架构-BERT架构简介
推荐 原创一、BERT模型架构
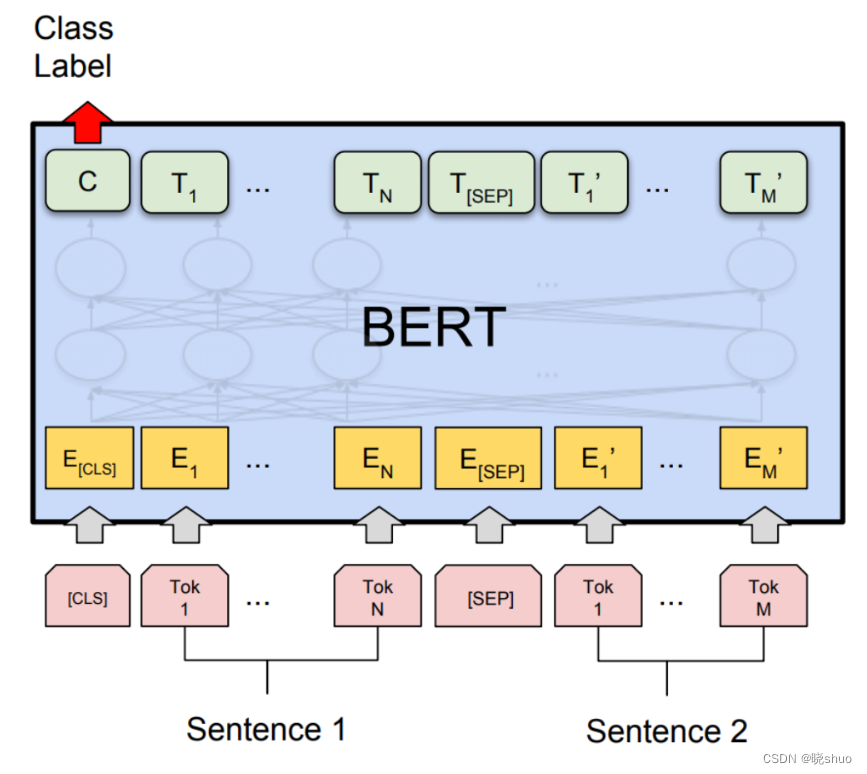
BERT沿用原始Transformer模型中的编码器层,具有编码器的堆叠。但BERT没有使用解码器层,因此没有掩码多头注意力子层。(BERT的设计者认为,对序列后续部分进行掩码会阻碍注意力过程)。于是,BERT引入了双向注意力机制,即一个注意力头从左到右,另一个注意力头从右到左注意所有单词。
二、BERT模型训练
BERT的训练过程分为两项任务:掩码语言建模(Masked Language Modeling,MLM)和下一句预测(Next Sentence Prediction, NSP)
2.1 掩码语言建模
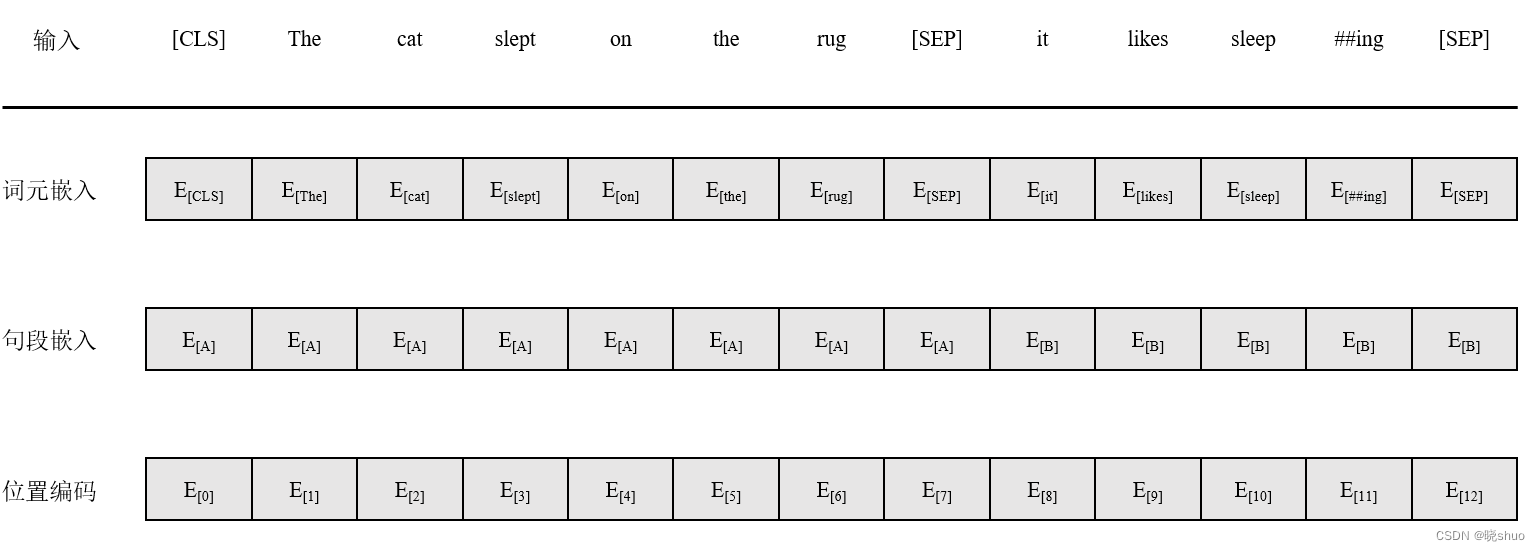
BERT对句子进行双向分析,随机对句子中的某一个单词进行随机掩码。
原句:The cat sat on it because it was a nice rug.
