那么,就来看看基于生成的boofuzz吧,虽然后面实现了持续生成的方案,但没有任何反馈调整变异机制,所以其实还是基于生成的
基于生成和基于变异的模糊测试区别在于,
基于生成的方法一次性生成所有样例,在生成初始输入后不会根据输入继续变动,实现起来很简单,无需插桩等;
而基于变异的方法则会一直运行,根据现有结果,不断地修改已有输入,可以说基于变异的模糊测试更为灵活和有效。
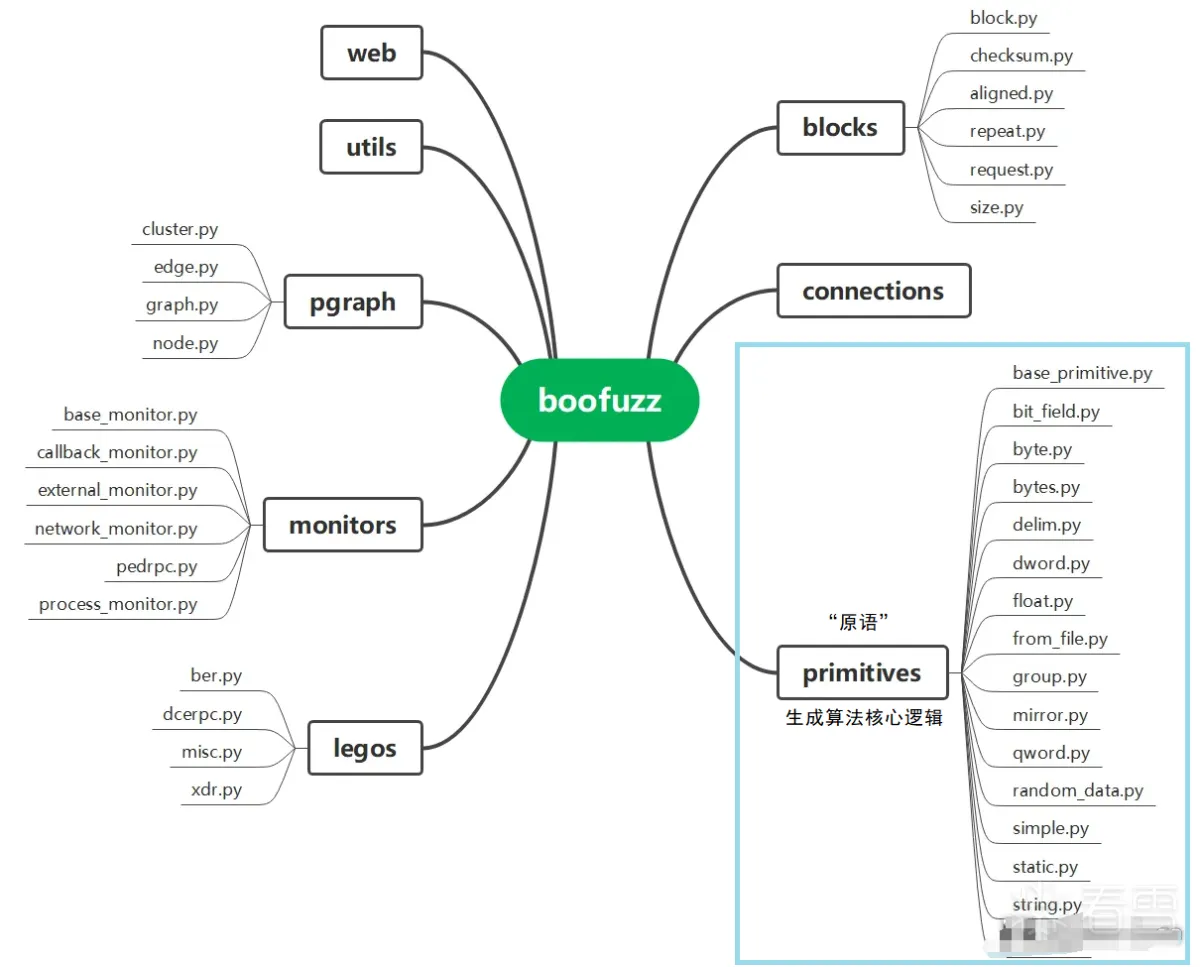
boofuzz目前的大致架构
本文基于boofuzz 0.4.2代码进行其变异算法的分析,为了对比前篇afl、afl++的变异算法的优异,暂且不关注boofuzz的网络请求、线程调度之类的代码,重点还是怎么生成、变异、靠什么引导的。即下图蓝框包含部分
直观感受:boofuzz脚本案例
首先直观感受一下boofuzz是怎么回事,来看一个简单的boofuzz脚本的一部分,比如想要fuzz这个数据包的特殊字段:
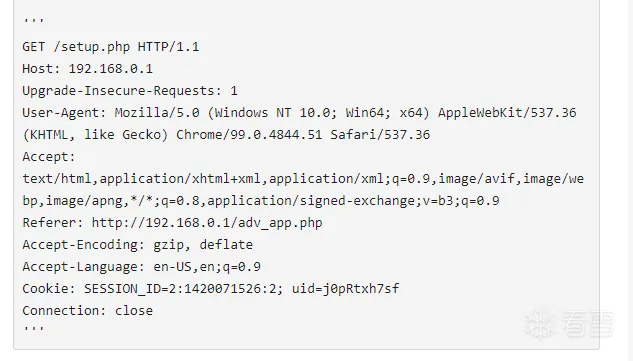

