该议题阐明了当前恶意软件分析方法面临的问题,针对分析难点和分析需求详细说明了借助大模型技术提高恶意软件分析效率及分析结果等方面的实践。
一起来回顾下 尹斌&刘璐 在SDC2024 上发表的议题演讲:《大模型技术在恶意软件分析中的实践》

(左)尹斌:奇安信技术研究院安全研究员
(右)刘璐:奇安信技术研究院安全研究员
背景介绍
众所周知,目前工业界和学术界常用的恶意软件分析工具有很多种,针对不同的目标对象有特定的分析工具,例如,有二进制分析工具、流量分析工具、内存转储分析工具等。这些分析工具主要分为两大类,一类是通用分析方法,另一类是机器学习方法。
通用分析方法主要包含以下4种:
静态分析:在不运行程序的状态下,对恶意软件进行分析。通常借助各类分析工具对恶意软件进行脱壳处理、逆向分析、特征提取等。
动态分析:在安全可控环境下运行恶意软件,智能触发软件恶意行为。通常使用沙箱、蜜罐等工具,观察软件执行流程。
动静结合:将静态分析方法和动态行为分析结合起来,更充分地鉴定软件恶意行为。例如,使用白加黑手段实施恶意行为的软件,可结合静态提取的证书信息和动态观察到的软件行为,综合鉴定软件的恶意性。
内存取证:将恶意软件运行时的内存数据转储为内存映像,利用分析工具从内存映像中查找恶意行为。
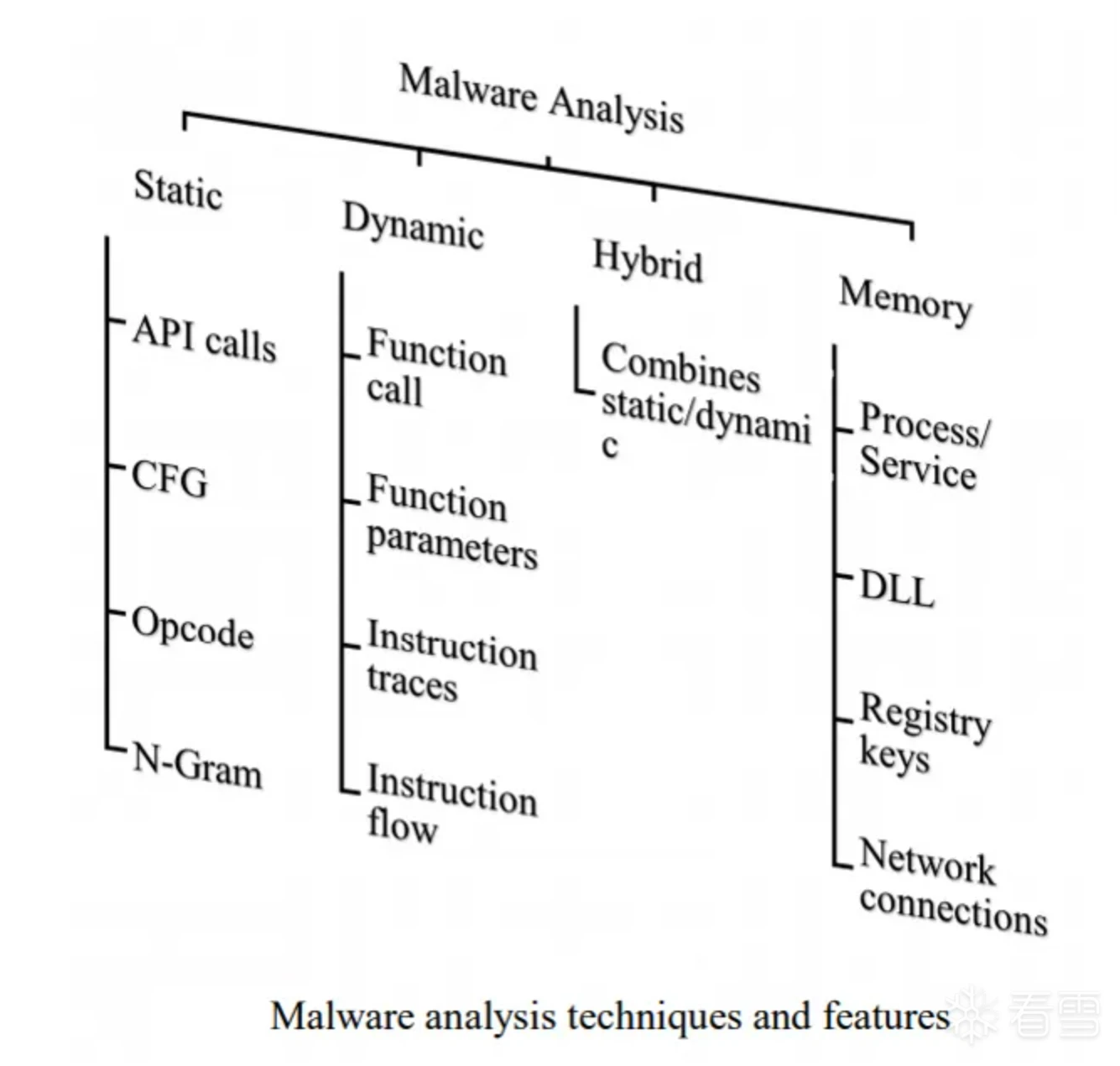
