python-关于python的数据可视化与可视化:数据读取
推荐 原创带着问题寻找答案可以使自己不再迷茫或者不知所措!
了解什么python的数据可视化?
数据的读取(一般伴随着课程文件中会进行提供和利用)
数据可视化是将Python应用于大气海洋科学中数据处理及分析过程的重要环节,它可以让复杂晦涩的数据变得鲜活生动,从而更好地被理解。《Python数据可视化》主要介绍几个基于Python且各具特色的绘图工具包,从安装到使用,并列举大量的代码示例,为使用Python进行数据分析的用户们提供详细的参考。(来源于:2021年科学出版社出版的图书《Python数据可视化》)
抓住其中的几个关键
工作流:销售库,客户库
们能够提取相关的数据(爬虫”抽取相关的数据(数据挖掘 ---存储位置:数据仓库<包含了多种数据库在其中>----数据产品(数据的预处理,有效数据和无效数据之分,模型是否合乎相关的逻辑结构))---数据分析/训练模型“,ETL”管理各种各样的数据库和集群相关的内容“),”每一个专属的位置都有专属的工作岗位!“
数据的预处理:短视频中不断地进行打标签(这里自己的最右里面的社区管理一种比较新奇的管理模式。)
学习的重点:对于数据进行分析和处理。
数据可视化的工具推荐:
bi软件(ibm和微软两个大公司)
python/R(专属用于统计学的理论),平台相关的,整个数据的基础平台,交互以及动态效果的图形。
在pycharm中可以进行安装,pip install -i 包名
anaconda (平时使用python的时候,转载一些python相关的包+常用的包+conda(包管理器))
自身存在管理器,
anaconda+jupyter
关于编程软件的选择
jupyter notebook(自动挑选的浏览器当中)运行局部和整体,可是跨平台进行运行,
将代码切换到markdown(中文释义:)输入和输出以及文本都可以混淆在一起的内容
所有的输入都是自动带有输出的内容
pycharm(交互式的编程界面,非交互式的,必须写完全部代码才能执行)
打开viscode,整个进行使用就一模一样的
创建python环境在其中进行识别和选用
jupyter语法之间会存在一定差距的
选择nutitled的运行环境,文件后缀名ipynb
关于编辑软件的下载和安装:
三种基础的相关的方式对其进行下载和安装。
什么是交互式呢?
交互式处理(interactiveprocessing)操作人员和系统之间存在交互作用的信息处理方式。操作人员通过终端设备(见输入输出系统)输入信息和操作命令,系统接到后立即处理,并通过终端设备显示处理结果。
人话:就是可以通过人为的方式所进行参与的一种基础操作系统。
工具的安装过程以及相关的模式的选择和运用,
了解数据获取的基础语法知识
导入nmpy这个基础的包
创建基础的数据,是在np的条件下
a = np.array([1,2,3,4,5])
print(a)
print(type(a))区别就是在前面那个地方增加了一个np
arange函数的基础用法(其本身就是不包含20);
均匀生成一个数列
a3=np.linsspace(-5,5,10)
a3 = np.linspace(-5,5,10)
print(a3)
a4 = np.random.randint(10)
print(a4)
a5 = np.random.normal(50,10,20)
print(a5)服从正态分步的20个随机数字
备注:这个代码可以自己尝试自己敲一遍,因为这个相关的文件和内容是自己进行不断地归纳和总结之后的内容,自己打一遍就是自己在进行归纳和总结。
最基本的数据运行结果;
[1 2 3 4 5]
<class 'numpy.ndarray'>
[ 0 5 10 15]
[-5. -3.88888889 -2.77777778 -1.66666667 -0.55555556 0.55555556
1.66666667 2.77777778 3.88888889 5. ]
6
[42.31149416 45.6621531 57.8668306 32.50171035 52.1458398 51.99344313
56.0246682 47.76336963 42.59052898 50.76403222 54.05306604 52.03812967
36.35192821 45.99588398 51.02228804 51.48190412 60.4714262 45.99991669
48.39481881 62.80562501]
Process finished with exit code 0学习反问;什么是nmpy?
numpy是python中科学计算的基础包,它是一个python库,提供多维数组对象,各种派生对象,如掩码数组和矩阵以及用于数组快速操作的各种例程。(来源:php中文网)
提取关键字:
科学计算的基础包,一个库,后面文字描述都是其相关的功能进行的描述
什么是库呢?