直观地看有什么感受?会觉得以上的代码其实就是把一个数据包请求拆出来好多块了,然后除去static静态值部分,实现了对SESSION_ID、uid的fuzz。而且大多数的地方都是static的,表示在测试样例的生成过程中照搬就好,不会进行改动
那么,s_string发生了什么?还有什么类似的生成方式?接下来尝试跟着用户手册和实现代码看看
测试样例的生成分为以下几种,实现代码位于boofuzz/primitives下
在这里要引入一个概念——boofuzz原语。诸如上面示例的s_string、s_byte、s_dword、s_static等,其实就是boofuzz的原语。查看其中的实现,就可以知道boofuzz是怎么对数据进行生成的。
python前置知识
python真的好灵活啊omg,好多“语法糖”,来尝一下吧
需要了解一下python迭代器、生成器以及装饰器的知识,因为boofuzz的代码实现用到了
关于python迭代器、生成器、装饰器可以看这篇总结:)比较详细
https://stonewiki.su-cvestone.cn/zh/program/basement/pyhon#%E8%BF%AD%E4%BB%A3%E5%99%A8
迭代器(Iterator)
Iterator(迭代器)对象是一个数据流,这一概念需要与list区分开,它们的区别有:
Iterator对象可以被不断使用next()函数进行下一个数据的返回,且只有当下一个数据被请求时才会进行计算,故与list相比,其具备“惰性”
但是Iterator对象理论上可以无限返回下一个数值,而list显然不可以,当然,如果Iterator没有数据时,会抛出StopIteration错误
一个简单的案例如下:
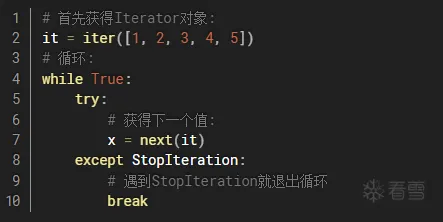
预先定义了一个Iterator对象,然后在循环中不断调用next获取下一个值,达到迭代1,2,3,4,5的效果
总的来说,迭代器仅仅只能通过next来导出下一个值
生成器(Generator)
创建一个简单的生成器,仅需将列表的[]包裹方式,改为()包裹方式即可
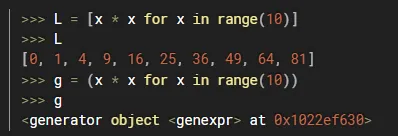
然后,就可以通过for循环的方式读取里面的值
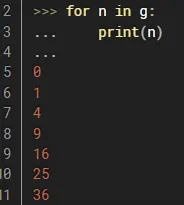
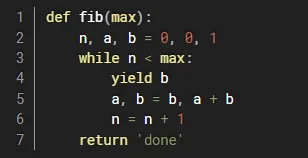
但是,更常用的生成器写法是,使用yield(中文是生成的意思)自动使用生成器来返回值,比如斐波那契数列的计算中,我们可以使用yield来进行返回。
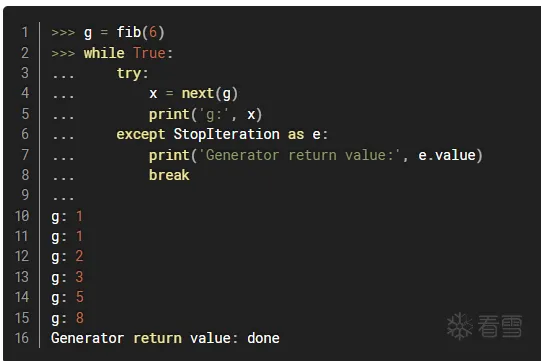
与迭代器相比,生成器属于是迭代器的容易使用的版本,故有跟迭代器完全相同的用法,可以使用next()导出。
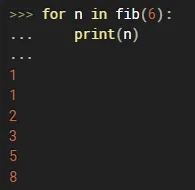
但是这一点都不简洁,更为常用的是下面这一种方法:
使用时仅需使用for循环,把fib(6)返回的,generator对象里的值逐一导出,这种写法比迭代器的写法简洁好多
此处注意:yield和return同样会返回值,但请注意它们的行为不同!
yield:返回当前值,记录停止执行的位置、状态,下次继续从上次返回值时的状态开始执行
return:返回当前值,下次执行时一切都重新开始了
装饰器(Decorator)
装饰器,简单来说就是,在不修改被装饰器的前提下,实现对其功能的增强。
首先,需要定义一个以函数为参数,并最终返回该函数及其参数,
其中,wrapper类似于一个中间层的概念,输入的是该函数及其参数,返回的也是该函数及其参数,
如以下示例
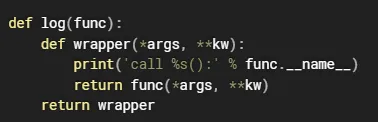
然后使用这一装饰器"log",去"装饰"now方法,now方法本身不会有call与func.__name__等字样,仅仅会输出日期
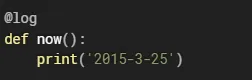
此时如果调用call
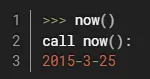
会发现now()不仅输出了日期,还输出了call与func.__name__等字样,这样就使用log完成了对now的装饰,了解到这一步就ok
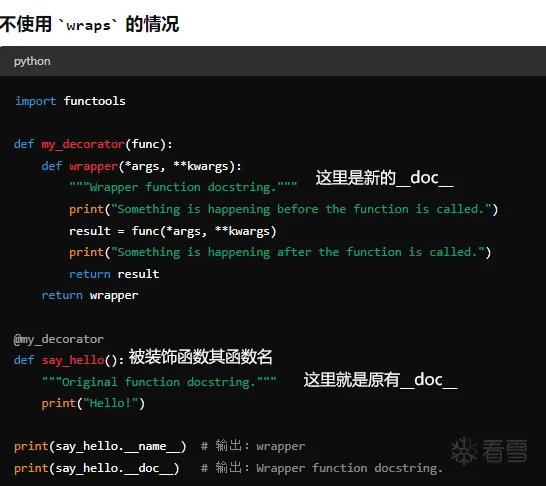
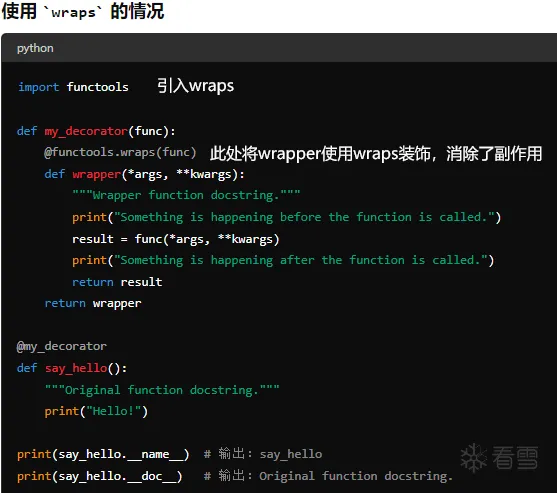
然而,实际上由于具体实现的原因,装饰器装饰后的函数本质上是另外一个全新的函数了。
为了消除其负面影响,boofuzz使用了wraps模块,其确保被装饰的函数保留原始函数的各属性
来看一个案例:
如何进行持续变异:MutationContext与协议树
曾经有人提过issue说能不能进行持续的fuzzing,https://github.com/jtpereyda/boofuzz/issues/328,以实现fuzzing一直跑而不是生成以后达到最大测试次数就停止了.于是在第499次pull的时候https://github.com/jtpereyda/boofuzz/pull/499,其引入了持续的无引导变异fuzzing,而非先前一次性的基于生成fuzzing
查看对应补丁发现

