CTF对抗-STL容器逆向与实战(N1CTF2022 cppmaster wp)
推荐 原创0x1 序言
在之前的CTF中常常出现了对STL容器的逆向,而在网上的资料中并没有搜到详细的STL容器逆向的经验和文章,这里配合编译器一起来看看常见的STL容器的内存模型,最后根据最近N1CTF比赛中cppmaster来进行实战。
STL存在非常多种类的容器,但是多个容器之间的底层实现其实是类似的,例如set和map都采用的是rb_tree这个结构,因此我们从这种底层实现的数据结构来对STL容器分类,这里将要分析的容器分为分析四类:rb_tree,deque,hashtable,vector,顺带分析一下string的结构。
当然可能还存在许许多多的STL容器,但是大体的分析思路是类似的。这里采用LLVM辅助我们分析容器的内存结构。
0x2 Dump
对于一个Class而言,在LLVM IR种对应的为StructType,可以使用API访问其下的子Type,因此可以随便简单写个pass来dump出ir种的类的内存模型,从而辅助我们逆向分析各个容器的内存表示和实现。具体代码如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
|
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/IR/CFG.h"
#include "llvm/IR/Type.h"
#include "llvm/ADT/SmallSet.h"
#include "llvm/ADT/SmallVector.h"
#include "llvm/IR/BasicBlock.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/Transforms/Utils/Cloning.h"
#include "llvm/Transforms/IPO/PassManagerBuilder.h"
#include<algorithm>
#include<string>
using namespace llvm;
namespace
{
struct DumpClass : public FunctionPass
{
static char
ID
;
DumpClass() : FunctionPass(
ID
) {}
std::string getTypeName(
Type
*
type
, DataLayout
*
data);
void dumpType(
int
depth,
Type
*
type
,
int
index, DataLayout
*
data);
bool
runOnFunction(Function &F) override
{
if
(F.getName().compare(
"main"
))
return
false;
std::
set
<StructType
*
> types;
const DataLayout
*
data
=
&F.getParent()
-
>getDataLayout();
for
(Function::iterator B
=
F.begin(); B !
=
F.end(); B
+
+
)
{
for
(BasicBlock::iterator I
=
B
-
>getFirstInsertionPt(); I !
=
B
-
>end(); I
+
+
)
{
Instruction
*
instr
=
&
*
I;
if
(isa<AllocaInst>(
*
instr))
{
AllocaInst
*
a
=
(AllocaInst
*
)instr;
Type
*
type
=
a
-
>getAllocatedType();
if
(
type
-
>isStructTy())
{
StructType
*
s
=
(StructType
*
)
type
;
if
(s
-
>isOpaque())
continue
;
types.insert(s);
}
}
}
}
for
(StructType
*
type
:types)
{
errs()<<
"\n\nstart dumping type: "
+