在计算机科学中,库(英语:library)是用于开发软件的子程序集合。库和可执行文件的区别是,库不是独立程序,他们是向其他程序提供服务的代码
提权关键字:
子程序集合,库与可执行文件的区别,库不是独立程序,他们可以向其他程序提供服务的一种代码
什么是二维数组?
二维数组本质上是以数组作为数组元素的数组,即“数组的数组”,类型说明符 数组名[常量表达式][常量表达式]。
所以其根本模式:数组的数组,【【数组里面的数组】】
二维数据的代码练习;
# 创建一个基础的二维数组
a6 = np.array([[1,2,3],[4,5,6]])
print(a6)
a7 = np.array([1,2,3,4,5,6]).reshape(2, 3)
# 将以为数组改为2*3的二维数组
print(a7)
a8 = np.random.randint(1,100, (3,4))
# 元素是从0的100(不含),3*4的数组
print(a8)二维数组的运行结果;
[[1 2 3]
[4 5 6]]
[[1 2 3]
[4 5 6]]
[[34 54 47 46]
[22 19 95 70]
[29 95 85 46]]特殊数组的练习
# 特殊的数组:
O = np.ones((3,4))
# 全是1
print(O)
z = np.zeros((5,6))
# 全是0
print(z)
e = np.empty((2,3))
# 空数组(随机数)
print(e)
ey = np.eye(4)
# 单位数组(对角线是1,其他是0)
print(ey)
f = np.full((2,3),99)
# 用99填充数组
print(f)关键点:
np代表其在np这个基础的限定条件下,ones,zeros,empty,eye,full(这几个基本的值代表其特殊的性质,特殊的性质可以产生基础的功能!),前面一个数字,前面一个是基本的行后面一个是基本的列,行和列之间的关系,通过后续的结果可以进行查看。
特殊数组的运行结果,其运行的结果如下:
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
[[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]
[[99 99 99]
[99 99 99]]
print('hello,world')在安装完anada之后可以让自己尝试选择创建一个新建的选项进行选择,输出一个hello,world就可以对其进行查看,
了解数据可视化的操作步骤?
能够做一些相关的图表分析,平均租金分析,各种图形进行展示
将会遇到的一些问题:
安装anaconda出现了以下的问题:
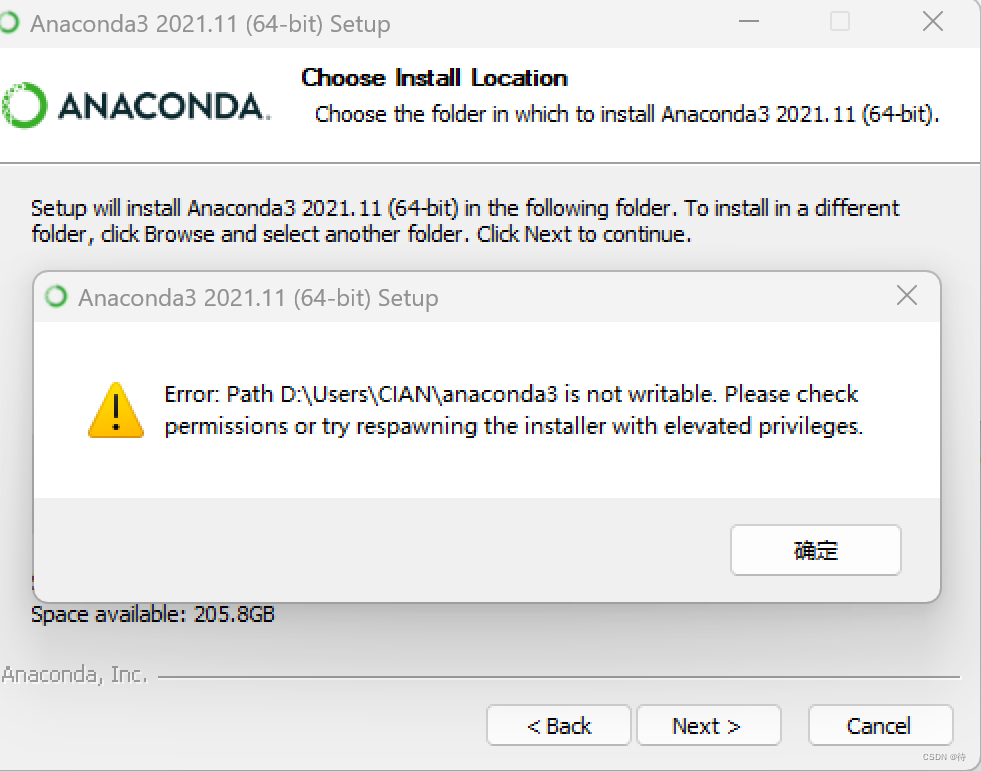
错误:路径D:usersiclANlanacoconda3不可写。请检查许可证或尝试用提升的权限重新部署安装程序
安装在c盘的基础解题权限是合适的,之后不断地点击下一步就可以完成安装。
anada安装的基础方法和措施:
练习题目的选择:
1、下列选项中,用于搭接数据仓库和保证数据质量的是( )。
A、 数据收集
B、 数据处理
C、 数据分析
D、 数据展现
答案为:B
数据处理可以提高搭建数据仓库和保障数据质量
2、关于Anconda组件的说法中,下列描述错误的是()。
A、 Anaconda Prompt是Anaconda自带的命令行
B、 Jupyter Notebook是基于客户端的交互式计算环境,可以编辑易于人们阅读的文档,用于展示数据分析的过程
