前言
关于ELF格式的解析和库文件的模拟执行在论坛里已经有很多了,这篇文章也算不上什么新的思路,单纯是作为个人在学习时的一点记录,希望我的经验能够帮助到大伙。
如有错误缺漏请在评论区指正捏
原文地址
Introduction
在尝试逆向一个动态链接库的时候,有时你可能希望单独运行某个函数,以探究它的具体作用。
如果这个二进制文件的编译架构与你的机器架构相同,并且你拥有其所有依赖库,那么操作相对简单:直接使用dlopen加载动态库,然后通过 offset 获取函数地址,执行即可。
然而,如果遇到不同架构的二进制文件,比如 aarch64 架构,应如何方便地进行调试和模拟运行呢?
一种常见的方法是在相应架构上启动gdbserver或使用frida等类似工具进行跟踪。但这种方法过于笨重。是否存在一种更轻量级的方法来模拟运行这个 ELF 文件呢?
unicorn模拟运行, 外加elf简单介绍
从去除字符串加密开始
让我们从我们的sample文件libkpk.so开始,这个库文件了包含了一个需要被逆向出来的加密算法。
libkpk.so是一个从安卓安装包里提取出来的库文件,根据反编译可以发现,这里面应该包含有三个函数,分别是fetch,isKpk和kpk,java通过jni来调用这几个函数。在这些函数中,我们重点关系的是kpk函数,这个函数是作为加密函数出现的,

但是在这个二进制里,并没有找到任何和加密有关的字符串,即使有字符串,这些字符串也是已一种非常诡异的状态出现的。
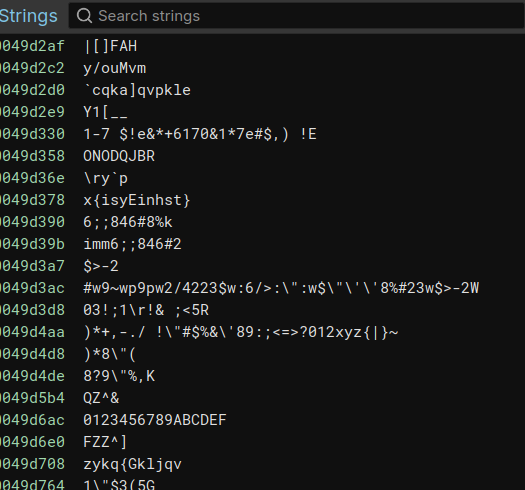
在观察这些诡异的字符串后,发现这些字符串都会在最开始被init_array里面的.datadiv_decodexxx函数修改,所以我们可以合理推断这些datadiv_decode函数就是解密函数,用在lib被加载的时候来解密被加密的字符串。
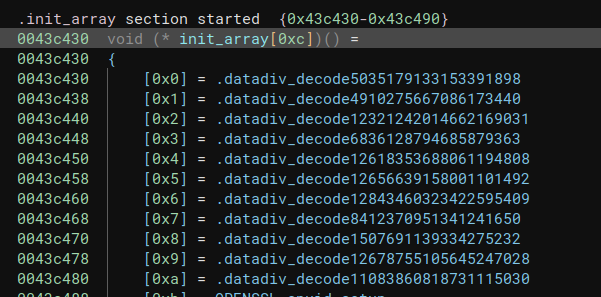
在经过搜索之后,可以发现datadiv_decode正是被Armariris进行字符串混淆后会出现的解密函数
Armariris混淆
Armariris是上海交通大学开发的基于llvm的混淆框架,开源在https://github.com/GoSSIP-SJTU/Armariris
armariris的字符串加密逻辑比较简单,“对于所有的常量字符串,先创建一份可读写的、类型相同、大小相同的全局变量,将原先的字符串xor随机数,存放到这块新的全局变量里[1]”。
解密也比较简单,把解密字符串的逻辑写到对应的解密的函数里,接下来只要在lib加载的时候,跑一下解密函数就行了。
详细步骤
所以,解密的方法可以被概括为
- 加载elf到内存
- 模拟运行解密函数
- 保存解密后的字符串,覆盖掉原来加密的字符串
- 删掉所有的解密函数
然而,由于这个二进制是在是在aarch64下编译的,而我们的电脑是amd64的,没办法直接运行。这个时候,我们可以使用unicorn来模拟运行程序。
unicorn基于qemu,但是更加轻量级,提供了一个多个架构下模拟cpu运行的接口,非常适合在这个地方使用。