type
-
>getStructName()
+
"\n"
;
dumpType(
0
,
type
,
0
, (DataLayout
*
)data);
}
return
false;
}
};
}
std::string DumpClass::getTypeName(
Type
*
type
, DataLayout
*
data)
{
if
(
type
-
>isIntegerTy())
{
IntegerType
*
i
=
(IntegerType
*
)
type
;
return
"uint"
+
std::to_string(i
-
>getBitWidth())
+
"_t"
;
}
else
if
(
type
-
>isPointerTy())
{
PointerType
*
ptrType
=
(PointerType
*
)
type
;
return
getTypeName(ptrType
-
>getPointerElementType(), data)
+
"*"
;
}
else
if
(
type
-
>isArrayTy())
{
ArrayType
*
arrType
=
(ArrayType
*
)
type
;
return
getTypeName(arrType
-
>getArrayElementType(), data)
+
"["
+
std::to_string(arrType
-
>getArrayNumElements())
+
"]"
;
}
else
if
(
type
-
>isFloatTy())
{
return
"float"
;
}
else
if
(
type
-
>isStructTy())
{
StructType
*
s
=
(StructType
*
)
type
;
return
s
-
>getStructName();
}
else
{
return
"unknown_"
+
std::to_string(data
-
>getTypeAllocSizeInBits(
type
));
}
}
void DumpClass::dumpType(
int
depth,
Type
*
type
,
int
index, DataLayout
*
data)
{
std::string blank
=
"";
for
(
int
i
=
0
; i < depth; i
+
+
)
blank
+
=
"\t"
;
if
(
type
-
>isStructTy())
{
StructType
*
s
=
(StructType
*
)
type
;
errs() << blank
+
s
-
>getStructName()
+
" {\n"
;
for
(
int
i
=
0
; i < s
-
>getStructNumElements(); i
+
+
)
{
Type
*
subType
=
s
-
>getStructElementType(i);
dumpType(depth
+
1
, subType, i, data);
}
/
/
errs() << blank
+
"} field_"
+
std::to_string(index)
+
";\n"
;
}
else
{
errs() << blank
+
getTypeName(
type
, data)
+
" field_"
+
std::to_string(index)
+
";\n"
;
}
}
char DumpClass::
ID
=
0
;
static RegisterPass<DumpClass> X(
"dump"
,
"DumpClass"
);
/
/
Register
for
clang
static RegisterStandardPasses Y(PassManagerBuilder::EP_EarlyAsPossible,
[](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) {
PM.add(new DumpClass());
});
|
0x3 deque