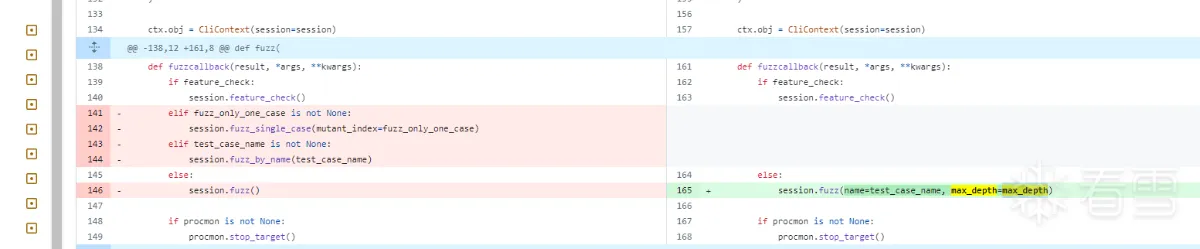
在这个补丁https://github.com/jtpereyda/boofuzz/commit/71f69bf829f98114100d3c7815caa5e827980d1a中加入了是否进行组合fuzz的判断值,如果是,则最大深度为none,否则1
然后在session类的fuzz方法里,看到了其被应用
查看sessions
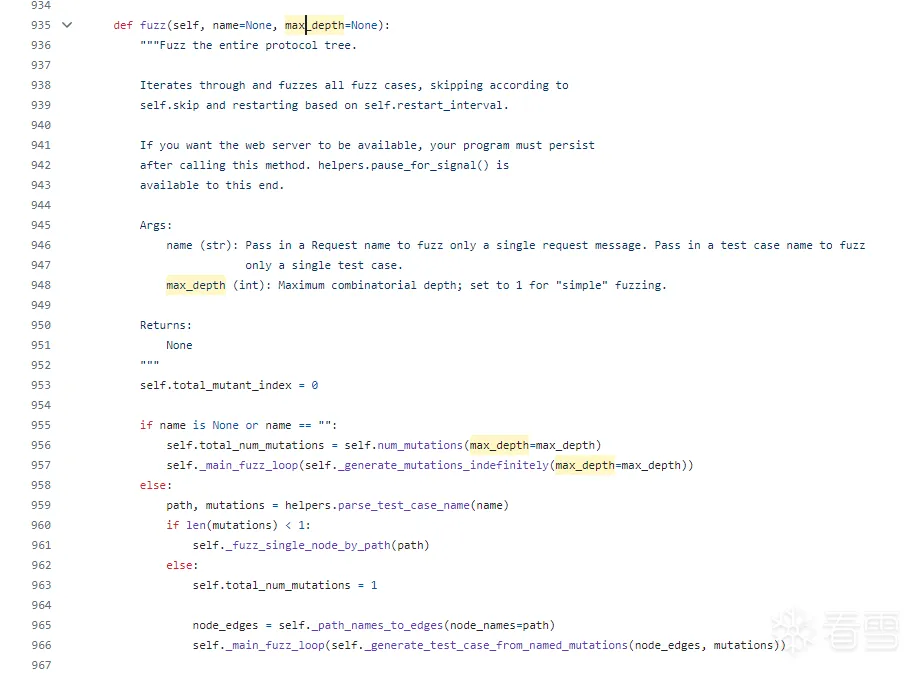
/session.py的fuzz方法
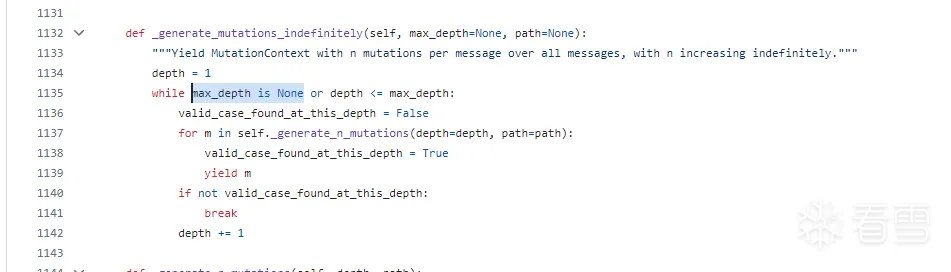
跟进_generate_mutations_indefinitely,发现有个or的循环条件,这里正是决定了无限突变的判断
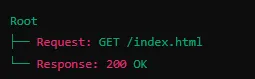
要了解接下来boofuzz是怎么进行无限变异,首先来了解一下协议树,比如以下就是协议树,其中,request的方式和路径,与响应的状态码,是这一棵简单协议树的两个节点,这两个节点到根节点,就是两条路径
_generate_n_mutations即核心的反复生成变异算法,其会基于以上协议树对每个节点之下的内容进行变异并发现新的路径
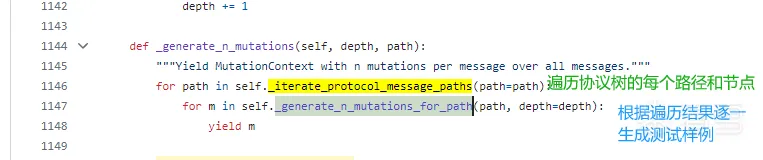
首先,在boofuzz v0.4.2上会将初始节点id和末尾节点id作为边(edge)的识别符号,

