Android安全-记一次基于unidbg模拟执行的去除ollvm混淆
推荐 原创0.前言
代码混淆是逆向分析中最令人头疼的问题之一。
面对混淆,通常的做法是直接硬着头皮调试,因为混淆只能混淆代码的形,但是代码的神——执行逻辑是不会变的,单步调试下去往往能梳理出程序本身的执行逻辑。但是面对非常复杂的混淆,小弟我也是经常调试数十小时最终招架不住选择放弃。。。有位伟人曾经说过“安全保护的目的不在于让代码固若金汤,无法攻破,而是在于让破解者望而生畏,主动放弃”,正所谓“不战而屈人之兵,善之善也~”,小弟我深以为然。
面对混淆更好的做法是去混淆,或者说反混淆,就是将混淆过的代码还原回去。还原后的代码通常逻辑清晰,通俗易懂,可以很简单的进行分析。但是反混淆往往比较难,抛开各种定制的混淆不说,即使是最基本的ollvm混淆,还原起来也不是那么容易。因为还原混淆通常要依赖于符号执行,模拟执行,指令trace等一系列高级的逆向手法。小弟我最近刚好遇到一个混淆的样本,趁着五一放假,研究了一下反混淆的方法,最终成功还原出了真实逻辑,故借此机会和论坛各位安全爱好者做一分享。
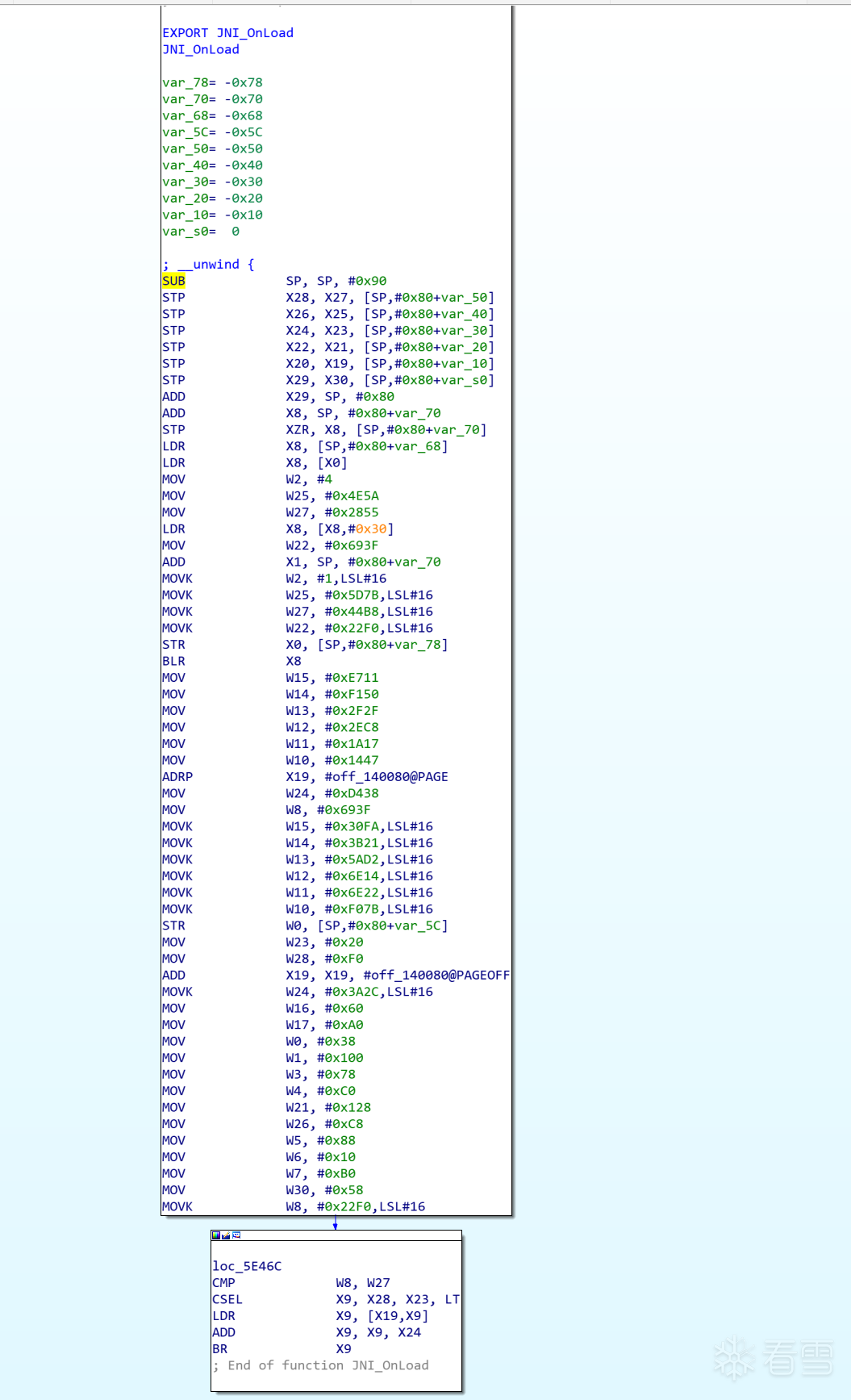
混淆前的程序,可以看到在 br x9 后ida无法分析了,因为x9是一个寄存器,ida并不知道里面是什么值,所以无法继续向下分析。F5后可以看到,函数调用jni->GetEnv函数后就jumpout了。

往下查看汇编代码,可以看到函数里有许多根据寄存器跳转的指令:
1.unidbg环境搭建
去混淆通常要对代码进行模拟执行。
模拟执行届扛把子的是unicorn引擎。不过unicorn引擎相对比较底层,需要手动的开辟内存,将指令写入,设置堆栈的位置,设置寄存器初始值,然后执行。unidbg是基于unicorn引擎的模拟执行框架,使用java语言编写,并且可以直接加载so,进行调用(unidbg在加载动态库时自动帮你完成了文件解析,映射,重定位,写入unicorn引擎等一系列底层操作),同时unidbg内置了Jni相关的环境,而unicorn本身没有相关环境,需要手动补充。同时,unidbg还内置了hookZz,xHook等一系列hook框架,可以很方便的进行函数级,指令级的各种hook。总之,unidbg大大方便了逆向人员进行模拟执行的流程,所以我们选用unidbg来进行模拟执行。
1.1 下载源码
unidbg的工作模式简单粗暴,直接git clone unidbg的项目,然后在项目里添加自己的模拟执行类,最终运行的时候是带着整个项目的源码一起运行的,这样做的好处是方便了定制化修改和源码调试。
下载好后使用idea进行打开。
1.2 模拟执行
直接在项目的unidbg-android/src/test/java目录下建立我们的模拟执行类:AntiOllvm
在进行模拟执行之前,需要做以下准备工作:
1.创建一个模拟器。
2.设置android系统库的版本
3.创建android虚拟机
4.加载动态库
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
public AntiOllvm()
{
/
/
创建模拟器
emulator
=
AndroidEmulatorBuilder
.for64Bit()
.addBackendFactory(new Unicorn2Factory(true))
.setProcessName(
"com.example.antiollvm"
)
.build();
Memory memory
=
emulator.getMemory();
/
/
设置andorid系统库版本
memory.setLibraryResolver(new AndroidResolver(
26
));
/
/
创建虚拟机
vm
=
emulator.createDalvikVM();
vm.setVerbose(true);
/
/
加载动态库
dm
=
vm.loadLibrary(new
File
(
"f:\\kshs\\libtprt.so"
), false);
module
=
dm.getModule();
}
|
这样,动态库就被unidbg加载了。
加载后需要先执行jni_onload,而DalvikModule这个类已经实现了callJNI_OnLoad方法,我们直接调用即可。
|
1
2
3
4
5
6
7
8
9
|
public static void main(String[] args) {
AntiOllvm ao
=
new AntiOllvm();
ao.callJniOnload();
}
public void callJniOnload()
{
dm.callJNI_OnLoad(emulator);
}
|
调用后,出现了报错和许多warning:
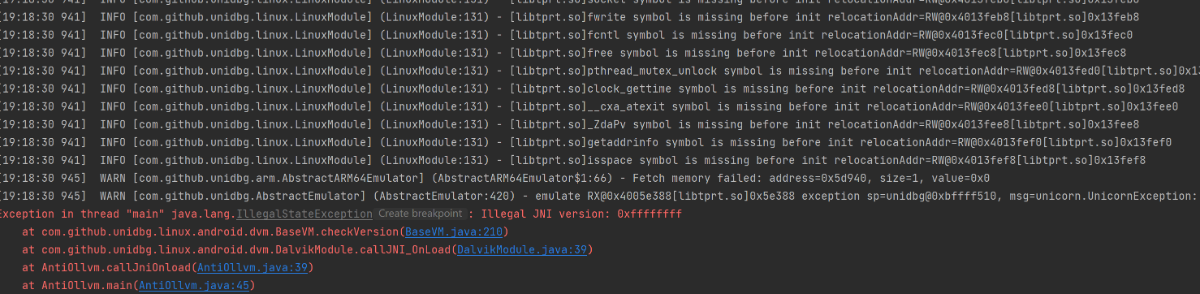
一方面,有许多libc的函数没有找到,另一方面,JNI返回了-1。
我们先补充所需的libc函数,只需要把手机里/system/lib64/libc.so等系统库交给unidbg加载即可。
将下列代码添加到加载目标so之前:
|
1
2
3
4
5
|
vm.loadLibrary(new
File
(
"f:\\androidlib\\libc.so"
),false);
vm.loadLibrary(new
File
(
"f:\\androidlib\\libm.so"
),false);