deque是queue,stack,deque等线性容器的底层实现,通过dump工具可以dump出具体的内存结构如下。不难发现在deque中,主要分为三个部分,第一个用于描述map的,其中包含map大小和map的指针,第二个则是指向deque中起始元素的Deque_iterator,第三个则是指向了deque中结束元素的Deque_iterator。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
class
.std::deque<string> {
class
.std::_Deque_base {
struct.std::_Deque_base<std::__cxx11::basic_string<char>, std::allocator<std::__cxx11::basic_string<char> > >::_Deque_impl {
struct.std::_Deque_base<std::__cxx11::basic_string<char>, std::allocator<std::__cxx11::basic_string<char> > >::_Deque_impl_data {
class
.std::__cxx11::basic_string
*
*
map
;
uint64_t map_size;
struct.std::_Deque_iterator {
class
.std::__cxx11::basic_string
*
cur;
class
.std::__cxx11::basic_string
*
first;
class
.std::__cxx11::basic_string
*
last;
class
.std::__cxx11::basic_string
*
*
map
;
} start;
struct.std::_Deque_iterator {
class
.std::__cxx11::basic_string
*
cur;
class
.std::__cxx11::basic_string
*
first;
class
.std::__cxx11::basic_string
*
last;
class
.std::__cxx11::basic_string
*
*
map
;
} finish;
} field_0;
} field_0;
} field_0;
} field_0;
|
这里需要注意的是:deque对元素的保存采取了分块保存的机制。deque采用一块连续的内存保存了一系列的指针。其中map即指向这一块连续的内存,换句话说map是一个指针,指向一个指针数组。而这个指针数组中的指针指向的则是一篇连续的,用于实际保存数据的内存区域,我们称为data array(每个元素的大小取决于deque中的模板类型),具体的内存示意图可以如下图所示。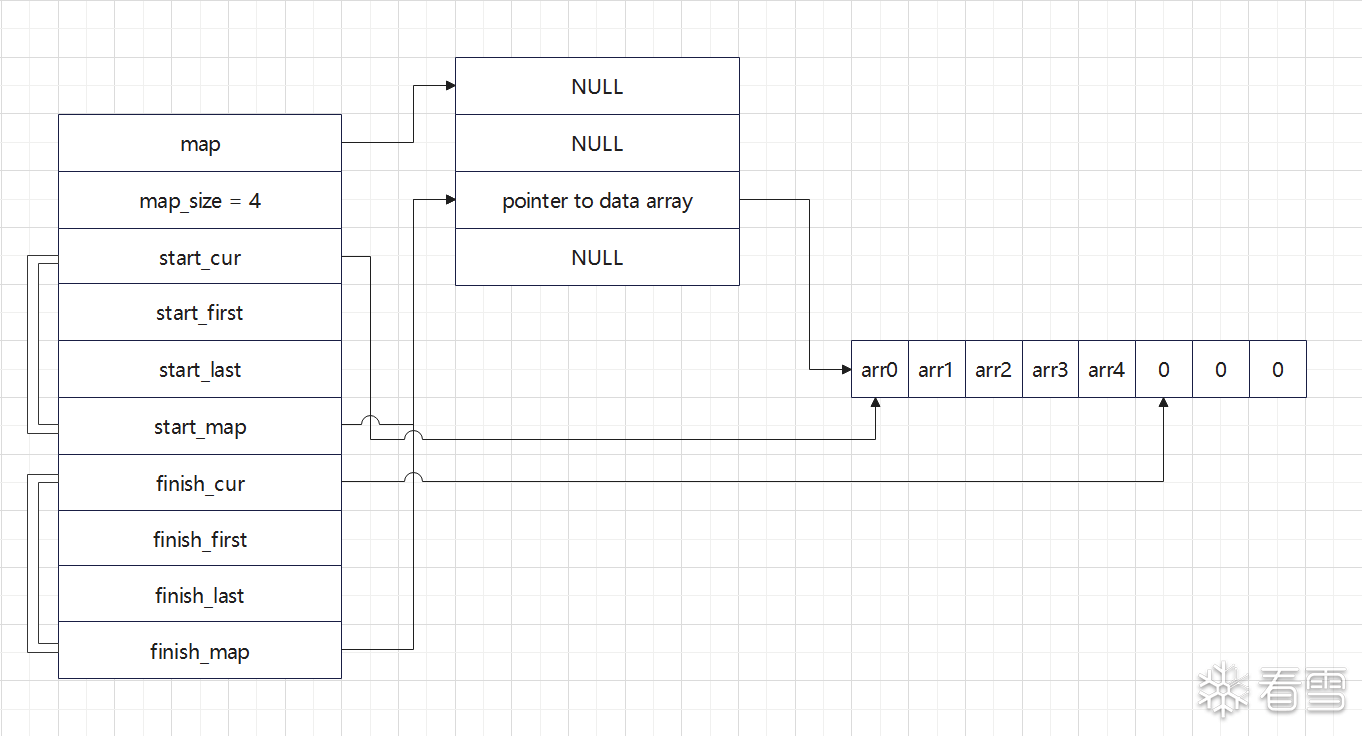
而iterator的结构需要关注的是cur,他将直接指向数据数组中具体的元素,还有就是iterator下的map指针,这个元素则代表当前iterator指向的元素所在区块对应map中地址,last和first则指向data array的起始和结束。因此可以得知start和finish的map并不一定是相同的(即start迭代器指向元素不一定和finish迭代器指向元素处在同一个data array中),所以iterator在进行迭代的时候是需要根据map跳跃到不同的data array中。
0x4 vector
vector作为常见又方便的stl容器,其实现并不复杂,比上述的deque要简单得多。vector仅仅由三个指针构成:start,finish,end_of_storage。start用于指向数组的第一个元素,而finish指向结束的位置,即最后一个元素后面。而end_of_storage指向当前为vector分配的堆空间的结束地址。
|
1
2
3
4
5
6
7
8
9
10
11
|
class
.std::vector<string> {
struct.std::_Vector_base {
struct.std::_Vector_base<std::__cxx11::basic_string<char>, std::allocator<std::__cxx11::basic_string<char> > >::_Vector_impl {