通用分析方法的优点是检出率高、可解释性强,但它非常依赖人工。因此,借助机器学习来分担人工消耗就形成一种趋势,将通用分析数据投入机器学习进行训练、识别,达到自动化样本分类、同源分析等目的。
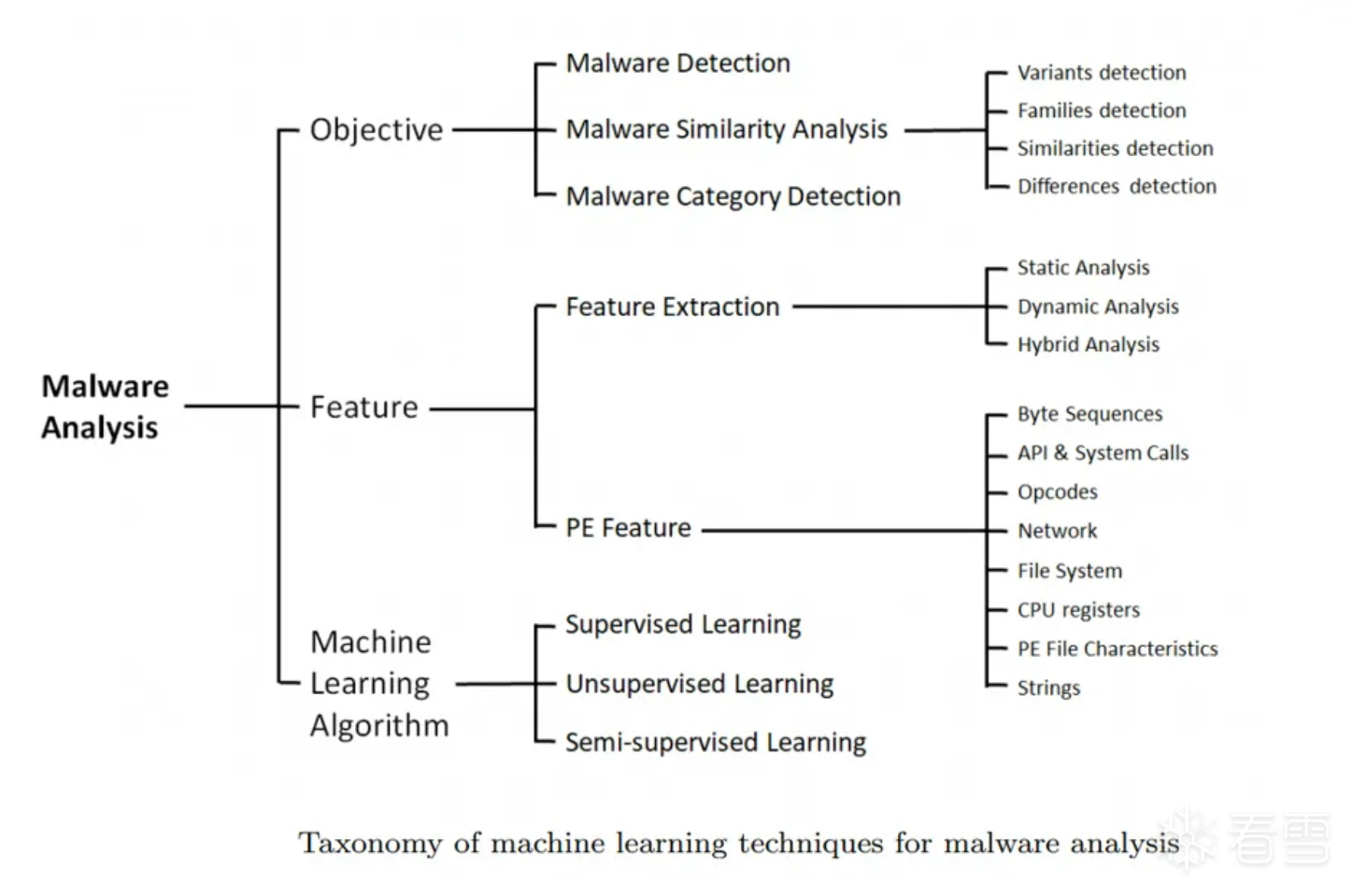
然而机器学习在工业界运用的越广,暴露的问题越多。在样本分析领域机器学习所面临的典型问题是误报和可解释性差,在海量样本分析的情形下,1%的误报率也将是用户难以接受的数字,而且机器学习对于样本危险行为或所属家族的判断很难解释清楚。
基于上述分析方法,我们总结出当前恶意软件分析领域存在以下问题:
技术方案
针对以上问题,星图实验室提出了大模型技术应用于恶意软件分析的架构设计。整体架构分为3层,如下图所示。首先通过模型微调获取一个大模型基座,然后搜集数据进行构造形成数据集,最后基于向量数据库实现对样本不同维度信息的语义检索。利用该架构实现对样本的深度疏理,达到智能问答和用户意图识别的精准易用目的。
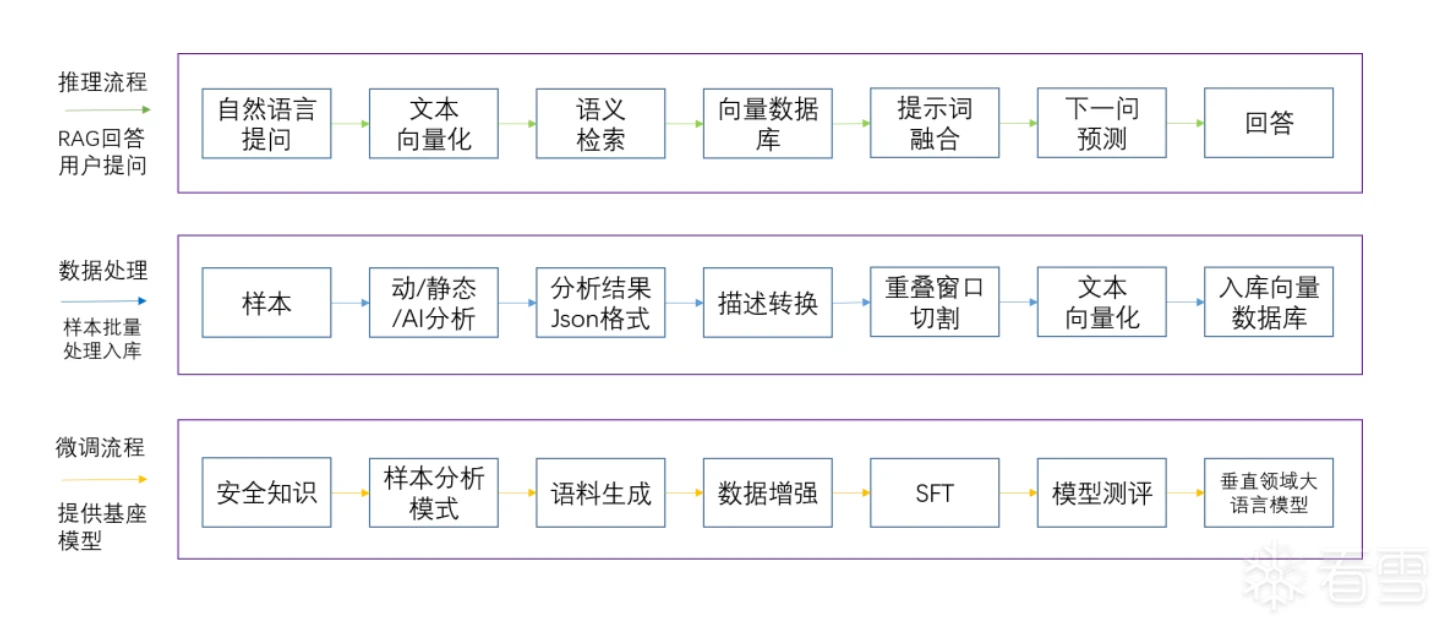
大模型微调
(1)大模型选型
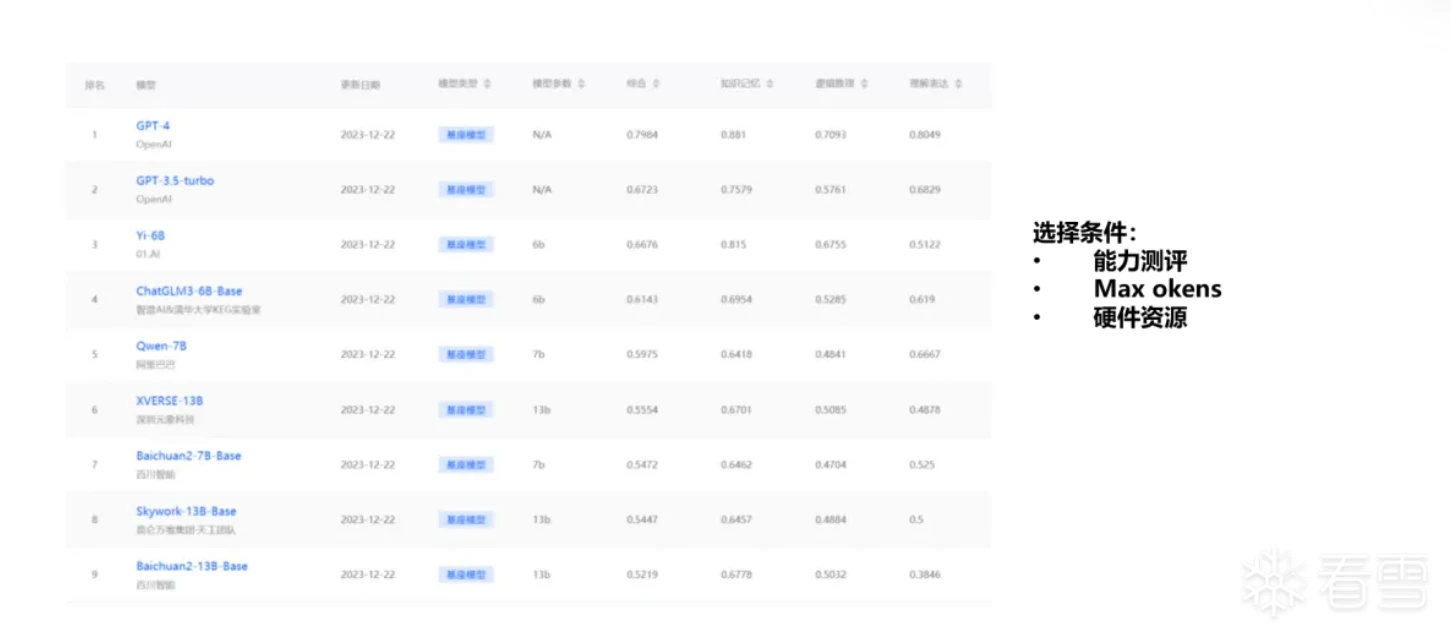
要让大模型学会分析样本,就需要去训练它,这就需要预训练出一个大模型,在此基础上进行微调达到自主分析的目的。从Open AI科学家的介绍可知,预训练大模型成本极高,通常需要千卡以上的GPU集群,这在工程实施上非常困难。因此,我们选择从基座大模型的榜单中挑选出与样本分析领域比较贴近且能力比较强的模型,结合要解决的任务tokens和实际的硬件资源确定最终的基座模型,本次实验选择的基座模型是chatglm3-6b-32k。