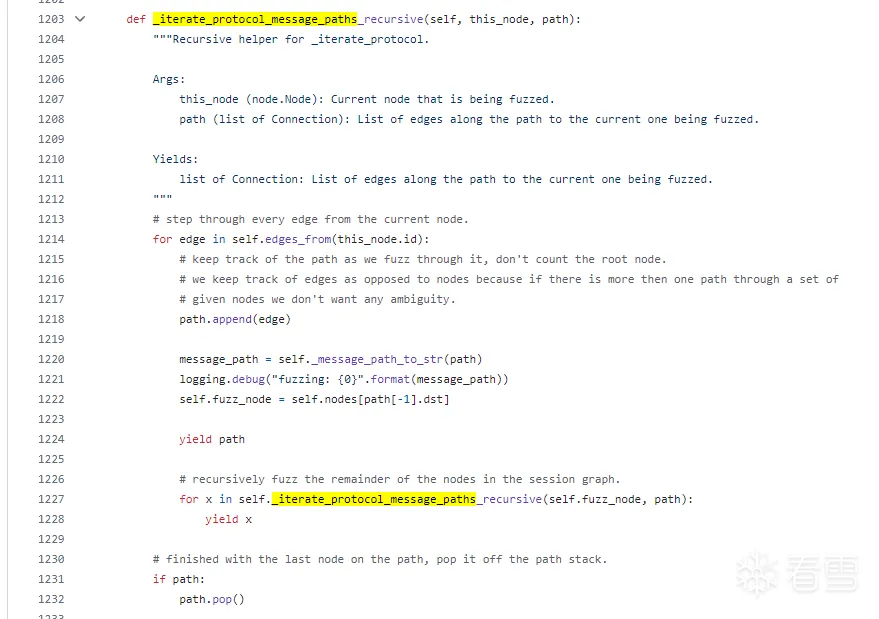
_iterate_protocol_message_paths
然后将边逐一加入到路径(path)里。框架通过 _iterate_protocol_message_paths 方法遍历某个节点下(this_node)所有消息路径,每个路径由多个节点组成,每个节点又有各自的id以供识别。于是就迭代完整个协议树了,生成了很多条路径
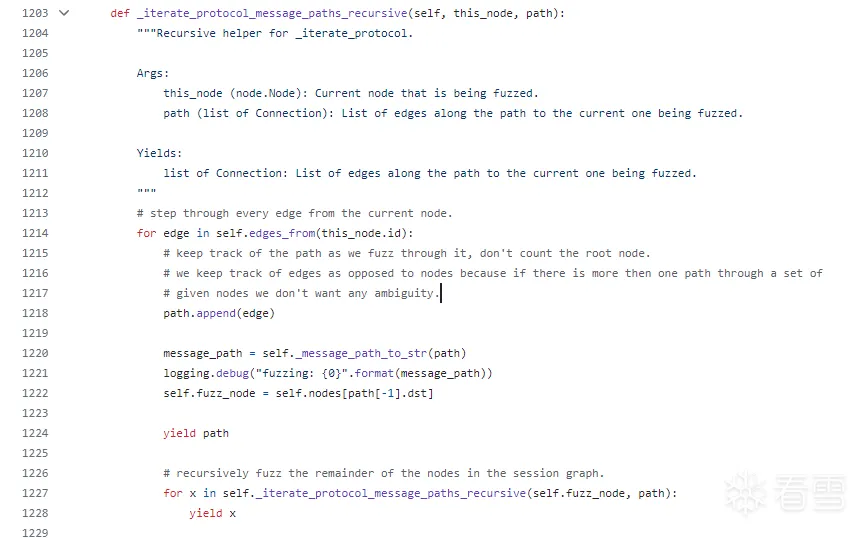
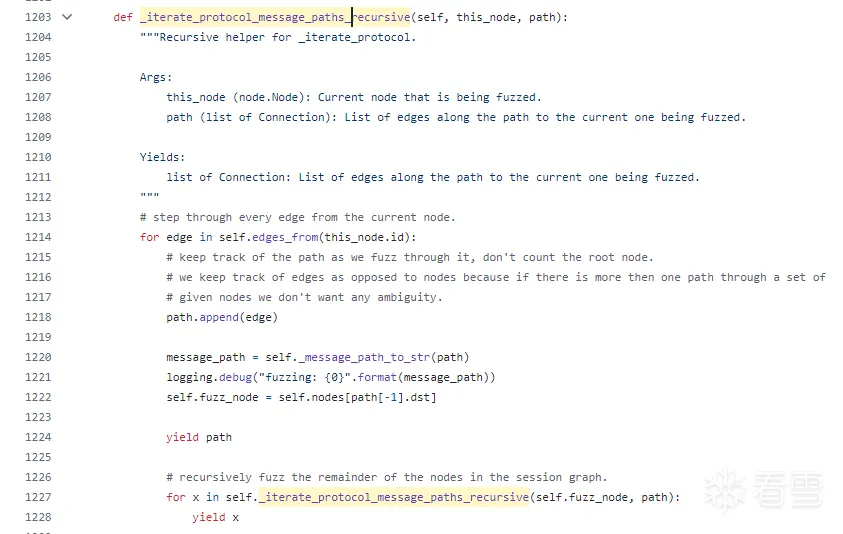
当然还有一个_iterate_protocol_message_paths_recursive ,其实功能大同小异,就是反复地递归调用自己,由_iterate_protocol_message_paths在path为空的情况下调用起来
_generate_n_mutations_for_path在每个路径上,框架通过 _generate_n_mutations_for_path 方法为路径上的每个节点生成突变。

到这里看出来了。这个看起来是boofuzz从sulley上继承的方式
当然也有一个_generate_n_mutations_for_path_recursive ,其实功能大同小异,就是反复地递归调用自己,_generate_n_mutations_for_path在path为空的情况下调用起来
从此,其自根节点自上而下,完成了对每一个不同的情况(对应不同的树形)不重复的变异,就这样直到爬完整棵树的每一种情况为止,当然其情况空间非常巨大
从boofuzz原语看生成算法
简单来说,每个原语主要是有mutation和encode步骤,据说这是为了将来实现覆盖率引导反馈和多重的变异,所以在v0.3.0明确地分开了原来同属与mutate的职能
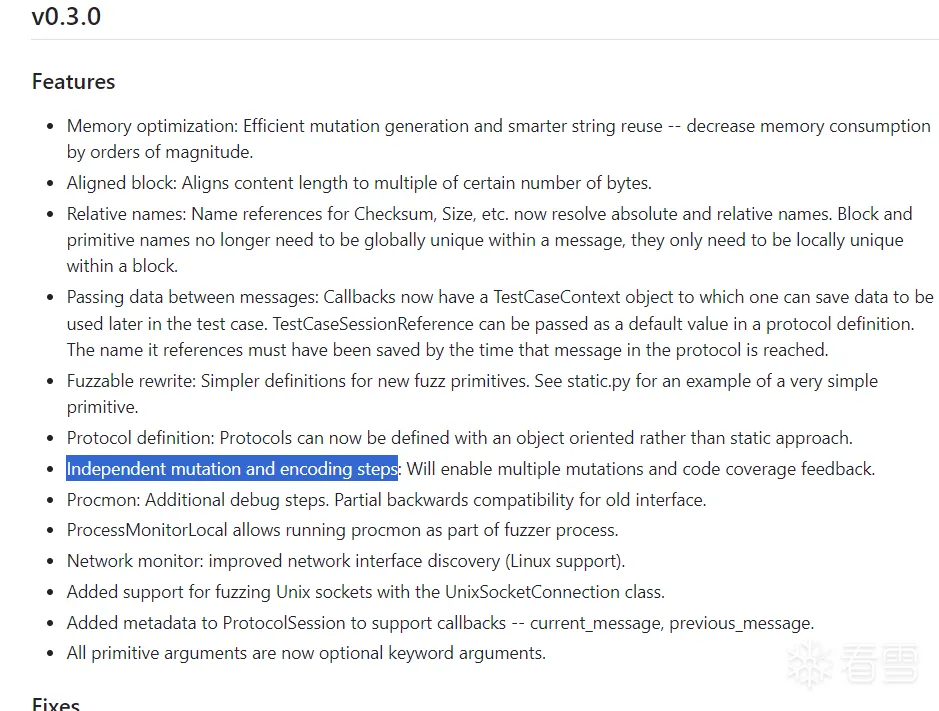
无论什么原语,最终引向的父类会是,Fuzzable类,从中我们可以看到作者解释了mutation与encode的作用

这里说,mutation主要起到生成突变的作用,返回的是一个生成器
而encode是起到对突变的结果编码的作用,返回的是值
简单来说,每次都生成不一样的东西,就给mutation
而每次都是固定化处理流程,就给encode
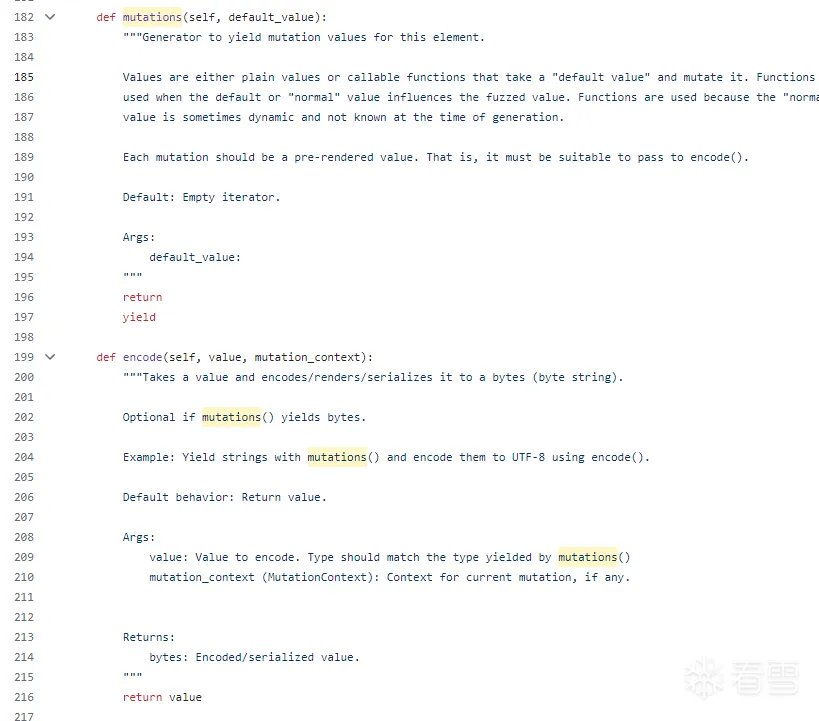
在这里都是默认没有任何行为的空方法,主要是提供给后面的原语进行重写,并预先进行相关处理定义
当然,mutations会被get_mutations处理。

