jvm-SQL语句学习+牛客基础39SQL
推荐 原创什么是SQL?
SQL (Structured Query Language:结构化查询语言) 是用于管理关系数据库管理系统(RDBMS)。 SQL 的范围包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。
SQL语法
数据库表
一个数据库通常包含一个或多个表。每个表有一个名字标识(例如:"Websites"),表包含带有数据的记录(行)。SQL 对大小写不敏感:SELECT 与 select 是相同的。
SQL一些最重要的命令(常用)
- SELECT - 从数据库中提取数据
- UPDATE - 更新数据库中的数据
- DELETE - 从数据库中删除数据
- INSERT INTO - 向数据库中插入新数据
- CREATE DATABASE - 创建新数据库
- ALTER DATABASE - 修改数据库
- CREATE TABLE - 创建新表
- ALTER TABLE - 变更(改变)数据库表
- DROP TABLE - 删除表
- CREATE INDEX - 创建索引(搜索键)
- DROP INDEX - 删除索引
select
SELECT 语句用于从数据库中选取数据。结果被存储在一个结果表中,称为结果集。
SELECT column1, column2, ...
FROM table_name;- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。*为查所有字段。
- table_name:要查询的表名称。
select distinct
在表中,一个列可能会包含多个重复值,有时您也许希望仅仅列出不同(distinct)的值。DISTINCT 关键词用于返回唯一不同的值。
SELECT DISTINCT column1, column2, ...
FROM table_name;- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
SQL WHERE
WHERE 子句用于提取那些满足指定条件的记录。
SELECT column1, column2, ...
FROM table_name
WHERE condition;- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
下面的运算符可以在 WHERE 子句中使用:
| 运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| BETWEEN | 在某个范围内 |
| LIKE | 搜索某种模式 |
| IN | 指定针对某个列的多个可能值 |
SQL AND & OR 运算符
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
例子:
SELECT * FROM Websites
WHERE country='CN'
AND alexa > 50;SQL ORDER BY 关键字
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 DESC 关键字。
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;- column1, column2, ...:要排序的字段名称,可以为多个字段。
- ASC:表示按升序排序。
- DESC:表示按降序排序。
SQL INSERT INTO 语句
INSERT INTO 语句用于向表中插入新记录。
第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name
VALUES (value1,value2,value3,...);第二种形式需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);参数说明:
- table_name:需要插入新记录的表名。
- column1, column2, ...:需要插入的字段名。
- value1, value2, ...:需要插入的字段值。
SQL UPDATE 语句
UPDATE table_name
SET column1 = value1, column2 = value2, ...
WHERE condition;- table_name:要修改的表名称。
- column1, column2, ...:要修改的字段名称,可以为多个字段。
- value1, value2, ...:要修改的值,可以为多个值。
- condition:修改条件,用于指定哪些数据要修改。
SQL DELETE 语句
DELETE 语句用于删除表中的行。
DELETE FROM table_name
WHERE condition;- table_name:要删除的表名称。
- condition:删除条件,用于指定哪些数据要删除。
高级操作
SQL SELECT TOP 子句
SELECT TOP 子句用于规定要返回的记录的数目。
SELECT TOP 子句对于拥有数千条记录的大型表来说,是非常有用的。
SELECT column_name(s)
FROM table_name
LIMIT number;SQL LIKE 操作符
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
SELECT column1, column2, ...
FROM table_name
WHERE column LIKE pattern;- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要搜索的字段名称。
- pattern:搜索模式。
例子:
SELECT * FROM Websites
WHERE name LIKE '%k';SQL 通配符
在 SQL 中,通配符与 SQL LIKE 操作符一起使用。
SQL 通配符用于搜索表中的数据。
在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist] 或 [!charlist] | 不在字符列中的任何单一字符 |
例子:
SELECT * FROM Websites
WHERE url LIKE 'https%';IN 操作符
IN 操作符允许您在 WHERE 子句中规定多个值。
SELECT column1, column2, ...
FROM table_name
WHERE column IN (value1, value2, ...);- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要查询的字段名称。
- value1, value2, ...:要查询的值,可以为多个值。
SQL BETWEEN 操作符
BETWEEN 操作符选取介于两个值之间的数据范围内的值。这些值可以是数值、文本或者日期。
SELECT column1, column2, ...
FROM table_name
WHERE column BETWEEN value1 AND value2;- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table_name:要查询的表名称。
- column:要查询的字段名称。
- value1:范围的起始值。
- value2:范围的结束值。
SQL 别名
通过使用 SQL,可以为表名称或列名称指定别名。
基本上,创建别名是为了让列名称的可读性更强。
-- 列的 SQL 别名语法 -->
SELECT column_name AS alias_name
FROM table_name;-- 表的 SQL 别名语法 -->
SELECT column_name(s)
FROM table_name AS alias_name;SQL JOIN
SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)。 SQL INNER JOIN 从多个表中返回满足 JOIN 条件的所有行。
在 SQL 中使用 INNER JOIN ... ON ... 时,ON 后面跟的连接条件用于指定如何将两个表中的行匹配起来。这个连接条件通常涉及两个表中的一个或多个字段,SQL 会根据这些条件找到两个表中满足条件的行的交集。
然后,基于这个条件匹配的结果集,SELECT 语句后面跟的字段将决定输出表格中包含哪些列。简单来说,INNER JOIN 会连接两个表中满足 ON 后面条件的那些行,而 SELECT 则用来选择需要显示的字段。
SELECT column1, column2, ...
FROM table1
JOIN table2 ON condition;- column1, column2, ...:要选择的字段名称,可以为多个字段。如果不指定字段名称,则会选择所有字段。
- table1:要连接的第一个表。
- table2:要连接的第二个表。
- condition:连接条件,用于指定连接方式。
SQL INNER JOIN 关键字
INNER JOIN 关键字在表中存在至少一个匹配时返回行。
SQL INNER JOIN 语法
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;或:
SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name=table2.column_name;- columns:要显示的列名。
- table1:表1的名称。
- table2:表2的名称。
- column_name:表中用于连接的列名。
SQL LEFT JOIN 关键字
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;SQL RIGHT JOIN 关键字
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。和left差不多,只不过是反过来
SQL FULL OUTER JOIN 关键字
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行.
FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;SQL UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
SQL UNION 语法
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
SQL UNION ALL 语法
SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;注释:UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
MySQL Date 函数
下面的表格列出了 MySQL 中最重要的内建日期函数:
| 函数 | 描述 |
|---|---|
| NOW() | 返回当前的日期和时间 |
| CURDATE() | 返回当前的日期 |
| CURTIME() | 返回当前的时间 |
| DATE() | 提取日期或日期/时间表达式的日期部分 |
| EXTRACT() | 返回日期/时间的单独部分 |
| DATE_ADD() | 向日期添加指定的时间间隔 |
| DATE_SUB() | 从日期减去指定的时间间隔 |
| DATEDIFF() | 返回两个日期之间的天数 |
| DATE_FORMAT() | 用不同的格式显示日期/时间 |
MySQL 使用下列数据类型在数据库中存储日期或日期/时间值:
- DATE - 格式:YYYY-MM-DD
- DATETIME - 格式:YYYY-MM-DD HH:MM:SS
- TIMESTAMP - 格式:YYYY-MM-DD HH:MM:SS
- YEAR - 格式:YYYY 或 YY
SQL ISNULL()、NVL()、IFNULL() 和 COALESCE() 函数
请看下面的 "Products" 表:
| P_Id | ProductName | UnitPrice | UnitsInStock | UnitsOnOrder |
|---|---|---|---|---|
| 1 | Jarlsberg | 10.45 | 16 | 15 |
| 2 | Mascarpone | 32.56 | 23 | |
| 3 | Gorgonzola | 15.67 | 9 | 20 |
假如 "UnitsOnOrder" 是可选的,而且可以包含 NULL 值。
我们使用下面的 SELECT 语句:
SELECT ProductName,UnitPrice*(UnitsInStock+UnitsOnOrder)
