r语言-vivo 基于 StarRocks 构建实时大数据分析平台,为业务搭建数据桥梁
推荐 原创在大数据时代,数据分析和处理能力对于企业的决策和发展至关重要。
vivo 作为一家全球移动互联网智能终端公司,需要基于移动终端的制造、物流、销售等各个方面的数据进行分析以满足业务决策。
而随着公司数字化服务的演进,业务诉求和技术架构有了新的调整,已有的基于 Trino 的架构面临着数据时效、查询性能、并发能力、复杂运维等方面的瓶颈,为此 vivo 大数据团队进行了一系列技术架构的探索和实践。
vivo 业务快速发展带来更多数据挑战
在数字化演进的过程中,vivo 面临着业务诉求和技术架构方面的新挑战,主要包括时效性要求提升、访问量大、计算场景复杂和运维难等问题。
vivo 原有数据平台是基于 Trino+Hive 的架构来实现,一方面通过 Trino 来抽取业务库里的数据(MySQL、Oracle、SQLserver 等),另一方面将抽取的数据写入到 Hive 中,根据业务侧需求进行数仓的加工处理。
时效性挑战,业务分析决策需加速
随着数字化进程推进,制造、营销、销售等业务对实时分析的应用越来越多,基于 Trino+Hive 架构的小时级数据时效性已无法满足业务需求,业务侧需要数仓架构能够实时抽取业务侧数据并加工,从而实现上层报表的实时呈现,以便更好地支持相关的决策分析。

访问量挑战,性能与稳定性亟待提高,支撑业务稳定运行
随着业务规模向全球发展,vivo 的分销代理系统覆盖用户量级飞速增长,营销、计价、订单、库存等业务系统均需要实时数据来保证销售业务精准稳定运营,这使得原有数仓架构的访问量持续增长,同时,随着各种大数据分析相关新业务的上线, Trino 负载越来越高,逐渐无法满足访问量持续增长带来的查询压力。

计算场景挑战,难以满足业务复杂查询需求
在业务侧的实际分析需求中,经常会有十几张表 Join 的场景,业界存在 Flink 和 Trino 两种方案。
第一种方案是在写入数仓前利用 Flink 等提前做好相关表的 Join 计算,将其加工成大宽表写入数仓中,但 Join 后的数据存储占用代价高。
第二种方案则是直接将各个维表存储在数仓中,分析查询的时候再进行 Join 计算,但 Trino 在处理多表 Join 时性能一般,难以满足业务侧实际的查询需求。
这两种方案都没有办法很好的平衡表 Join 的性能和数据存储占用的问题。
运维挑战,用户查询体验需优化
在实际运维使用 Trino 的过程中,vivo IT 部门发现 Trino 不支持高可用和多副本的问题,在业务高峰期,Trino 负载较高,会影响到数据平台的稳定性和用户查询体验,降低业务决策效率,甚至有可能收到用户对数据平台的投诉。