vm.loadLibrary(new
File
(
"f:\\androidlib\\libstdc++.so"
),false);
vm.loadLibrary(new
File
(
"f:\\androidlib\\ld-android.so"
),false);
vm.loadLibrary(new
File
(
"f:\\androidlib\\libdl.so"
),false);
|
再次执行,这次运行成功了,并且unidbg hook 了所有的jni掉用,也将他们打印了出来:

可以看到,在0x5e900处调用了registernative,注册的函数名叫:initialize,签名是:(Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;Ljava/lang/String;[Ljava/lang/String;Ljava/lang/String;)I,函数的地址在0x5e1e8处。
至此,我们成功使用unidbg加载了android的动态库,并且正常运行了动态库的jni_onload函数。
1.3 基本的hook
我们已经成功运行了目标动态库,接下来可以看看还能做些什么。我们做一个最基本的操作,使用指令hook,在每条指令执行之前将其打印出来。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
public void logIns()
{
emulator.getBackend().hook_add_new(new CodeHook() {
@Override
public void hook(Backend backend,
long
address,
int
size,
Object
user) {
Capstone capstone
=
new Capstone(Capstone.CS_ARCH_ARM64,Capstone.CS_MODE_ARM);
byte[] bytes
=
emulator.getBackend().mem_read(address,
4
);
Instruction[] disasm
=
capstone.disasm(bytes,
0
);
System.out.printf(
"%x:%s %s\n"
,address
-
module.base ,disasm[
0
].getMnemonic(),disasm[
0
].getOpStr());
}
@Override
public void onAttach(UnHook unHook) {
}
@Override
public void detach() {
}
}, module.base, module.base
+
module.size, null);
}
|
使用到的是unicorn引擎提供的codehook,即指令hook。我们在指令执行前进行hook,然后初始化Capstone引擎(反汇编引擎),接着通过unicorn的接口从当前地址读取4字节机器码,再将机器码反汇编,然后打印输出。我们可以将hook的范围指定在一个函数中,这样就不会打印超出该函数范围的指令了:
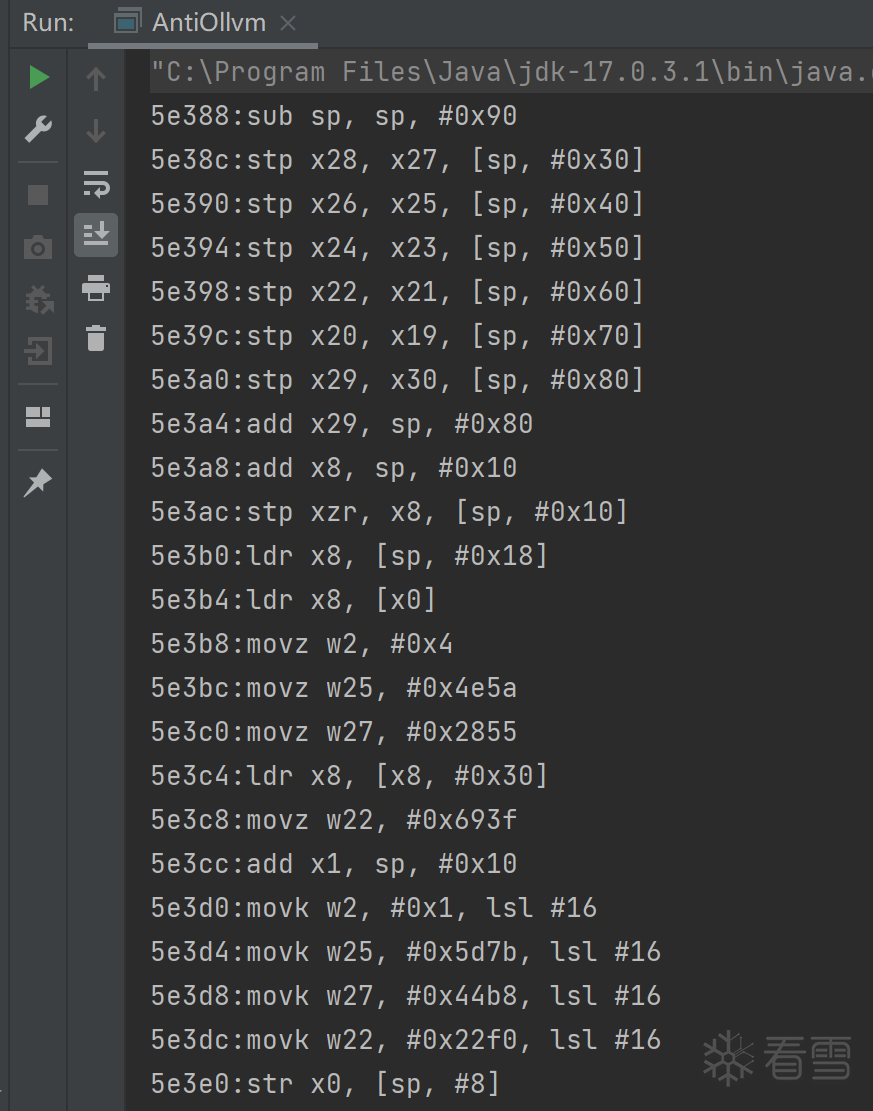
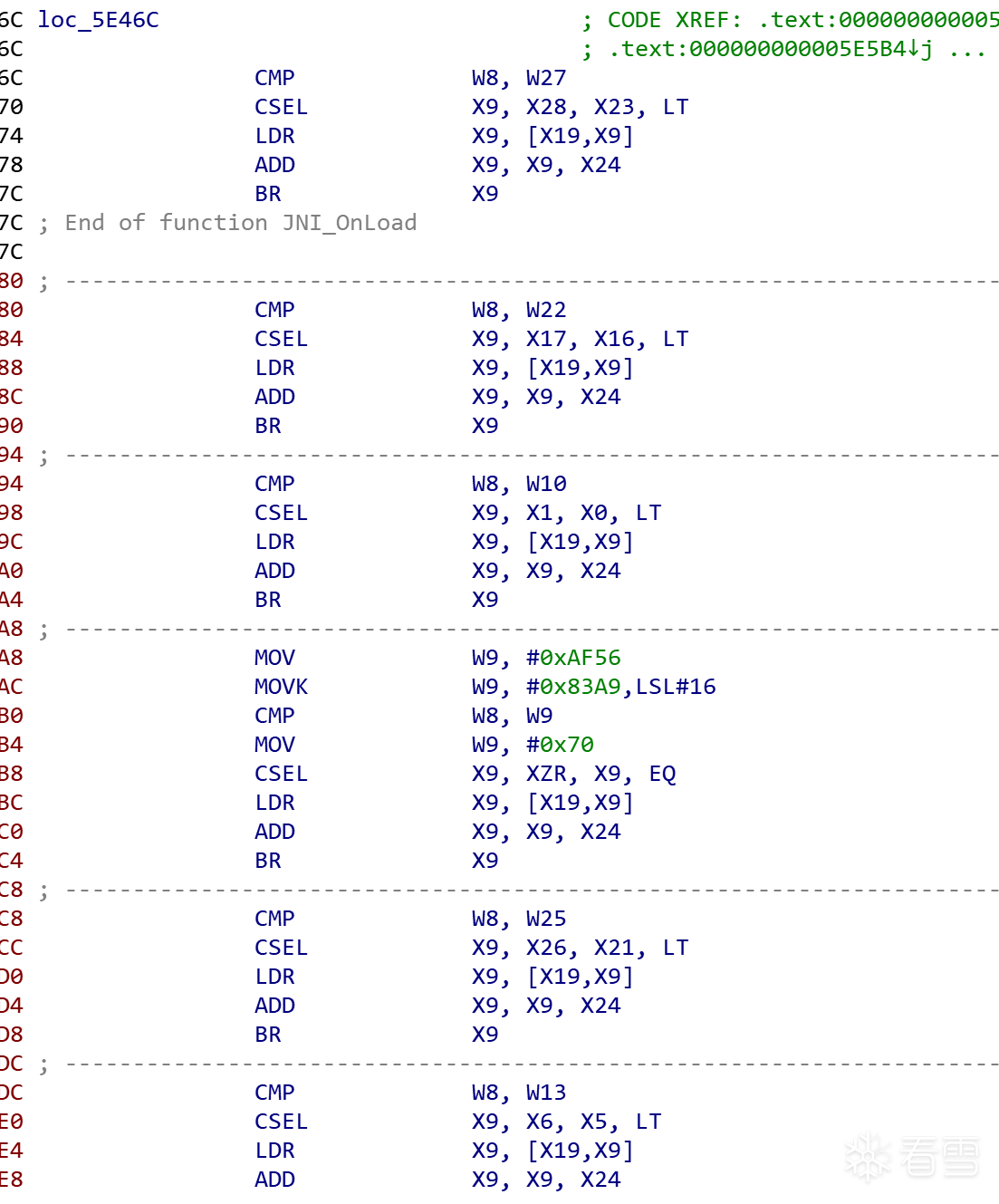
可以看到,打印的指令和ida中解析出的jnionload函数指令一致。当然,我们也看到了br x9之后的那条指令:
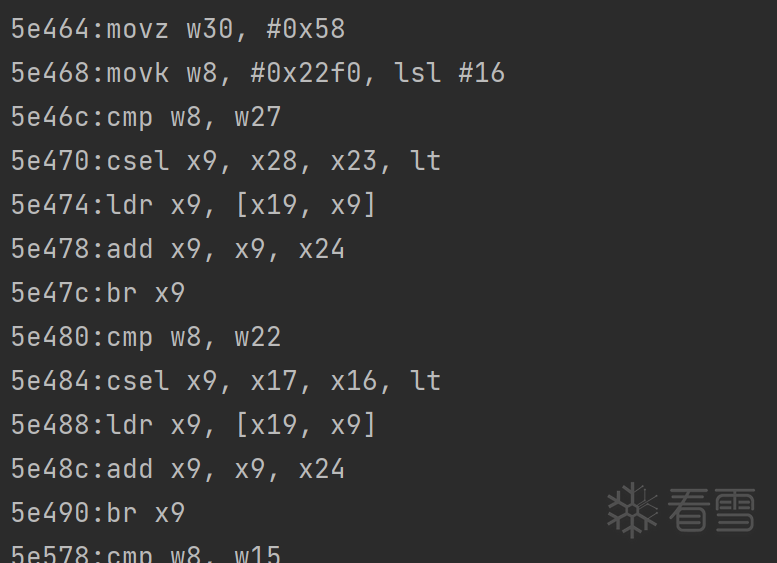
跳转到0x5e480,又执行了若干组间接跳转。
至此,我们已经可以通过unidbg的接口,进行指令trace。同时我们还可以使用unidbg提供的其他接口,在hook的同时读取,写入寄存器,查看内存,修改内存,设置断点等等。接下来我们就可以开始着手去混淆了。
2.去除间接跳转
首先要解决的是 br x9 的问题,至少让ida能F5吧。
通过阅读汇编代码,可以看到该函数的混淆是这样做的:
1.比较 w8 和 wk(另外一个寄存器,不固定)寄存器。
2.根据比较的结果,选择xA或者xB寄存器的值赋值给X9
3.从x9 + x19的地址处读取一个值,赋值给x9
4.x9 = x9 + x24
5.跳转到x9指向的位置。
其中,x19和x24始终是固定的,我们看到,x19和x24在程序开始时被初始化了:


可以看到,X19是0x140080,而0x140080是一个数组
x24则为固定的值0x3a2cd438
这里就理解这个间接跳转是怎么做的了,每次根据比较结果在数组中选择一个偏移,然后用偏移加上基数,得到真实的跳转地址。
所以我们可以在每次执行到br x9的时候获取x9的真实值,然后将根据寄存器跳转的指令br 换成直接跳转b,这样ida就可以继续分析了。
直接这样做有一个问题,因为偏移值是根据比较结果不同而不同,如果我们直接将最终的跳转地址写死,那就相当于将原来的条件跳转改为了直接跳转,改变了逻辑。
所以正确的做法是保留条件,计算出条件成立与不成立时对应的跳转地址,然后将br x9改为一条条件跳转和一条直接跳转,这样做就和原来的逻辑完全一致了,并且所有的跳转都是有确定的地址,ida可以分析。
于是我们用这样的算法进行还原:
1.建立一个指令栈,每条指令执行前,保留该指令的地址,指令内容,当前所有寄存器的值。然后将当前指令的信息push进指令栈。
3.pop跳转指令,再次获取栈顶指令,检查是否为ADD x9,x9,x24指令,如果是,进行4,否则执行下一条指令。
