CTF对抗- Go AST 浅析
推荐 原创Go AST 浅析
(炒冷饭)
在今年的网鼎杯某赛道中遇到了一个题,通过混淆的go源码分析各类函数调用、定义信息。但由于题目本身要求获得的信息过于简单,有不少人直接暴力搜索来解决。但当我们遇到更为复杂,更为巨大的混淆代码时,IDE所提供的简单分析功能也就无能为力了。这也就是我写下这篇文章的原因。
What are ASTs?
AST,即抽象语法树(Abstract Syntax Tree),也被简称为语法树,是源代码的抽象语法结构的树状显示。其中树上的每个节点代表着源代码中的一种结构。AST并不是一种编程语言特有的。JavaScript、C/C++、Python、Go等几乎所有的编程语言都有AST。只是其编译器各不相同。
正如孩提时代总喜欢玩的积木那般,我们将其组装,而后将其拆解,再次又将其组装成“新”玩具。是的。通过AST,我们可以将我们的源代码拆解开来,而后根据我们的意愿进行组装。
你是否想过,我们常用的IDE所具备的各类功能:语法高亮、自动补全、错误提示、代码格式化、代码压缩等等其实都是通过AST来实现的。
Token
Token是编程语言中最小的具有独立意义的词法单元。Token不仅包含关键字,还包含了各种用户自定义的标识符、运算符、分隔符和注释等。
Token对应的词法单元有三个重要属性:
- Token本身的值表示词法单元的类型
- Token在源代码中的表现形式
- Token出现的位置
在Token中,较为特殊的是注释和分号。普通的注释并不影响程序的语义,因此在某些情况下,我们可以忽略注释。
正如上文所说的,Go语言也由标识符、运算符等Token组成。其中标识符的语法定义如下。
|
1
2
|
identifier
=
letter { letter | unicode_digit } .
letter
=
unicode_letter |
"_"
.
|
其中identifier表示标识符,由字母和数字组成,开头必须为字母,较为特殊的,下划线也被视作字母。因此我们可以使用下划线作为标识符。
Token的定义在go/token中。
|
1
2
|
/
/
Token
is
the
set
of lexical tokens of the Go programming language.
type
Token
int
|
Token被定义为一种枚举值,不同值的Token表示不同类型的词法记号。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
/
/
The
list
of tokens.
const (
/
/
Special tokens
ILLEGAL Token
=
iota
EOF
COMMENT
literal_beg
/
/
Identifiers
and
basic
type
literals
/
/
(these tokens stand
for
classes of literals)
IDENT
/
/
main
INT
/
/
12345
FLOAT
/
/
123.45
IMAG
/
/
123.45i
CHAR
/
/
'a'
STRING
/
/
"abc"
literal_end
operator_beg
/
/
Operators
and
delimiters
ADD
/
/
+
SUB
/
/
-
MUL
/
/
*
QUO
/
/
/
REM
/
/
%
AND
/
/
&
OR
/
/
|
XOR
/
/
^
SHL
/
/
<<
SHR
/
/
>>
AND_NOT
/
/
&^
ADD_ASSIGN
/
/
+
=
SUB_ASSIGN
/
/
-
=
MUL_ASSIGN
/
/
*
=
QUO_ASSIGN
/
/
/
=
REM_ASSIGN
/
/
%
=
AND_ASSIGN
/
/
&
=
OR_ASSIGN
/
/
|
=
XOR_ASSIGN
/
/
^
=
SHL_ASSIGN
/
/
<<
=
SHR_ASSIGN
/
/
>>
=
AND_NOT_ASSIGN
/
/
&^
=
LAND
/
/
&&
LOR
/
/
||
ARROW
/
/
<
-
INC
/
/
+
+
DEC
/
/
-
-
EQL
/
/
=
=
LSS
/
/
<
GTR
/
/
>
ASSIGN
/
/
=
NOT
/
/
!
NEQ
/
/
!
=
LEQ
/
/
<
=
GEQ
/
/
>
=
DEFINE
/
/
:
=
ELLIPSIS
/
/
...
LPAREN
/
/
(
LBRACK
/
/
[
LBRACE
/
/
{
COMMA
/
/
,
PERIOD
/
/
.
RPAREN
/
/
)
RBRACK
/
/
]
RBRACE
/
/
}
SEMICOLON
/
/
;
COLON
/
/
:
operator_end
keyword_beg
/
/
Keywords
BREAK
CASE
CHAN
CONST
CONTINUE
DEFAULT
DEFER
ELSE
FALLTHROUGH
FOR
FUNC
GO
GOTO
IF
IMPORT
INTERFACE
MAP
PACKAGE
RANGE
RETURN
SELECT
STRUCT
SWITCH
TYPE
VAR
keyword_end
additional_beg
/
/
additional tokens, handled
in
an ad
-
hoc manner
TILDE
additional_end
)
|
所有的Token被分为四类:特殊类型的Token、基础面值对应的Token、运算符Token和关键字。
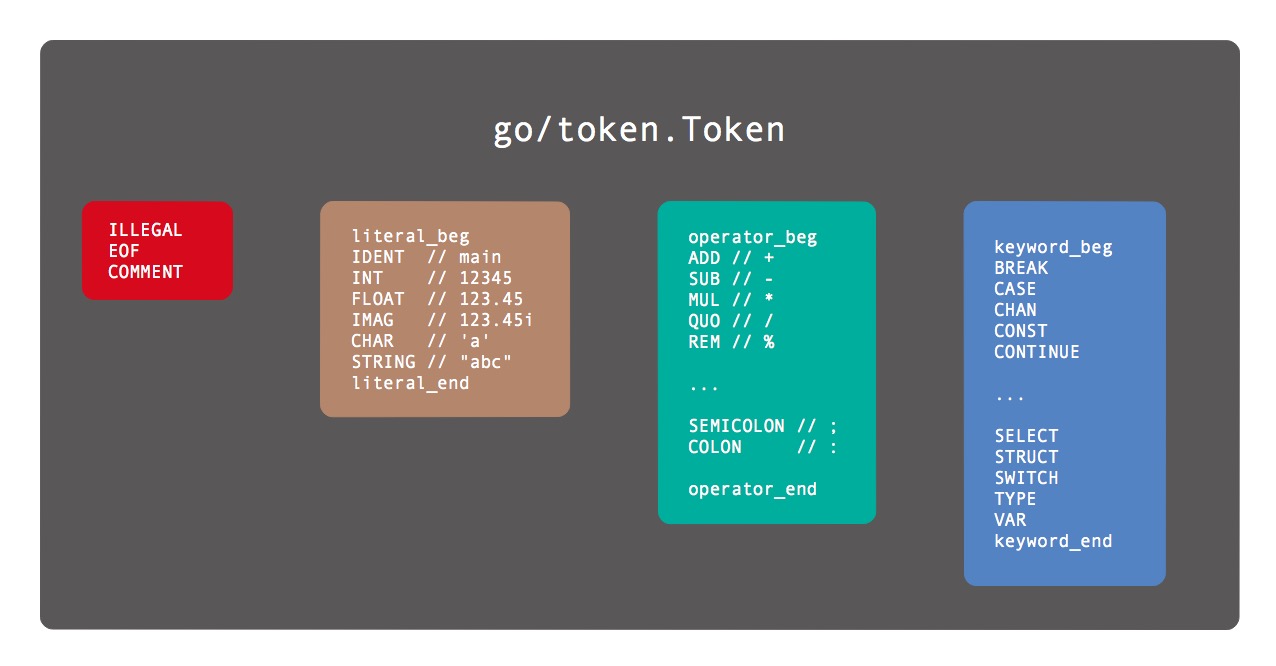
需要注意的是这里的*_beg是私有类型,主要用于值域范围范围的判断。
FileSet & File
Go语言是由多个文件组成的包,而后多个包链接为一个可执行文件,因此单个包对应的多个文件可被视作Go的基本编译单元。
因此就有了go/token中的FileSet和File对象。用于描述文件以及对应的文件集合。
FileSet的结构如下所示。
|
1
2
3
4
5
6
|
type
FileSet struct {
mutex sync.RWMutex
/
/
protects the
file
set
base
int
/
/
base offset
for
the
next
file
files []
*
File
/
/
list
of files
in
the order added to the
set
last atomic.Pointer[
File
]
/
/
cache of last
file
looked up
}
|
File的结构如下所示。
|
1
2
3
4
5
6
7
8
9
10
|
type
File
struct {
name string
/
/
file
name as provided to AddFile
base
int
/
/
Pos value
range
for
this
file
is
[base...base
+
size]
size
int
/
/
file
size as provided to AddFile
/
/
lines
and
infos are protected by mutex
mutex sync.Mutex
lines []
int
/
/
lines contains the offset of the first character
for
each line (the first entry
is
always
0
)
infos []lineInfo
}
|
显而易见,FileSet可以抽象为一个存储File的一维数组。而每个File的主要组成为name、base、size。
Position
在go/token中,定义了一个包含具体位置信息的结构,即Position。
|
1
2
3
4
5
6
|
type
Position struct {
Filename string
/
/
filename,
if
any
Offset
int
/
/
offset, starting at
0
Line
int
/
/
line number, starting at
1
Column
int
/
/
column number, starting at
1
(byte count)
}
|
源代码中的注释解释了各个变量代表的含义,这里不再赘述。
Lit
BasicLit
BasicLit是程序代码中直接表示的值。比如在x*2+1中,2即为BasicLit,而x不是BasicLit而是identifier。
|
1
2
3
4
5
6
7
8
9
10
|
literal_beg
/
/
Identifiers
and
basic
type
literals
/
/
(these tokens stand
for
classes of literals)
IDENT
/
/
main
INT
/
/
12345
FLOAT
/
/
123.45
IMAG
/
/
123.45i
CHAR
/
/
'a'
STRING
/
/
"abc"
literal_end
|
没有导出的literal_beg和literal_end之间的Token都是BasicLit。
Go语言的抽象语法树由go/ast定义。其中ast.BasicLit表示一个基础类型的面值常量结构,它的定义如下所示。
|
1
2
3
4
5
6
|
/
/
A BasicLit node represents a literal of basic
type
.
