ocr-OCR文本纠错思路
推荐 原创文字错误类别:多字 少字 形近字
当前方案
文本纠错思路
简单:
一、构建自定义词典,提高分词正确率。不在词典中,也不是停用词,分成单字的数据极有可能是错字(少部分可能是新词)。错字与前后的词语组成错词 (分词工具:cutword)
二、利用字形相似度获取错词的字形最相似词语 参考: https://github.com/tiantian91091317/OCR-Corrector(FASPell采用字符串编辑距离进行计算 )
难点:
-
字形相似度计算还不够准
-
错字与前后的词语组成的错词可能不准确
-
需要不断维护词典
解决的问题
提高检错率
jieba有HMM新词算法,错词无法单独分出来
cutword 词典的一些词 对于 特定领域 可能是错词,需要删除
提高组词正确率
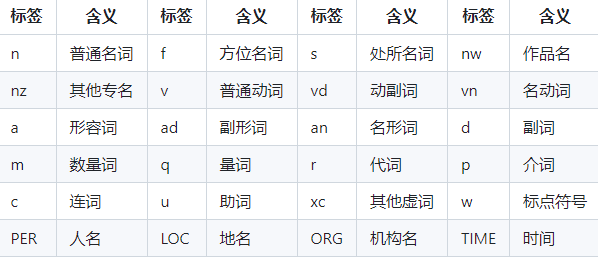
# baidu lac
from LAC import LAC
# 装载LAC模型
lac = LAC(mode='lac')
# 单个样本输入,输入为Unicode编码的字符串
text = u"含固书馆学、档案学"
lac_result = lac.run(text)
lac_result
# [['含', '固书馆学', '、', '档案学'], ['v', 'n', 'w', 'n']]
对于部分文本效果不错,但是还有部分文本实体识别粒度太大,比如:

paddlenlp
taskflow.md
容易出现实体识别不出的情况,弃用
# 批量样本输入, 输入为多个句子组成的list,平均速率更快
texts = [u"LAC是个优秀的分词工具", u"百度是一家高科技公司"]
lac_result = lac.run(texts)
# paddle nlp Taskflow
from pprint import pprint
from paddlenlp import Taskflow
schema = ['专业名称', '地点', '人名','学校名称','班级名称'] # Define the schema for entity extraction
ie = Taskflow('information_extraction', schema=schema)
sentence = '中外合作办学,新西兰尼尔森马尔佰勤理工学院合作办学'
sentence = '日语、俄语、德语、法语、西班牙语,人校后可参与选拨项目:涉外法治双主学位项目、国际新闻全英文实验班:各语种均有机会进人自标语言国著名高校进行交流学习'
pprint(ie(sentence))
初始思路
目标:通过正确数据对错误数据进行检测与纠正
错字检测+修正:
检测错字:
参考:
kenLM统计语言模型构建与应用
kenlm
- 将正确数据分词构建词典
kenlm计算一个句子中连续的n个单词的概率来评估句子结构合法性,kenlm检测错字有两种方法,1.使用招生计划的数据做语料训练模型,让模型对句子合法性打分 2.使用pycorrector kenlm模型,检测错字
纠正错字:
参考 https://github.com/shibing624/pycorrector
检测到的错字在一个词语中,该词任一字都可能是错字。 - 根据语义编辑距离,找到该错字所在词语与字典中的词最相似的词,如果相似度超出阈值,则替代该词(需要增加形近字字典)
- 利用正确数据训练一个自然语言处理模型(类bert),不将错字掩盖,预测正确的字,预测字与错字相似度超出阈值,并在词典中,则修正
kenlm
kemlm检错原理:利用 2-gram 、3-gram 语言模型找到错误位置;
利用形近字字表生成候选句(对应上文的使P(O|I)最大的n个 Input);
利用语言困惑度找到得分最低的候选句(对应上文的使P(I)最大的Input)。
使用pycorrector项目加入专有名词字典后(数量大概有几万),检索速度太太太慢。并且训练kenlm模型正确数据不够。所以放弃kenlm.
bert
待正确数据更多后,再训练bert模型
更多【ocr-OCR文本纠错思路】相关视频教程:www.yxfzedu.com
相关文章推荐
- stm32-FPGA与STM32_FSMC总线通信实验 - 其他
- spring-springboot集成redis -- spring-boot-starter-data-redis - 其他
- ios-LibXL 4.2.0 for c++/net/win/mac/ios Crack - 其他
- unity-Unity DOTS系列之System中如何使用SystemAPI.Query迭代数据 - 其他
- 网络-openssl+SM2开发实例一(含源码) - 其他
- spring-Redis的内存淘汰策略分析 - 其他
- 单一职责原则-01.单一职责原则 - 其他
- 分布式-Java架构师分布式搜索词库解决方案 - 其他
- 电脑-京东数据分析:2023年9月京东笔记本电脑行业品牌销售排行榜 - 其他
- 云计算-什么叫做云计算? - 其他
- 编程技术-基于springboot+vue的校园闲置物品交易系统 - 其他
- 零售-OLED透明屏在智慧零售场景的应用 - 其他
- 交互-顶板事故防治vr实景交互体验提高操作人员安全防护技能水平 - 其他
- unity-原型制作神器ProtoPie的使用&Unity与网页跨端交互 - 其他
- python-Django知识点 - 其他
- 前端-js实现定时刷新,并设置定时器上限 - 其他
- 需求分析-2023-11-11 事业-代号s-duck-官网首页需求分析 - 其他
- node.js-【第2章 Node.js基础】2.5 Node.js 的定时器 - 其他
- 编程技术-parasoft Jtest 使用教程:防止和检查内存问题 - 其他
- hive-【Python大数据笔记_day06_Hive】 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- Android安全-某相机APP分析
- Android安全- 安卓某加固脱壳
- Pwn-无路远征——GLIBC2.37后时代的IO攻击之道(四)house_of_魑魅魍魉
- Pwn-无路远征——GLIBC2.37后时代的IO攻击之道(三)house_of_借刀杀人
- Pwn-Binwalk命令执行漏洞复现-CVE-2022-4510
- Pwn-无路远征——GLIBC2.37后时代的IO攻击之道(二)house_of_秦月汉关
- 智能设备-[工控安全]CodeSys V3 协议及授权机制分析
- 2-抖音最新版抓包方案
- Android安全-四川航空sign分析
- Pwn-无路远征——GLIBC2.37后时代的IO攻击之道(零)