在https://github.com/jtpereyda/boofuzz/pull/499
其引入了simple原语之后,所形成的组合模糊测试(Combinatorial Fuzzing)功能就是指组合生成的内容和用户指定的_fuzz_values(该值仅仅提供给simple原语使用),也就是上面提到的chain所做的事情:"组合"
所以看来get_mutations也没有定义太多的特殊操作,而是留空给原语进行定义,等下细细看看
num_mutations就是返回了突变的生成数目,用于后面的可视化,并不会对突变过程本身造成影响,这里不是重点
s_static原语
函数原型:
boofuzz.s_static(value=None, name=None)
正如其名,其不会对字符串进行任何变动,如果没有传入value,还会初始化一下然后返回空值
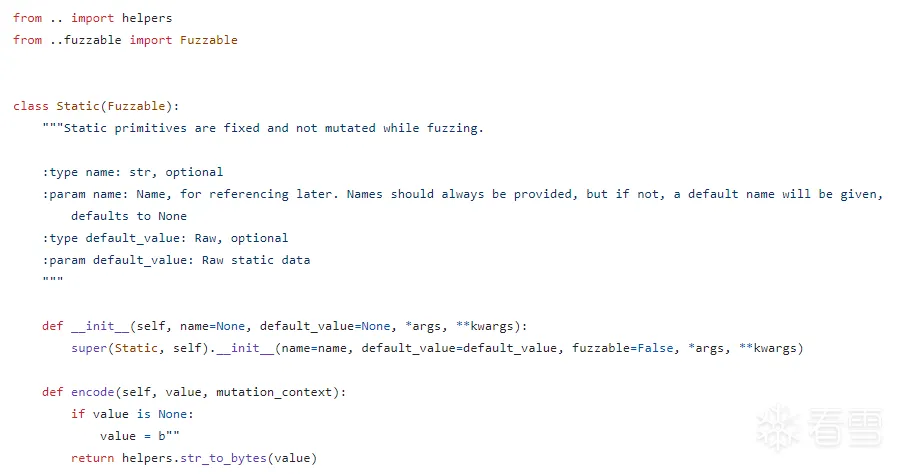
s_bit_field原语下的生成方法
首先来看看这个类的第一句话:
The bit field primitive represents a number of variable length and is used to define all other integer types.
意思是,BitField是用来表示接下来多个可变长度(Byte、Word、DWord、QWord)的基础原语,其实也是它们的父类
函数原型:
boofuzz.s_bit_field(value=0, width=8, endian='<', output_format='binary', signed=False, full_range=False, fuzzable=True, name=None, fuzz_values=None)

默认的定义是小端序的,
width参数定义了比特字段的长度,以位为单位,这为其它原语提供了长度变化的控制位置
max_num: 这是比特字段可以表示的最大值。如果未指定,将根据 width 自动计算。例如,对于 8 位的比特字段,max_num 将是 255(即 2^8 - 1)。
如果用户没有指定max_num,就会根据二进制位数转成相应十进制数为最大的数

如果用户没有指定有趣的边界值,boofuzz会针对以下"interesting_boundaries(有趣的边界值)"进行生成,
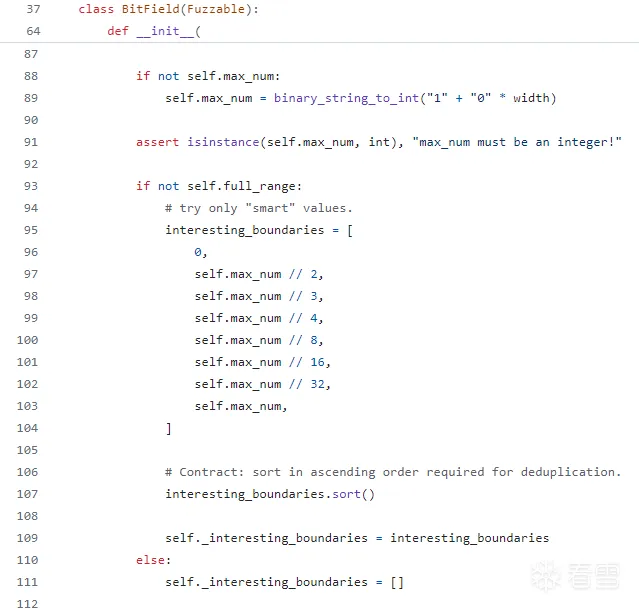
核心的生成部分在_iterate_fuzz_lib函数,调用sort()以及使用下边界lower_border来限定生成,是为了避免重复生成测试样例:
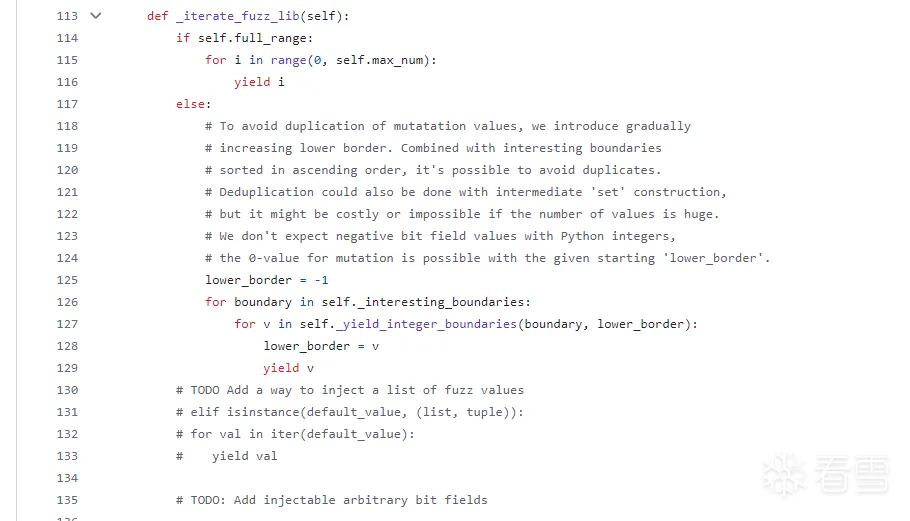
(感觉注释部分的todo没必要,因为后面引入变异以后有了类似的功能)
引用了_yield_integer_boundaries函数用于生成符合要求的值,integer对应现在遍历到的有趣边界(boundary):