(2)构造数据集
有了基座大模型,接下来要构造微调的数据集,简单讲就是做指令遵循,一般是一问一答式的数据。我们构造的第一阶段的数据集是安全领域的知识,要让大模型学会和样本分析相关的一些基础知识,包括APT组织、漏洞信息和情报信息等。初始数据内容不满足指令微调一问一答的格式,需要对这些数据进行解析转换,再对构造出的数据进行人工审计,确认数据集达到理想效果。
例如,我们将从沙箱分析样本和爬虫获取的数据进行格式化后,再经过人工审计筛选出高质量数据构造为第一阶段数据集。
第二阶段是构造让大模型学会推理的数据集,有了这种数据的训练模型,就能够结合上述提到的各种分析工具和分析方法所检测出来的行为,做进一步的推理了。例如,大模型可以根据样本自身的行为推理出提权过程中样本实施的高危行为等。所以通过这种推理类的数据集以及知识类的数据集的训练样本,就能够具备这些基础的推理能力,即垂直领域的推理能力。
例如,从样本动态行为中识别出关键行为,根据行为关联人工推理出样本意图,进而构造出第二阶段的数据集。
(3)选择微调方法
选择微调方法,首先是模型微调,我们采用的是一个国产化的微调框架叫LLaMA-Factory,它支持非常多的模型,也支持非常多主流的微调和对齐的方法。