FROM Products
在上面的实例中,如果有 "UnitsOnOrder" 值是 NULL,那么结果是 NULL。
微软的 ISNULL() 函数用于规定如何处理 NULL 值。
NVL()、IFNULL() 和 COALESCE() 函数也可以达到相同的结果。
SQL函数
AVG() 函数
AVG() 函数返回数值列的平均值。
SQL AVG() 语法
SELECT AVG(column_name) FROM table_nameSQL COUNT() 函数
COUNT() 函数返回匹配指定条件的行数。
SQL COUNT(column_name) 语法
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
SELECT COUNT(column_name) FROM table_name;SQL COUNT(*) 语法
COUNT(*) 函数返回表中的记录数:
SELECT COUNT(*) FROM table_name;SQL COUNT(DISTINCT column_name) 语法
COUNT(DISTINCT column_name) 函数返回指定列的不同值的数目:
SELECT COUNT(DISTINCT column_name) FROM table_name;FIRST() 函数
FIRST() 函数返回指定的列中第一个记录的值。
SQL FIRST() 语法
SELECT FIRST(column_name) FROM table_name;SELECT column_name FROM table_name
ORDER BY column_name ASC
LIMIT 1;LAST() 函数
LAST() 函数返回指定的列中最后一个记录的值。
SQL LAST() 语法
SELECT LAST(column_name) FROM table_name;SELECT column_name FROM table_name
ORDER BY column_name DESC
LIMIT 1;MAX() 函数
MAX() 函数返回指定列的最大值。
SQL MAX() 语法
SELECT MAX(column_name) FROM table_name;MIN() 函数
MIN() 函数返回指定列的最大值。
SQL MIN() 语法
SELECT MIN(column_name) FROM table_name;SUM() 函数
SUM() 函数返回数值列的总数。
SQL SUM() 语法
SELECT SUM(column_name) FROM table_name;GROUP BY 语句