那么我们就可以开始惹。
Step 1: 加载elf到内存中
第一部,我们需要加载elf文件到内存中,要完成这个,我们需要把elf文件里所有PT_LOAD segment标示的内存区域从文件中读取并写入相对应的内存地址。
在64位下,program header的定义如下。当p_type=PT_LOAD即代表该段为可装载段,表示即这个段将被装载或映射到内存中,其中p_offset代表该段在文件中的位置,p_filesz代表该段的长度。p_vaddr为数据映射到虚拟内存中的地址,p_flags代表这段区域的读写执行权限。当然因为我们是在cpu模拟机下执行,我们根本不关心他的权限,所以全部设置为rwx。
1 2 3 4 5 6 7 8 9 10 | typedef struct {
Elf64_Word p_type;
Elf64_Word p_flags;
Elf64_Off p_offset;
Elf64_Addr p_vaddr;
Elf64_Addr p_paddr;
Elf64_Xword p_filesz;
Elf64_Xword p_memsz;
Elf64_Xword p_align;
} Elf64_Phdr;
|
https://docs.oracle.com/cd/E19683-01/816-7777/chapter6-83432/index.html
在了解了基本概念后,我们就可以把elf对应的段加载到内存里了。如下代码所示,get_mapping_address会计算出这块内存需要mmap哪一块内存地址,并对齐page size,也就是0x1000。然后mmap并写入数据就行了
1 2 3 4 5 6 | for seg in lib.iter_segments_by_type('PT_LOAD'):
st_addr, size = get_mapping_address(seg)
emulator.mem_map(lib.address + st_addr, size, UC_PROT_ALL)
emulator.mem_write(lib.address + seg.header.p_vaddr, seg.data())
log.info("loaded segment 0x%x-0x%x to memory 0x%x-0x%x", seg.header.p_vaddr,seg.header.p_vaddr+seg.header.p_memsz, lib.address + st_addr, lib.address + st_addr+size)
|
Step 2: 找到所有.datadiv_decode开头的函数并执行
这步比较简单,用pwntools的读取文件后,在symbol table里找到所有开头为.datadiv_decode的函数,然后执行即可。
在aarch64中,return pointer的寄存器为LR,在进入函数前,先设置LR,那么函数结束的时候就会跳回LR,我们在这里把LR设置为0,那么就知道当程序运行到0的时候,函数就结束了。