在微调的时候要注意微调的效率,在保持大模型学会垂直领域的分析能力的前提下,保证它不会灾难遗忘,不会遗忘掉它的基础能力,所以,我们使用的是LoRA和FP16半精度微调的方式,它能够在保持模型的准确性和模型原有的基座能力的前提下,快速短时微调出一个比较好的效果。在微调的过程当中,需要设置很多的超参数和参数,这里简单给大家分享几个比较重要的经验:
调参可以采用粗调和细调相结合的方式,先粗略做网格搜索,确定一个比较理想的区间再进行细调,能节约时间;
模型微调可能是持续多天的任务,不能等到最后一天再进行测评,而是需要每隔一些steps就把微调好的模型dump出来及时测评;
模型微调过程中会出现因服务器不稳定等情况导致微调终止,如果终止后从头再微调一遍就太耗时了,所以可以设置resume_from_checkpoint等参数,从某个终止点接着往下进行微调。
模型测评时既要考虑loss收敛和使用传统的ROUGE等指标进行测评,也要考虑借助大模型加评分规则的打分方式,结合人工审计进行最终打分。
(4)微调效果
大模型经过微调后,能够从直接描述样本行为递进为在样本行为基础上推理样本行为背后意图:

(5)实际应用
上述训练大模型输入的数据都是一些文本信息,换成二进制是否可行呢?针对这一想法,我们做了实际验证,如果直接把二进制输入给像GPT-4或者GPT-4o这一系列模型得到的效果是不好的,但是可以把模型在二进制上做一些微调达到较好的效果。