BasicLit struct {
ValuePos token.Pos
/
/
literal position
Kind token.Token
/
/
token.
INT
, token.
FLOAT
, token.IMAG, token.CHAR,
or
token.STRING
Value string
/
/
literal string; e.g.
42
,
0x7f
,
3.14
,
1e
-
9
,
2.4i
,
'a'
,
'\x7f'
,
"foo"
or
`\m\n\o`
}
|
ValuePos代表其词法元素在源代码中的位置;Kind表示面值的类型;Value表示面值对应的值。
Ident
Ident同样位于go/ast中,用于表示标识符类型。
|
1
2
3
4
5
6
|
/
/
An Ident node represents an identifier.
Ident struct {
NamePos token.Pos
/
/
identifier position
Name string
/
/
identifier name
Obj
*
Object
/
/
denoted
object
;
or
nil
}
|
NamePos代表其词法元素在源代码中的位置;Name表示其标识符的名称;Obj表示标识符的类型以及其他的一些拓展信息。
ast.Object是一个相对复杂的结构。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
/
/
Objects
/
/
An
Object
describes a named language entity such as a package,
/
/
constant,
type
, variable, function (incl. methods),
or
label.
/
/
/
/
The Data fields contains
object
-
specific data:
/
/
/
/
Kind Data
type
Data value
/
/
Pkg
*
Scope package scope
/
/
Con
int
iota
for
the respective declaration
type
Object
struct {
Kind ObjKind
Name string
/
/
declared name
Decl
any
/
/
corresponding Field, XxxSpec, FuncDecl, LabeledStmt, AssignStmt, Scope;
or
nil
Data
any
/
/
object
-
specific data;
or
nil
Type
any
/
/
placeholder
for
type
information; may be nil
}
|
Expression
Basic Expr
基础表达式主要是由一元、二元运算符组成的表达式,运算的主题为各种面值、或标识符。语法如下所示。
|
1
2
3
4
5
6
7
8
9
10
|
Expression
=
UnaryExpr | Expression binary_op Expression .
UnaryExpr
=
Operand | unary_op UnaryExpr .
Operand
=
Literal | identifier |
"("
Expression
")"
.
binary_op
=
"||"
|
"&&"
| rel_op | add_op | mul_op .
rel_op
=
"=="
|
"!="
|
"<"
|
"<="
|
">"
|
">="
.
add_op
=
"+"
|
"-"
|
"|"
|
"^"
.
mul_op
=
"*"
|
"/"
|
"%"
|
"<<"
|
">>"
|
"&"
|
"&^"
.
unary_op
=
"+"
|
"-"
|
"!"
|
"^"
|
"*"
|
"&"
|
"<-"
.
|
其中Expression表示基础表达式的递归定义,可以是UnaryExpr类型的一元表达式,或者是binary_op生成的二元表达式。而基础表达式运算符两边的对象由Operand定义,主要是面值或表达式,也可以是由小括弧包含的表达式。
我们可以使用parser.ParseExpr来解析单个表达式。其返回的值类型实际上是一个抽象类型的接口。
|
1
2
3
4
5
|
/
/
All
expression nodes implement the Expr interface.
type
Expr interface {
Node
exprNode()
}
|
其内置了一个ast.Node接口以及一个exprNode方法。
Node接口仅定义了两个方法表示了这个语法树结点的开始位置和结束位置。
|
1
2
3
4
5
|
/
/
All
node types implement the Node interface.
type
Node interface {
Pos() token.Pos
/
/
position of first character belonging to the node
End() token.Pos
/
/
position of first character immediately after the node
}
|
我们可以查询go中expr为后缀的表达式类型。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
> go doc go
/
ast | grep Expr
type
BadExpr struct{ ... }
type
BinaryExpr struct{ ... }
type
CallExpr struct{ ... }
type
Expr interface{ ... }
type
ExprStmt struct{ ... }
type
IndexExpr struct{ ... }
type
IndexListExpr struct{ ... }
type
KeyValueExpr struct{ ... }
type
ParenExpr struct{ ... }
type
SelectorExpr struct{ ... }
type
SliceExpr struct{ ... }
type
StarExpr struct{ ... }
type
TypeAssertExpr struct{ ... }
type
UnaryExpr struct{ ... }
|
当然表达式类型远不止这些,这里仅用作举例。
我们可以使用ast.BinaryExpr构造一个简单的二元算术表达式。
|
1
2
3
4
|
func main() {
expr, _ :
=
parser.ParseExpr(
"1+9*2"
)
ast.
Print
(nil, expr)
}
|
输出结果如下。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
0
*
ast.BinaryExpr {
1
. X:
*
ast.BasicLit {
2
. . ValuePos:
1
3
. . Kind:
INT
4
. . Value:
"1"
5
. }
6
. OpPos:
2
7
. Op:
+
8
. Y:
*
ast.BinaryExpr {
9
. . X:
*
ast.BasicLit {
10
. . . ValuePos:
3
11
. . . Kind:
INT
12
. . . Value:
"9"
13
. . }
14
. . OpPos:
4
15
. . Op:
*
16
. . Y:
*
ast.BasicLit {
17
. . . ValuePos:
5
18
. . . Kind:
INT
19
. . . Value:
"2"
20
. . }
21
. }
22
}
|
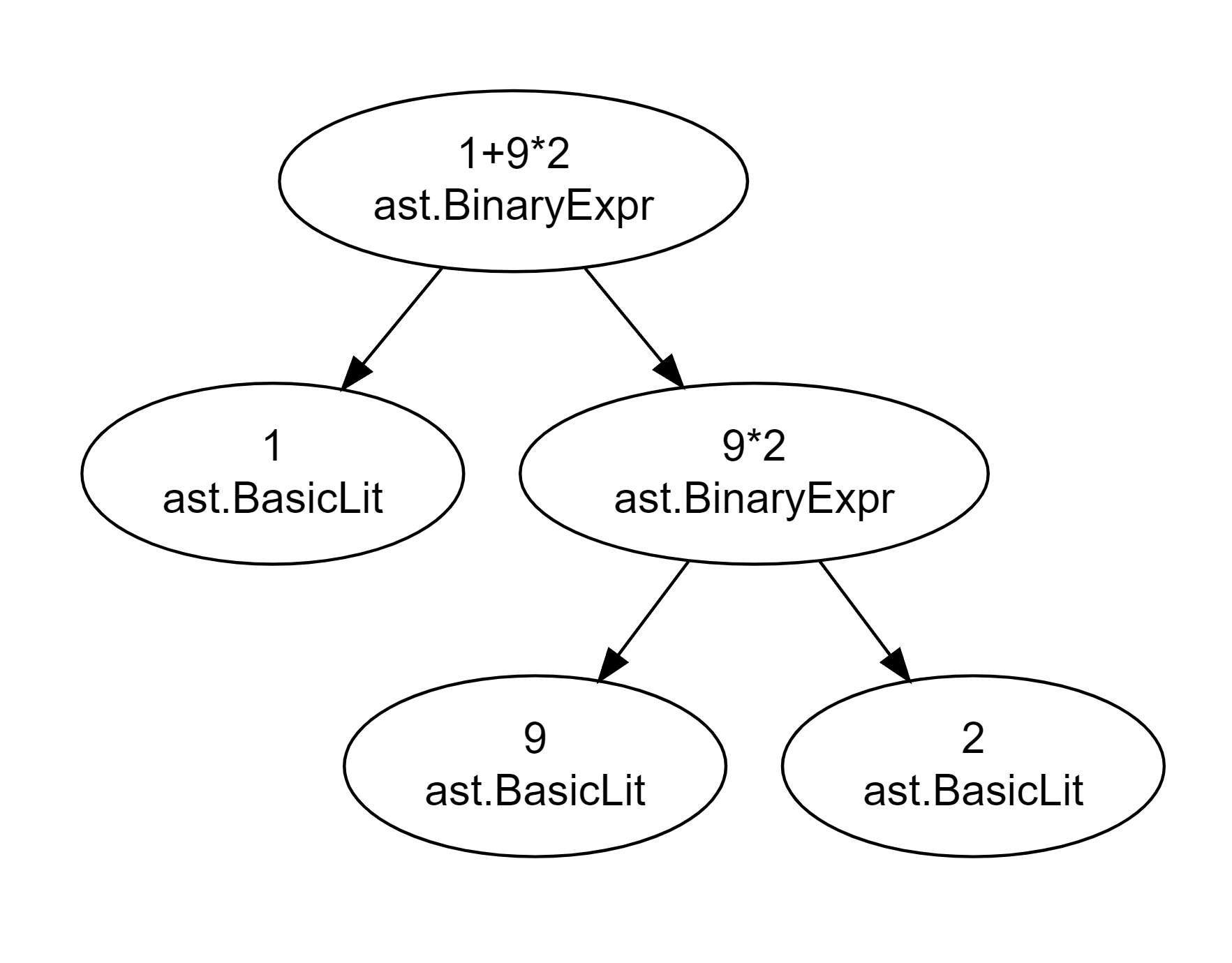
相应的树结构表示:
其中ast.BasicLit是基础面值类型,ast.BinaryExpr表示二元表达式的结点,其定义如下:
|
1
2
3
4
5
6
7
|
/
/
A BinaryExpr node represents a binary expression.