4.pop add指令,再次获取栈顶指令,检查是否为LDR x9,[x19,x9]指令,如果是,则进行5,否则执行下一条指令。
5.pop 加载指令,再次获取栈顶指令,检查是否为条件选择指令。如果是,记录选择条件,记录为条件成立与不成立时对应的选择的值(通过保留的寄存器值获取)。否则执行下一条指令。
6.pop 条件选择指令,获取到上一次 比较指令,检查是否是cmp x8,类型的指令,如果是,进行7,否则执行下一条指令。
7.通过前六步,说明我们已经定位到了正确的间接跳转的位置。然后分别计算条件成立与不成立时对应的真实跳转地址,将Add 指令替换为 条件跳转->成立时地址,将br x9替换为直接跳转->条件不成立地址。
以以下指令为例:
|
1
2
3
4
5
|
CMP
W8, W27
CSEL X9, X28, X23, LT
LDR X9, [X19,X9]
ADD X9, X9, X24
BR X9
|
在csel 一步,当条件LT成立时,x9 = x28。真实的跳转地址为
|
1
|
*
(x19
+
x28)
+
x24
/
/
记为addrT。
|
当条件不成立时,x9 = x23。真实的跳转地址为:
|
1
|
*
(x19
+
x23)
+
x24
/
/
记为addrF。
|
然后将add X9, X9, X24指令替换为b.lt addrT,
将br x9 指令替换为 b addrF。
将条件选择和加载指令nop掉。
替换后的指令为:
|
1
2
3
4
5
|
CMP
W8, W27
NOP
NOP
BLT addrT
B addrF
|
这样所有的间接跳转都变成了直接跳转,ida是可以分析的,并且逻辑与之前完全相同,我们所做的只不过是提前计算出目标地址,然后直接跳转罢了。
对应的java代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
|
/
/
保存指令和寄存器环境类:
class
InsAndCtx
{
long
addr;
Instruction ins;
List
<Number> regs;
public
long
getAddr() {
return
addr;
}
public void setAddr(
long
addr) {
this.addr
=
addr;
}
public void setIns(Instruction ins) {
this.ins
=
ins;
}
public Instruction getIns() {
return
ins;
}
public void setRegs(
List
<Number> regs) {
this.regs
=
regs;
}
public
List
<Number> getRegs() {
return
regs;
}
}
/
/
patch类
class
PatchIns{
long
addr;
/
/
patch 地址
String ins;
/
/
patch的指令
public
long
getAddr() {
return
addr;
}
public void setAddr(
long
addr) {
this.addr
=
addr;
}
public String getIns() {
return
ins;
}
public void setIns(String ins) {
this.ins
=
ins;
}
}
/
/
指令栈
private Stack<InsAndCtx> instructions;
/
/
所有需要patch的指令
private
List
<PatchIns> patchs;
/
/
保存指令寄存器环境
public
List
<Number> saveRegs(Backend bk)
{
List
<Number> nb
=
new ArrayList<>();
for
(
int
i
=
0
;i<
29
;i
+
+
)
{
nb.add(bk.reg_read(i
+
Arm64Const.UC_ARM64_REG_X0));
}
nb.add(bk.reg_read(Arm64Const.UC_ARM64_REG_FP));
nb.add(bk.reg_read(Arm64Const.UC_ARM64_REG_LR));
return
nb;
}
/
/
指令hook,每条指令执行前保存环境
public void processBr()
{
emulator.getBackend().hook_add_new(new CodeHook() {
@Override
public void hook(Backend backend,
long
address,
int
size,
Object
user) {
Capstone capstone
=
new Capstone(Capstone.CS_ARCH_ARM64,Capstone.CS_MODE_ARM);
byte[] bytes
=
emulator.getBackend().mem_read(address,
4
);
Instruction[] disasm
=
capstone.disasm(bytes,
0
);
InsAndCtx iac
=
new InsAndCtx();
iac.setIns(disasm[
0
]);
iac.setRegs(saveRegs(backend));
iac.setAddr(address);
instructions.push(iac);