1 2 3 4 5 6 7 8 9 | datadivs = []
for name in lib.symbols:
if name.startswith(".datadiv_decode"):
datadivs.append(name)
for datadiv in datadivs:
log.info("[%s] Function %s invoke", hex(lib.symbols[datadiv]), datadiv)
emulator.reg_write(arm64_const.UC_ARM64_REG_LR, 0)
emulator.emu_start(begin=lib.symbols[datadiv], until=0)
log.info("[%s] Function return",hex(lib.symbols[datadiv]),)
|
Step 3: 用解密后的数据patch掉原来加密的数据
这步也比较简单,因为所有的文本都在.data段里,直接把整个.data段覆盖掉就行了
1 2 3 4 | log.info("Patch .data section")
new_data = emulator.mem_read(lib.address + data_section_header.sh_addr, data_section_header.sh_size)
libfile.seek(data_section_header.sh_offset)
libfile.write(new_data)
|
Step 4: Patch掉所有的解密函数
这步也比较简单,直接让函数ret就行了
1 2 3 4 5 6 7 8 9 10 | log.info("Patch .datadiv_decode functions")
for datadiv in datadivs:
libfile.seek(lib.symbols[datadiv] & 0xFFFFFFFE)
ret = b''
try:
ret = asm(shellcraft.ret())
except:
ret = asm("ret")
libfile.write(ret)
|
效果
把解密后的二进制拖入反编译软件,我们可以看到所有的字符串都已经被解密了,且对应的JNINativeMethod结构也比较好容易可以分辨出来。
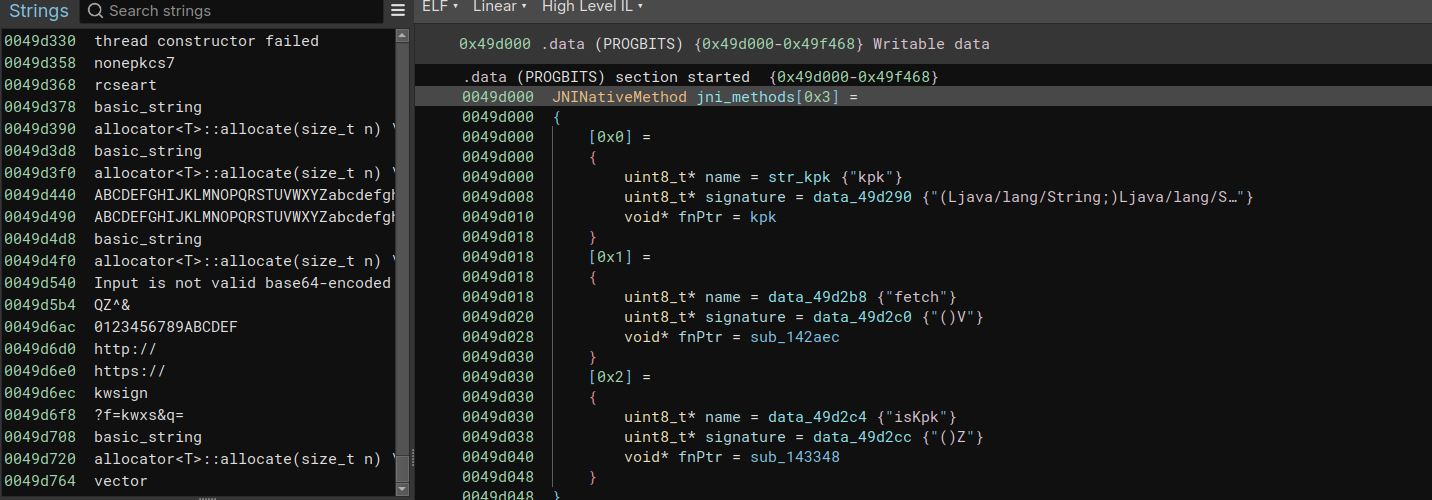
找到了kpk对应的函数之后,就要考虑如何去模拟执行它了。
ELF文件是怎么Load的
在开始正式模拟运行之前,让我先来回顾一点基础知识,就是elf文件是怎么从加载到内存到运行的。
Segment简单介绍
通过readelf -l libkpk.decrypt.so我们可以读取ELF文件并获取到一些基本的信息,首先我们可以知道这个库文件是一个动态的共享库文件
他包含了几个关键的segment
PT_LOAD:
在前文中提到了,PT_LOAD即可装载段,代表这类段会被加载到内存中。
PT_DYNAMIC:
这段也非常重要,代表了所有需要在运行时进行重定向的内容。这些内容包含got表,全局变量重定向信息以及任何其他需要在运行时重定向的内容。
比如说,现在大部分程序运行的时候都会开启PIE(position-independent executable),开启pie之后,程序的基值就不为0了,这个时候就需要通过重定向修正符号正确的地址。
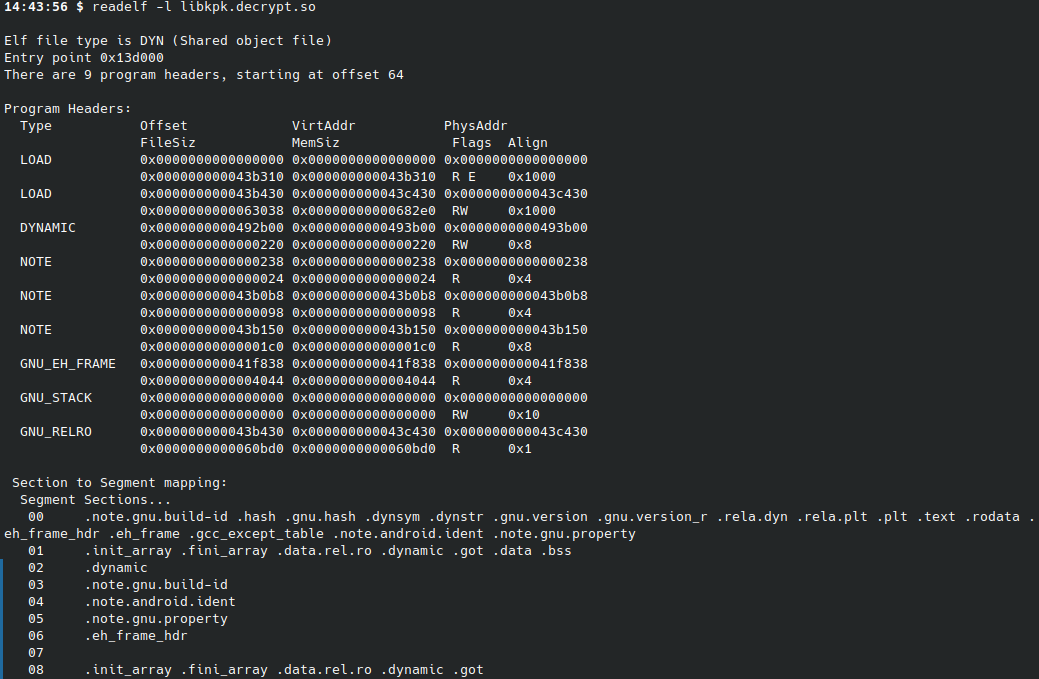
如果一个二进制文件不是库文件而是一个动态的可执行文件,那么还会有另外一个重要的segment,PT_INTERP
PT_INTERP
这个segment里存放了所需要的程序解释器(也就是动态链接器)的信息与位置。动态链接器的作用是加载可执行文件的共享库,并且解析可执行文件中使用的符号,以便在程序运行时正确地调用这些库函数。它在程序启动时将各个共享库加载到内存中,并根据需要将符号解析成实际的内存地址,使得程序可以顺利执行。
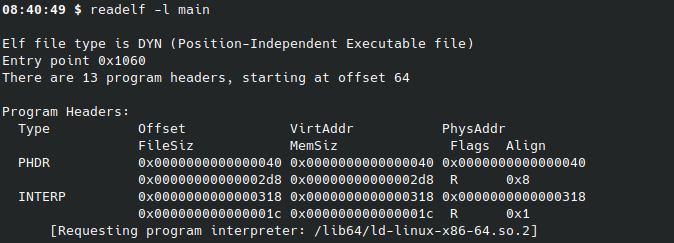
要注意的是,如果一个二进制文件是一个静态的可执行文件,简单来说,就是在build的时候加上-static参数的可执行文件,一般来说是没有PT_DYNAMIC和PT_INTERP segment的,因为没有必要。
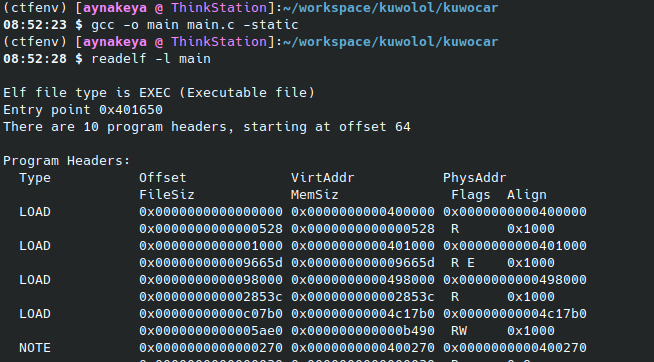
静态链接与动态链接
我们知道,elf可执行文件根据编译的时候链接方式可以分为两类:一个是静态程序,编译的时候使用静态链接,另一种是动态程序,编译的时候使用动态链接。
静态链接
静态链接就是在编译链接时直接将目标的代码(也就是生成的.o文件)和所引用的库文件的代码一起打包的可执行文件中。也就是说,可执行文件本身就包含了所需的所有代码。
所以,通过静态链接的程序在发布与运行的时候不需要依赖库,可以独立运行。但是相对的,由于静态链接把所有需要的库都打包了进去,生成的二进制的文件会比较大。
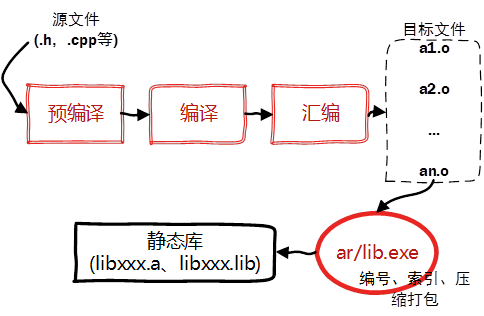
source: 创建静态库的过程 14
动态链接
动态链接是在编译时并不将所有目标代码和库文件的代码打包到可执行文件中,而是仅包含对这些库的引用信息。在程序运行时,动态链接器会根据这些引用信息找到并加载所需的共享库。
编译时:编译器生成目标文件(.o 文件),并将动态库的引用信息嵌入到可执行文件中,而不是库的实际代码。
链接时:链接器会将这些目标文件和必要的符号表一起打包生成最终的可执行文件。
加载时:程序启动时,制定的动态链接器会根据可执行文件中的引用信息,查找并加载需要的共享库,将它们映射到进程的地址空间中。
符号解析:动态链接器负责解析程序中使用的符号(例如函数调用和全局变量),将它们与加载的共享库中的实际地址进行匹配。
重定位:对于那些需要在运行时确定的地址,动态链接器会进行必要的重定位操作,确保程序在内存中正确运行。
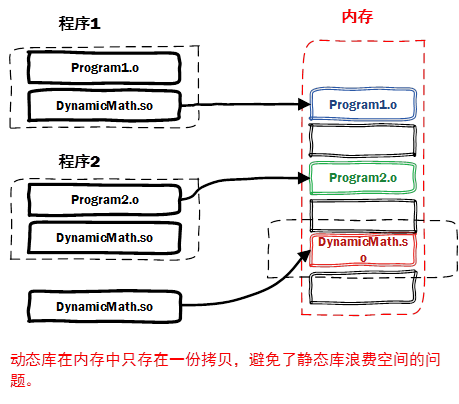
source: 动态库链接过程 14
ELF LOOOADING.....