StarRocks 破局:OLAP 选型与实践
面对上述挑战,vivo 开始寻找一款新的 OLAP 引擎以提升数据平台的性能。
vivo IT 部门调研了几款当前比较流行的 OLAP 引擎,包括 Trino、ClickHouse、StarRocks 和 Doris,并从查询延迟、SQL 类型、并发性能、Join 性能和运维成本等多个维度进行了对比:
-
Trino 当前的查询性能和并发能力是无法满足需求的,且 Join 查询的能力也相对较弱。 -
ClickHouse 虽然查询延迟表现很优秀,但由于其支持的 SQL 类型为非标准 SQL,可能会涉及到较多的业务改造,同时其并发能力和 Join 能力也无法满足需求,且运维起来比较复杂。 -
StarRocks 在调研的各个维度上表现都非常好,能够很好地解决当前数仓架构所面临的问题。 -
Doris 在选型时还不支持向量化引擎,其查询表现和 StarRocks 相比还存在一定的差距。

经过深入调研与测试,vivo IT 部门总结了 StarRocks 的一些优势: 查询性能优秀:查询延迟在亚秒级别,Join 性能优秀,能够满足 vivo 对实时大数据分析的需求
使用方便:支持数据导入、导出等功能
数据模型丰富:支持明细模型、聚合模型、更新模型、主键模型,其中主键模型能够很好地满足 vivo 大数据的场景
运维成本低:支持高可用、在线扩缩容、数据分片自动均衡
基于以上的对比与考量,最终选择了使用 StarRocks 来作为数据平台的 OLAP 引擎。
StarRocks 应用为业务搭建数据桥梁
在过去 2 年里,vivo IT 部门深度应用 StarRocks,并通过 StarRocks 进一步完善数据架构,帮助业务更好地使用和查询数据。
vivo IT 部门对接的业务主要有可视化报表、BI 数据探索、营销分析、驾驶舱、数据大屏等,另外对应的还有研发系统和运维系统。
vivo 的数据主要来自于手机相关的订单、ERP、MES 以及其他数据,在升级数据分析平台架构后,他们将 StarRocks 应用在查询引擎中,为业务团队搭建数据桥梁,支撑上层业务应用更快地查询,更准地分析。

数据链路优化,让查询更便捷
vivo 的数据链路分为离线和实时链路,其中离线链路主要是通过 Trino 进行离线抽数到 Hive 中,经过 Hive 加工处理为大宽表,再推到 ClickHouse 中进行离线场景数据的查询;
实时链路则通过 Flink 加工后写入到 Kafka 中,然后通过 Flink 消费处理写入到 StarRocks 中进行实时表的查询。
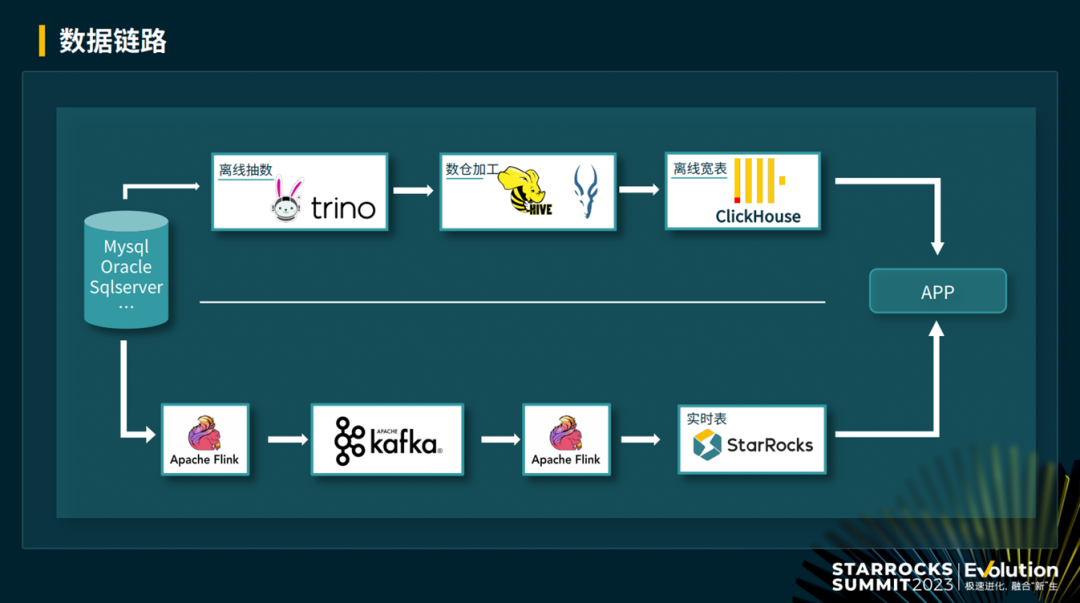