do_processbr();
}
@Override
public void onAttach(UnHook unHook) {
System.out.println(
"attach"
);
}
@Override
public void detach() {
System.out.println(
"detach"
);
}
},module.base
+
start, module.base
+
end,null);
}
/
/
指令栈回溯,根据处理结果,生成patchIns,供最后统一patch
public void do_processbr()
{
Instruction ins
=
instructions.peek().getIns();
if
(ins.getMnemonic().equals(
"br"
) && ins.getOpStr().equals(
"x9"
))
{
boolean finish
=
false;
long
base
=
-
1
;
long
listoffset
=
-
1
;
long
cond1
=
-
1
;
long
cond2
=
-
1
;
String cond
=
"";
long
addinstaddr
=
-
1
;
long
brinsaddr
=
instructions.peek().getAddr()
-
module.base;
long
selectaddr
=
-
1
;
long
ldaaddr
=
-
1
;
try
{
while
(!finish && !instructions.empty())
{
instructions.pop();
ins
=
instructions.peek().getIns();
if
(ins.getMnemonic().toLowerCase(Locale.ROOT).equals(
"add"
))
{
String[] split
=
ins.getOpStr().split(
","
);
if
(split.length
=
=
3
)
{
if
(split[
0
].toLowerCase(Locale.ROOT).trim().equals(
"x9"
) && split[
1
].toLowerCase(Locale.ROOT).trim().equals(
"x9"
))
{
String reg
=
split[
2
].trim().toLowerCase(Locale.ROOT);
base
=
getRegValue(reg,instructions.peek().getRegs()).longValue();
addinstaddr
=
instructions.peek().getAddr()
-
module.base;
}
else
{
break
;
}
}
else
{
break
;
}
}
if
(ins.getMnemonic().toLowerCase(Locale.ROOT).equals(
"ldr"
))
{
String[] sp
=
ins.getOpStr().toLowerCase().split(
","
);
if
(sp.length
=
=
3
)
{
if
(sp[
0
].trim().toLowerCase(Locale.ROOT).equals(
"x9"
) && sp[
2
].trim().toLowerCase(Locale.ROOT).equals(
"x9]"
))
{
String reg
=
sp[
1
].toLowerCase(Locale.ROOT).trim().substring(
1
);
listoffset
=
getRegValue(reg,instructions.peek().getRegs()).longValue()
-
module.base;
ldaaddr
=
instructions.peek().getAddr()
-
module.base;
}
}
}
if
(ins.getMnemonic().trim().toLowerCase(Locale.ROOT).equals(
"csel"
))
{
String[] sp
=
ins.getOpStr().toLowerCase(Locale.ROOT).split(
","
);
if
(sp.length
=
=
4
)
{
cond
=
sp[
3
].trim();
if
(sp[
0
].trim().equals(
"x9"
))
{
String reg1
=
sp[
1
].trim();
String reg2
=
sp[
2
].trim();
cond1
=
getRegValue(reg1,instructions.peek().getRegs()).longValue();
cond2
=
getRegValue(reg2,instructions.peek().getRegs()).longValue();
selectaddr
=
instructions.peek().getAddr()
-
module.base;
}
}
}
if
(ins.getMnemonic().trim().toLowerCase(Locale.ROOT).equals(
"cmp"
))
{
if
(base
=
=
-
1
|| listoffset
=
=
-
1
|| cond1
=
=
-
1
|| cond2
=
=
