语言模型-ABeam Insight | 大语言模型系列 (1) : 大语言模型概览
推荐 原创大语言模型系列
引入篇
ABeam
Insight
自从图灵测试在20世纪50年代提出以来,人类一直不断探索机器如何掌握语言智能。语言本质上是一个由语法规则支配的错综复杂的人类表达系统。
近年来,具备与人对话互动、回答问题、协助创作等能力的ChatGPT等大语言模型应用横空出世,引发社会热议,成为全球科技的竞争焦点。大语言模型也成为人工智能发展的热点方向,有望给人工智能创新带来爆发式增长。
本系列文章中,ABeam将聚焦于大语言模型,探讨大语言模型的商业模式和行业应用案例,以期为不同类型的企业带来迎接科技浪潮、拥抱大模型的新灵感。
本期作为大语言模型系列的引入篇,将为大家介绍语言模型及其演进历程、大语言模型的底座、概念、特点等基本概览。
01
关于语言模型
About Language Model
1
概念
语言模型是根据语言客观事实而进行的语言抽象数学建模,是一种对应关系。语言模型与语言客观事实,就如同数学上的抽象直线与具体直线之间的关系。
2
语言模型的任务
■ 判断句子的语言序列是否为正常语句
【例】语言序列W1,W2,W3,…,Wn
P=概率
语言模型即P(W1,W2,W3,…,Wn )
■ (在语言识别、机器翻译等任务中)对候选答案进行打分排序,以此筛选出正确结果
【例】语音识别:
结果1-再给我两份葱,让我把记忆煎成饼
结果2-再给我两分钟,让我把记忆结成冰
评分:结果2>结果1
02
语言模型研究的关键概念及技术
Key Concepts and Techniques
语言模型研究中包含多种关键概念及技术,通过改进各个方面,达成模型研究的发展。

数据来源:ABeam根据公开资料整理
03
语言模型演进里程
Milestones
从传统二十世纪中期的N-gram模型,渐渐发展至神经网络模型,再到现今的Transformer架构,语言模型一路不断创新,实现了自然语言处理领域的重大进步。
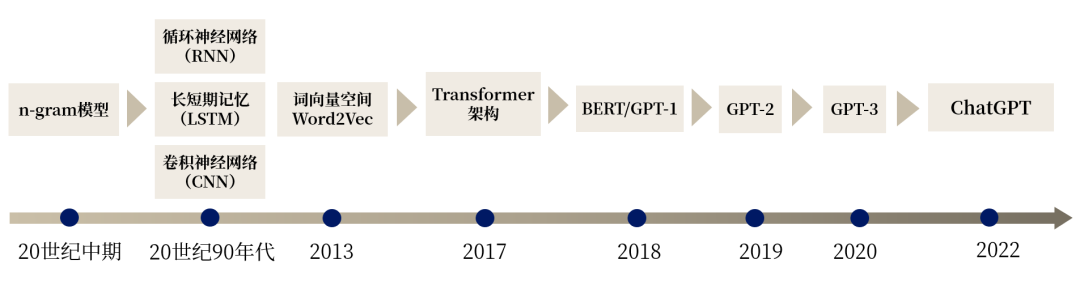
数据来源:ABeam根据公开资料整理
04
大模型底座--Transformer架构
Transformer Architecture
Transformer模型是一种深度学习架构,自2017年推出以来,彻底改变了自然语言处理(NLP)领域的发展。该模型由Vaswani等人提出,并已成为NLP界非常具有影响力的模型之一。
它在机器翻译、文本摘要、问答系统等多个自然语言处理任务中取得了显著的性能提升。Transformer模型的突破性表现使得它成为现代自然语言处理、研究和应用中的重要组成部分。它能够捕捉复杂的语义关系和上下文信息,极大地推动了自然语言处理的发展。
1
特点
Transformer模型引入了自注意力机制(self-attention),使得模型不仅能够关注当前的词,还能关注句子其他位置的词,进而确定输入的序列哪些与输出强相关。
故而训练模型时不必标记所有的训练数据,可以直接导入大段文本,进行留空训练,对输出内容进行纠正。
05
关于大语言模型