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
SQL GROUP BY 语法
SELECT column_name, aggregate_function(column_name)
FROM table_name
WHERE column_name operator value
GROUP BY column_name;HAVING 子句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
SQL HAVING 语法
SELECT column1, aggregate_function(column2)
FROM table_name
GROUP BY column1
HAVING condition;column1:要检索的列。aggregate_function(column2):一个聚合函数,例如SUM、COUNT、AVG等,应用于column2的值。table_name:要从中检索数据的表。GROUP BY column1:根据column1列的值对数据进行分组。HAVING condition:一个条件,用于筛选分组的结果。只有满足条件的分组会包含在结果集中。
EXISTS 运算符
EXISTS 运算符用于判断查询子句是否有记录,如果有一条或多条记录存在返回 True,否则返回 False。
SQL EXISTS 语法
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);
MID() 函数
MID() 函数用于从文本字段中提取字符。
SQL MID() 语法
SELECT MID(column_name[,start,length]) FROM table_name;| 参数 | 描述 |
|---|---|
| column_name | 必需。要提取字符的字段。 |
| start | 必需。规定开始位置(起始值是 1)。 |
| length | 可选。要返回的字符数。如果省略,则 MID() 函数返回剩余文本。 |
LEN() 函数
LEN() 函数返回文本字段中值的长度。
MySQL 中函数为 LENGTH():
SELECT LENGTH(column_name) FROM table_name;ROUND() 函数
ROUND() 函数用于把数值字段舍入为指定的小数位数。
SQL ROUND() 语法
SELECT ROUND(column_name,decimals) FROM TABLE_NAME;| 参数 | 描述 |
|---|---|