-
1
|| cond.equals("") || addinstaddr
=
=
-
1
|| ldaaddr
=
=
-
1
|| selectaddr
=
=
-
1
)
{
break
;
}
else
{
long
offset1
=
base
+
readInt64(emulator.getBackend(), module.base
+
listoffset
+
cond1)
-
module.base;
long
offset2
=
base
+
readInt64(emulator.getBackend(),module.base
+
listoffset
+
cond2)
-
module.base;
if
( brinsaddr
-
addinstaddr !
=
4
)
{
System.out.println(
"add ins and br ins gap more than 4 size,may make mistake"
);
}
String condBr
=
"b"
+
cond.toLowerCase(Locale.ROOT)
+
" 0x"
+
Integer.toHexString((
int
) (offset1
-
addinstaddr));
String br
=
"b 0x"
+
Integer.toHexString((
int
)(offset2
-
brinsaddr));
PatchIns pi1
=
new PatchIns();
pi1.setAddr(addinstaddr);
pi1.setIns(condBr);
patchs.add(pi1);
PatchIns pi2
=
new PatchIns();
pi2.setAddr(brinsaddr);
pi2.setIns(br);
patchs.add(pi2);
PatchIns pi3
=
new PatchIns();
pi3.setAddr(selectaddr);
pi3.setIns(
"nop"
);
patchs.add(pi3);
PatchIns pi4
=
new PatchIns();
pi4.setAddr(ldaaddr);
pi4.setIns(
"nop"
);
patchs.add(pi4);
finish
=
true;
}
}
}
}catch (Exception e)
{
e.printStackTrace();
}
}
}
/
/
遍历patch表,执行patch,生成新的so,使用Ketstone将汇编转为机器码。
public void patch()
{
try
{
File
f
=
new
File
(inName);
FileInputStream fis
=
new FileInputStream(f);
byte[] data
=
new byte[(
int
) f.length()];
fis.read(data);
fis.close();
for
(PatchIns pi:patchs)
{
System.out.println(
"procrss addr:"
+
Integer.toHexString((
int
) pi.addr)
+
",code:"
+
pi.getIns());
Keystone ks
=
new Keystone(KeystoneArchitecture.Arm64, KeystoneMode.LittleEndian);
KeystoneEncoded assemble
=
ks.assemble(pi.getIns());
for
(
int
i
=
0
;i<assemble.getMachineCode().length;i
+
+
)
{
data[(
int
) pi.addr
+
i]
=
assemble.getMachineCode()[i];
}
}
File
fo
=
new
File
(outName);
FileOutputStream fos
=
new FileOutputStream(fo);
fos.write(data);
fos.flush();
fos.close();
System.out.println(
"finish"
);
}
catch (Exception e)
{
e.printStackTrace();
}
}
|
patch完成后,再次使用ida打开原so,发现Jni_onLoad函数已经可以F5了:

但是依然有一些jumpout。
原因是因为在模拟执行的是后并没有走遍所有的分支,我们只是将走过的分支处理了。
接下来需要在jumpout的地方手动修改寄存器的值,来控制他的走势,让unidbg最终走完所有分支。
比如对于这一处br,在blt时才会跳转过去,

可以看到这一处的跳转和w12有关,我们找到给w8赋值为w12的地方,通过修改寄存器来给其赋值:


重新跑一边代码,这一处的br x9 就修复了。将没有走到的分支处理完后,F5结果如下:

可以看到是标准的ollvm的控制流平坦化。
所以br x9的混淆其实是在ollvm控制流平坦化的基础上,将所有的跳转地址都加了一步运算。
3.去除控制流平坦化
间接跳转去除完后,需要去除控制流平坦化。根据控制流平坦化的工作原理,原来的代码会被打碎成代码片段,然后装进一个大的switch case里,最外层包一个while true循环,根据索引变量来按照原来的顺序执行代码。
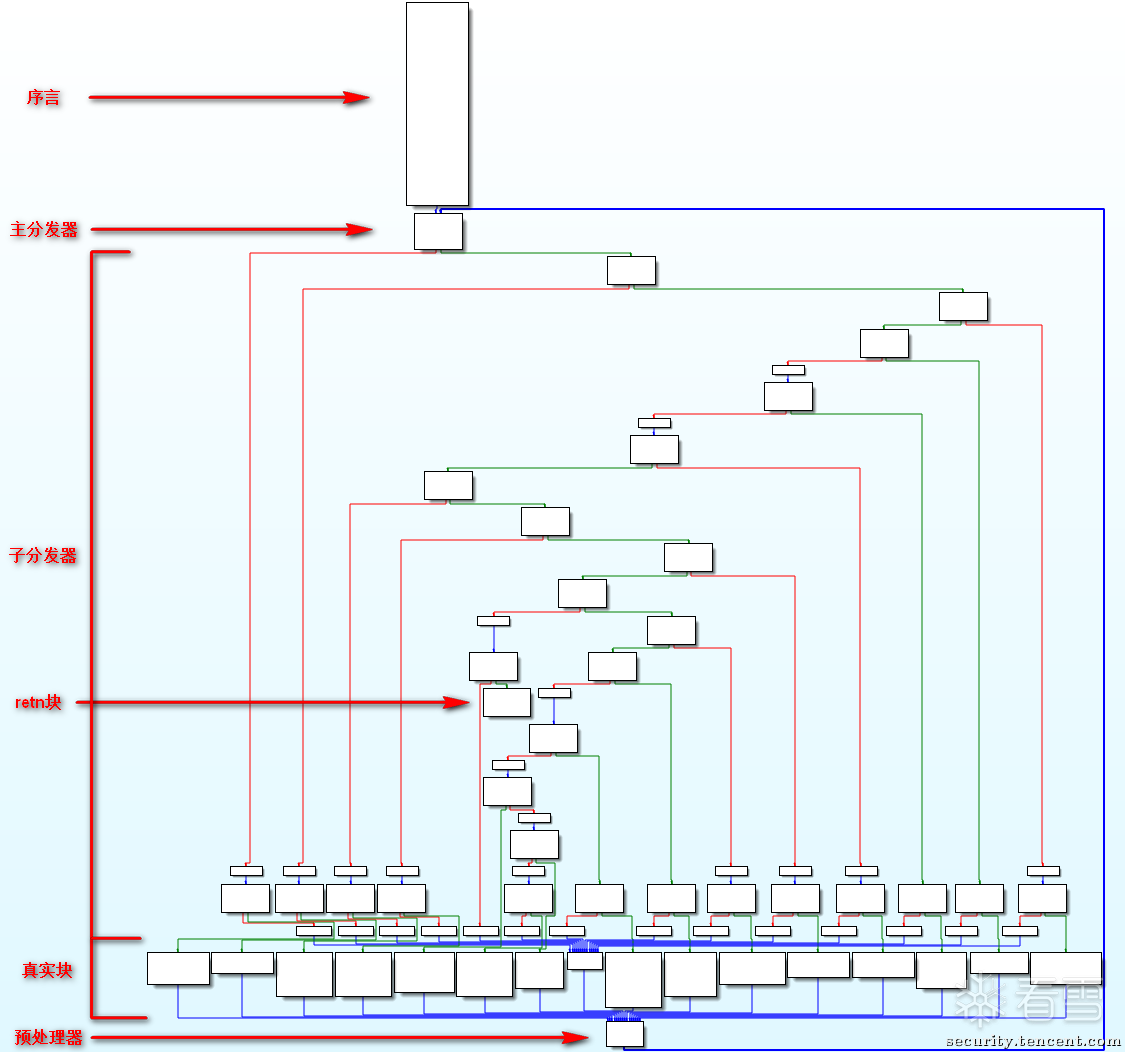