BinaryExpr struct {
X Expr
/
/
left operand
OpPos token.Pos
/
/
position of Op
Op token.Token
/
/
operator
Y Expr
/
/
right operand
}
|
Op代表二元运算符,OpPos代表运算符的位置。X和Y代表二元运算符两侧的操作数,即左值和右值。他们的类型都是Expr这个抽象接口,这就构成了递归定义。在上图中也能看到,ParseExpr得到的结果的最外层是由一个ast.BasicLit和ast.BinaryExpr共同组成的(这也说明了乘法拥有相对较高的优先级)。
File Structure
Go语言代码根据目录组织多个文件,文件必须属于同一个目录下。
标准库go/parser包中的parser.ParseDir用于解析目录内的全部Go语言文件,返回的map[string]*ast.Package包含多个包信息。
ast.Package的结构如下。
|
1
2
3
4
5
6
7
8
|
/
/
A Package node represents a
set
of source files
/
/
collectively building a Go package.
type
Package struct {
Name string
/
/
package name
Scope
*
Scope
/
/
package scope across
all
files
Imports
map
[string]
*
Object
/
/
map
of package
id
-
> package
object
Files
map
[string]
*
File
/
/
Go source files by filename
}
|
parser.ParseFile用于解析单个文件,返回的*ast.File包含文件内部代码信息。
每个*ast.Package是由多个*ast.File文件组成。它们之间的逻辑关系如下图所示:
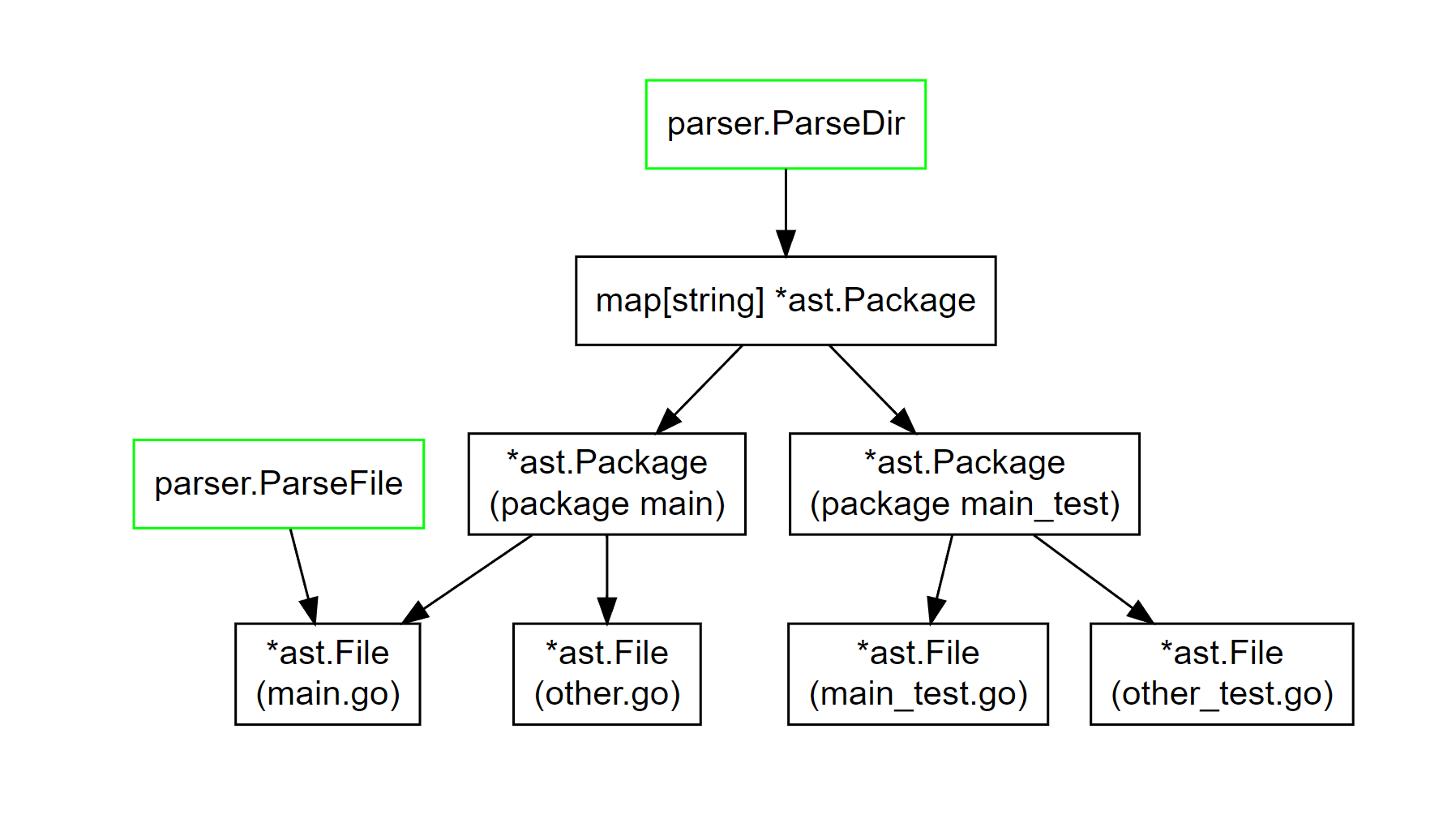
ast.File结构如下所示。
|
1
2
3
4
5
6
7
8
9
10
|
type
File
struct {
Doc
*
CommentGroup
/
/
associated documentation;
or
nil
Package token.Pos
/
/
position of
"package"
keyword
Name
*
Ident
/
/
package name
Decls []Decl
/
/
top
-
level declarations;
or
nil
Scope
*
Scope
/
/
package scope (this
file
only)
Imports []
*
ImportSpec
/
/
imports
in
this
file
Unresolved []
*
Ident
/
/
unresolved identifiers
in
this
file
Comments []
*
CommentGroup
/
/
list
of
all
comments
in
the source
file
}
|
File.Name成员表示文件对应包的名字;File.Imports表示当前文件导入的第三方的包信息;File.Decls包含了当前文件全部的包级声明信息(包含导入信息),这意味着即使没有File.Imports,我们也能够从File.Decls中获取所有的包级信息。
我们可以通过File.Decls查看每个成员的类型。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
/
*
package main
import
"go/ast"
import
"go/parser"
type
intArray [
10
]
int
const hello
=
"hello world!"
var array
=
[]
int
{
1
,
2
,
3
,
4
,
5
}
func main() {
var a ast.
File
a.Pos()
}
*
/
for
idx, decl :
=
range
pl.Decls {
fmt.Printf(
"%d: %T\n"
, idx, decl)
}
/
*
0
:
*
ast.GenDecl
1
:
*
ast.GenDecl
2
:
*
ast.GenDecl
3
:
*
ast.GenDecl
4
:
*
ast.GenDecl
5
:
*
ast.FuncDecl
*
/
|
我们可以发现import、type、const和var都是对应*ast.GenDecl类型,只有函数是独立的*ast.FuncDecl类型。
General declaration
通用声明是不含函数声明的包级别声明,包含:导入、类型、常量和变量四种声明。
Import
在Go中,当package关键字定义一个包后,导入语句必须其后出现,然后才能是类型、常量等其他声明。
根据导入语法定义,创建的导入声明有以下几种形式
|
1
2
3
4
|
import
"fmt"
import
https
"net/http"
import
.
"go/token"
import
_
"go/parser"
|
第一种为默认的导包形式,即将包名作为符号导入当前的文件的符号空间;第二种将导入的net/http以https命名导入当前文件的符号空间;第三种将包中所有公开符号导入当前文件的符号空间;第四种仅触发包初始化动作,而不导入任何符号。
我们可以解析四种不同的导入方式来查看其中的异同。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
func main() {
var src string
=
`package main
import
"fmt"
import
https
"net/http"
import
.
"go/token"
import
_
"go/parser"
`
fl :
=
token.NewFileSet()
pl, _ :
=
parser.ParseFile(fl,
"example.go"
, src, parser.ImportsOnly)
for
idx, spec :
=
range
pl.Imports {
fmt.Printf(
"%d\t %s\t %#v\n"
, idx, spec.Name, spec.Path)
}
}
/
*
0
<nil> &ast.BasicLit{ValuePos:
22
, Kind:
9
, Value:
"\"fmt\""
}
1
https &ast.BasicLit{ValuePos:
41
, Kind:
9
, Value:
"\"net/http\""
}
2
. &ast.BasicLit{ValuePos:
61
, Kind:
9
, Value:
"\"go/token\""
}
3
_ &ast.BasicLit{ValuePos:
81
, Kind:
9
, Value:
"\"go/parser\""
}
*
/
|
Type
类型声明在语法树的结点类型为ast.TypeSpec。我们可以通过以下代码查看类型声明列表中的每个元素。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
func main() {
var src string
=
`package main
type
b string
type
array [
10
]
int
`
fl :
=
token.NewFileSet()
pl, _ :
=
parser.ParseFile(fl,
"example.go"
, src, parser.AllErrors)
for
idx, spec :
=
range
pl.Decls {
if
v, ok :
=
spec.(
*
ast.GenDecl); ok {
fmt.Printf(
"%d\t %T\t %#v\n"
, idx, v, v.Specs)
}
}
}
/
*
0
*
ast.GenDecl []ast.Spec{(
*
ast.TypeSpec)(
0x14000122080
)}
1
*
ast.GenDecl []ast.Spec{(
*
ast.TypeSpec)(
0x14000122100
)}
*
/
|
ast.TypeSpec的结构定义如下。
|
1
2
3
4
5
6
7
8
9
|
/
/
A TypeSpec node represents a
type
declaration (TypeSpec production).
