解决方案
- 架构-LoRaWAN物联网架构
- clickhouse-【总结卡】clickhouse数据库常用高级函数
- java-深入理解ClickHouse跳数索引
- 小程序-小程序发成绩
- 运维-墨者学院 Ruby On Rails漏洞复现第一题(CVE-2018-3760)
- 企业安全-2023数字安全产业大会丨华云安应邀参加“数说安全”中原论坛
- fpga开发-「Verilog学习笔记」多功能数据处理器