Transformer:The cat sat on it <masked sequence>.
BERT:The cat sat on it [MASK] it was a nice rug.
上述掩码过程只是一个注意力子层的效果,当使用多个注意力子层时,就可以看到整个序列,运行注意力过程,然后观测被掩码的词元。
2.2 下一句预测
在这个过程中会添加两个新的词元:
-
[CLS]词元:二分类词元,添加到第一个句子的开头,用于预测第二个句子是否跟随第一个句子。
-
[SEP]词元:分隔符词元,添加到每个句子的结尾,用于分隔不同的句子。
2.3 总结
- 使用WordPiece对句子进行词元化
- 使用[MASK]词元随机替换句子中的单词
- 在序列的开头插入[CLS]分类词元
- 在序列的两个句子结尾插入[SEP]词元
- 句子嵌入是在词嵌入的基础上添加的,因此句子A和句子B具有不同的嵌入值
- 位置编码采用了可学习方法,而没有采用原始Transformer中的正弦-余弦位置编码方法
参考文献
[1] 丹尼斯·罗斯曼.《基于GPT-3、ChatGPT、GPT-4等Transformer架构的自然语言处理》 [M]. 北京: 清华大学出版社, 2024
更多【架构-BERT架构简介】相关视频教程:www.yxfzedu.com
相关文章推荐
- 数据库-长安链可验证数据库,保证数据完整性的可信存证方案 - 其他
- 前端框架-React Hooks为什么要在顶层使用? - 其他
- flink-Flink之Java Table API的使用 - 其他
- c#-C# List<T>.IndexOf()方法的使用 - 其他
- 计算机视觉-Libra R-CNN: Towards Balanced Learning for Object Detection(2019.4) - 其他
- ar-Angular 由一个bug说起之一:List / Grid的性能问题 - 其他
- vr-VR全景技术,为养老院宣传推广带来全新变革 - 其他
- 网络-【广州华锐互动】VR安防网络综合布线仿真实训打造沉浸式的教学体验 - 其他
- list-使用多线程处理List数据 - 其他
- vr-【广州华锐互动】楼宇智能化VR虚拟教学系统 - 其他
- 笔记-FreeRTOS源码阅读笔记2--list.c - 其他
- react.js-Antd React Form.Item内部是自定义组件怎么自定义返回值 - 其他
- 区块链-2023年A股借壳上市研究报告 - 其他
- spring-Spring Boot中处理简单的事务 - 其他
- 网络-【hcie-cloud】【4】华为云Stack规划设计之华为云Stack标准组网【中】 - 其他
- 华为云-基于STM32设计的智能水母投喂器(华为云IOT) - 其他
- 缓存-【Redis】list常用命令&内部编码&使用场景 - 其他
- pdf-PDF有限制密码,不能复制怎么办? - 其他
- objective-c-【Objective-C】Objective-C汇总 - 其他
- node.js-npm切换镜像源 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- 软件逆向-记Github上下载到的WinExplorer夹带私货
- 编程技术-读取W25Q64的设备ID时输出0xff
- 金融-可以写进简历的软件测试项目(银行/金融/电商/商城......)
- 百度-想要创建百度百科词条怎么做?
- c#-C#基于inpoutx64读写ECRAM硬件信息
- java-JavaScript如何实现钟表效果,时分秒针指向当前时间,并显示当前年月日,及2024春节倒计时,源码奉上
- c++-Linux驱动应用层与内核层之间的数据传递
- 人工智能-读书笔记:彼得·德鲁克《认识管理》第11章 若干例外及经验教训
- 运维-短时间不点击云服务器,自动化断开连接,怎么设置长时间
- 运维-Rocky Linux 配置邮件发送