TypeSpec struct {
Doc
*
CommentGroup
/
/
associated documentation;
or
nil
Name
*
Ident
/
/
type
name
TypeParams
*
FieldList
/
/
type
parameters;
or
nil
Assign token.Pos
/
/
position of
'='
,
if
any
Type
Expr
/
/
*
Ident,
*
ParenExpr,
*
SelectorExpr,
*
StarExpr,
or
any
of the
*
XxxTypes
Comment
*
CommentGroup
/
/
line comments;
or
nil
}
|
Name表示类型定义的名称;Assign对应=符号的位置。如果Assign对应的位置有效,表示这是定义已有类型的一个别名;Type表示具体的类型的表达式。
Const
在Go中,我们拥有两种常量:弱类型常量和强类型常量。
|
1
2
|
const Pi
=
3.14
const Pi64 float64
=
3.1415926
|
其中Pi被定义为弱类型的浮点数常量,可以赋值给float32或float64为基础其它变量。而Pi64是被定义为float64的强类型常量,默认只能非接受float64类型的变量赋值。
常量声明和导入声明一样同属ast.GenDecl类型的通用声明,它们的区别在于ast.GenDecl.Specs部分。我们可以使用同样的代码查看常量声明语句中Specs中元素的类型。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
func main() {
var src string
=
`package main
const Pi
=
3.14
const Pi64 float64
=
3.1415926
`
fl :
=
token.NewFileSet()
pl, _ :
=
parser.ParseFile(fl,
"example.go"
, src, parser.AllErrors)
for
idx, spec :
=
range
pl.Decls {
if
v, ok :
=
spec.(
*
ast.GenDecl); ok {
fmt.Printf(
"%d\t %T\t %#v\n"
, idx, v, v.Specs)
}
}
}
/
*
0
*
ast.GenDecl []ast.Spec{(
*
ast.ValueSpec)(
0x1400010c0a0
)}
1
*
ast.GenDecl []ast.Spec{(
*
ast.ValueSpec)(
0x1400010c0f0
)}
*
/
|
可以看到常量类型为ast.ValueSpec。其结构如下所示。
|
1
2
3
4
5
6
7
|
ValueSpec struct {
Doc
*
CommentGroup
/
/
associated documentation;
or
nil
Names []
*
Ident
/
/
value names (
len
(Names) >
0
)
Type
Expr
/
/
value
type
;
or
nil
Values []Expr
/
/
initial values;
or
nil
Comment
*
CommentGroup
/
/
line comments;
or
nil
}
|
进一步的,我们可以使用ast.Print(nil, v.Specs)来查看两者异同。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
0
[]ast.Spec (
len
=
1
) {
1
.
0
:
*
ast.ValueSpec {
2
. . Names: []
*
ast.Ident (
len
=
1
) {
3
. . .
0
:
*
ast.Ident {
4
. . . . NamePos:
20
5
. . . . Name:
"Pi"
6
. . . . Obj:
*
ast.
Object
{
7
. . . . . Kind: const
8
. . . . . Name:
"Pi"
9
. . . . . Decl:
*
(obj @
1
)
10
. . . . . Data:
0
11
. . . . }
12
. . . }
13
. . }
14
. . Values: []ast.Expr (
len
=
1
) {
15
. . .
0
:
*
ast.BasicLit {
16
. . . . ValuePos:
25
17
. . . . Kind:
FLOAT
18
. . . . Value:
"3.14"
19
. . . }
20
. . }
21
. }
22
}
0
[]ast.Spec (
len
=
1
) {
1
.
0
:
*
ast.ValueSpec {
2
. . Names: []
*
ast.Ident (
len
=
1
) {
3
. . .
0
:
*
ast.Ident {
4
. . . . NamePos:
36
5
. . . . Name:
"Pi64"
6
. . . . Obj:
*
ast.
Object
{
7
. . . . . Kind: const
8
. . . . . Name:
"Pi64"
9
. . . . . Decl:
*
(obj @
1
)
10
. . . . . Data:
0
11
. . . . }
12
. . . }
13
. . }
14
. .
Type
:
*
ast.Ident {
15
. . . NamePos:
41
16
. . . Name:
"float64"
17
. . }
18
. . Values: []ast.Expr (
len
=
1
) {
19
. . .
0
:
*
ast.BasicLit {
20
. . . . ValuePos:
51
21
. . . . Kind:
FLOAT
22
. . . . Value:
"3.1415926"
23
. . . }
24
. . }
25
. }
26
}
|
可以发现相较于弱类型常量,强类型常量的定义拥有了Type属性,使用ast.Ident标记了常量的类型。
Var
我们同样可以使用先前的例子,看到其中的异同。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
0
[]ast.Spec (
len
=
1
) {
1
.
0
:
*
ast.ValueSpec {
2
. . Names: []
*
ast.Ident (
len
=
1
) {
3
. . .
0
:
*
ast.Ident {
4
. . . . NamePos:
18
5
. . . . Name:
"Pi"
6
. . . . Obj:
*
ast.
Object
{
7
. . . . . Kind: var
8
. . . . . Name:
"Pi"
9
. . . . . Decl:
*
(obj @
1
)
10
. . . . . Data:
0
11
. . . . }
12
. . . }
13
. . }
14
. . Values: []ast.Expr (
len
=
1
) {
15
. . .
0
:
*
ast.BasicLit {
16
. . . . ValuePos:
23
17
. . . . Kind:
FLOAT
18
. . . . Value:
"3.14"
19
. . . }
20
. . }
21
. }
22
}
0
[]ast.Spec (
len
=
1
) {
1
.
0
:
*
ast.ValueSpec {
2
. . Names: []
*
ast.Ident (
len
=
1
) {
3
. . .
0
:
*
ast.Ident {
4
. . . . NamePos:
32
5
. . . . Name:
"Pi64"
6
. . . . Obj:
*
ast.
Object
{
7
. . . . . Kind: var
8
. . . . . Name:
"Pi64"
9
. . . . . Decl:
*
(obj @
1
)
10
. . . . . Data:
0
11
. . . . }
12
. . . }
13
. . }
14
. .
Type
:
*
ast.Ident {
15
. . . NamePos:
37
16
. . . Name:
"float64"
17
. . }
18
. . Values: []ast.Expr (
len
=
1
) {
19
. . .
0
:
*
ast.BasicLit {
20
. . . . ValuePos:
47
21
. . . . Kind:
FLOAT
22
. . . . Value:
"3.1415926"
23
. . . }
24
. . }
25
. }
26
}
|
可以看到变量声明几乎与常量声明相同。但我们仍可以通过ast.GenDecl.Tok来区分它们。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
/
*
package main
var Pi
=
3.14
const cPi
=
3.14
*
/
fmt.Printf(
"%s\t %#v\n"
, v.Tok, v.Specs)
/
*
var []ast.Spec{(
*
ast.ValueSpec)(
0x140001000a0
)}
const []ast.Spec{(
*
ast.ValueSpec)(
0x140001000f0
)}
*
/
|
Vars
Go中有如下定义方式,暂且称为分组定义。
|
1
2
3
4
5
6
|
var (
a
=
1
b
=
2
c
=
3
d
=
"4"
)
|
当我们使用先前的例子进行解析,其与Var的区别仅在于[]ast.Spec的成员随之增加。
|
1
2
|
fmt.Printf(
"%d\n"
,
len
(v.Specs))
/
/
4
|
Function
一个完整的函数定义如下。
|
1
|
func (p
*
xType) Hello(arg1, arg2
int
) (
bool
, error) { ... }
|
函数的声明对应ast.FuncDecl,它的定义如下所示。
|
1
2
3
4
5
6
7
8
|
/
/
A FuncDecl node represents a function declaration.
FuncDecl struct {
Doc
*
CommentGroup
/
/
associated documentation;
or
nil
Recv
*
FieldList
/
/
receiver (methods);
or
nil (functions)
Name
*
Ident
/
/
function
/
method name
Type
*
FuncType
/
/
function signature:
type
and
value parameters, results,
and
position of
"func"
keyword
Body
*
BlockStmt
/
/
function body;
or
nil
for
external (non
-
Go) function
}
|
Recv对应接收者列表,在这里代表(p *xType)部分;Name是函数的名字,这里的名字是Hello;Type表示方法或函数的类型(函数的类型和接口的定义一致,因为接口并不包含接收者信息),其中包含输入参数和返回值信息;Body表示函数体中的语句部分。
函数声明最重要的是Name、Recv、输入参数和返回值(FuncType),其中除Name之外的三者实际上都是ast.FieldList类型,输入参数和返回值被封装为ast.FuncType类型。表示函数类型的ast.FuncType结构体定义如下:
|
1
2
3
4
5
6
7
|
/
/
A FuncType node represents a function
type
.