| column_name | 必需。要舍入的字段。 |
| decimals | 可选。规定要返回的小数位数。 |
SQL进阶
子查询
子查询用于为主查询返回其所需数据,或者对检索数据进行进一步的限制,通常将一个查询(子查询)的结果作为另一个查询(主查询)的数据来源或判断条件,常见的子查询有WHERE子查询,HAVING子查询,FROM子查询,SELECT子查询,EXISTS子查询。
子查询是一种嵌套在其他 SQL 查询的 WHERE 子句中的查询,可以在 SELECT、INSERT、UPDATE 和 DELETE 语句中,同逻辑运算符一起使用。
使用子查询必须遵循以下几个规则:
-
子查询必须括在圆括号中。
-
子查询的 SELECT 子句中只能有一个列。
-
子查询不能使用 ORDER BY,在子查询中,GROUP BY 可以起到同 ORDER BY 相同作用。
-
返回多行数据的子查询只能同多值操作符一起使用,比如 IN 操作符。
-
子查询不能直接用在聚合函数中。
-
BETWEEN 不能同子查询一起使用,但 BETWEEN 操作符可以用在子查询中。
-
使用子查询查询薪水大于8000的员工的所有信息,首先内部查询薪水大于8000的ID,然后外部使用一个WHERE查询即可得到结果。
SELECT *
FROM SALARY
WHERE ID IN (SELECT ID
FROM SALARY
WHERE SAL > 8000);使用子查询的另一方法是创建计算字段,创建计算字段需要使用聚合函数,例如count,sum,avg,max,min等,这里首先计算平均薪水作为一个内查询,然后在外部使用WHERE子句进行查询,得出薪资比平均薪资低的员工的所有信息。
SELECT * FROM SALARY
WHERE SAL < (SELECT AVG(SAL)
FROM SALARY);窗口函数
窗口函数与数据分组功能相似,可指定数据窗口进行统计分析,但窗口函数与数据分组又有所区别,窗口函数对每个组返回多行,而数据分组对每个组只返回一行;窗口函数指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,而数据分组是针对所有数据进行统计,窗口函数的写法如下。
<窗口函数> over (partition by <用于分组的列名>order by <用于排序的列名>)窗口函数主要有两种,一种是专用窗口函数,包括rank、dense_rank、row_number等。另一种是聚合函数,包括sum、avg、count、max、min等,下面逐一介绍窗口函数的五个功能,分别是聚合、排序、极值、移动、切片。