考虑到编译的结果要在逻辑上和原来的代码完全一致,所以一个重要的结论是——真实的代码块一定在cmp eq 之后。(switch case 的一个case)
控制流平坦化对于顺序执行的处理比较简单,直接在前一个真实块的末尾,将索引值改为下一个真实块的索引,然后跳转到主分发器即可。
对于分支执行(判断,循环),在条件的部分会有一个条件选择指令CSEl,将索引寄存器的值根据条件结果设置为不同的索引,然后跳转到主分发器。
所以我们可以按照以下算法对控制流平坦化进行还原:
1.建立一个指令栈,每条指令执行前,保留该指令的地址,指令内容,当前所有寄存器的值。然后将当前指令的信息push进指令栈。
2.对指令进行回溯,如果栈顶指令是b.eq,则进行3(收集真实块),如果栈顶指令是直接跳转指令b,则进行5(处理分支块),否则继续执行下一条指令。
3.向上回溯指令栈,找到第一条cmp 指令,判断是否为与索引寄存器w8 比较,如果是,则进行4,否则继续执行下一条指令。
4.获取与w8比较的另一个寄存器的值,获取b.eq的目标地址,组成一个(索引,真实块)对。继续执行下一条指令。
5.判断上一条指令是否为CSEL W8。如果是,则记录一个(条件成立块索引,条件不成立块索引)对。否则,继续执行下一条指令。
同时,我们在主分发器处hook 指令,记录每次经过主分发器时的索引寄存器的值为索引值顺序。
在模拟执行收集完成信息之后,做以下处理:
1.去除索引值顺序中为条件块的索引。
2.获取索引值顺序中的第一个值,找到对应的真实块。将主分发器处patch为跳转向第一个真实块的跳转指令。
3.根据真实块结束时的新的索引值,寻找到对应的真实块,将结尾处patch为跳转到下一个真实块。
4.在CSEL指令处,根据条件成立块索引和条件不成立索引找到对应的真实块。将CSEL指令和后面的跳转向主分发器的指令patch为两条指令:
第一条为条件成立时的条件跳转,第二条为条件不成立时的直接跳转。
对应的代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
|
/
/
用于记录条件块中,条件成立,条件不成立时对应的索引值,同时记录条件。
class
selectBr
{
long
insaddr;
long
trueindex;
long
falseindex;
String cond;
public String getCond() {
return
cond;
}
public void setCond(String cond) {
this.cond
=
cond;
}
public
long
getInsaddr() {
return
insaddr;
}
public void setInsaddr(
long
insaddr) {
this.insaddr
=
insaddr;
}
public
long
getTrueindex() {
return
trueindex;
}
public void setTrueindex(
long
trueindex) {
this.trueindex
=
trueindex;
}
public
long
getFalseindex() {
return
falseindex;
}
public void setFalseindex(
long
falseindex) {
this.falseindex
=
falseindex;
}
}
/
/
真实块,索引值和开始地址
class
TrueBlock{
long
index;
long
startAddr;
public TrueBlock(){}
public TrueBlock(
long
l,
long
s)
{
index
=
l;
startAddr
=
s;
}
public
long
getIndex() {
return
index;
}
public void setIndex(
long
index) {
this.index
=
index;
}
public
long
getStartAddr() {
return
startAddr;
}
public void setStartAddr(
long
startAddr) {
this.startAddr
=
startAddr;
}
}
/
/
记录真实块
private
List
<TrueBlock>tbs;
/
/
记录条件块
private
List
<selectBr> sbs ;
/
/
记录索引顺序
private
List
<
Long
> indexOrder;
public void processFlt()
{
emulator.getBackend().hook_add_new(new CodeHook() {
@Override
public void hook(Backend backend,
long
address,
int
size,
Object
user) {
Capstone capstone
=
new Capstone(Capstone.CS_ARCH_ARM64,Capstone.CS_MODE_ARM);
byte[] bytes
=
emulator.getBackend().mem_read(address,
4
);
Instruction[] disasm
=
capstone.disasm(bytes,
0
);
InsAndCtx iac
=
new InsAndCtx();
iac.setIns(disasm[
0