FuncType struct {
Func token.Pos
/
/
position of
"func"
keyword (token.NoPos
if
there
is
no
"func"
)
TypeParams
*
FieldList
/
/
type
parameters;
or
nil
Params
*
FieldList
/
/
(incoming) parameters; non
-
nil
Results
*
FieldList
/
/
(outgoing) results;
or
nil
}
|
Params和Results分别表示输入参数和返回值列表,它们和函数的接收者参数列表都是ast.FieldList类型。
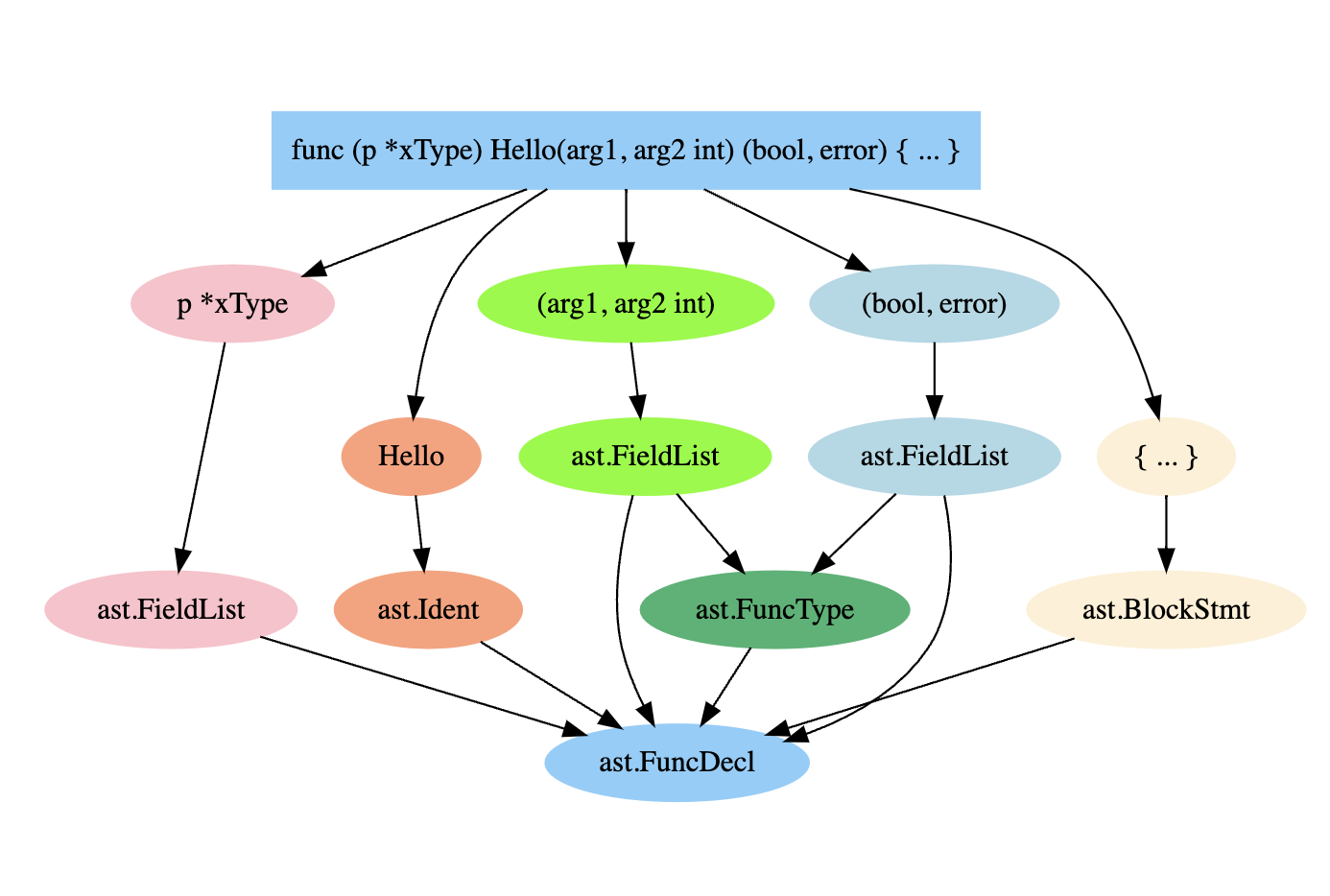
下面是ast.FielfList的结构。
|
1
2
3
4
5
6
7
|
/
/
A FieldList represents a
list
of Fields, enclosed by parentheses,
/
/
curly braces,
or
square brackets.
type
FieldList struct {
Opening token.Pos
/
/
position of opening parenthesis
/
brace
/
bracket,
if
any
List
[]
*
Field
/
/
field
list
;
or
nil
Closing token.Pos
/
/
position of closing parenthesis
/
brace
/
bracket,
if
any
}
|
其中包含了一个元素类型为ast.Field的切片,增加了开始与结束的位置信息。
ast.Field的结构如下所示。
|
1
2
3
4
5
6
7
|
type
Field struct {
Doc
*
CommentGroup
/
/
associated documentation;
or
nil
Names []
*
Ident
/
/
field
/
method
/
(
type
) parameter names;
or
nil
Type
Expr
/
/
field
/
method
/
parameter
type
;
or
nil
Tag
*
BasicLit
/
/
field tag;
or
nil
Comment
*
CommentGroup
/
/
line comments;
or
nil
}
|
Name存放参数的标识符;Type表示这一组参数的类型。
假定有如下函数定义:
|
1
|
func Hello(s0, s1 string, s2 string)
|
则s0, s1为同一个类型定义,对应一个ast.Field,s2则对应另一个ast.Field。
下面是一个简单的例子。
假定有如下方法函数
|
1
|
func (
*
int
) gogogo(arg1, arg2
int
, arg3 string)
int
{
return
arg1
+
arg2; }
|
我们可以使用以下的一个例子解析:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func main() {
var src string
=
`package main
func (
*
int
) gogogo(arg1, arg2
int
, arg3 string)
int
{
return
arg1
+
arg2; }
`
fl :
=
token.NewFileSet()
pl, _ :
=
parser.ParseFile(fl,
"example.go"
, src, parser.AllErrors)
for
_, spec :
=
range
pl.Decls {
if
v, ok :
=
spec.(
*
ast.FuncDecl); ok {
ast.
Print
(nil, v)
}
}
}
|
得到的结果
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
|
0
*
ast.FuncDecl {
1
. Recv:
*
ast.FieldList {
2
. . Opening:
19
3
. .
List
: []
*
ast.Field (
len
=
1
) {
4
. . .
0
:
*
ast.Field {
5
. . . .
Type
:
*
ast.StarExpr {
6
. . . . . Star:
20
7
. . . . . X:
*
ast.Ident {
8
. . . . . . NamePos:
21
9
. . . . . . Name:
"int"
10
. . . . . }
11
. . . . }
12
. . . }
13
. . }
14
. . Closing:
24
15
. }
16
. Name:
*
ast.Ident {
17
. . NamePos:
26
18
. . Name:
"gogogo"
19
. }
20
.
Type
:
*
ast.FuncType {
21
. . Func:
14
22
. . Params:
*
ast.FieldList {
23
. . . Opening:
32
24
. . .
List
: []
*
ast.Field (
len
=
2
) {
25
. . . .
0
:
*
ast.Field {
26
. . . . . Names: []
*
ast.Ident (
len
=
2
) {
27
. . . . . .
0
:
*
ast.Ident {
28
. . . . . . . NamePos:
33
29
. . . . . . . Name:
"arg1"
30
. . . . . . . Obj:
*
ast.
Object
{
31
. . . . . . . . Kind: var
32
. . . . . . . . Name:
"arg1"
33
. . . . . . . . Decl:
*
(obj @
25
)
34
. . . . . . . }
35
. . . . . . }
36
. . . . . .
1
:
*
ast.Ident {
37
. . . . . . . NamePos:
39
38
. . . . . . . Name:
"arg2"
39
. . . . . . . Obj:
*
ast.
Object
{
40
. . . . . . . . Kind: var
41
. . . . . . . . Name:
"arg2"
42
. . . . . . . . Decl:
*
(obj @
25
)
43
. . . . . . . }
44
. . . . . . }
45
. . . . . }
46
. . . . .
Type
:
*
ast.Ident {
47
. . . . . . NamePos:
44
48
. . . . . . Name:
"int"
49
. . . . . }
50
. . . . }
51
. . . .
1
:
*
ast.Field {
52
. . . . . Names: []
*
ast.Ident (
len
=
1
) {
53
. . . . . .
0
:
*
ast.Ident {
54
. . . . . . . NamePos:
49
55
. . . . . . . Name:
"arg3"
56
. . . . . . . Obj:
*
ast.
Object
{
57
. . . . . . . . Kind: var
58
. . . . . . . . Name:
"arg3"
59
. . . . . . . . Decl:
*
(obj @
51
)
60
. . . . . . . }
61
. . . . . . }
62
. . . . . }
63
. . . . .
Type
:
*
ast.Ident {
64
. . . . . . NamePos:
54
65
. . . . . . Name:
"string"
66
. . . . . }
67
. . . . }
68
. . . }
69
. . . Closing:
60
70
. . }
71
. . Results:
*
ast.FieldList {
72
. . . Opening:
0
73
. . .
List
: []
*
ast.Field (
len
=
1
) {
74
. . . .