计算各国家总金额就要对各个国家分组,这里分组使用的是PARTITION by,PARTITION by的功能与GROUP BY的功能类似,指定按照那一列进行分组,用country分组求和,则每个country的输出结果一致。
SELECT *, SUM(payment) OVER() as Total_payment,
SUM(payment) OVER(PARTITION by country) as country_payment
from pay;这里使用SQL中常用的向下累计求和的方法,当使用order by时,没有rows between则意味着窗口是从起始行到当前行,所以对不同国家进行累加求和操作。
SELECT *, SUM(payment) OVER() as Total_payment,SUM(payment) OVER(PARTITION by country) as country_payment,
SUM(payment) OVER(PARTITION by country ORDER BY payment DESC) as order_payment
from pay;基础查询
1.查询所有列
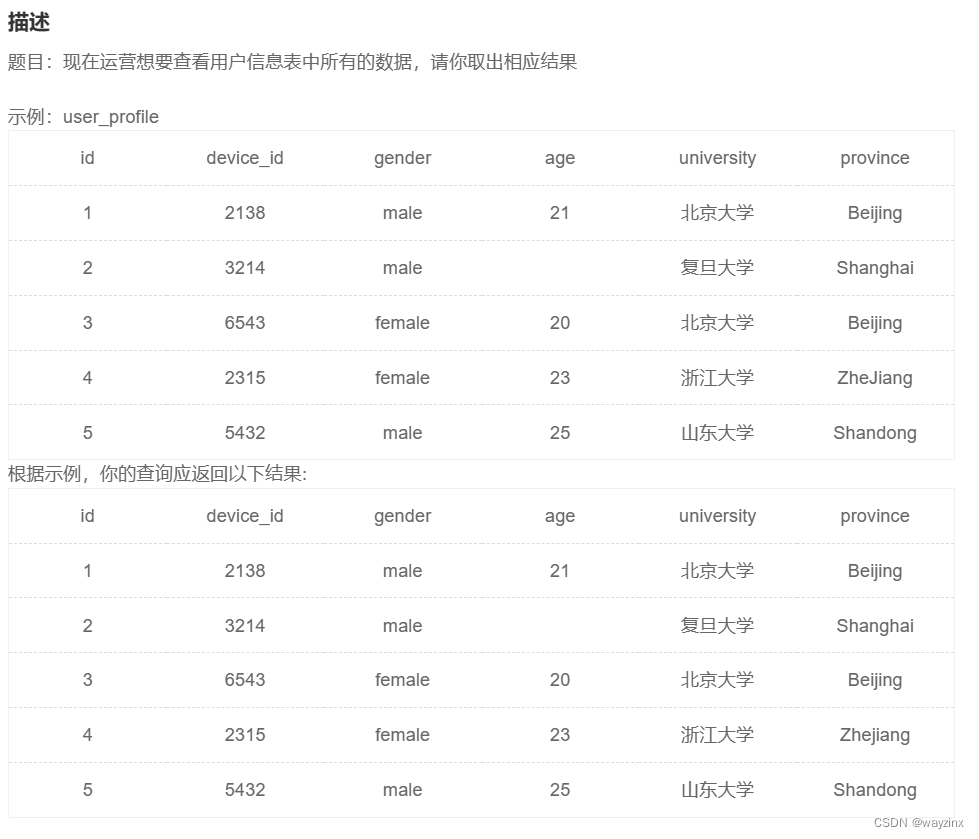
select * from user_profile2.查询多列
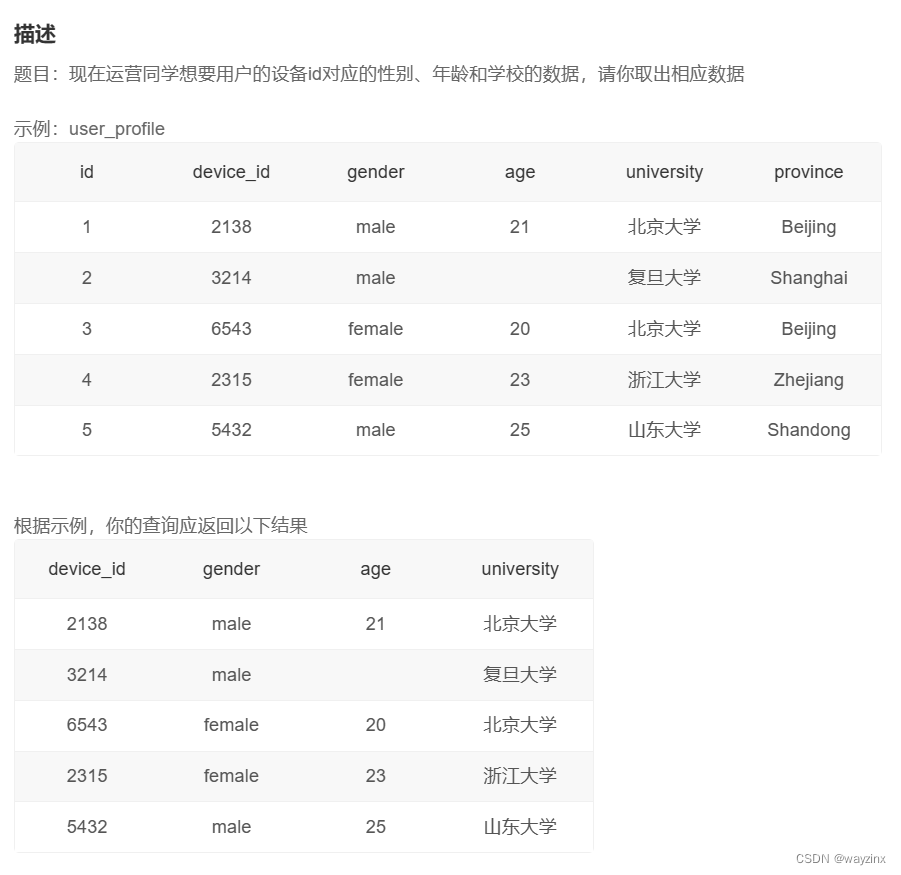
select device_id,gender,age,university from user_profile简单处理查询结果
3.查询结果去重
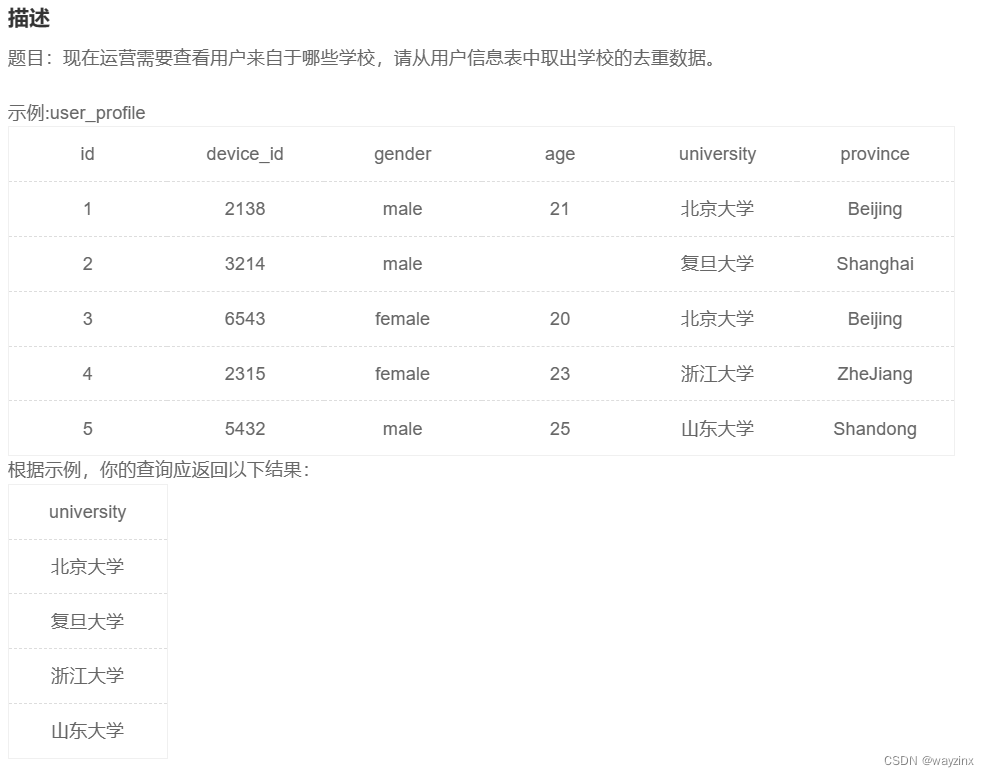
select distinct university from user_profile4.查询结果限制返回行数
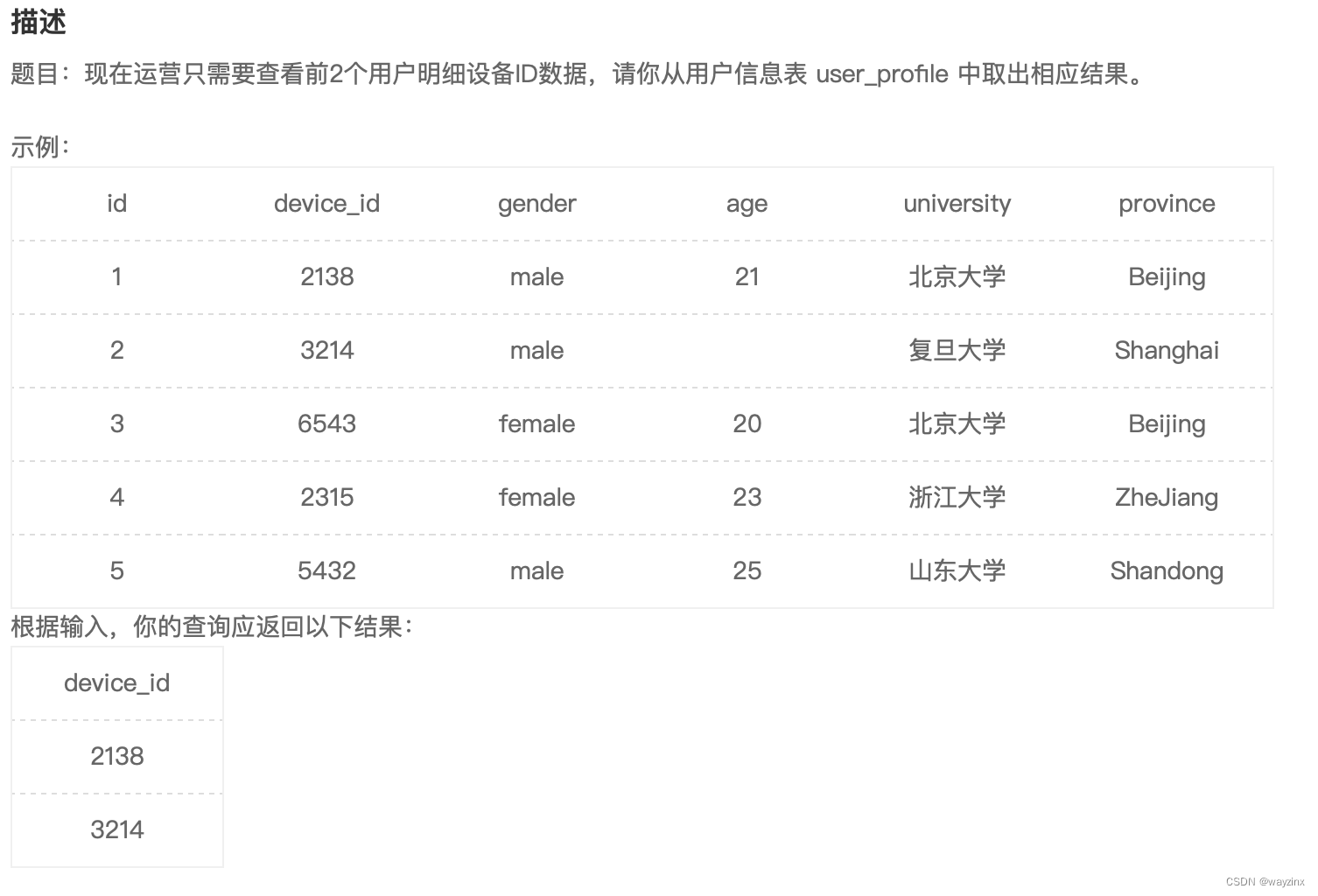
select device_id from user_profile where id<=25.将查询后的列重新命名
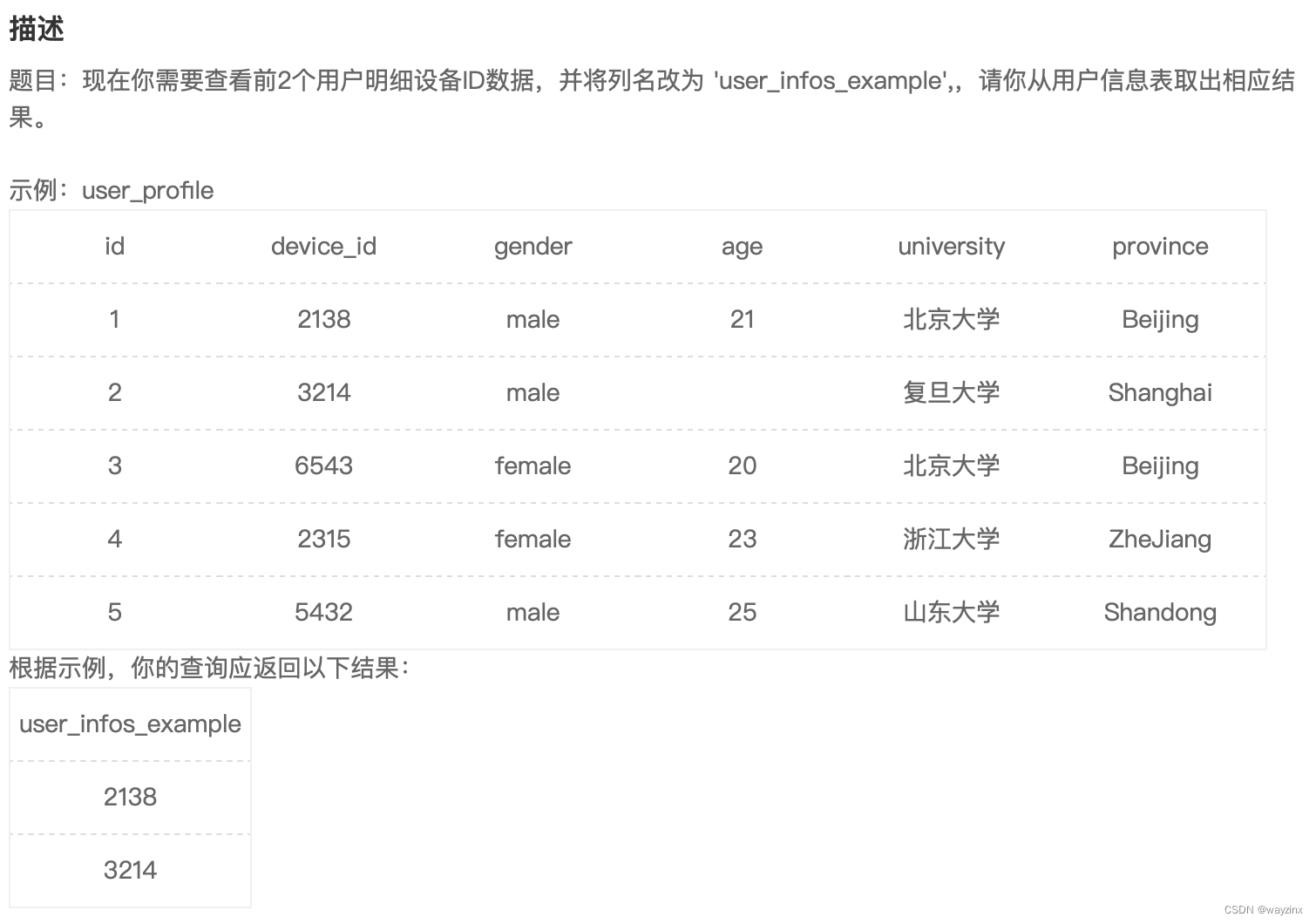
select device_id as user_infos_example from user_profile where id <= 2基础操作符
6.查找学校是北大的学生信息

select device_id,university from user_profile where university = '北京大学'7.查找年龄大于24岁的用户信息

8.查找某个年龄段的用户信息