一个elf文件的loading也分情况讨论,如果需要加载的二进制文件是静态链接的,那么elf加载的过程相对来说就比较简单。
- 首先把所有
PT_LOAD端都加载到内存中,设置并初始化好stack
- 把pc(或者rip)指向elf头中的
entry地址
这样,一个静态elf文件就成功执行起来了。
但是,如果是动态链接的elf,那么就稍微比较复杂一点了,再加载完PT_LOAD端后还需要额外处理PT_DYNAMIC段修复重定向。
- 首先把所有
PT_LOAD端都加载到内存中,设置并初始化好stack
- 解析
PT_LOAD并完成本程序内所有符号的重定向
- 加载所有依赖的动态库
- 根据重定位表(
.rel 或 .rela),解析所有符号依赖,找到每个符号的实际地址,对符号引用进行重定位,修改内存中的代码或数据,使其指向正确的符号地址(包含即时绑定和懒绑定)。
- 把pc设置为
entry,开始执行程序。
当然,在实际应用中,除了第一步,其他的步骤都不需要程序本体进行。这些步骤一般会被系统的动态链接器完成。所以动态加载的程序在完成自身程序的加载后,会首先用同样的方法把动态链接器加载到内存中,然后向动态链接器传入对应的数据,之后,程序就不需要管了,只需要等待动态连接器完成所有的操作并把pc重新指向程序本体的entry就好了。
当然,在这里我们就不依赖动态链接器了,我们可以来手动实现程序的重定向
重定位
首先第一步是读取PT_DYNAMIC段来拿到所有需要的信息。在64位下,PT_DYNAMIC端中的数据结构可以由如下数据结构表示。
其中d_tag相当于一个类型标识符,d_un由d_tag控制,内部的值根据d_tag的不同代表不同的值
1 2 3 4 5 6 7 | typedef struct {
Elf64_Xword d_tag;
union {
Elf64_Xword d_val;
Elf64_Addr d_ptr;
} d_un;
} Elf64_Dyn;
|
我们主要关注以下几个d_tag
DT_STRTAB/DT_STRSZ: 字符串表的地址和长度。运行时链接程序所需的符号名称、依赖项名称和其他字符串位于该表中。
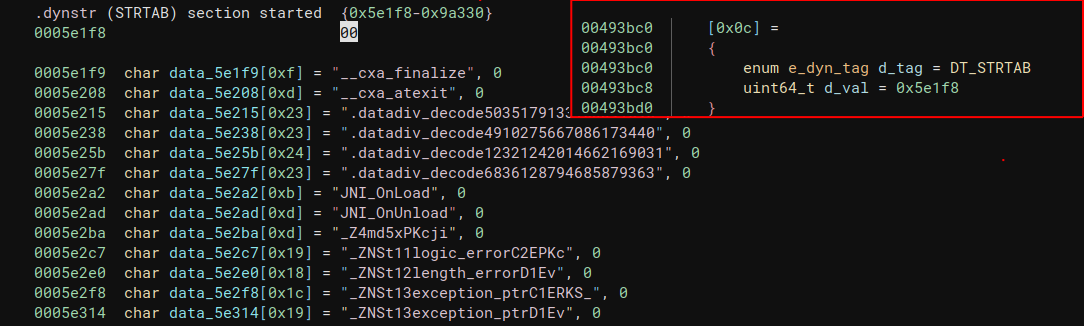
DT_SYMTAB: 符号表的地址。
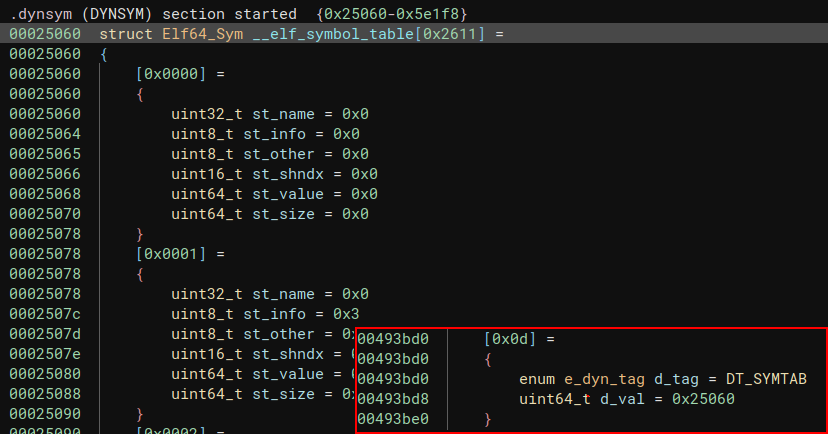
64位下符号表可以用如下结构表示,我们主要关注st_name和st_value。
st_name表示该符号在字符串表的索引,可以通过这个值和字符串表拿到该符号的字符串名称,如果st_name的值为0,则代表该符号没有相对于的字符串名称。
st_info代表该符号的值。根据上下文,该值可以是绝对值或地址(和之后的重定向的类型相关)。
1 2 3 4 5 6 7 8 | typedef struct {
Elf64_Word st_name;
unsigned char st_info;
unsigned char st_other;
Elf64_Half st_shndx;
Elf64_Addr st_value;
Elf64_Xword st_size;
} Elf64_Sym;
|
DT_RELA/DT_REL: 重定位表的地址。一个二进制文件里可以有多个重定位节。为可执行文件或共享目标文件创建重定位表时,链接编辑器会连接这些节以形成一个表。在64位下,ELF有两种重定位表的结构 REL and RELA,分别对于DT_REL和DT_RELA
1 2 3 4 5 6 7 8 9 10 | typedef struct {
Elf64_Addr r_offset;
Elf64_Xword r_info;
} Elf64_Rel;
typedef struct {
Elf64_Addr r_offset;
Elf64_Xword r_info;
Elf64_Sxword r_addend;
} Elf64_Rela;
|
r_offset代表需要修复的虚拟地址
r_info存放了r_info_sym和r_info_type的值,其中r_info_sym表示该重定向指向了符号表中的第N项,r_info_type代表了重定向的类型,对于不同的架构,重定向类型也有不同,具体可以参考官方的ABI。
1 2 | r_info_sym = r_info >> 8
r_info_type = r_info && 0xff
|
开始重定向时,我们首先读取所有的重定位表,然后根据r_info_sym和符号表找到每一个重定位项对应的符号,最后根据符号表中的st_value,重定位表中的r_info_type, r_addend以及当前程序的base address计算出重定向之后的地址并写入内存中即可。
AArch64下的重定位
因为我们的测试用二进制是aarch64的,那我们这里就用aarch64作为例子来说明重定向的过程。
首先我们需要知道不同的重定向类别即r_info_type是如何计算重定向值的,具体的计算方法我们可以参考arm官方的ABI 6。在这里呢,我们来看一下比较常用的几个重定向类别。