生成指定有趣边界-10到+10范围的、符合下边界到最大值范围内的值,至此,完成了生成器的定义。
总的来说,bit_field做的事情就是去生成指定长度里面有趣的边界值附近的值
然后可以看到接着的mutations变异函数采取了对_iterate_fuzz_lib函数的引用,最后返回一个可供使用的生成器

变长版s_bit_field原语:s_byte、s_word、s_dword、s_qword原语下的生成方法
首先,它们都from boofuzz.primitives.bit_field import BitField,都继承自bit_field
然后就是使用super去调用父类bit_field的初始化函数,
比如byte,8位长,默认小端序
boofuzz.s_byte(value=0, endian='<', output_format='binary', signed=False, full_range=False, fuzzable=True, name=None, fuzz_values=None)

比如DWord,32位长,默认小端序,即所谓的'<'
boofuzz.s_dword(value=0, endian='<', output_format='binary', signed=False, full_range=False, fuzzable=True, name=None, fuzz_values=None)

又比如QWord指定长度为64位长度,8字节长,默认小端序
boofuzz.s_qword(value=0, endian='<', output_format='binary', signed=False, full_range=False, fuzzable=True, name=None, fuzz_values=None)
总而言之,以上都是使用super去调用父类bit_field的初始化函数
可以感受一下具体使用方法:比如针对bacnet(一种通信协议)抓下来的数据包,可以指定这样的方式去fuzzing每个字段
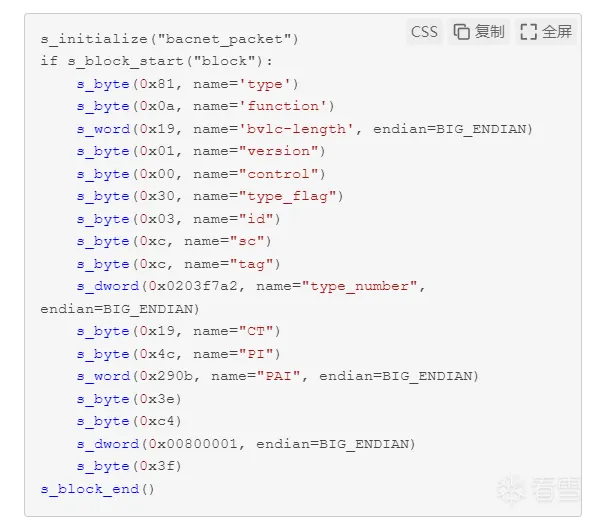
实际上,目前(v0.4.2)这里,针对各长度字节原语,指定初始value种子似乎没有起到任何作用,倒是可能方便编程的时候对照着报文结构查看
无论指定什么初始的value,都会按先前提到的方式来生成测试用例
s_bytes原语下的生成方法
函数原型:
boofuzz.s_bytes(value=b'', size=None, padding=b'\x00', fuzzable=True, max_len=None, name=None)
首先,作者认为以下内容必须包含到这个生成原语之下,这样可以关注到溢出问题

作者还取用了https://en.wikipedia.org/wiki/Magic_number_(programming)#Magic_debug_values
所述的“魔术debug值”,这比起afl的字典来说是很特别的一点——它的字典比较“先进”
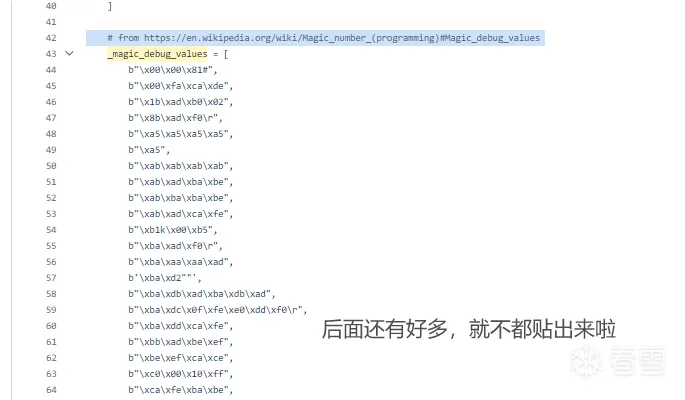
然后作者把主要的fuzz 的bytes种类分为1字节长,2字节长,以及4字节长度的字典

+号后面的内容其实就是挑选前述魔术debug值对应长度的内容,拼接到对应长度的字典后面
那么是怎么进行测试样例生成的呢?查看_iterate_fuzz_cases函数

前面把_fuzz_library,_magic_debug_values逐一单独输出了,
而后面的for fuzz_bytes in self.fuzz_strings[1,2,4]byte,其实就是把原来的字符串里面的每个可能的位置,尽可能插入每个先前提到的bytes串,
这里分成三个长度去处理是因为对应长度的字符串最后一个循环预留的空间有所不同,比如1字节的无需多预留,2字节的预留多1字节,4字节的预留多3字节,这样就能恰好覆盖
最后由mutations函数调用_iterate_fuzz_cases函数,变异了原输入的字符串,逐一遍历之,然后经过一些格式处理后喂给生成器,其实没有对测试样例进行实质上的改变
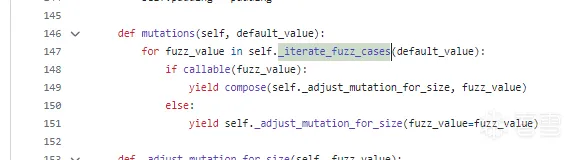
_fuzz_library
这一部分也和前面的差不多,为_fuzz_library字典添加了很多内容:

_yield_variable_mutations

2是极短的,100是比较长的
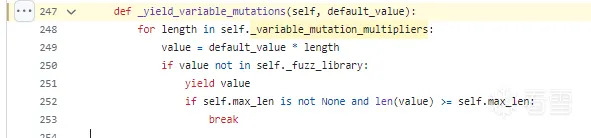
其实就是把默认字符串重复了*2,*10,*100次,来进行测试
_yield_long_strings
值得注意的是,还有一个供给长字符串使用的种子集合

以及限定字符串长度的、还有辅助变异用的数组

它们被用于这里,生成了所有可能的size,通过相加的方式
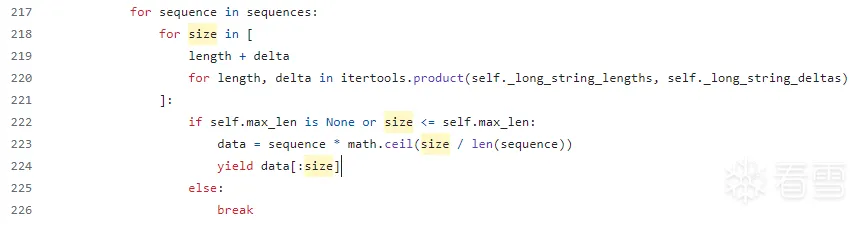
所谓sequence其实就是long_string_seeds,之前提到的长字符串种子