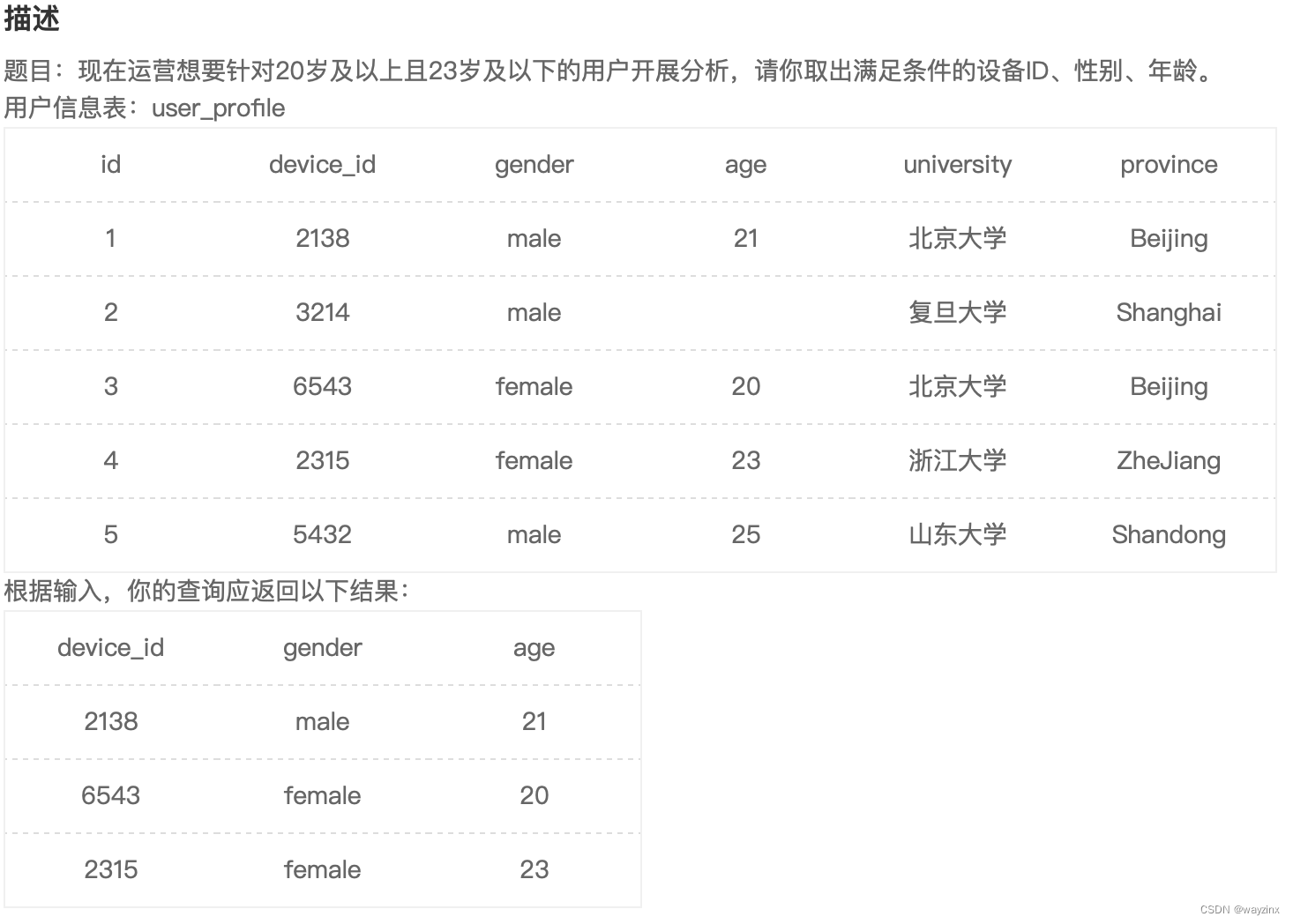
select device_id,gender,age from user_profile where age >=20 and age <= 239.查找除复旦大学的用户信息
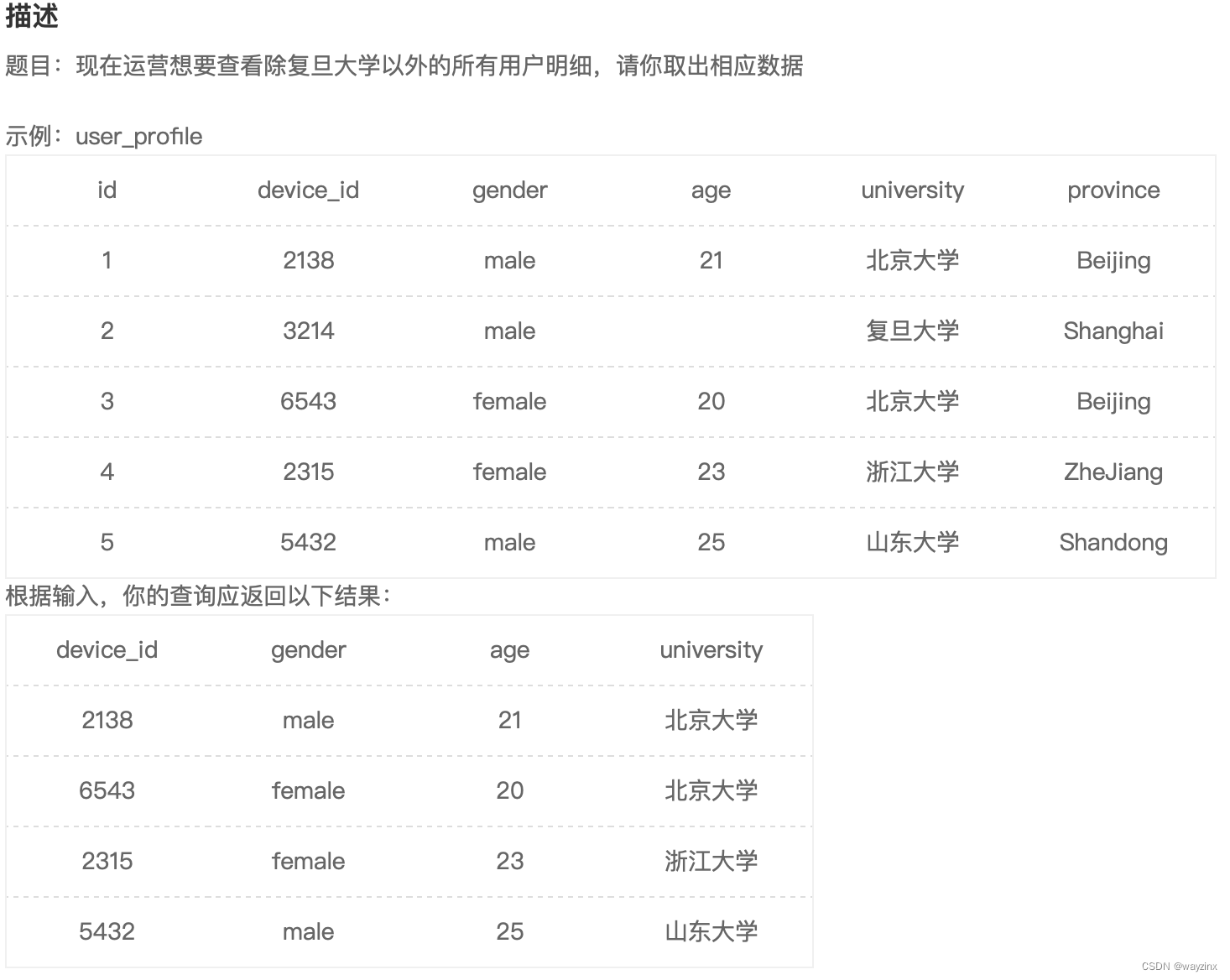
select device_id,gender,age,university from user_profile where university != '复旦大学'10.用where过滤空值练习

select device_id,gender,age,university from user_profile where age!=' '11.高级操作符练习(1)

select device_id,gender,age,university,gpa from user_profile where gpa > 3.5 and gender = 'male'12.高级操作符练习(2)

select device_id,gender,age,university,gpa from user_profile where gpa > 3.7 or university = '北京大学'13.where in 和 Not in
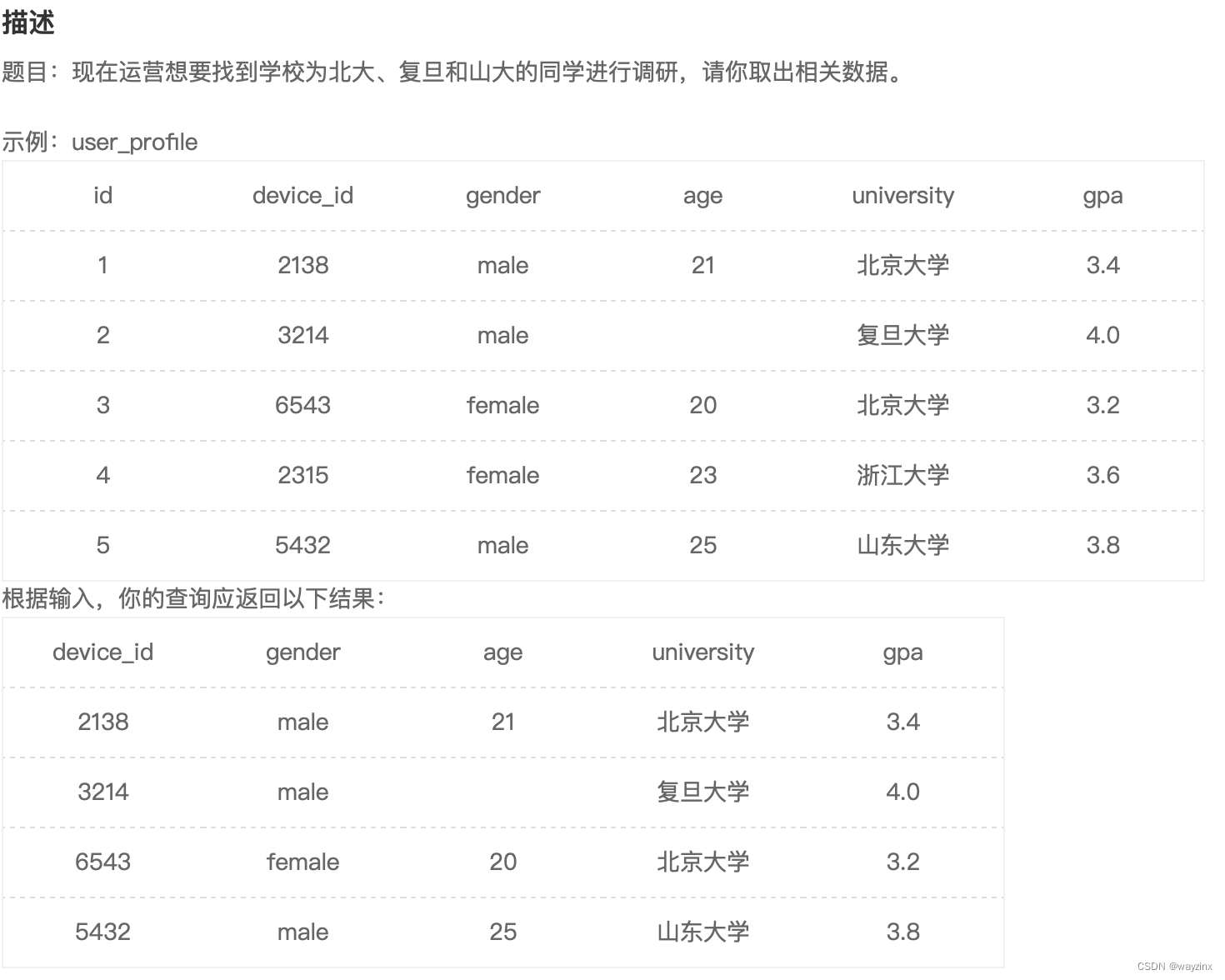
select device_id,gender,age,university,gpa from user_profile where university in ('北京大学','复旦大学','山东大学')14.操作符混合运用
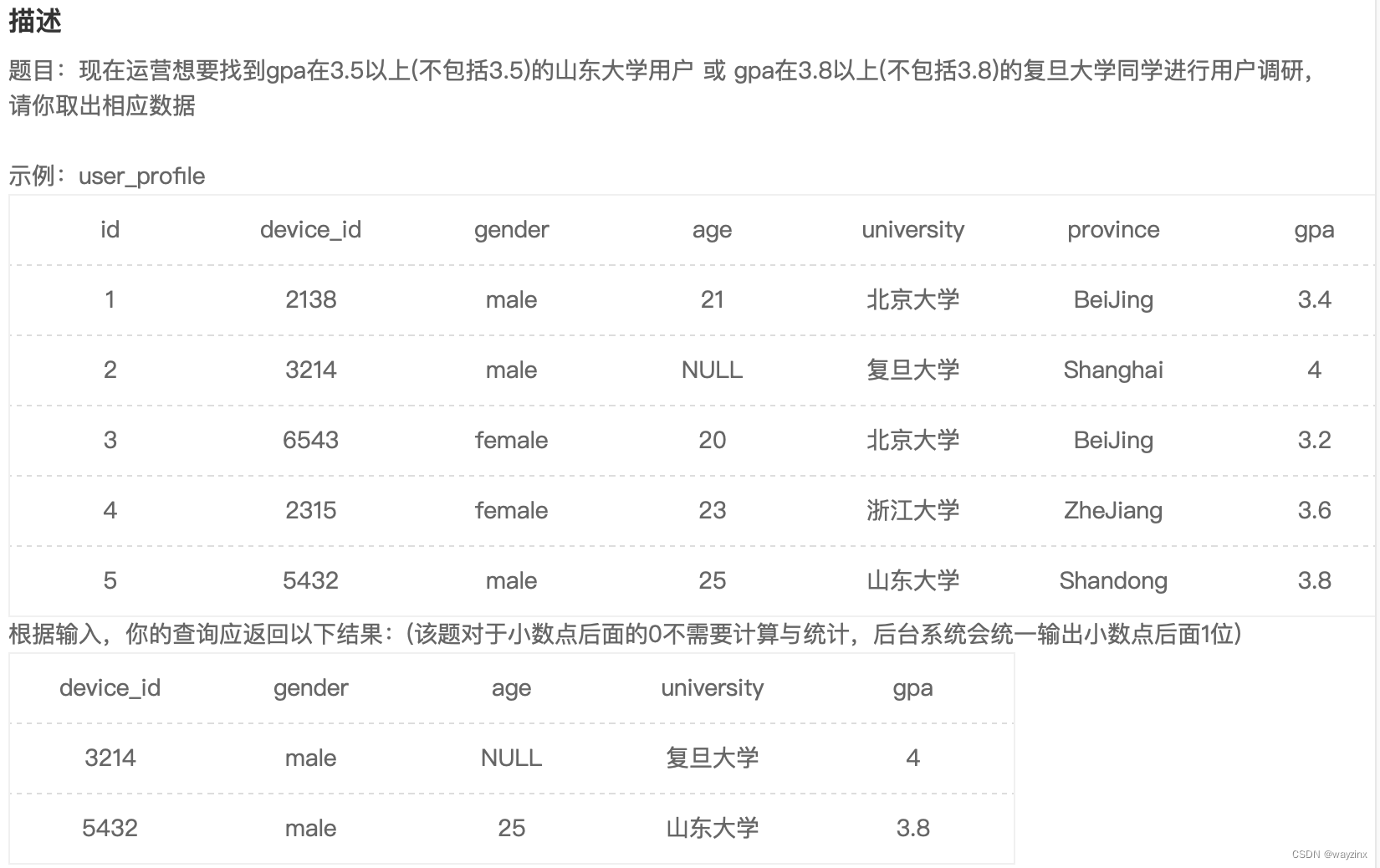
select device_id,gender,age,university,gpa from user_profile where (gpa > 3.5 and university = '山东大学') or (gpa > 3.8 and university = '复旦大学')15.查看学校名称中含北京的用户
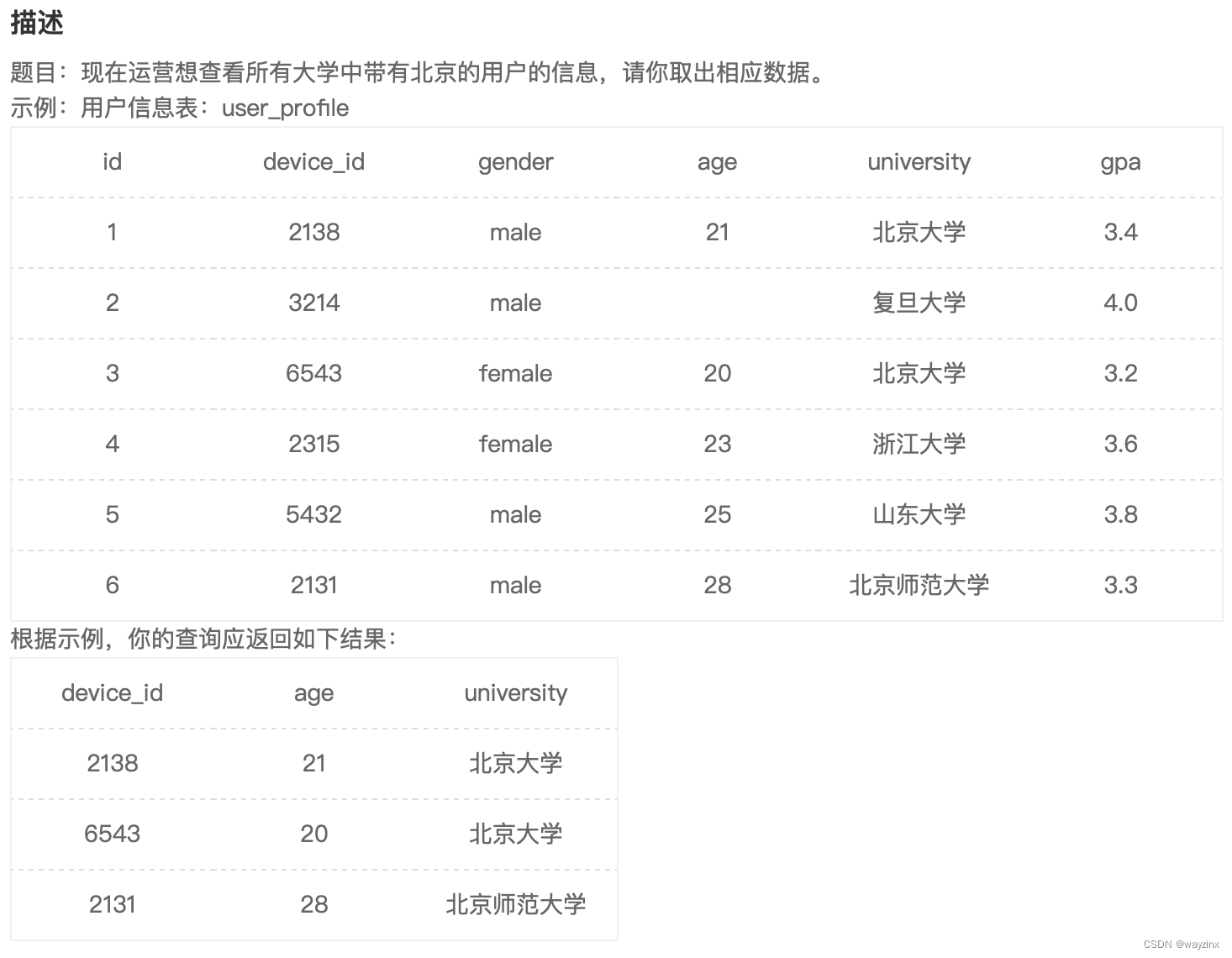
select device_id,age,university from user_profile where university like '%北京%'16.查找GPA最高值
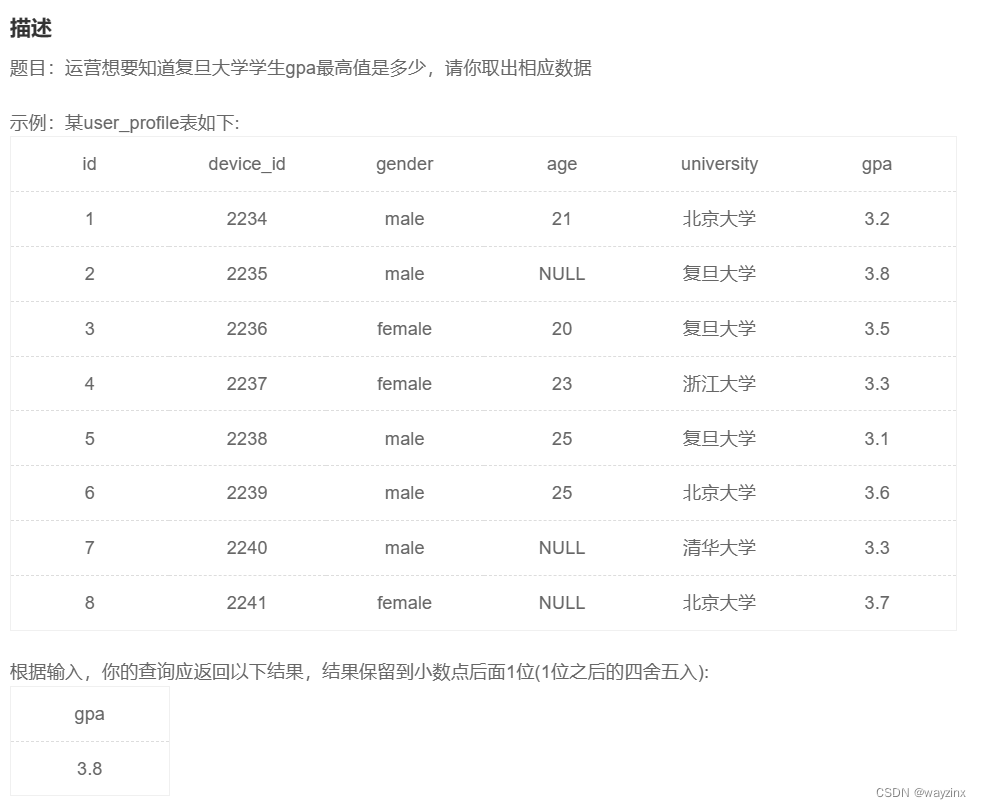
select max(gpa) from user_profile 17.计算男生人数以及平均GPA