R_AARCH64_ABS64: 符号地址+r_addend 即 程序基值 + st_value + r_addened

R_AARCH64_GLOB_DAT: 也是符号地址 + r_addend 也是 程序基值 + st_value + r_addened
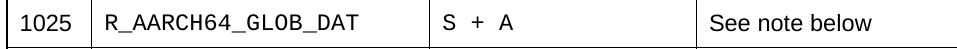
R_AARCH64_RELATIVE: 程序基值加上 + r_addend

R_AARCH64_JUMP_SLOT: 这个比较特殊,代表了跳转表。这个类别一般和调用外部库时有关。当st_value的值为0的时候,说明这个符号是外部导入的,需要通过连接器从加载的库中找到并加载。当然,这个重定向也可以在运行时再链接,即在需要这个符号的时候进行懒加载,关于这段可以在搜索并参考**__dl_runtime_resolve()**的过程
如果st_value的值不为0,则和R_AARCH64_GLOB_DAT一样,都是符号地址+r_addend
手动实现重定向代码的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | def get_symbol_table(elf: 'ELF') -> SymbolTableSection:
for section in elf.iter_sections():
if section.header.sh_type == "SHT_DYNSYM":
return section
def get_relocations(elf: 'ELF') -> Dict[int, Relocation]:
rel_sections: List[RelocationSection] = []
for section in elf.iter_sections():
if section.header.sh_type in ["SHT_REL", "SHT_RELA"]:
rel_sections.append(section)
if section.header.sh_type == "SHT_DYNSYM":
dynsym = section
relocs = dict()
for rel_section in rel_sections:
for reloc in rel_section.iter_relocations():
r_offset = reloc.entry.r_offset
if r_offset in relocs:
raise Exception("wtf")
relocs[r_offset] = reloc
return relocs
relocs = get_relocations(lib)
symtab = get_symbol_table(lib)
for addr, reloc in relocs.items():
if reloc.entry.r_info_type == ENUM_RELOC_TYPE_AARCH64['R_AARCH64_JUMP_SLOT']:
name = symtab.get_symbol(relocs[addr].entry.r_info_sym).name
if symtab.get_symbol(relocs[addr].entry.r_info_sym).entry.st_value == 0:
print(name, hex(addr), symtab.get_symbol(relocs[addr].entry.r_info_sym).entry.st_value,
relocs[addr].entry.r_addend)
if reloc.entry.r_info_type in [
ENUM_RELOC_TYPE_AARCH64['R_AARCH64_ABS64'],
ENUM_RELOC_TYPE_AARCH64['R_AARCH64_GLOB_DAT'],
ENUM_RELOC_TYPE_AARCH64['R_AARCH64_JUMP_SLOT']]:
ql.mem.write(lib.address + addr,
(lib.address + symtab.get_symbol(relocs[addr].entry.r_info_sym).entry.st_value + relocs[
addr].entry.r_addend).to_bytes(8,
"little"))
elif reloc.entry.r_info_type in [ENUM_RELOC_TYPE_AARCH64['R_AARCH64_RELATIVE']]:
ql.mem.write(lib.address + addr,
(lib.address + relocs[addr].entry.r_addend).to_bytes(8, "little"))
else:
print(f"not handled r_info_type {reloc.entry.r_info_type}")
|
当完成重定位之后,我们就可以把pc指向我们想要开始运行的地方,接着就可以开始执行代码了
用Qiling来模拟运行
在完成重定向之后,我们就可以来开始执行代码了。在这里,我使用了qiling框架来模拟运行aarch64下的代码。
简单来说,qiling框架就是unicorn加上更高级别的模拟功能。不仅支持处理器仿真,还能够模拟操作系统的行为。这意味着我们可以在模拟器中运行完整的用户态程序,而不仅仅是单个指令或小段代码。qiling还支持文件系统、网络等外围设备的模拟,比较适合整体模拟运行整个程序。
导入函数的实现
在使用上面所讲的重定位方法重定位好二进制后,我们还需要处理外部导入的函数。这边我们可以有两种办法,一种是把依赖库也加载的内存里,然后寻找对应的导出函数并把地址写回。或者我们也可以用hook的形式在python里手动实现需要导入的函数。
比如,libkpk.so需要使用strlen这个函数,那我们就可以hookstrlen的地址并实现strlen的功能,这样就不需要寻找对于的依赖库了,而且还可以追踪函数调用的参数和结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | def hook_strlen(ql: Qiling):
string_address = ql.arch.regs.read(arm64_const.UC_ARM64_REG_X0)
length = 0
while True:
byte = ql.mem.read(string_address + length, 1)
if byte[0] == 0:
break
length += 1
stlogger.log(f"strlen called with {ql.mem.read(string_address, length)}")
ql.arch.regs.write(arm64_const.UC_ARM64_REG_X0, length)
stlogger.callstack.pop(-1)
ql.arch.regs.write(arm64_const.UC_ARM64_REG_PC, ql.arch.regs.read(arm64_const.UC_ARM64_REG_LR))
ql.hook_address(hook_strlen, base_address + 0x0013b970)
|
函数调用追踪
借助qiling的hook,我们同样可以实现对每个函数的调用追踪,并打印出函数的call stack
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | class StackTracerLogger:
def __init__(self,
addr_to_fname,
base_address=0,
print_func_with_symbol_only=False,
print_exit=True,
printer=print
):
self.addr_to_fname = addr_to_fname
self.base_address = base_address
self.printer = printer
self.print_func_with_symbol_only = print_func_with_symbol_only
self.print_exit = print_exit
self.callstack = []
def call(self, func_addr: int, call_from: int):
self.callstack.append(func_addr)
fname = ""
if func_addr in self.addr_to_fname:
fname = self.addr_to_fname[func_addr]
if fname == "" and self.print_func_with_symbol_only:
return
elif fname == "":
fname = f"func_{hex(func_addr - base_address)}"
self.printer(
f"[{len(self.callstack)}]{' ' * len(self.callstack)}calls {fname} from {hex(call_from - self.base_address)}")
def exit(self, exit_addr):
if self.print_exit:
self.printer(f"[{len(self.callstack)}]{' ' * len(self.callstack)}exit at {hex(exit_addr - base_address)}")
if self.callstack:
self.callstack.pop(-1)
def log(self, msg):
self.printer(f"[{len(self.callstack)}]{' ' * (len(self.callstack) + 1)}{msg}")
def select_qiling_backtrace(self, arch_type: QL_ARCH):
if arch_type == QL_ARCH.ARM64:
return self.ql_aarch64_backtrace
def ql_aarch64_backtrace(self, ql: Qiling, address, size):
code = ql.mem.read(address, size)
if size == 4:
opcode = int.from_bytes(code, 'little')
if (int.from_bytes(code, 'little') & 0xFC000000) == 0x94000000:
offset = int.from_bytes(code, 'little') & 0x03FFFFFF
if offset & 0x02000000:
offset -= 0x04000000
target = address + (offset << 2)
self.call(target, address)
elif (opcode & 0xFFFFFC1F) == 0xD63F0000:
reg_num = (opcode >> 5) & 0x1F
reg_val = ql.arch.regs.read(reg_num)
self.call(reg_val, address)
elif opcode == 0xd65f03c0:
self.exit(address)
addr_to_fname = dict((v, k) for k, v in lib.symbols.items())
stlogger = StackTracerLogger(
addr_to_fname, lib.address, print_func_with_symbol_only=True, print_exit=False,
printer=log.info
)
ql.hook_code(stlogger.select_qiling_backtrace(ql.arch.type))
|
效果
我们可以看见程序完美的运行了起来,并打印出了相对应的call stack

call stack 追踪,发现使用了aec ecb作为加密方法
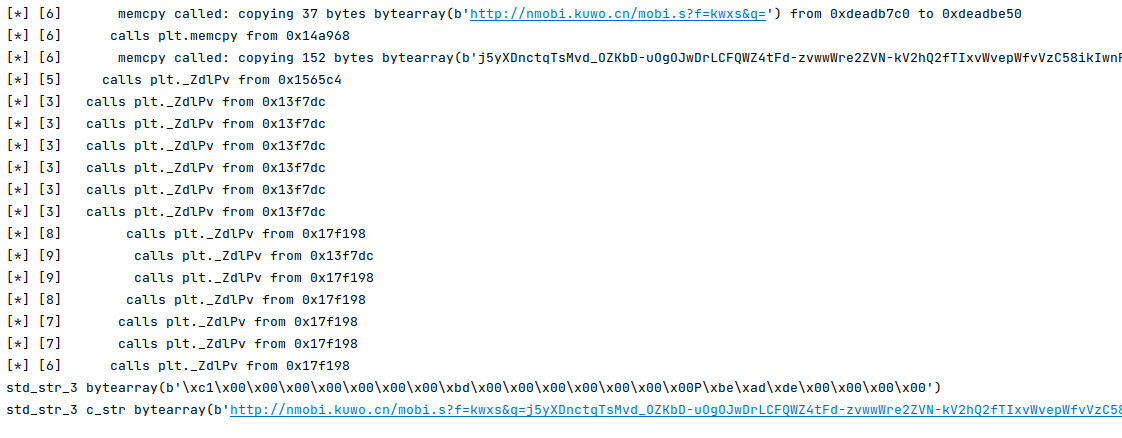
成功完成加密,并读取到了加密后的网址
结语
通过以上的详细分析和步骤演示,我们成功地在一个不同架构的系统上模拟运行了特定的动态链接库函数。这一过程不仅涉及了对ELF文件格式的深入理解,包括其加载和链接的细节,还包括了使用高级工具如unicorn和qiling进行跨平台模拟。
这种方法的优势在于其能够让我们在不具备目标架构硬件的情况下,进行复杂的二进制文件分析和调试。通过模拟运行,我们能够绕过传统物理设备的限制,更加灵活和深入地探索软件内部的运作机制。
然而,虽然技术上可行并且相当强大,这种方法也要求研究者有较高的技术背景知识,包括对操作系统、编译原理及低级编程的深刻理解。因此,建议有志于深入逆向工程和安全研究领域的朋友们,可以以此作为一个学习的起点,逐步深入研究这些高级技术。
通过实践这样的项目,不仅能够增强对ELF文件结构的理解,还能实际应用在安全分析、漏洞研究等多个领域,帮助我们在未来的安全挑战中占据有利地位。希望本文的内容能为你提供实际的帮助和启发,让你在技术的道路上更进一步。
(结语 - by chatgpt)
Reference
- Unicorn实战(二):去掉armariris的字符串加密
- armariris arm32 decode script
- ELF special sections
- Relative relocations and RELR: REL & RELA, basic relocation
- ARM连接时重定位简介(上)
- ELF for the ARM® 64-bit Architecture (AArch64): official specification in pdf
- 一种新的Android Runtime环境仿真及调试方法
- Linux x86 Program Start Up
- How To Write Shared Libraries
- ELF Loader
- Hack ELF Loader:用户态execve
- Program Header Reference
- ELF病毒分析
- C语言:静态库和动态库
- How programs get run: ELF binaries
- ELF 格式解析
- ELF 应用程序二进制接口
- AndroidNativeEmu