About Large Language Models
1
概念
大语言模型(LLM)是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。大语言模型可以处理多种自然语言任务,如文本分类、问答、对话等,是通向人工智能的一条重要途径。
2
特点
规模庞大、包含数十亿参数,以帮助它们学习语言数据中的复杂模式。
3
与小模型的区别
大语言模型与以前AI模型的不同之处在于其通用性和泛化能力。它们通过预训练阶段获取了深刻的语言理解,使其在处理不同任务时无需大量标注样本,这降低了依赖标注数据的程度。

数据来源:ABeam根据公开资料整理
4
目前主流大语言模型(部分)
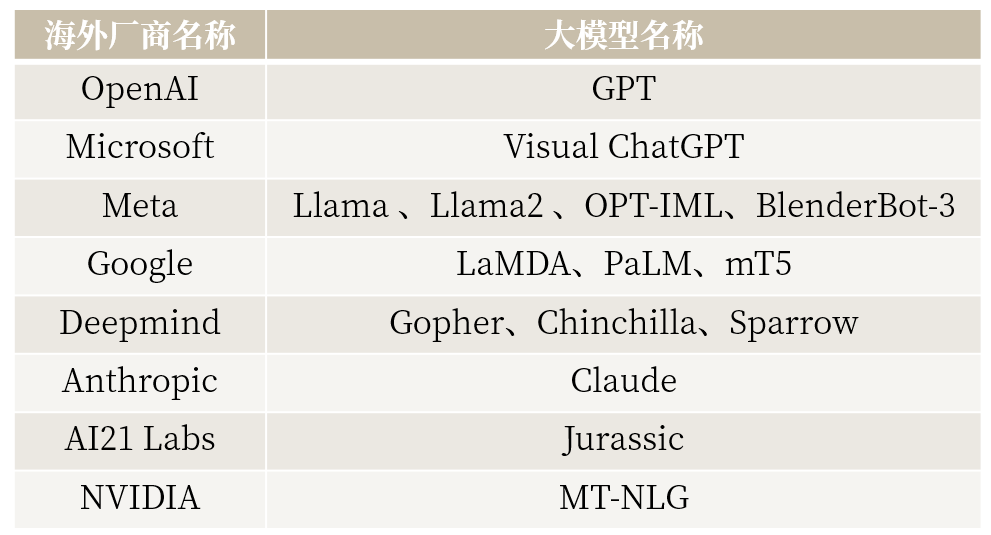
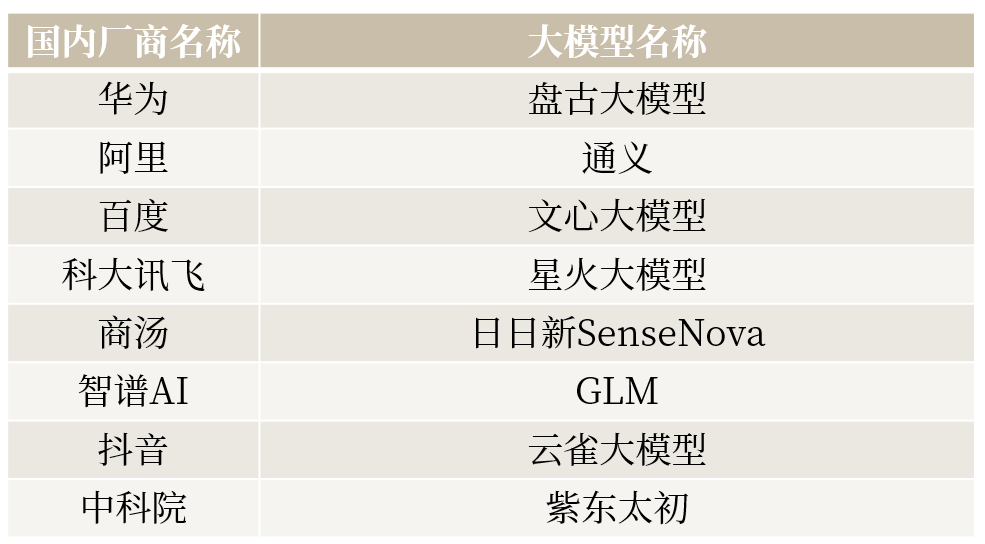
下期,ABeam将着眼于
大语言模型的商业模式及商业价值,
为大家解锁更多大语言模型的深层逻辑。
敬请期待~
更多【语言模型-ABeam Insight | 大语言模型系列 (1) : 大语言模型概览】相关视频教程:www.yxfzedu.com
相关文章推荐
- 前端框架-vue项目中页面遇到404报错 - 其他
- 安全-vivo 网络端口安全建设技术实践 - 其他
- 前端框架-前端框架Vue学习 ——(五)前端工程化Vue-cli脚手架 - 其他
- 物联网-ZZ038 物联网应用与服务赛题第D套 - 其他
- 爬虫-网络爬虫的实战项目:使用JavaScript和Axios爬取Reddit视频并进行数据分析 - 其他
- c语言-ZZ038 物联网应用与服务赛题第C套 - 其他
- c语言-cordova Xcode打包ios以及发布流程(ionic3适用) - 其他
- 物联网-Xcode15 framework ‘CoreAudioTypes‘ not found - 其他
- 科技-打造高效运营底座,极智嘉一体化软件系统彰显科技威能 - 其他
- golang-深入剖析Golang中单例模式 - 其他
- 网络-工业自动化工厂PLC远程控制网关物联网应用 - 其他
- react.js-React Native自学笔记 - 其他
- android-【Android】Lombok for Android Studio 离线插件 - 其他
- android-Android Studio新建项目下载依赖慢,只需一个操作解决 - 其他
- 后端-使用 Ruby 的 Nokogiri 库来解析 - 其他
- 编程技术-一、配置环境 - 其他
- 算法-03 矩阵与线性变换 - 其他
- android-Android Studio(控件常用属性) - 其他
- 编程技术-ES使用ik分词器查看分词结果及自定义词汇 - 其他
- asp.net-asp.net水资源检测系统VS开发sqlserver数据库web结构c#编程Microsoft Visual Studio - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