我们使用上述类似的基座模型和完全相同的微调思路参加了中国电子协会主办的大模型微调比赛,把Pcap包里面的二进制和相关筛选统计特征,直接对大模型进行推理,它在做44个类别的流量分类当中,F1值也是能达到零点九几的,而且在经过微调以后,大模型对二进制的认识能力也会逐步增强。
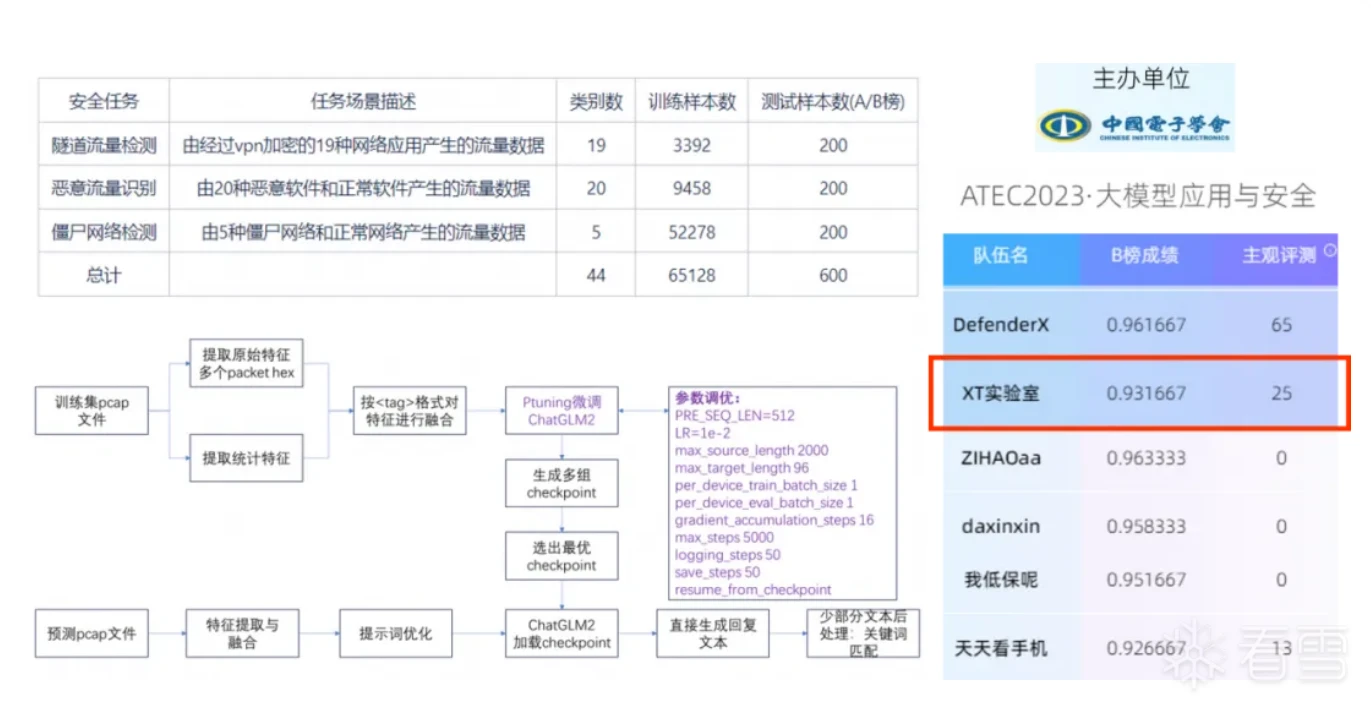
数据处理
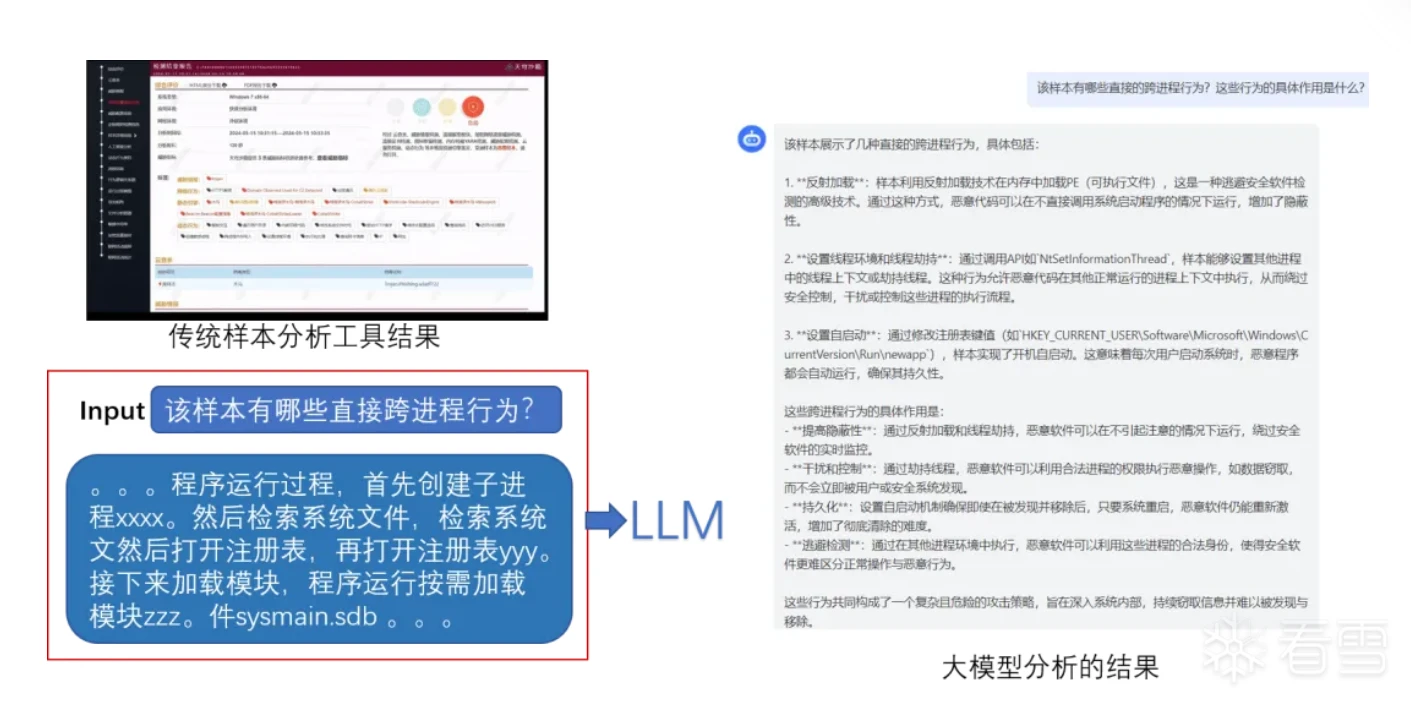
有了微调的基座模型,怎么样能够让它针对特定的样本做分析呢?那就需要对数据做一些特殊的处理,让大模型能够更好的理解。主要操作是描述转换和LLM润色,因为LLM难以直接理解分析工具给出的元数据,而且不同分析工具所使用的字段命名也不统一,描述转换就是将各类软件分析工具产生的元数据的key和value描述清楚,经过转换模板形成一段文字,利用大模型对自然语言的理解和推理能力,再加上LLM润色调整,这样就会输出用户更容易理解的文本信息。
RAG流程
传统分析工具的分析结果在经过描述转换后,大模型已经能够进行较好的NLP问答,但无法做到多样本关联分析,所以我们决定引入RAG,这样不仅可以实现多样本关联分析,甚至可以结合情报信息进行更深入的分析。
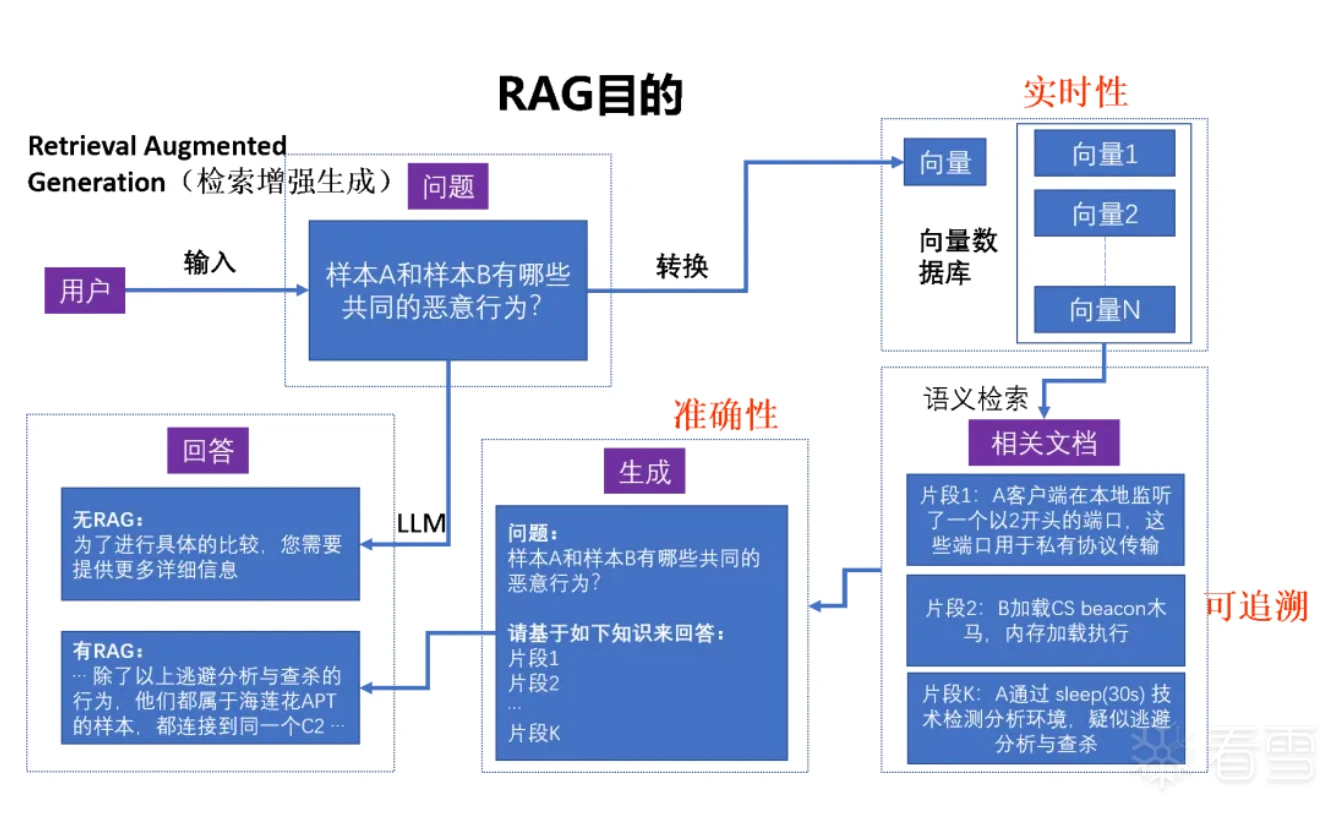
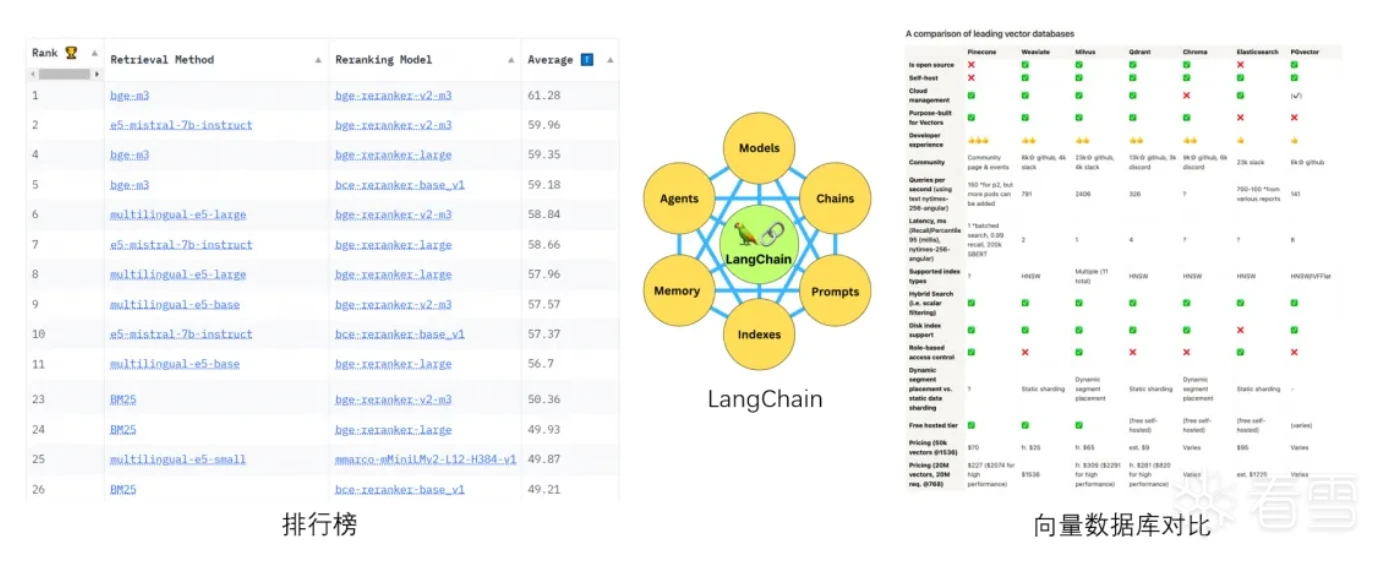