0
:
*
ast.Field {
75
. . . . .
Type
:
*
ast.Ident {
76
. . . . . . NamePos:
62
77
. . . . . . Name:
"int"
78
. . . . . }
79
. . . . }
80
. . . }
81
. . . Closing:
0
82
. . }
83
. }
84
. Body:
*
ast.BlockStmt {
85
. . Lbrace:
66
86
. .
List
: []ast.Stmt (
len
=
1
) {
87
. . .
0
:
*
ast.ReturnStmt {
88
. . . . Return:
68
89
. . . . Results: []ast.Expr (
len
=
1
) {
90
. . . . .
0
:
*
ast.BinaryExpr {
91
. . . . . . X:
*
ast.Ident {
92
. . . . . . . NamePos:
75
93
. . . . . . . Name:
"arg1"
94
. . . . . . . Obj:
*
(obj @
30
)
95
. . . . . . }
96
. . . . . . OpPos:
80
97
. . . . . . Op:
+
98
. . . . . . Y:
*
ast.Ident {
99
. . . . . . . NamePos:
82
100
. . . . . . . Name:
"arg2"
101
. . . . . . . Obj:
*
(obj @
39
)
102
. . . . . . }
103
. . . . . }
104
. . . . }
105
. . . }
106
. . }
107
. . Rbrace:
88
108
. }
109
}
|
下面来分析ast.BlockStmt,其结构如下所示。
|
1
2
3
4
5
6
|
/
/
A BlockStmt node represents a braced statement
list
.
BlockStmt struct {
Lbrace token.Pos
/
/
position of
"{"
List
[]Stmt
Rbrace token.Pos
/
/
position of
"}"
,
if
any
(may be absent due to syntax error)
}
|
ast.BlockStmt中包含块的起始位置,以及类型为ast.Stmt的切片。实质上ast.BlockStmt仅仅只是简单包装了[]ast.Stmt。
ast.Stmt是一个抽象类型的接口。函数体中的语句块构成的语法树和类型中的语法树结构很相似,但是语句的语法树最大的特点是可以循环递归定义,而类型的语法树不能递归定义自身(语义层面禁止)。
|
1
2
3
4
5
|
/
/
All
statement nodes implement the Stmt interface.
type
Stmt interface {
Node
stmtNode()
}
|
我们也可以查找Stmt为后缀的表达式类型。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
> go doc go
/
ast | grep Stmt
type
AssignStmt struct{ ... }
type
BadStmt struct{ ... }
type
BlockStmt struct{ ... }
type
BranchStmt struct{ ... }
type
DeclStmt struct{ ... }
type
DeferStmt struct{ ... }
type
EmptyStmt struct{ ... }
type
ExprStmt struct{ ... }
type
ForStmt struct{ ... }
type
GoStmt struct{ ... }
type
IfStmt struct{ ... }
type
IncDecStmt struct{ ... }
type
LabeledStmt struct{ ... }
type
RangeStmt struct{ ... }
type
ReturnStmt struct{ ... }
type
SelectStmt struct{ ... }
type
SendStmt struct{ ... }
type
Stmt interface{ ... }
type
SwitchStmt struct{ ... }
type
TypeSwitchStmt struct{ ... }
|
Pointer
Go语言指针类型的语法规范:
|
1
2
3
4
5
|
PointerType
=
"*"
BaseType .
BaseType
=
Type
.
Type
=
TypeName | TypeLit |
"("
Type
")"
.
...
|
在Go语言中,指针类型以星号*开头,后面是BaseType定义的类型表达式。从语法规范角度看,Go语言没有单独定义多级指针,只有一种指向BaseType类型的一级指针。但是PointerType又可以作为TypeLit类型面值被重新用作BaseType,这就产生了多级指针的语法。
首先来看一下一级指针的AST
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
func main() {
var src string
=
`package main
type
IntPtr
*
int
`
fl :
=
token.NewFileSet()
pl, _ :
=
parser.ParseFile(fl,
"example.go"
, src, parser.AllErrors)
for
_, spec :
=
range
pl.Decls {
if
v, ok :
=
spec.(
*
ast.GenDecl); ok {
ast.
Print
(nil, v)
}
}
}
|
其结果为:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
0
*
ast.GenDecl {
1
. TokPos:
14
2
. Tok:
type
3
. Lparen:
0
4
. Specs: []ast.Spec (
len
=
1
) {
5
. .
0
:
*
ast.TypeSpec {
6
. . . Name:
*
ast.Ident {
7
. . . . NamePos:
19
8
. . . . Name:
"IntPtr"
9
. . . . Obj:
*
ast.
Object
{
10
. . . . . Kind:
type
11
. . . . . Name:
"IntPtr"
12
. . . . . Decl:
*
(obj @
5
)
13
. . . . }
14
. . . }
15
. . . Assign:
0
16
. . .
Type
:
*
ast.StarExpr {
17
. . . . Star:
21
18
. . . . X:
*
ast.Ident {
19
. . . . . NamePos:
22
20
. . . . . Name:
"int"
21
. . . . }
22
. . . }
23
. . }
24
. }
25
. Rparen:
0
26
}
|
能看到指针所使用的类型为ast.StarExpr。其结构如下所示。
|
1
2
3
4
|
StarExpr struct {
Star token.Pos
/
/
position of
"*"
X Expr
/
/
operand
}
|
Star表示*所在的位置,X指向一个递归定义的类型表达式。
指针是一种天然递归定义的类型。我们可以再定义一个指向IntPtr类型的指针,即指向int的二级指针。
相同的办法得到type IntPtrPtr **int的AST:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
0
*
ast.GenDecl {
1
. TokPos:
14
2
. Tok:
type
3
. Lparen:
0
4
. Specs: []ast.Spec (
len
=
1
) {
5
. .
0
:
*
ast.TypeSpec {
6
. . . Name:
*
ast.Ident {
7
. . . . NamePos:
19
8
. . . . Name:
"IntPtrPtr"
9
. . . . Obj:
*
ast.
Object
{
10
. . . . . Kind:
type
11
. . . . . Name:
"IntPtrPtr"
12
. . . . . Decl:
*
(obj @
5
)
13
. . . . }
14
. . . }
15
. . . Assign:
0
16
. . .
Type
:
*
ast.StarExpr {
17
. . . . Star:
29
18
. . . . X:
*
ast.StarExpr {
19
. . . . . Star:
30
20
. . . . . X:
*
ast.Ident {
21
. . . . . . NamePos:
31
22
. . . . . . Name:
"int"
23
. . . . . }
24
. . . . }
25
. . . }
26
. . }
27
. }
28
. Rparen:
0
29
}
|
可以看到IntPtrPtr与IntPtr解析的差别在于嵌套了另一个ast.StarExpr,对于多级指针而言,其AST很像一个单向链表。其中X成员指向的是减一级指针的*ast.StarExpr结点,链表的尾结点是一个*ast.Ident标识符类型。
Array
在传统的C/C++中,数组是和指针近似等同的类型。在传递参数是我们可以通过传递标识符,即数组的首地址。但在Go中,我们传递标识符得到的却是传递参数的值拷贝。
其语法定义如下所示。
|
1
2
3
|
ArrayType
=
"["
ArrayLength
"]"
ElementType .
ArrayLength
=
Expression .
ElementType
=
Type
.
|
我们定义一个简单的数组
|
1
|
type
array [
10
]
int
|
其AST表现为:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
0
*
ast.GenDecl {
1
. TokPos:
14
2
. Tok:
type
3
. Lparen:
0
4
. Specs: []ast.Spec (
len
=
1
) {
5
. .
0
:
*
ast.TypeSpec {
6
. . . Name:
*
ast.Ident {
7
. . . . NamePos:
19
8
. . . . Name:
"array"
9
. . . . Obj:
*
ast.
Object
{
10
. . . . . Kind:
type
11
. . . . . Name:
"array"
12
. . . . . Decl:
*
(obj @
5
)
13
. . . . }
14
. . . }
15
. . . Assign:
0
16
. . .
Type
:
*
ast.ArrayType {
17
. . . . Lbrack:
25
18
. . . .
Len
:
*
ast.BasicLit {
19
. . . . . ValuePos:
26
20
. . . . . Kind:
INT
21
. . . . . Value:
"10"
22
. . . . }
23
. . . . Elt:
*
ast.Ident {
24
. . . . . NamePos:
29
25
. . . . . Name:
"int"
26
. . . . }
27
. . . }
28
. . }
29
. }
30
. Rparen:
0
31
}
|
其ast.TypeSpec.Type为ast.ArrayType,其结构如下所示。
|
1
2
3
4
5
|
ArrayType struct {
Lbrack token.Pos
/
/
position of
"["
Len
Expr
/
/
Ellipsis node
for
[...]T array types, nil
for
slice
types
Elt Expr
/
/
element
type
}
|
Len是一个表示数组长度的表达式,正如注释中所提到的,其表达式也可以是...表示从元素个数提取长度;数组的元素类型由Elt定义,其值对应一个类型的表达式。和指针类似,数组类型同样可以递归定义。因此我们有了二维数组甚至多维数组。
我们定义一个二维数组:
|
1
|
type
arrays [
4
][
5
]
int
|
其AST表现如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
0
*
ast.GenDecl {
1
. TokPos:
14
2
. Tok:
type
3
. Lparen:
0
4
. Specs: []ast.Spec (
len
=
1
) {
5
. .