列更新(Partial Update),优化性能同时降低资源消耗
StarRocks 的 Join 性能表现很好,不过频繁的 Join 查询会带来计算资源的大量消耗。基于此,vivo IT 部门使用 Flink 将多个维表打平为大宽表,写入 StarRocks 来进行查询,在节省 StarRocks 计算资源的同时,查询体验也更好。
针对维表历史数据变更的场景,他们使用 StarRocks 提供的部分列更新(Partial Update)功能,在 Flink 写入主键模型大宽表的过程中,通过一些简单的配置开启部分列更新,实现以较小的代价灵活地更新大宽表中对应的列数据。
集群监控告警,灵活、便捷运维
在常规的监控告警方面,由于 StarRocks 提供了丰富的 Metrics 接口,便于Prometheus 采集并存储 StarRocks 集群各个节点的状态信息,以供 Grafana 生成各种可视化的 Panel。
另外 vivo IT 部门还会对集群的审计 SQL 进行采集分析,通过 ELK 将各个 FE 节点的审计日志采集后写入到 Elasticsearch 中,通过配置规则,筛选出其中的慢 SQL,推送到告警系统中,以提醒相应的同事关注及优化。
弹性方案,降本增效
vivo 的业务特点是业务访问量存在波峰波谷,且波峰波谷之间的访问量差异明显、时间界限明显,业务对访问持续时间更短的波峰期性能要求高,服务器资源使用率考核压力大。
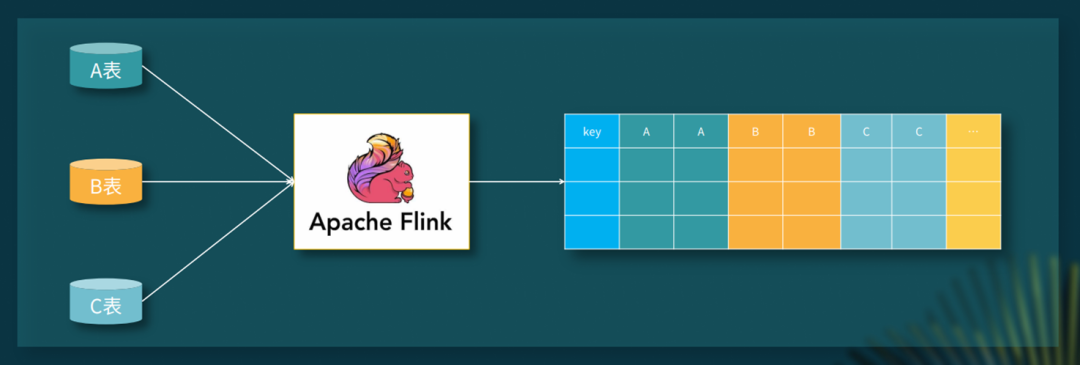
对于国内集群,vivo IT 部门采取了多集群的模式来分担高峰期的查询访问量,通过负载均衡将流量分摊到主备集群。
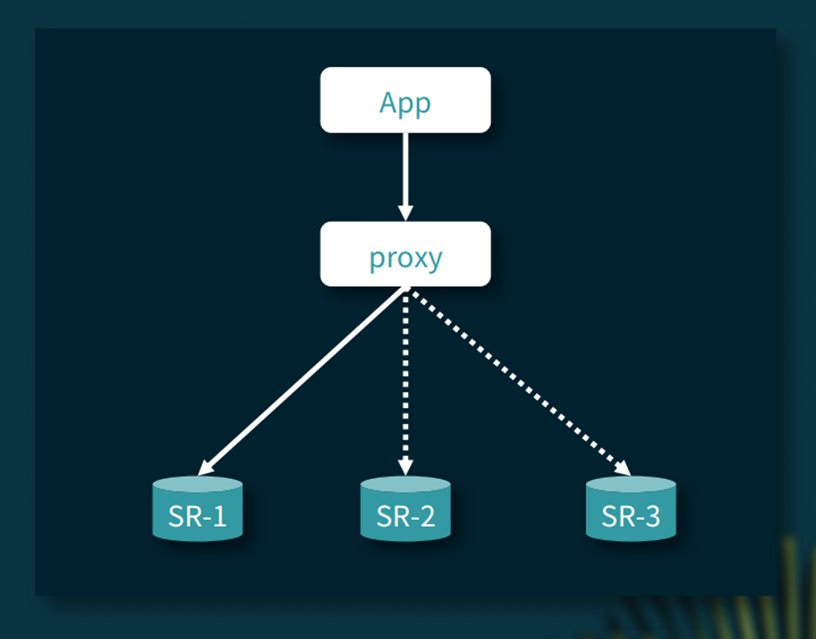
海外集群则依赖于 StarRocks 的多副本高可用机制,采用各个节点轮询升降配实现集群配置的扩缩容。具体的流程如下图所示,vivo IT 部门将整个流程通过代码的方式嵌入到运维平台里,通过程序自动化调度执行,提高扩缩容执行的效率。
结语
在过去两年多的探索中,vivo 发现 StarRocks 具有便捷运维、便捷部署与弹性扩缩容能力,同时提供了卓越的查询性能,足以应对高并发查询场景。借助 StarRocks 数据库,vivo 打造了实时大数据分析平台,为业务实时分析提供高效支持。
在未来,vivo 将在云原生建设、存算分离等场景与 StarRocks 进行更加深入的探索,以实现数据平台的持续演进,同时也将关注 StarRocks 社区的发展,与其他企业和开发者共同推动项目进步。
本文由 mdnice 多平台发布