struct.std::_Vector_base<std::__cxx11::basic_string<char>, std::allocator<std::__cxx11::basic_string<char> > >::_Vector_impl_data {
class
.std::__cxx11::basic_string
*
start;
class
.std::__cxx11::basic_string
*
finish;
class
.std::__cxx11::basic_string
*
end_of_storage;
} field_0;
} field_0;
} field_0;
} field_0;
|
为什么需要有一个end_of_storage呢,vector是一个动态的容器,他会根据元素数目分配固定内存,但是当有新的元素加入时,如果分配的固定内存不足以存放新的元素的话,则会进行扩容。因此,这个指针则用于对vector需要扩容时使用(需要注意的是元素的大小取决于模板类型type的大小,因此存在(finish-start)%sizeof(type)==0)。具体的内存示意图可以如下图所示。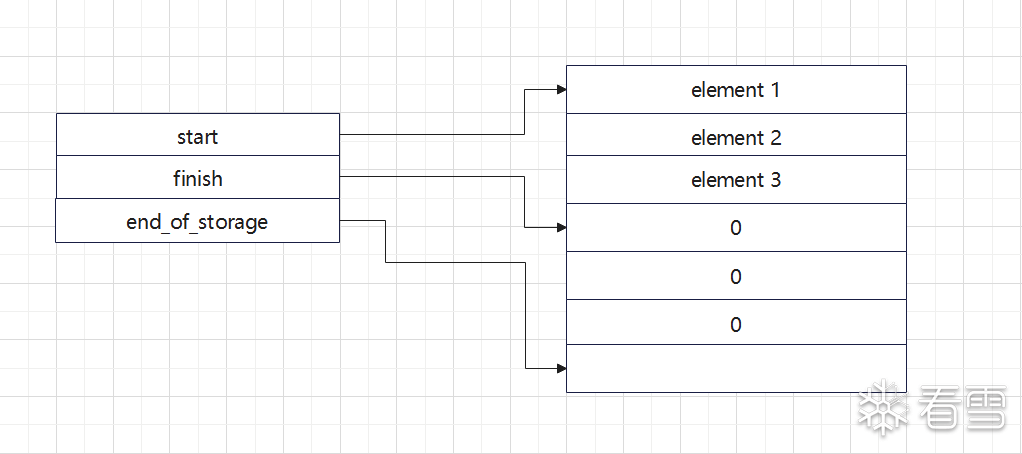
0x5 rb_tree
rb_tree即红黑树,具体的定义可以去网上翻阅资料,这里并不讨论其具体的实现和算法,仅仅讨论其数据结构在内存中的表示。rb_tree分为两个部分,一个适用于比较的key_compare,另一个则是header。重点分析header,header中存在一个node,和node_count。node即这个红黑树的起始节点,而node_count则代表这颗红黑树拥有多少的节点。node中描述了当前节点的颜色,父亲节点,左儿子和右儿子节点。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class
.std::
map
<string,string> {
class
.std::_Rb_tree.
6
{
struct.std::_Rb_tree<std::__cxx11::basic_string<char>, std::pair<const std::__cxx11::basic_string<char>, std::__cxx11::basic_string<char> >, std::_Select1st<std::pair<const std::__cxx11::basic_string<char>, std::__cxx11::basic_string<char> > >, std::less<std::__cxx11::basic_string<char> >, std::allocator<std::pair<const std::__cxx11::basic_string<char>, std::__cxx11::basic_string<char> > > >::_Rb_tree_impl {
struct.std::_Rb_tree_key_compare {
struct.std::less {
uint8_t value;
} key_compare;
} compare;
struct.std::_Rb_tree_header {
struct.std::_Rb_tree_node_base {
uint32_t color;
struct.std::_Rb_tree_node_base
*
parent;
struct.std::_Rb_tree_node_base
*
left;
struct.std::_Rb_tree_node_base
*
right;
} node;
uint64_t node_count;
} field_1;
} field_0;
} field_0;
} field_0;
|
这里需要注意的是,当红黑树中不存在节点时,header中node的parent是0,而left和right则指向node自身。当插入了结点之后,这个parent则会指向树的根节点,而left和right则指向红黑树的最左边的节点和最右边的节点。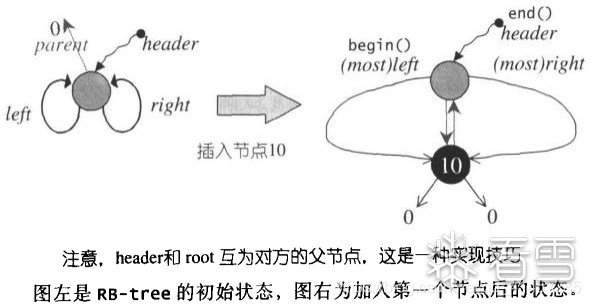