在对RAG组件进行选型时,我们参考了MTEB榜单上的组件排名,选择了bge-m3。大模型整体开发基础使用langchain,langchain有自己的智能体,对大模型调用兼容性强,适合我们的业务开发。向量数据库选择milvus,根据已有的应用经验,milvus在工程化和海量数据并发处理方面表现比较好。
恶意软件分析样例
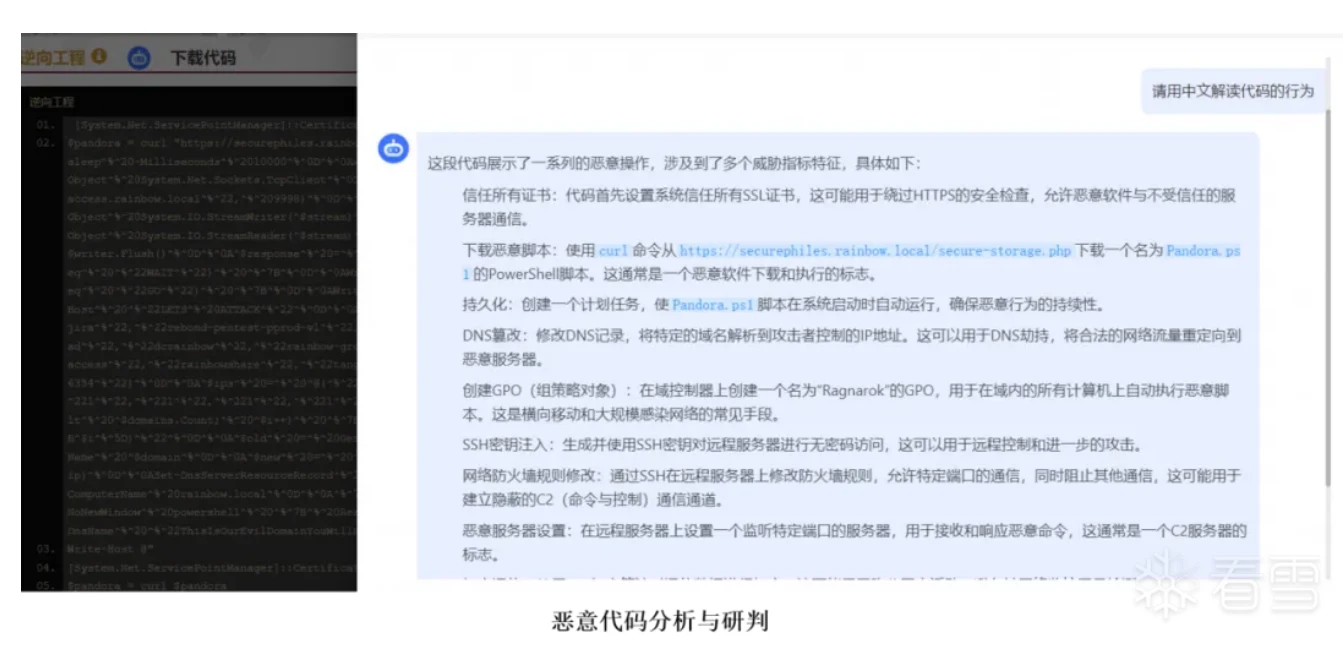
(1)代码解读
经过微调后的大模型能够直接对代码进行解读,我们将一些恶意或者非恶意的脚本代码输入给大模型后,它可以分析出代码块中比较关键的恶意行为。
(2)多Agent同源分析
样本同源分析比较常用的方法包括基因分析、相似性分析、关联分析、家族分类、YARA规则等等,以及现在有了大模型以后直接在搜索引擎搜索,但是这些分析方式效率不高。
为了提高效率和准确性,我们采用多Agent组合的方式,利用ReAct Agent在执行任务时让模型去做推理和行动,理解上下文后去推理、规划、执行反馈和迭代,输出比较可信的结果。

多Agent之间通过Planner做计划设计,当输入样本进行同源分析时,Planner会计划第一步应该去看什么数据库,第二步应该去找什么信息,然后再把这些计划交给SAagent去做执行。执行过程中SAagent调用同源分析工具获取分析结果,将分析结果交由SAReviewer判断结果是否准确可靠,如果结果正确无误,就会终止并给出结果。如果SAReviewer判断结果有问题,则交由SAReplaner进行重新规划。从上图可以看出,Agent之间能进行交互,在执行任务时结合推理和行动两方面对上下文进行理解,并通过推理、规划、执行、反馈和迭代,给出准确结果。