更多【r语言-vivo 基于 StarRocks 构建实时大数据分析平台,为业务搭建数据桥梁】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-C++学习第三十七天----第十章--对象和类 - 其他
- 算法-Python输出三角形面积和周长 - 其他
- 算法-C语言 每日一题 牛客网 11.12 Day16 - 其他
- 编程技术-新型的铁塔基站“能源管家” - 其他
- 深度学习-卷积输入输出计算 - 其他
- 编程技术-VsCode 安装 GitHub Copilot插件 (最新) - 其他
- 编程技术-Mysql数据库 15.SQL语言 索引 - 其他
- 编程技术-【赠书第4期】机器学习与人工智能实战:基于业务场景的工程应用 - 其他
- java-数据结构线性表——栈 - 其他
- objective-c-iOS OpenGL ES3.0入门实践 - 其他
- 编程技术-FreeRTOS知识梳理 - 其他
- 计算机视觉-【OpenCV实现图像:用OpenCV图像处理技巧之巧用直方图】 - 其他
- objective-c-axios请求的问题 - 其他
- 编程技术-c++四种类型转换 - 其他
- 编程技术-基于RK3568的跑步机方案 - 其他
- 网络-超级干货:光纤知识总结最全的文章 - 其他
- 编程技术-eNSP启动路由器一直出#号、以为是安装配置winpcap的问题。。。。(以为是win10安装winpcap失败的问题。。。) - 其他
- log4j-项目实战:中央控制器实现(2)-优化Controller,将共性动作抽取到中央控制器 - 其他
- 聚类-数据挖掘:分类,聚类,关联关系,回归 - 其他
- objective-c-http客户端简单demo - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- Android安全-【从源码过反调试】二、过PTRACE_TRACEME
- Android安全-【从源码过反调试】一、安卓12过IsDebuggerConnected检测
- Android安全- Android Studio Debug dlopen
- Android安全-记一次对vm保护的算法的快速定位
- 编程技术- 驱动开发:通过Async反向与内核通信
- 加壳脱壳- [原创工具] FRIDA-JS-DEXDump 基于Frida的内存脱壳工具(学习frida-dexdump的成果)
- Pwn-小小做题家之——musl 1.2.2的利用手法
- 编程技术-cmake使用
- Pwn-手动编译测试musl1.2.2 meta dequeue特性
- 软件逆向-高级APT木马逆向分析