同时需要分清楚rb_tree变量本身和树本身。rb_tree变量中的node是不携带具体数据元素的,而树本身的节点在其node_base结构体结束后的内存区域则是数据元素。具体的内存示意图如下图所示。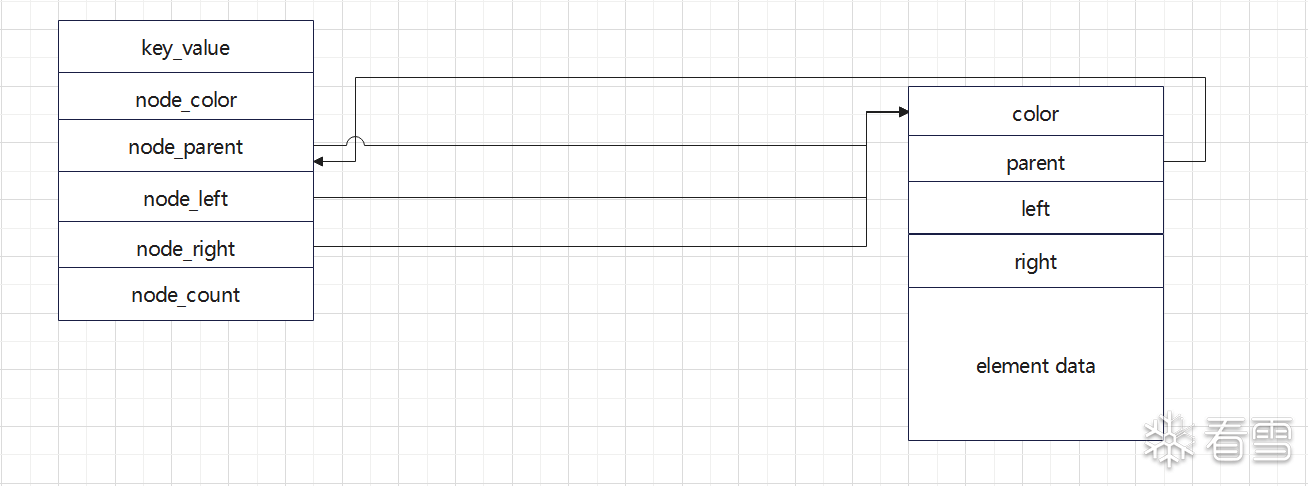
map和set的实现皆是基于rb_tree,而唯一不同之处在于set直接在node中存储数据,而map在node中存储的是键值对,是一个pair,而pair<a,b>在内存中的表示则是直接a后存放b。
0x6 hashtable
unordered_map和unordered_set的底层是由hashtable实现的。Prime_rehash_policy结构体适用于hashtable的rehash操作的不做分析,这里我们主要需要关注的是buckets,这个指针指向了一个_Hash_node_base*数组,如果指针为null则无效,这些指针数组中的指针指向的是一个链表,可以通过不断的访问next遍历链表中的所有node。bucket_count则表示buckets的大小,而element_count指的当前hashtable中所有的节点数目。默认的hashtable采用取模的方式找到对应的bucket,bucket_count一般为13。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
class
.std::unordered_map<
int
, string> {
class
.std::_Hashtable {
struct.std::__detail::_Hash_node_base
*
*
buckets;
uint64_t bucket_count;
struct.std::__detail::_Hash_node_base {
struct.std::__detail::_Hash_node_base
*
next
;
} field_2;
uint64_t element_count;
struct.std::__detail::_Prime_rehash_policy {
float
max_load_factor;
uint64_t next_resize;
} field_4;
struct.std::__detail::_Hash_node_base
*
field_5;
} field_0;
} field_0;
|
因此需要遍历一个hashtable只需要遍历其bucket找到有效的list,并遍历各个list就能找到所有的数据了,类似rb_tree,元素的数据存储与链表结构_Hash_node_base的后面。具体的内存模型如下图所示。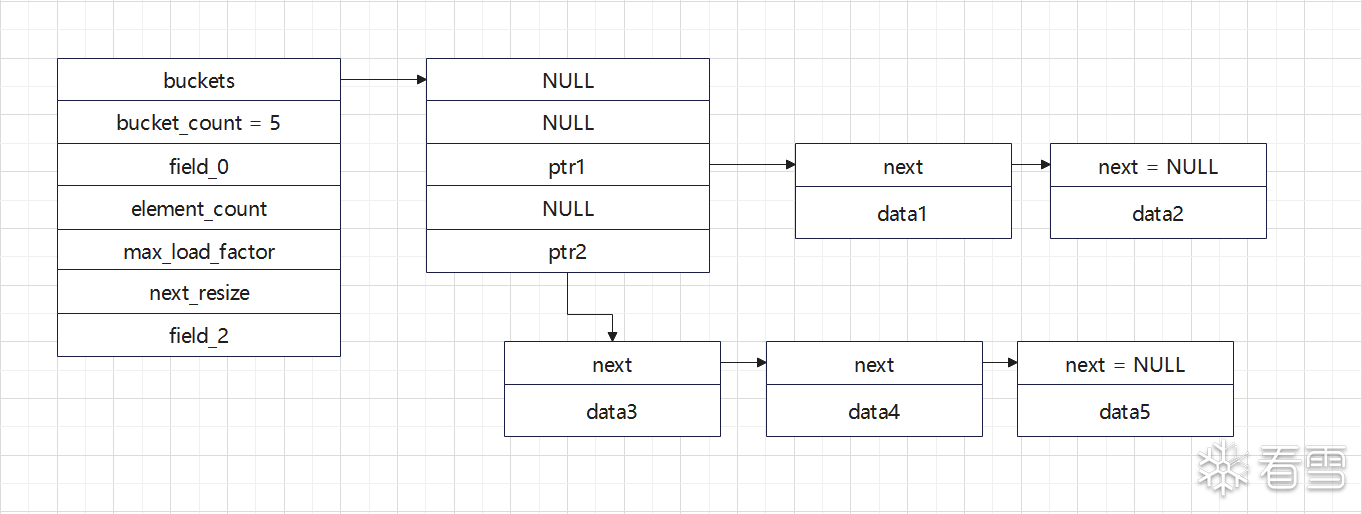
0x7 string
string的结构比较简单。主要由一个指针ptr和字符串长度string_length构成。除此之外还会存在一个联合体,当字符串的长度小于8时会直接存储与这个缓冲区中,此时ptr指针将指向这个local_buf,大于这个local_buf将会在堆上另外分配内存,此时这个union转而用于存储分配堆的大小。
|
1
2
3
4
5
6
7
8
9
10
|
class
.std::__cxx11::basic_string {
struct.std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> >::_Alloc_hider {
uint8_t
*
ptr;
} dataplus;
uint64_t string_length;
union.anon {
uint64_t allocated_capacity;
uint8_t local_buf[
8
];
};
} field_0;
|
这样设计的目的是方便字符串大小变化的适应,便于实现字符串拼接等工作,且小字符串不用在堆上分配,对速度有少量提升。具体的内存示意图如下图所示,左边的是长度小于8的string。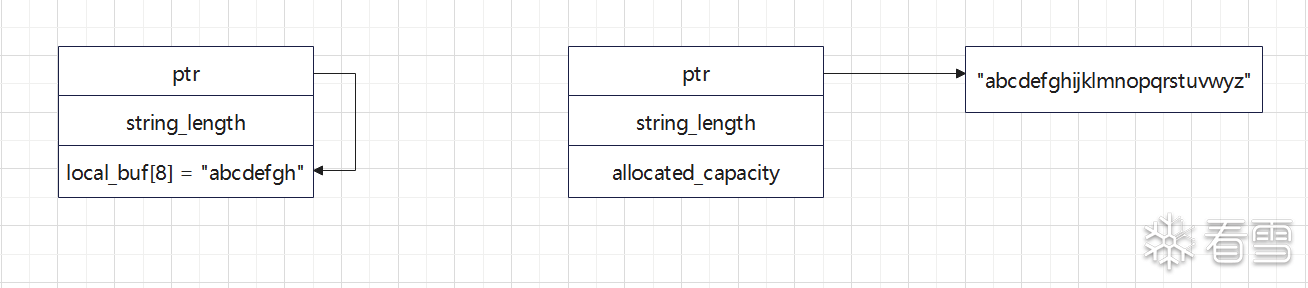