这里的for循环里面,其实就是把sequence复制了足够多铺满的次数,然后截断到合适长度
注意这里的deltas就是△,是增量的意思,范围在[-2,2]区间
所谓笛卡尔积的操作是:会输出(8, -2)
,(8, -1)
,(8, 0)
,(8,1),(8,2),(16, 0)之类的二元数组
然后就会参与相加,输出6,7,8,9,10....其实size就是覆盖了各种有意思的长度可能性
而对于超长的字符串生成,其使用了类似的方法,并且检查了字符串的长度限制,使用同样的种子来不断重复内容,以生成一个超长的字符串
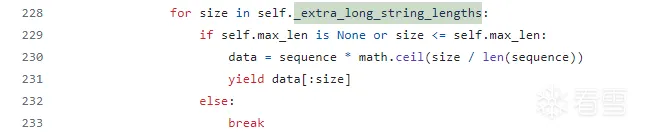
在函数的最后,还尝试了使用字符"D"填满字符串,然后不断在其中每个位置插入\x00截断字符

chain
这里把以上三个迭代器给链接在一起了,chain起来了,val即遍历用变量,被_adjust_mutation_for_size进行逐一修剪
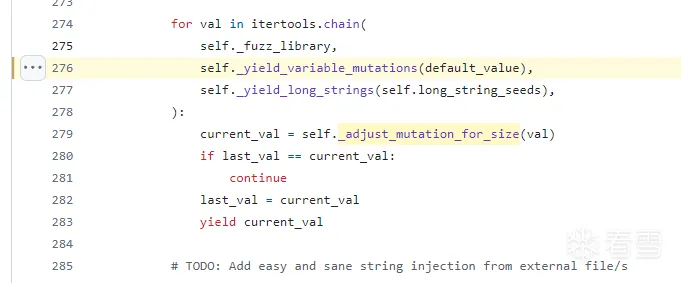
根据最大长度来修剪每个测试样例

最后返回current_val迭代器,提供给fuzzer
总的来说,s_static 原语通过重复预定的字符串以生成不同长度的测试字符串,包括短字符串、长字符串和超长字符串。它使用种子集合和增量范围生成各种长度的字符串,并在字符串中插入截断字符\x00 进行测试。
s_delim原语下的生成方法
函数原型:
boofuzz.s_delim(value=' ', fuzzable=True, name=None)
针对分隔符的变异,变异为各种各样非预期的分隔符

base_primitive原语下的生成方法
接下来的方法有些会继承这个原语,有个迭代器和_fuzz_library字典,还有encode方法(前面忘记说了,这个其实就是字符串转ascii码什么的,其实不是变异策略里的东西)
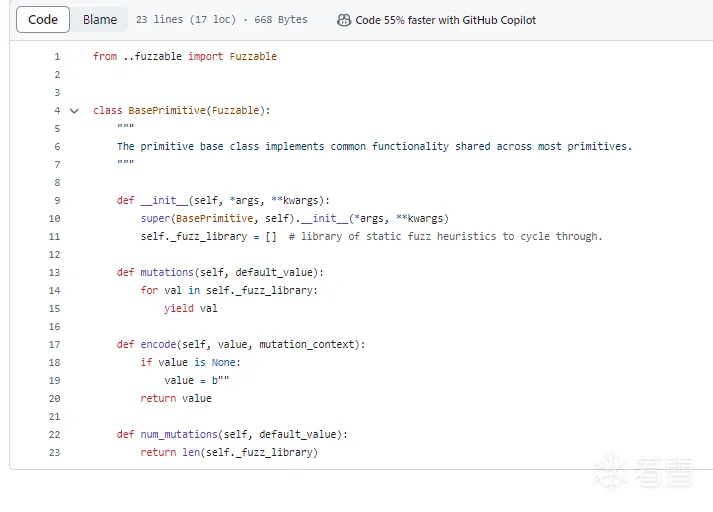
其定义了一个可以提供继承的框架
s_from_file原语下的生成方法
函数原型:
boofuzz.s_from_file(value=b'', filename=None, encoding='ascii', fuzzable=True, max_len=0, name=None)
其继承了base_primitive

然后其实就是逐行读字典
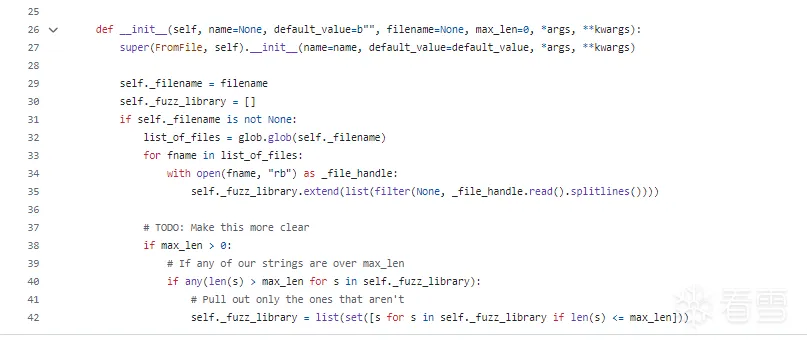
这里没有任何变异,仅仅是把文件内容原封不动地添加进字典里
s_float原语下的生成方法
boofuzz.s_float(value=0.0,s_format=".1f",f_min=0.0,f_max=100.0,max_mutations=1000,fuzzable=True,seed=None,encode_as_ieee_754=False,endian="big",name=None):
其实float生成的逻辑非常简单:随机,但检测是否与上次相同
这样能够保证性能不会太差,而且是不是随机感觉差别也不大,因为浮点数没有什么“有趣值”之说
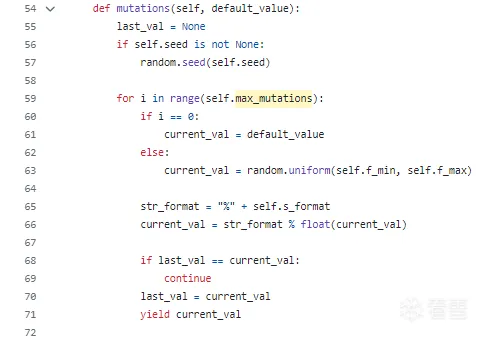
然后就是encode函数,根据参数决定是否将浮点数编码为 IEEE 754 格式,如果需要则调用辅助方法 __convert_to_iee_754。