0
:
*
ast.TypeSpec {
6
. . . Name:
*
ast.Ident {
7
. . . . NamePos:
19
8
. . . . Name:
"arrays"
9
. . . . Obj:
*
ast.
Object
{
10
. . . . . Kind:
type
11
. . . . . Name:
"arrays"
12
. . . . . Decl:
*
(obj @
5
)
13
. . . . }
14
. . . }
15
. . . Assign:
0
16
. . .
Type
:
*
ast.ArrayType {
17
. . . . Lbrack:
26
18
. . . .
Len
:
*
ast.BasicLit {
19
. . . . . ValuePos:
27
20
. . . . . Kind:
INT
21
. . . . . Value:
"4"
22
. . . . }
23
. . . . Elt:
*
ast.ArrayType {
24
. . . . . Lbrack:
29
25
. . . . .
Len
:
*
ast.BasicLit {
26
. . . . . . ValuePos:
30
27
. . . . . . Kind:
INT
28
. . . . . . Value:
"5"
29
. . . . . }
30
. . . . . Elt:
*
ast.Ident {
31
. . . . . . NamePos:
32
32
. . . . . . Name:
"int"
33
. . . . . }
34
. . . . }
35
. . . }
36
. . }
37
. }
38
. Rparen:
0
39
}
|
ast.TypeSpec.Type.Elt.Elt不再是ast.Ident而是嵌套了一个ast.ArrayType。由此可见,数组类型的AST也可以类似的视作一个单向链表结构。后N-1维的数组的元素是*ast.ArrayType类型,最后的尾结点对应一个*ast.Ident标识符(也可以是其它面值类型)。
Slice
Go语言中切片是简化的数组,从其语法定义上来看,切片与数组的区别仅仅在于切片省略了数组的长度。其语法定义如下:
|
1
2
|
SliceType
=
"["
"]"
ElementType .
ElementType
=
Type
.
|
以简单的切片为例:
|
1
|
type
s []
int
|
其AST表现如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
0
*
ast.GenDecl {
1
. TokPos:
14
2
. Tok:
type
3
. Lparen:
0
4
. Specs: []ast.Spec (
len
=
1
) {
5
. .
0
:
*
ast.TypeSpec {
6
. . . Name:
*
ast.Ident {
7
. . . . NamePos:
19
8
. . . . Name:
"s"
9
. . . . Obj:
*
ast.
Object
{
10
. . . . . Kind:
type
11
. . . . . Name:
"s"
12
. . . . . Decl:
*
(obj @
5
)
13
. . . . }
14
. . . }
15
. . . Assign:
0
16
. . .
Type
:
*
ast.ArrayType {
17
. . . . Lbrack:
21
18
. . . . Elt:
*
ast.Ident {
19
. . . . . NamePos:
23
20
. . . . . Name:
"int"
21
. . . . }
22
. . . }
23
. . }
24
. }
25
. Rparen:
0
26
}
|
通过AST,我们能看到切片与数组的区别在于,在切片中其ast.ArrayType.Len的值变为了nil,即切片的Len为nil,数组的Len为一个基本面值。
Others
Go AST的组成远不止如此,其中还有大量的复合类型,复合面值、复合表达式、语句块和语句等未曾提及释义。但相信通过动手实践,我们的认知并不会止步于此。
AST explorer
Go是静态语言,我们必须将其编译而后执行,这意味着我们无法实时得到我们想要的结果。这对我们使用Go AST进行调试、分析造成了阻碍。
是一个AST可视化工具网站,其支持对多个语言进行解析,Go也不例外。通过AST explorer,我们可以快速了解其AST组成,方便我们进行调试、分析。
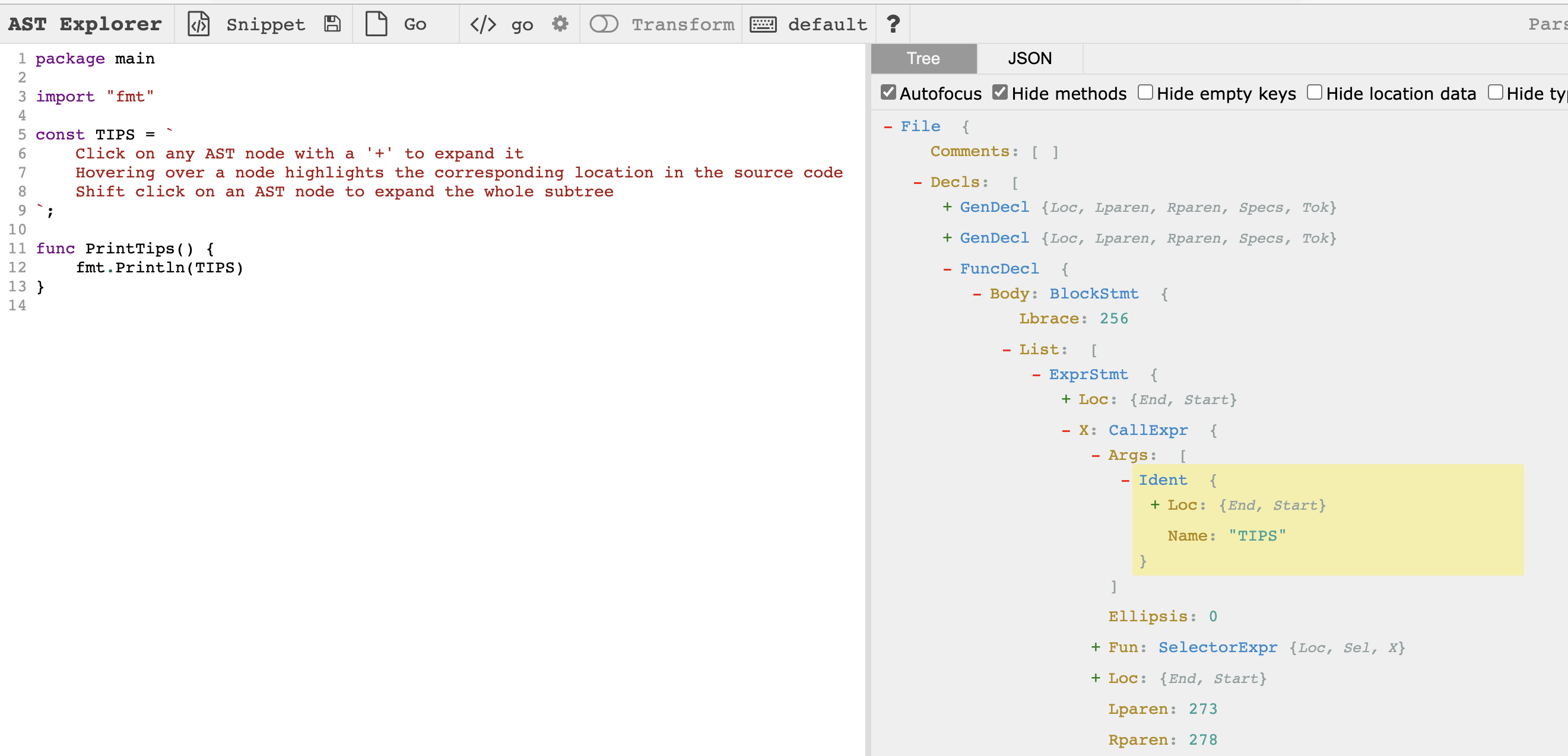
网鼎杯2022某赛道 Handmake
介绍了那么多关于Go AST,下面就是实际的运用。
拿到的文件是一个go源码,其对标识符、语句等进行了大量混淆。
我们从程序入口着手分析。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
func main() {
var nFAzj, CuSkl string
jjxXf :
=
[]byte{
37
,
73
,
151
,
135
,
65
,
58
,
241
,
90
,
33
,
86
,
71
,
41
,
102
,
241
,
213
,
234
,
67
,
144
,
139
,
20
,
112
,
150
,
41
,
7
,
158
,
251
,
167
,
249
,
24
,
129
,
72
,
64
,
83
,
142
,
166
,
236
,
67
,
18
,
211
,
100
,
91
,
38
,
83
,
147
,
40
,
78
,
239
,
113
,
232
,
83
,
227
,
47
,
192
,
227
,
70
,
167
,
201
,
249
,
156
,
101
,
216
,
159
,
116
,
210
,
152
,
234
,
38
,
145
,
198
,
58
,
24
,
183
,
72
,
143
,
136
,
234
,
246
}
KdlaH :
=
[]byte{
191
,
140
,
114
,
245
,
142
,
55
,
190
,
30
,
161
,
18
,
200
,
7
,
21
,
59
,
17
,
44
,
34
,
181
,
109
,
116
,
146
,
145
,
189
,
68
,
142
,
113
,
0
,
33
,
46
,
184
,
21
,
33
,
66
,
99
,
124
,
167
,
201
,
88
,
133
,
20
,
211
,
67
,
133
,
250
,
62
,
28
,
138
,
229
,
105
,
102
,
125
,
124
,
208
,
180
,
50
,
146
,
67
,
39
,
55
,
240
,
239
,
203
,
230
,
142
,
20
,
90
,
205
,
27
,
128
,
136
,
151
,
140
,
222
,
92
,
152
,
1
,
222
,
138
,
254
,
246
,
223
,
224
,
236
,
33
,
60
,
170
,
189
,
77
,
124
,
72
,
135
,
46
,
235
,
17
,
32
,
28
,
245
}
fmt.