0x8 N1CTF2022 cppmaster
该题给与了一个ELF文件,并给出了hint.txt:Recursive stl containers ( > 3 ), Identify and traverse these containers
不难知道这个题目与STL容器密切相关,配合traverse不难猜测肯定是使用stl容器套容器的操作,先打开ida看看实现,找到main函数。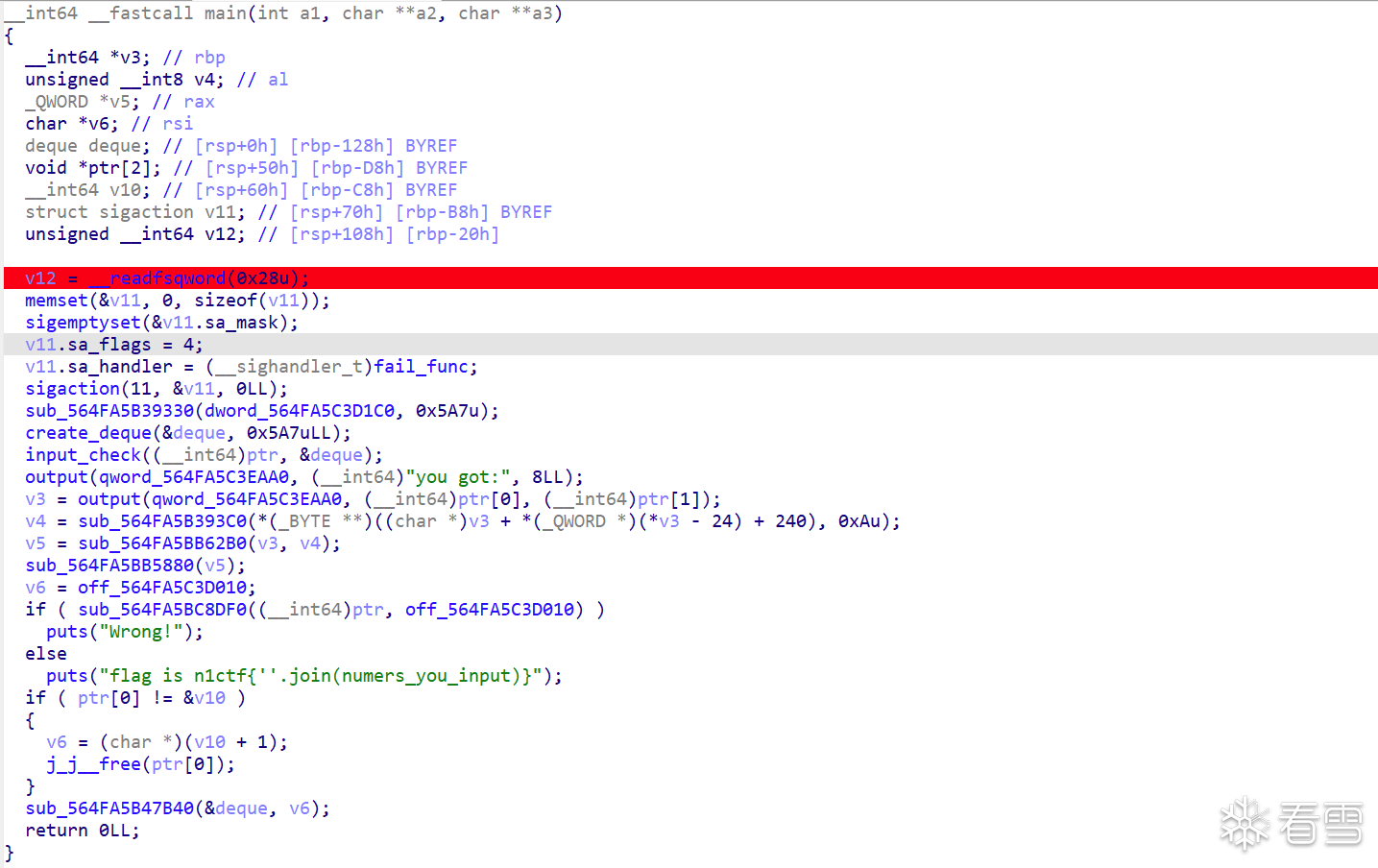
经过动调,可以定位到代码输入函数所在位置,在main中给他命名为input_check。而他上面的函数明显初始化了一个deque的数据结构,第一行对应map,第二行对应map_size,接下来是两个iterator,四个qword一组。
点开每个iterator的cur,也就是cur,可以看到其中存储了两个元素。
如果理解了上述的数据结构内存模型,很容易看出来其实是rb_tree,第一个qword是compare_key,第二个qword是color,第三个qword代表parent,第四个和第五个是left和right,第六个qword则代表node_count,因此其实就是deque<rb_tree<>>这种嵌套方式。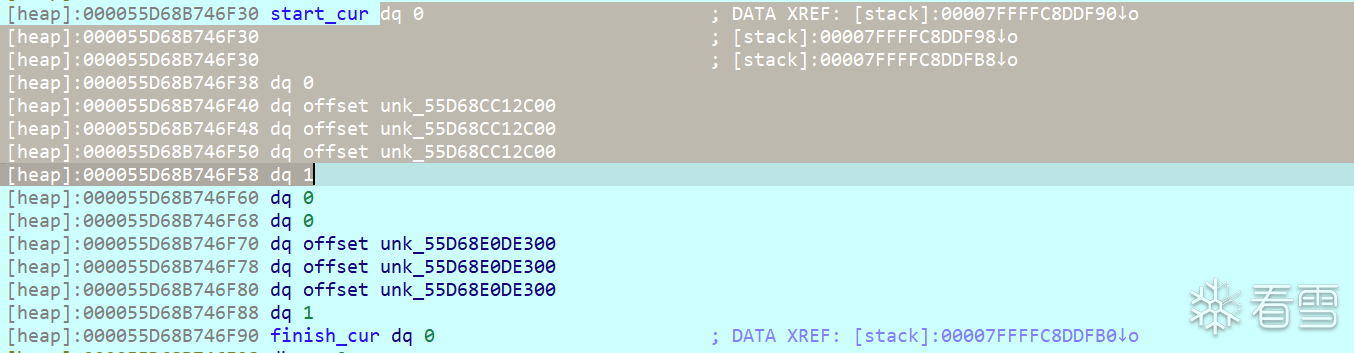
随意点开rb_tree中的一个node,分析一下rb_tree对应的模板类型,可以看到他存储的其实是std::pair<int,hashtable>,所以其实是deque<map<int,hashtable<>>>,为什么我会知道是int呢,因为后文分析输入流时输入的都是数字,并通过数字从容器中访问内部数据。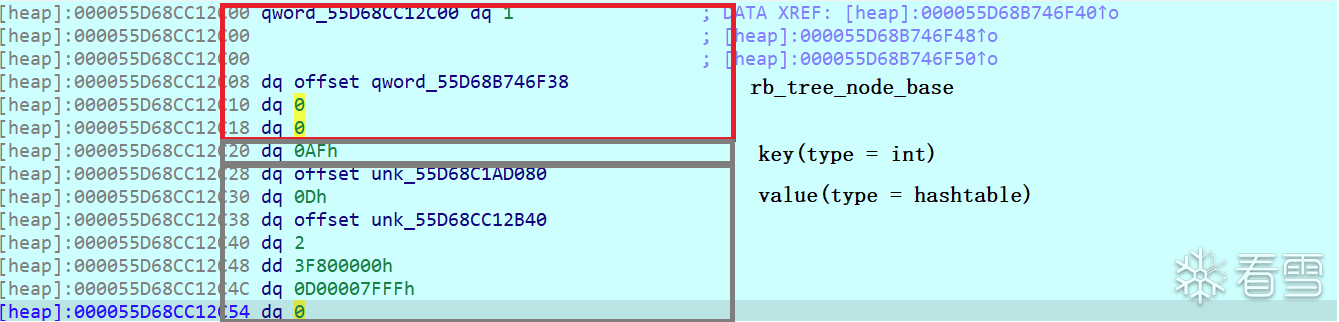
继续查看一下hash_table的buckets。
随意点开一个bucket,里面存储的是个链表,链表节点数据中存储的也是一个std::pair<int,deque>,因此这其实是一个unordered_map<int,deque>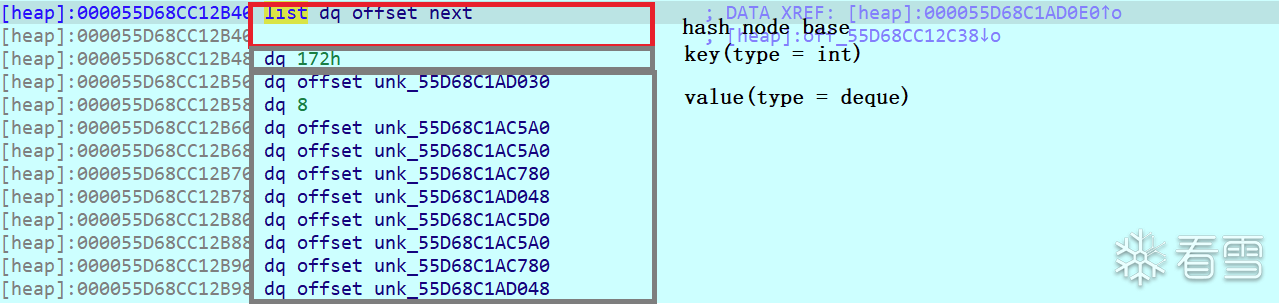
到这里我们对该变量有了大体的认识,大概率是不断地stl容器嵌套,接下来继续去分析输入和这些容器之间的关系。input_check函数通过input_num输入一个数字,并且返回该容器对应元素。这个明显是deque的取元素操作。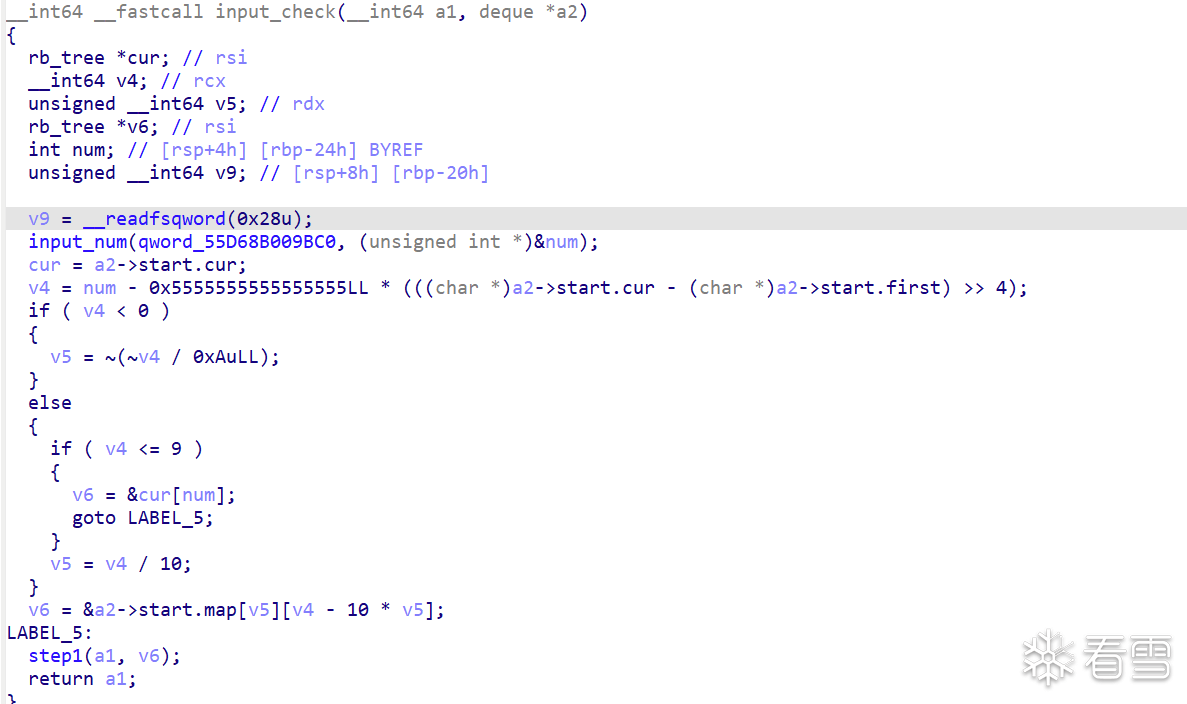
然后通过step1跳转到下一层,下一层和input_check逻辑其实是差不多的,也是输入一个数字,然后获取map中对应的元素。
然后通过step2跳转到下一层,持续同样的操作,只不过这一层是unordered_map罢了。
这样的顺序刚好和我们之前分析的数据类型嵌套的顺序相符,所以我们需要根据这些函数来反推出这些数据结构的嵌套顺序。不难发现unordered_map的代码明显存在一个取mod的操作,而map存在std::rebalanced的操作。因此可以写出如下脚本来分析出容器的嵌套类型。、
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
import
ida_bytes
import
ida_funcs
import
ida_xref
import
idaapi
step_funcs
=
{}
funclist
=
Functions()
rebalance_func
=
None
for
f
in
funclist:
name
=
ida_funcs.get_func_name(f)
if
'step'
in
name:
step_funcs[name]
=
f
elif
'rebalance'
in
name:
rebalance_func
=
f
assert
rebalance_func !
=
None
step_type
=
{}
for
name, addr
in
step_funcs.items():
code
=
str
(idaapi.decompile(addr))
if
'rebalance'
in
code:
step_type[name]
=
'map'
elif
'%'
in
code:
step_type[name]
=
'hash_map'
else
:
step_type[name]
=
'deque'
for
i
in
range
(
28
):
print
(
'\''
+
step_type[
'step'
+
str
(i
+
1
)]
+
'\''
+
', '
, end
=
'')
|
然后根据上述的出的容器嵌套顺序和对应容器的内存模型dump出对应的数据结构。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
import
ida_bytes
import
idaapi
size_table
=
{
'map'
:
48
,
'deque'
:
80
,
'string'
:
32
,
'hash_map'
:
16
,
}
def
dump_rbtree_node(addr):
return
{
'color'
: ida_bytes.get_qword(addr),
'parent'
: ida_bytes.get_qword(addr
+
8
),
'left'
: ida_bytes.get_qword(addr
+
16
),
'right'
: ida_bytes.get_qword(addr
+
24
),
}
def
dump_rbtree_map(addr):
key
=
ida_bytes.get_qword(addr)
node_addr
=
addr
+
8
node_num
=
ida_bytes.get_qword(addr
+
40
)
result
=
{}
def
visit(node):
if
node
=
=
idaapi.BADADDR:
return
info
=
dump_rbtree_node(node)
assert
info[
'color'
]
=
=
1
or
info[
'color'
]
=
=
0
value_key
=
ida_bytes.get_qword(node
+
32
)
data_addr
=
node
+
40
result[value_key]
=
data_addr
if
info[
'left'
] !
=
0
:
visit(info[
'left'
])
if
info[
'right'
] !
=
0
:
visit(info[
'right'
])
d
=
dump_rbtree_node(node_addr)
visit(d[
'parent'
])
assert
len
(result.keys())
=
=
node_num
return
result
def
dump_deque_iterator(addr):
return
{
'cur'
: ida_bytes.get_qword(addr),
'first'
: ida_bytes.get_qword(addr
+
8
),
'last'
: ida_bytes.get_qword(addr
+
16
),
'map'
: ida_bytes.get_qword(addr
+
24
),
}
def
dump_deque(addr, delta):
deque_map
=
ida_bytes.get_qword(addr)
map_size
=
ida_bytes.get_qword(addr
+
8
)
assert
map_size
=
=
8
start
=
dump_deque_iterator(addr
+
16
)
finish
=
dump_deque_iterator(addr
+
16
+
32
)
assert
start[
'last'
]
=
=
finish[
'last'
]
and
start[
'first'
]
=
=
finish[
'first'
]
and
start[
'map'
]
=
=
finish[
'map'
]
assert
(finish[
'cur'
]
-
start[
'cur'
])
%
delta
=
=
0
ptr
=
start[
'cur'
]
index
=
0
result
=
{}
while
ptr !