__convert_to_iee_754格式转换函数不是本文探究的重点
s_simple原语下的生成方法
boofuzz.s_simple(value=None, name=None, fuzz_values=None, fuzzable=True)
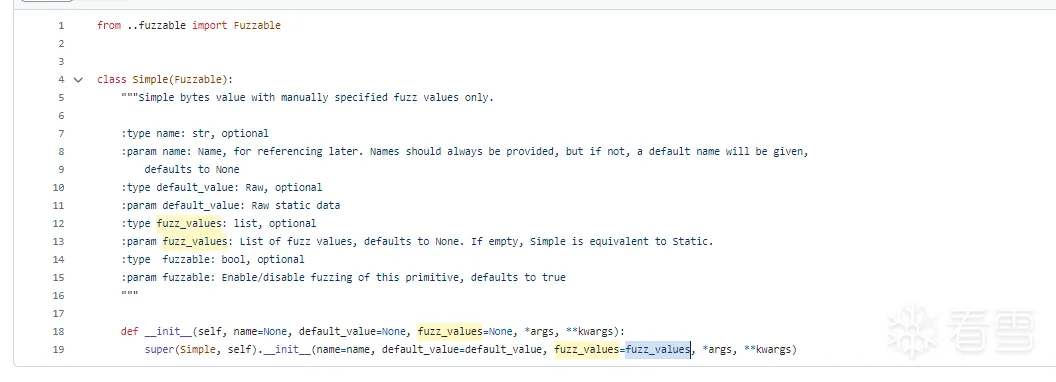
仅仅会测试手动指定的fuzz_value
s_group原语下的生成方法
s_group(name=None, values=None, default_value=None)
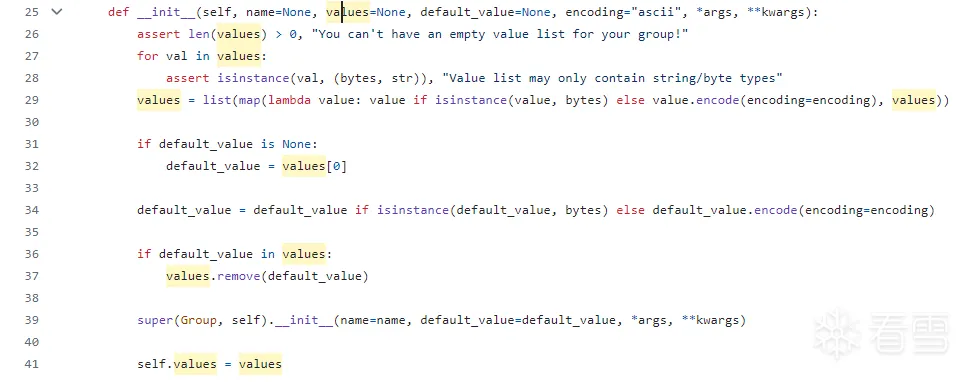
传入value数组
values = list(map(lambda value: value if isinstance(value, bytes) else value.encode(encoding=encoding), values))
这句有点长,其实就是将 values 列表中的每个不是字节类型的元素,都转换为字节类型(bytes),以在后面进行统一的处理。因为用户有时候希望用于fuzzing的传入参数是字节,有时候传入的是字符串
同理,传入的default_value也被做了类似的初始化操作,如果没有,还会被赋值为value[0]
最后的生成器环节就是遍历每个value
s_random原语下的生成方法
函数原型:
boofuzz.s_random(value='', min_length=0, max_length=1, num_mutations=25, fuzzable=True, step=None, name=None)
要指定 min_length,max_length, max_mutations,以及step(默认0)
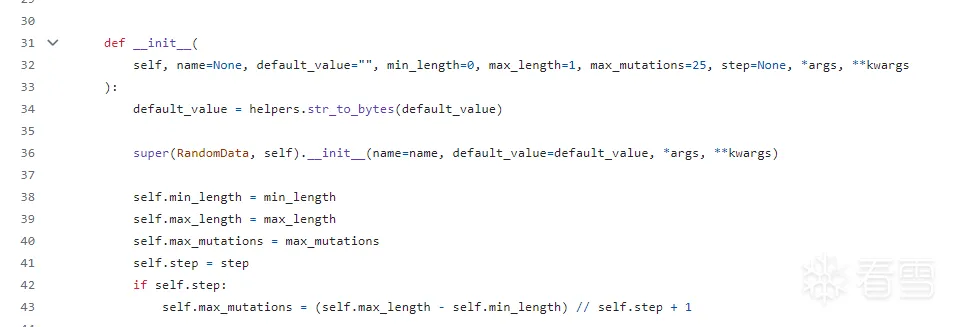
如果指定了step=1.将会无视max_mutations设置,且采取从min_length渐进到max_length之间所有长度的随机变异

随机数种子指定为0是因为,作者希望测试用例可重现
如果没有指定step=1,那么就连长度也是被随机化的

然后就是关键的生成random字节部分,这里的意思其实就是生成ascii码0-255的无符号char

其实pack负责打包的是字符串

在这里是把python的int打包成c语言下的unsigned char了,以供输入测试
s_mirror原语下的生成方法
函数原型:
boofuzz.s_mirror(primitive_name=None, name=None)
用于与另外一个原语保持完全的同步,在某些情况下,字符串需要同时进行变动。最核心的获取部分如下,是根据primitive_name,即被复制对象的名称来进行同步获取的

s_size原语
函数原型:
block_name=None,
offset=0,
length=4,
endian=LITTLE_ENDIAN,
output_format="binary",
inclusive=False,
signed=False,
math=None,
fuzzable=True,
name=None)```
s_size原语用于获取对应字符长度并嵌入到fuzz数据包,这对于Content-Length等字段的长度获取很有用,需要指定name,和其它原语匹配即可计算其长度
用法示例

这个的实现在boofuzz/blocks
/size.py

接下来的计算长度逻辑主要是在encode函数进行的

其中,计算长度的逻辑是:

_recursion_flag如何防止递归?首先,定义了一个装饰器_may_recurse(f),并使用wraps来消除副作用,其在调用前把递归flag设置为true

有时候用户设置了复杂的样例,导致计算长度的size原语可能递归。那么,当以下两个被装饰器发生了递归的时候,其计算逻辑会进行“短路”,以避免重复的大量运算。这可以在
_calculated_length调用到的_length_of_target_block观察到

以上就完成了对encode函数的防止递归,避免了性能损耗
# 总结
boofuzz基于以上原语进行了测试用例的针对性生成,虽然没有根据代码覆盖率进行变异,但对专门的位置使用专门的生成方法(反观AFL,把所有方法都使用了,没有针对性),非常适合对通信时的协议格式有一定了解的情况,且使用了比AFL更现代化的生成语料。复现略,直接下个脚本跑就ok。
# 参考
v0.4.2版本boofuzz源代码:
https://github.com/jtpereyda/boofuzz/tree/5552d0c6113d98a61ee2ec85a8135cde45246df2
关于python迭代器、生成器、装饰器可以看这篇总结:)比较详细
https://stonewiki.su-cvestone.cn/zh/program/basement/pyhon#%E8%BF%AD%E4%BB%A3%E5%99%A8
boofuzz关于各原语的介绍文档:
https://boofuzz.readthedocs.io/en/stable/user/static-protocol-definition.html
https://boofuzz.readthedocs.io/en/stable/_modules/boofuzz.html
boofuzz的用户手册:https://boofuzz.readthedocs.io/_/downloads/en/stable/pdf/