C、 Spyder是一个使用Python语言、跨平台的、科学运算集成开发环境
D、 Anaconda Navigator是用于管理工具包和环境的图形用户界面,后续涉及的众多管理命令也可以在Navigator中手动实现
此题的正确选项:B
Jupyter Notebook是基于客户端的交互式计算环境(不是客户端是一个网页),可以编辑易于人们阅读的文档,用于展示数据分析的过程
后续更新文章:(参考学校的教学课程之后得出的基本更新顺序)
# numpy(高维数据/矩阵预算的方式和方法) # pandas(数据处理/)这两个都是两个包! # 如何进行处理,进行分组或者进行聚合 # 做一个基础可视化的部分 matplotlib seaborn(语法相对比较简单一点),bokeh(一种交互式的运行方式),echaRtz(完全基于网页的基础内容) # 支线:数据预处理(缺失值,重复值,异常值”一个人的年龄是一万岁,从常识来说就会存在一定不合理,但是数据的角度而言,其基础是进行满足“,特征化可以帮助自己进行比例的计算), # 时间(也是一个基础的数据类型)序列 # 文本数据(一个人说的语言将其进行转换为一个电脑可以进行识别的基础数据,可能长得相同,但是其实际操作是否是相关的呢?) # 做一些基础的项目,通过这些项目来帮助自己提高自己的基础熟练度 # 爬虫(scrapy)
更多【python-关于python的数据可视化与可视化:数据读取】相关视频教程:www.yxfzedu.com
相关文章推荐
- elasticsearch-搜索引擎Elasticsearch基础与实践 - 其他
- flink-flink1.18.0 macos sql-client.sh启动报错 - 其他
- .net-Ubuntu安装.Net SDK - 其他
- 论文阅读-论文阅读:LOGO-Former: Local-Global Spatio-Temporal Transformer for DFER(ICASSP2023) - 其他
- 数码相机-深度图(Depth Map) - 其他
- c#-C#在.NET Windows窗体应用中使用LINQtoSQL - 其他
- flink-flink的CoProcessFunction使用示例 - 其他
- 文心一言-百度上线“文心一言”付费版本,AI聊天机器人市场竞争加剧 - 其他
- 数据库-MongoDB常用的语句 - 其他
- flink-Flink(三)【运行时架构】 - 其他
- java-Windows 安装 Maven - 其他
- 爬虫-使用JavaScript编写游戏平台数据爬虫程序 - 其他
- python-Python(七) 元组 - 其他
- 编程技术-liunx的启动过程 - 其他
- rust-Rust教程7:Gargo包管理、创建并调用模块 - 其他
- c#-顶顶通语音识别使用说明 - 其他
- stm32-FPGA与STM32_FSMC总线通信实验 - 其他
- spring-springboot集成redis -- spring-boot-starter-data-redis - 其他
- ios-LibXL 4.2.0 for c++/net/win/mac/ios Crack - 其他
- unity-Unity DOTS系列之System中如何使用SystemAPI.Query迭代数据 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