=
finish[
'cur'
]:
result[index]
=
ptr
index
+
=
1
ptr
+
=
delta
return
result
def
dump_string(addr):
data
=
ida_bytes.get_qword(addr)
length
=
ida_bytes.get_qword(addr
+
8
)
return
ida_bytes.get_bytes(data, length).decode()
def
dump_hashtable_map(addr):
addrs
=
set
()
hash_table
=
ida_bytes.get_qword(addr)
table_num
=
ida_bytes.get_qword(addr
+
8
)
for
i
in
range
(table_num):
link_list
=
ida_bytes.get_qword(hash_table
+
8
*
i)
if
link_list
=
=
0
:
continue
ptr
=
ida_bytes.get_qword(link_list)
while
ptr !
=
0
:
assert
ptr !
=
idaapi.BADADDR
addrs.add(ptr)
ptr
=
ida_bytes.get_qword(ptr)
result
=
{}
for
a
in
addrs:
result[ida_bytes.get_qword(a
+
8
)]
=
a
+
16
return
result
type_list
=
[
'deque'
,
'map'
,
'hash_map'
,
'deque'
,
'map'
,
'map'
,
'hash_map'
,
'hash_map'
,
'map'
,
'map'
,
'hash_map'
,
'map'
,
'map'
,
'deque'
,
'deque'
,
'map'
,
'map'
,
'map'
,
'map'
,
'map'
,
'map'
,
'map'
,
'map'
,
'map'
,
'map'
,
'map'
,
'deque'
,
'deque'
,
'string'
]
def
dump_dfs(depth, addr):
stl_type
=
type_list[depth]
tmp
=
{}
if
stl_type
=
=
'map'
:
tmp
=
dump_rbtree_map(addr)
elif
stl_type
=
=
'hash_map'
:
tmp
=
dump_hashtable_map(addr)
elif
stl_type
=
=
'deque'
:
next_type
=
type_list[depth
+
1
]
tmp
=
dump_deque(addr, size_table[next_type])
elif
stl_type
=
=
'string'
:
return
dump_string(addr)
else
:
assert
False
node
=
{}
for
k, v
in
tmp.items():
node[k]
=
dump_dfs(depth
+
1
, v)
return
node
result
=
dump_dfs(
0
,
0x7FFEA5D3A460
)
import
json
with
open
(
'json_data.txt'
,
'w+'
) as f:
json.dump(result, f)
#dump_rbtree_map(0x55F47B277658)
|
最后得到如下数据文件,是一个dict的嵌套,最后保存的是字符串。
最后main函数通过对比字符串,来判断我们输入的一系列数字是否能够访问到对应的字符串,从而判断数字是否正确。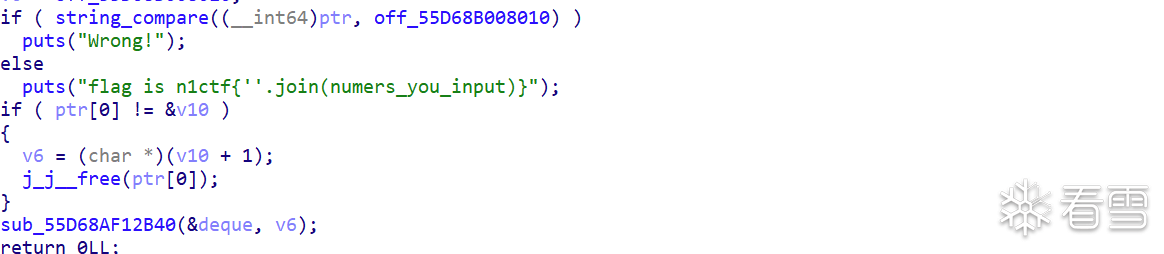
最后根据dump出的dict从而写出dfs查找出对应的数字序列,从而获得flag。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
target
=
'8850a16d-e427-446e-b4df-5f45376e20e4'
path
=
[]
def
dfs(depth, node):
global
path
if
type
(node)
=
=
dict
:
for
k, v
in
node.items():
path.append(k)
dfs(depth
+
1
, v)
path.pop()
else
:
if
node
=
=
target:
print
(path)
import
json
f
=
open
(
'json_data.txt'
,
'r'
)
data
=
json.load(f)
f.close()
dfs(
0
, data)
|
更多【STL容器逆向与实战(N1CTF2022 cppmaster wp)】相关视频教程:www.yxfzedu.com
相关文章推荐
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全 CTF对抗 IOS安全
- 2-wibu软授权(三) - Android安全 CTF对抗 IOS安全
- 软件逆向-wibu软授权(二) - Android安全 CTF对抗 IOS安全
- 软件逆向-wibu软授权(一) - Android安全 CTF对抗 IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全 CTF对抗 IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全 CTF对抗 IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全 CTF对抗 IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全 CTF对抗 IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全 CTF对抗 IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全 CTF对抗 IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全 CTF对抗 IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全 CTF对抗 IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全 CTF对抗 IOS安全
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全 CTF对抗 IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全 CTF对抗 IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全 CTF对抗 IOS安全
- 二进制漏洞-Windows内核提权漏洞CVE-2018-8120分析 - Android安全 CTF对抗 IOS安全
- CTF对抗-Hack-A-Sat 2020预选赛 beckley - Android安全 CTF对抗 IOS安全
- CTF对抗-]2022KCTF秋季赛 第十题 两袖清风 - Android安全 CTF对抗 IOS安全
- CTF对抗-kctf2022 秋季赛 第十题 两袖清风 wp - Android安全 CTF对抗 IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com

接各种驱动定制如:游戏读写驱动,软件内存保护,防止调试等功能定制。
出租读写驱动,调试驱动,无痕注入支持各种游戏。
邮箱:service@yxfzedu.com
QQ:851920120
特别说明:不接游戏数据分析,外挂编写,登陆协议等类似业务。