]);
iac.setRegs(saveRegs(backend));
iac.setAddr(address);
instructions.add(iac);
do_processflt();
}
@Override
public void onAttach(UnHook unHook) {
System.out.println(
"attach"
);
}
@Override
public void detach() {
System.out.println(
"detach"
);
}
},module.base
+
start, module.base
+
end, null);
}
public void do_processflt()
{
if
(instructions.empty())
{
return
;
}
Instruction ins
=
instructions.peek().getIns();
if
(instructions.peek().getAddr()
-
module.base
=
=
dispatcher)
{
indexOrder.add(getRegValue(
"x8"
,instructions.peek().getRegs()).longValue());
}
if
(ins.getMnemonic().toLowerCase(Locale.ROOT).equals(
"b.eq"
)) {
InsAndCtx beq
=
instructions.peek();
/
/
等于跳转,检查是否为
cmp
x8,
while
(true)
{
if
(instructions.empty())
{
break
;
}
instructions.pop();
ins
=
instructions.peek().getIns();
if
(ins.getMnemonic().toLowerCase(Locale.ROOT).equals(
"cmp"
))
{
String[] sp
=
ins.getOpStr().toLowerCase(Locale.ROOT).split(
","
);
if
(sp[
0
].equals(
"w8"
))
{
/
/
找到一个真实块
TrueBlock tb
=
new TrueBlock();
long
regValue
=
getRegValue(sp[
1
].trim(), instructions.peek().getRegs()).longValue();
long
targetAddr
=
0
;
String offset
=
beq.getIns().getOpStr().toLowerCase(Locale.ROOT);
long
offsetvalue
=
getLongFromOpConst(offset);
targetAddr
=
beq.getAddr()
+
offsetvalue
-
module.base;
tb.setIndex(regValue);
tb.setStartAddr(targetAddr);
tbs.add(tb);
break
;
}
}
}
}
/
/
处理分支块
if
(ins.getMnemonic().toLowerCase(Locale.ROOT).equals(
"b"
))
{
long
offset
=
getLongFromOpConst(ins.getOpStr());
if
(offset !
=
0
)
{
long
target
=
offset
+
instructions.peek().getAddr()
-
module.base;
/
/
直接跳向主发生器
if
(target
=
=
dispatcher)
{
instructions.pop();
ins
=
instructions.peek().getIns();
if
(ins.getMnemonic().toLowerCase(Locale.ROOT).equals(
"csel"
))
{
String[] sp
=
ins.getOpStr().toLowerCase(Locale.ROOT).split(
","
);
if
(sp[
0
].trim().equals(
"w8"
))
{
String cond
=
sp[
3
].trim();
String reg1
=
sp[
1
].trim();
String reg2
=
sp[
2
].trim();
selectBr sb
=
new selectBr();
sb.setInsaddr(instructions.peek().getAddr()
-
module.base);
sb.setCond(cond);
sb.setTrueindex(getRegValue(reg1,instructions.peek().getRegs()).longValue());
sb.setFalseindex(getRegValue(reg2,instructions.peek().getRegs()).longValue());
sbs.add(sb);
}
}
}
}
}
}
|
在模拟执行完后,发现有一些索引值没有找到对应的块:
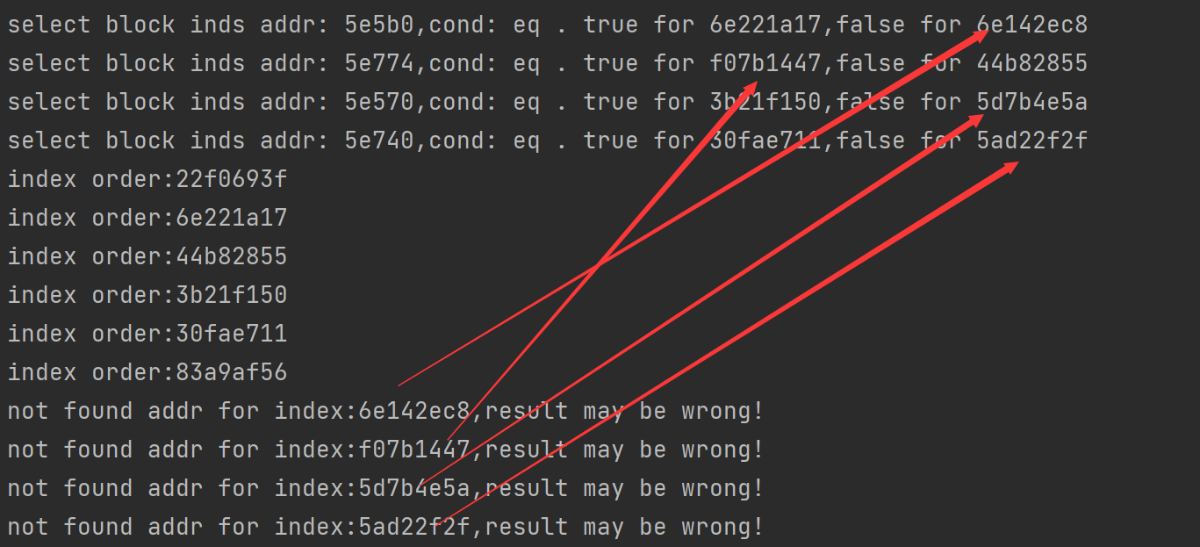
查看他们的索引,发现刚好是条件块中的索引。这个也好理解,因为在模拟执行的时候我们只走了条件的一个分支,没有走另一个分支,所以就没有记录下对应的真实块。这里我们手动根据b.eq和寄存器的值,添加对应的真实块:
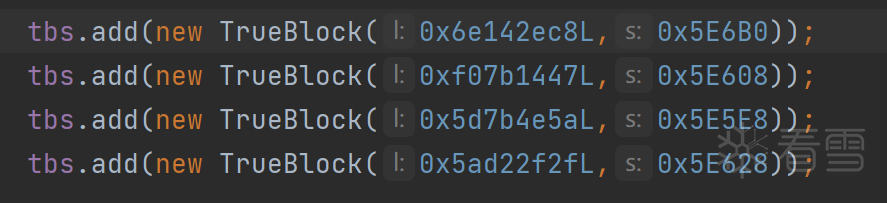
添加完成后,再次运行程序,发现已经patch成功了。打开ida查看Jni_onload:
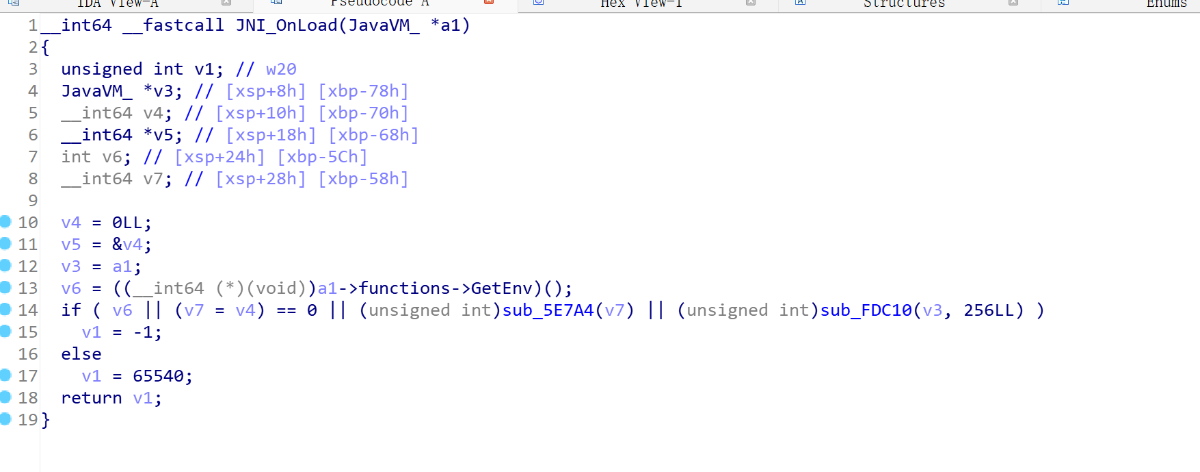
发现函数已经被完美的还原了。
4.总结
借着五一假期简单研究了一下模拟执行和去混淆,感慨unidbg是真的强。我认为我使用的方法应该是没有任何逻辑漏洞,可以完全等效的还原的。
间接跳转的还原比较简单,控制流平坦化的还原则比较难。
控制流平坦化还原的最大难点在与找到真实块与索引之间的关系。由于我这次使用的样本对于跳转做了混淆,虽然难住了ida,但是也可能难住了编译器,导致对控制流平坦化部分没有做复杂的编译优化——所有的真实块都在b.eq后面,并且只有一个主分发器,没有次分发器。同时真实块执行结束都很乖巧的跳转到了分发器(有的编译优化会直接将两个真实块连在一起)。
总体来说,本次反混淆不是特别完美,有手工的部分,同时也不能通杀所有混淆,只能说提供一种反混淆思路和经验吧。
ollvm反混淆感觉是永无止境的,目前还没有见到有什么非常强大,通杀,可以完美还原的方案,只能针对目标混淆器定制反混淆策略。
安全攻防不息,吾辈仍需努力!
更多【记一次基于unidbg模拟执行的去除ollvm混淆】相关视频教程:www.yxfzedu.com
相关文章推荐
- 软件逆向-Wibu Codemeter 7.3学习笔记——AxProtector壳初探 - Android安全 CTF对抗 IOS安全
- 企业安全-学习Kubernetes笔记——暴露站点服务(Ingress) - Android安全 CTF对抗 IOS安全
- 企业安全-学习Kubernetes笔记——部署数据库站点(MySql) - Android安全 CTF对抗 IOS安全
- 企业安全-学习Kubernetes笔记——部署web站点环境(PHP+Nginx) - Android安全 CTF对抗 IOS安全
- 企业安全-学习Kubernetes笔记——安装NFS驱动 - Android安全 CTF对抗 IOS安全
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全 CTF对抗 IOS安全
- 软件逆向-wibu软授权(四) - Android安全 CTF对抗 IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全 CTF对抗 IOS安全
- 2-wibu软授权(三) - Android安全 CTF对抗 IOS安全
- 软件逆向-wibu软授权(二) - Android安全 CTF对抗 IOS安全
- 软件逆向-wibu软授权(一) - Android安全 CTF对抗 IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全 CTF对抗 IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全 CTF对抗 IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全 CTF对抗 IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全 CTF对抗 IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全 CTF对抗 IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全 CTF对抗 IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全 CTF对抗 IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全 CTF对抗 IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全 CTF对抗 IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- ddos-DDoS攻击剧增,深入解析抗DDoS防护方案
- spring boot-AI 辅助学习:Spring Boot 集成 PostgreSQL 并设置最大连接数
- golang-go中的rune类型
- python-深度学习之基于Python+OpenCV(DNN)性别和年龄识别系统
- 运维-Linux-Docker的基础命令和部署code-server
- 算法-421. 数组中两个数的最大异或值/字典树【leetcode】
- 编程技术-解非线性方程python实现黄金分割法
- 学习-Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks - 翻译学习
- python-第三章:人工智能深度学习教程-基础神经网络(第四节-从头开始的具有前向和反向传播的深度神经网络 – Python)
- css-数据结构与算法 | 第四章:字符串

接各种驱动定制如:游戏读写驱动,软件内存保护,防止调试等功能定制。
出租读写驱动,调试驱动,无痕注入支持各种游戏。
邮箱:service@yxfzedu.com
QQ:851920120
特别说明:不接游戏数据分析,外挂编写,登陆协议等类似业务。