Print
(MPyt9GWTRfAFNvb1(jjxXf))
fmt.Scanf(
"%20s"
, &nFAzj)
fmt.
Print
(kZ2BFvOxepd5ALDR(KdlaH))
fmt.Scanf(
"%20s"
, &CuSkl)
vNvUO :
=
GwSqNHQ7dPXpIG64(nFAzj)
YJCya :
=
""
mvOxK :
=
YI3z8ZxOKhfLmTPC(CuSkl)
if
mvOxK !
=
nil {
YJCya
=
mvOxK()
}
if
YJCya !
=
"
" && vNvUO != "
" {
fmt.Printf(
"flag{%s%s}\n"
, vNvUO, YJCya)
}
}
|
此时我们有两种选择了解程序逻辑:
- 编译源文件,通过编译器优化得到一个化简的二进制文件而后运行、分析。
- 摘取片段代码,而后执行片段。
目前为止,两者都是可行的。但前者需要大量的系统资源,并需要一定时间;后者需要考虑到函数间的引用链。
不管何种方式,我们都能得到fmt.Print打印的明文内容:
|
1
2
|
Input
the first function, which has
6
parameters
and
the third named gLIhR:
Input
the second function, which has
3
callers
and
invokes the function named cHZv5op8rOmlAkb6:
|
显而易见,出题人并不希望我们通过编译优化的方式解题,而是通过分析源代码得到信息。
到这里,我们就可以使用Go AST来帮助我们分析得到这类信息。
Part 1
首先考虑解决第一个问题:Input the first function, which has 6 parameters and the third named gLIhR:
提取出要求:
- 函数有6个参数
- 第3个参数名称为
gLIhR
通过ast.Inspect遍历函数定义节点,我们可以迅速找到对应的函数名。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
func solve_part1(n
*
ast.
File
) {
ast.Inspect(n, func(node ast.Node)
bool
{
switch x :
=
node.(
type
) {
case
*
ast.FuncDecl:
paramLen :
=
0
funcName :
=
x.Name.Name
thirdParamName :
=
""
for
_, param :
=
range
x.
Type
.Params.
List
{
for
_, name :
=
range
param.Names {
paramLen
+
=
1
if
paramLen
=
=
3
{
thirdParamName
=
name.Name
}
}
}
if
paramLen
=
=
6
&& thirdParamName
=
=
"gLIhR"
{
fmt.Println(
"find part 1:"
, funcName)
}
}
return
true
})
}
func main() {
src, _ :
=
os.ReadFile(
"challenge.go"
)
fl :
=
token.NewFileSet()
pl, _ :
=
parser.ParseFile(fl,
"challenge.go"
, src, parser.AllErrors)
solve_part1(pl)
}
/
/
find part1: ZlXDJkH3OZN4Mayd
|
由此,我们得到了第一个答案:ZlXDJkH3OZN4Mayd
Part 2
第二个问题:Input the second function, which has 3 callers and invokes the function named cHZv5op8rOmlAkb6:
提取出要求:
- 函数拥有三个调用者
- 并且函数调用了
cHZv5op8rOmlAkb6方法
由于Go AST没有设计直接获取引用的API,我们需要手动实现一个Visitor获取引用信息。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
|
func solve_part2(n
*
ast.
File
) {
type
Info struct {
start
int
end
int
referenceFuncs
*
[]string
references
int
/
/
被引用的次数
}
InfoArray :
=
map
[string]Info{}
/
/
初始化函数
map
ast.Inspect(n, func(node ast.Node)
bool
{
switch x :
=
node.(
type
) {
case
*
ast.FuncDecl:
funcName :
=
x.Name.Name
info :
=
Info{references:
0
, referenceFuncs: new([]string), start:
int
(x.Body.Lbrace), end:
int
(x.Body.Rbrace)}
InfoArray[funcName]
=
info
}
return
true
})
/
/
获取调用信息
ast.Inspect(n, func(node ast.Node)
bool
{
switch x :
=
node.(
type
) {
case
*
ast.CallExpr:
if
ident, ok :
=
x.Fun.(
*
ast.Ident); ok {
funcName :
=
""
callName :
=
ident.Name
if
callName
=
=
"string"
|| callName
=
=
"make"
{
return
true
}
var info Info
/
/
寻找调用callFunc的函数
for
key, info :
=
range
InfoArray {
if
info.start <
int
(ident.Pos()) && info.end >
int
(ident.End()) {
funcName
=
key
}
}
/
/
set
references
info
=
InfoArray[callName]
info.references
+
+
InfoArray[callName]
=
info
/
/
set
referenceFuncs
*
InfoArray[funcName].referenceFuncs
=
append(
*
InfoArray[funcName].referenceFuncs, callName)
}
}
return
true
})
/
/
搜索符合条件的函数
for
key, info :
=
range
InfoArray {
if
info.references
=
=
3
{
for
_, s :
=
range
*
info.referenceFuncs {
if
s
=
=
"cHZv5op8rOmlAkb6"
{
fmt.Println(
"find part 2:"
, key)
}
}
}
}
}
func main() {
src, _ :
=
os.ReadFile(
"challenge.go"
)
fl :
=
token.NewFileSet()
pl, _ :
=
parser.ParseFile(fl,
"challenge.go"
, src, parser.AllErrors)
solve_part2(pl)
}
/
/
find part
2
: UhnCm82SDGE0zLYO
|
最终得到了第二部分的答案:UhnCm82SDGE0zLYO
最后,我们只需要将代码片段截取,执行程序逻辑就能得到正确的答案。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
func GwSqNHQ7dPXpIG64(cJPTR string) string {
YrXQd :
=
hex
.EncodeToString([]byte(cJPTR))
return
fmt.Sprintf(
"%c%c%c%c%c%c%c%c%c%c%c%c%c%c%c%c"
, YrXQd[
22
], YrXQd[
19
], YrXQd[
20
], YrXQd[
21
], YrXQd[
28
], YrXQd[
10
], YrXQd[
20
], YrXQd[
7
], YrXQd[
29
], YrXQd[
14
], YrXQd[
0
], YrXQd[
18
], YrXQd[
3
], YrXQd[
24
], YrXQd[
27
], YrXQd[
31
])
}
func cHZv5op8rOmlAkb6(HIGXt []byte, VGvny string, ZOkKV string, eU0uD string) string {
QTk4l :
=
make([]byte,
20
)
Ek08m :
=
[
16
]byte{
167
,
238
,
45
,
89
,
160
,
95
,
34
,
175
,
158
,
169
,
20
,
217
,
68
,
137
,
231
,
54
}
for
i :
=
0
; i <
16
; i
+
+
{
QTk4l[i]
+
=
Ek08m[i] ^ HIGXt[i]
}
return
string(QTk4l)
}
func UhnCm82SDGE0zLYO() string {
SythK :
=
[]byte{
159
,
141
,
72
,
106
,
196
,
62
,
16
,
205
,
170
,
159
,
36
,
232
,
125
,
239
,
208
,
3
}
var Vw2mJ, Nij87, zVclR string
return
cHZv5op8rOmlAkb6(SythK, Vw2mJ, Nij87, zVclR)
}
func getflag() {
nFAzj :
=
"ZlXDJkH3OZN4Mayd"
vNvUO :
=
GwSqNHQ7dPXpIG64(nFAzj)
YJCya :
=
UhnCm82SDGE0zLYO()
fmt.Printf(
"flag{%s%s}\n"
, vNvUO, YJCya)
}
|
总结
本文简要介绍了Go AST的结构以及组成,虽然其中仍有大量未列出的表达式类型、语句类型、复杂类型等,但通过这篇文章的梳理以及介绍,我们能够了解到如何了解Go AST,正所谓授人以鱼不如授人以渔,只有学会如何学习Go AST,才能真正了解到Go AST的魅力。
而对于例举题目而言,其难度仍有拓展空间,例如利用大量的无意义函数引用,膨胀源码等操作,使分析难度加大,将暴力分析的可行性排除在外,不乏为一个较好的出题方向。
Reference
更多【 Go AST 浅析】相关视频教程:www.yxfzedu.com
相关文章推荐
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全 CTF对抗 IOS安全
- 2-wibu软授权(三) - Android安全 CTF对抗 IOS安全
- 软件逆向-wibu软授权(二) - Android安全 CTF对抗 IOS安全
- 软件逆向-wibu软授权(一) - Android安全 CTF对抗 IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全 CTF对抗 IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全 CTF对抗 IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全 CTF对抗 IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全 CTF对抗 IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全 CTF对抗 IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全 CTF对抗 IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全 CTF对抗 IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全 CTF对抗 IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全 CTF对抗 IOS安全
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全 CTF对抗 IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全 CTF对抗 IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全 CTF对抗 IOS安全
- 二进制漏洞-Windows内核提权漏洞CVE-2018-8120分析 - Android安全 CTF对抗 IOS安全
- CTF对抗-Hack-A-Sat 2020预选赛 beckley - Android安全 CTF对抗 IOS安全
- CTF对抗-]2022KCTF秋季赛 第十题 两袖清风 - Android安全 CTF对抗 IOS安全
- CTF对抗-kctf2022 秋季赛 第十题 两袖清风 wp - Android安全 CTF对抗 IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com

接各种驱动定制如:游戏读写驱动,软件内存保护,防止调试等功能定制。
出租读写驱动,调试驱动,无痕注入支持各种游戏。
邮箱:service@yxfzedu.com
QQ:851920120
特别说明:不接游戏数据分析,外挂编写,登陆协议等类似业务。