研究启发
在大模型框架应用于恶意软件分析的实践过程中,我们将遇到的问题和解决方式总结如下:
(1)基座LLM样本分析能力弱
开源或商业基座模型一般在专业垂直领域上能力较弱,为了提高模型能力,需要进行LLM微调。同时为了提高模型的可解释性,需要传统分析工具辅助,例如,样本源码和逆向后的代码等,经过描述转换后输入给大模型进行分析。微调过程中需要构建大量高质量数据集。
(2)难以做到:实时性+准确性+可追溯
任何一个大模型的知识储备都具有滞后性,例如,GPT-4的训练数据集只到2023年12月,2023年12月以后的信息它就不认识了,难以做到实时准确。借助RAG来补充最新知识库,就能提高整体结果的实时性,也能降低幻觉来提高答案的准确性。对模型的输出做引用标注,就能知道模型回复内容的来源,做到结果可追溯。
(3)整体自动化分析能力弱
在基础模型上做了微调后,大模型的自动化分析能力也是并不是很强,所以为了进一步提高它的自动化分析能力,用现有框架做工具调用,例如使用RAG和多个Agent组合的方式,用参数量比较小的模型就能做到比较好的效果。
(4)RAG问答不够准确
为了提升大模型的准确性,我们采用了多种方式进行优化。在文本分块时根据语义信息使用不同的长度切块,相同的块必须要有相类似的语义,必须有相同分析工具所分析出来的结果,且同一个块要保证它的信息完整。切出来的基础块做总结或关键词提取后变成小块,分别存储到不同的数据库中,检索时就可以用多种不同的检索方式做多路召回,这样能够检索到更丰富的数据,提高模型的表现能力。语义检索上的不足,也可以对Embedding模型做微调来改进。
参考
(1)https://core.ac.uk/download/pdf/325990564.pdf
(2)https://arxiv.org/pdf/1710.08189
(3)https://community.aws/content/2f1mRXuakNO22izRKDVNRazzxhb/how-to-use-retrieval-augmented-generation-rag-for-go-applications
(4)https://www.comet.com/site/blog/advanced-rag-algorithms-optimize-retrieval/
(5)https://x.com/qloog/status/1792546826908020967
(6)https://huggingface.co/spaces/AIR-Bench/leaderboard
(7)https://neurohive.io/en/news/microsoft-autogen-a-framework-for-configuring-llm-agents/
天穹沙箱地址:https://sandbox.qianxin.com