select count(gender) as male_num,avg(gpa)
from user_profile
where gender = 'male'18.分组计算练习题

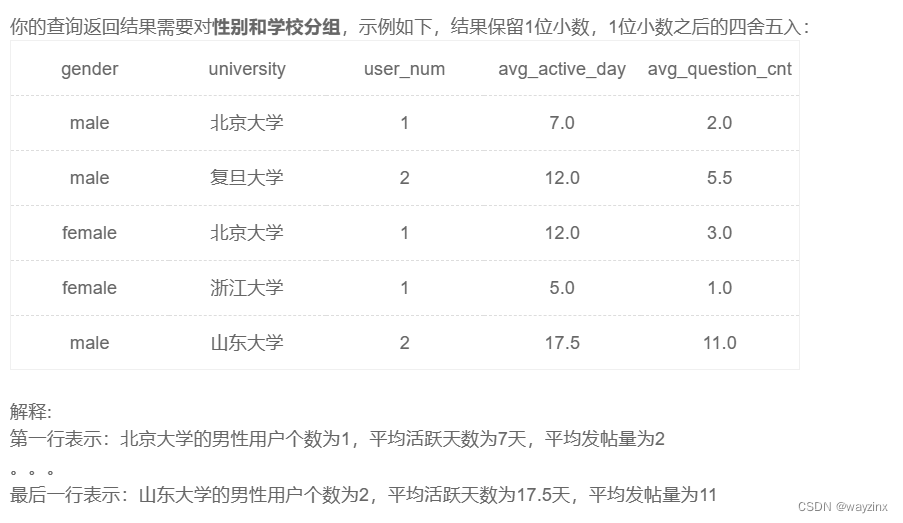
select gender,university,
count(device_id) as user_num,
avg(active_days_within_30) as avg_active_day,
avg(question_cnt) as avg_question_cnt
from user_profile
group by gender,university19.分组过滤练习题

select university,
avg(question_cnt) as avg_question_cnt,
avg(answer_cnt) as avg_answer_cnt
from user_profile
group by university
having avg_question_cnt < 5
or avg_answer_cnt < 2020.分组排序练习题

select university,
avg(question_cnt) as avg_question_cnt
from user_profile
group by university
order by avg_question_cnt 21.浙江大学用户题目回答情况


select device_id, question_id, result
from question_practice_detail
where device_id in (
select device_id
from user_profile
where university = '浙江大学'
)22.统计每个学校的答过题的用户的平均答题数

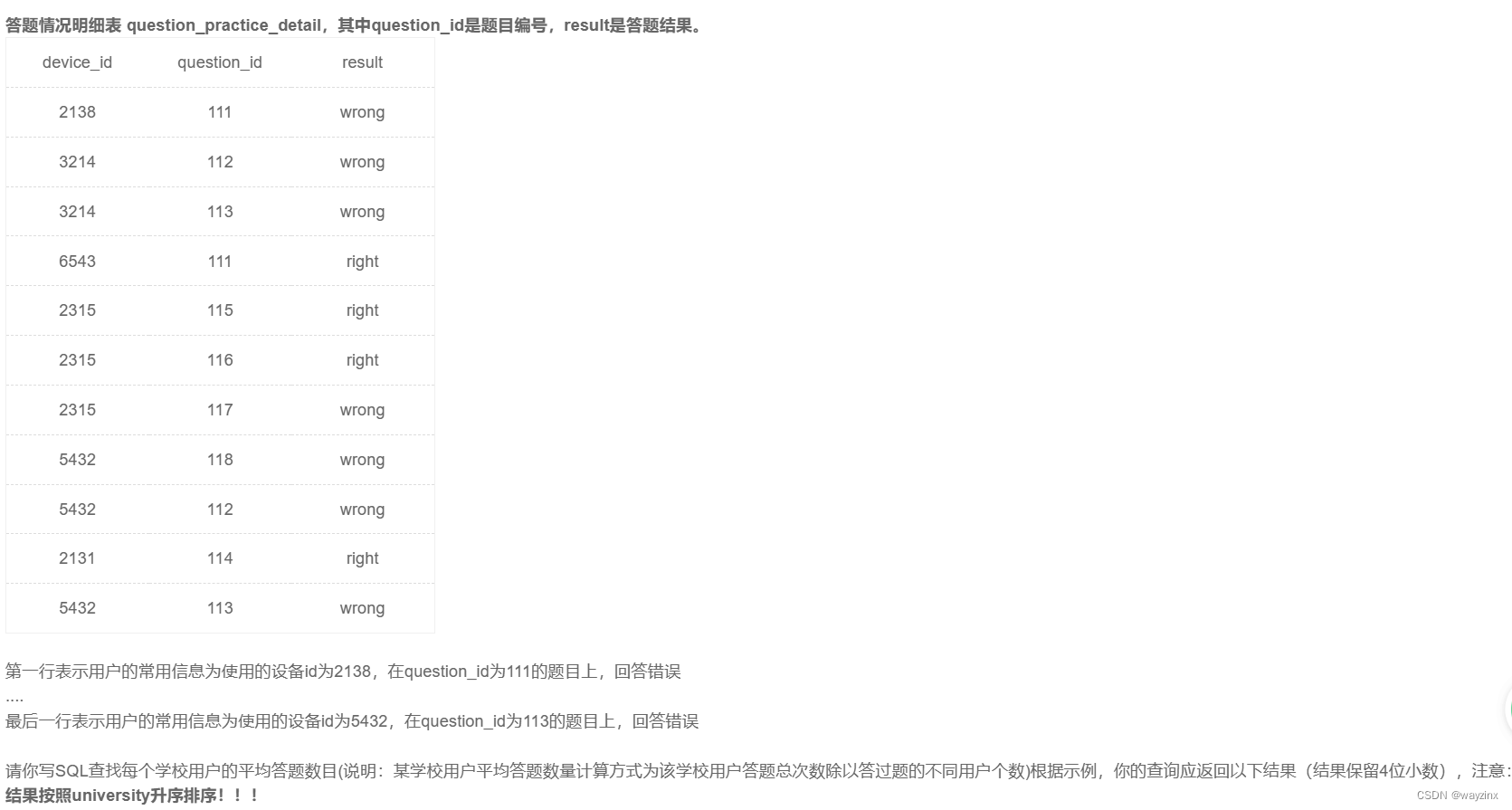

select university,
count(b.question_id)/count(distinct a.device_id) as avg_answer_cnt
from user_profile as a
inner join question_practice_detail as b
on a.device_id = b.device_id
group by a.university23.统计每个学校各难度的用户平均刷题数
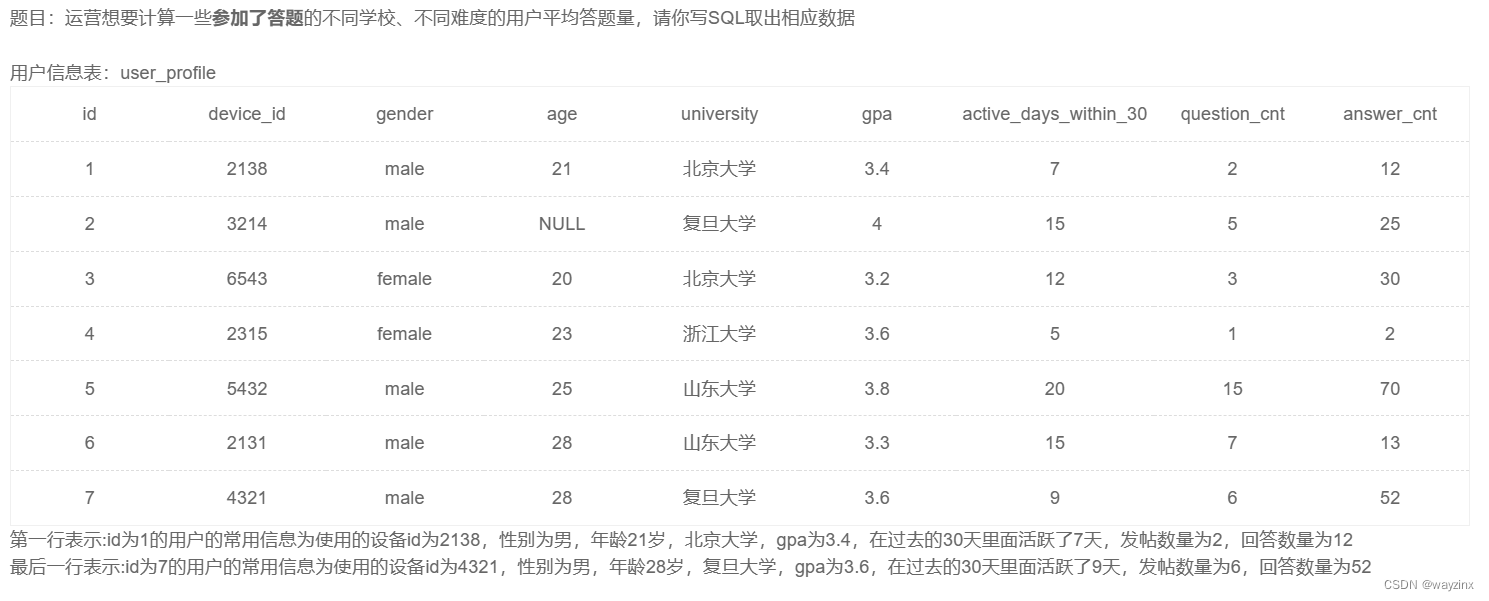
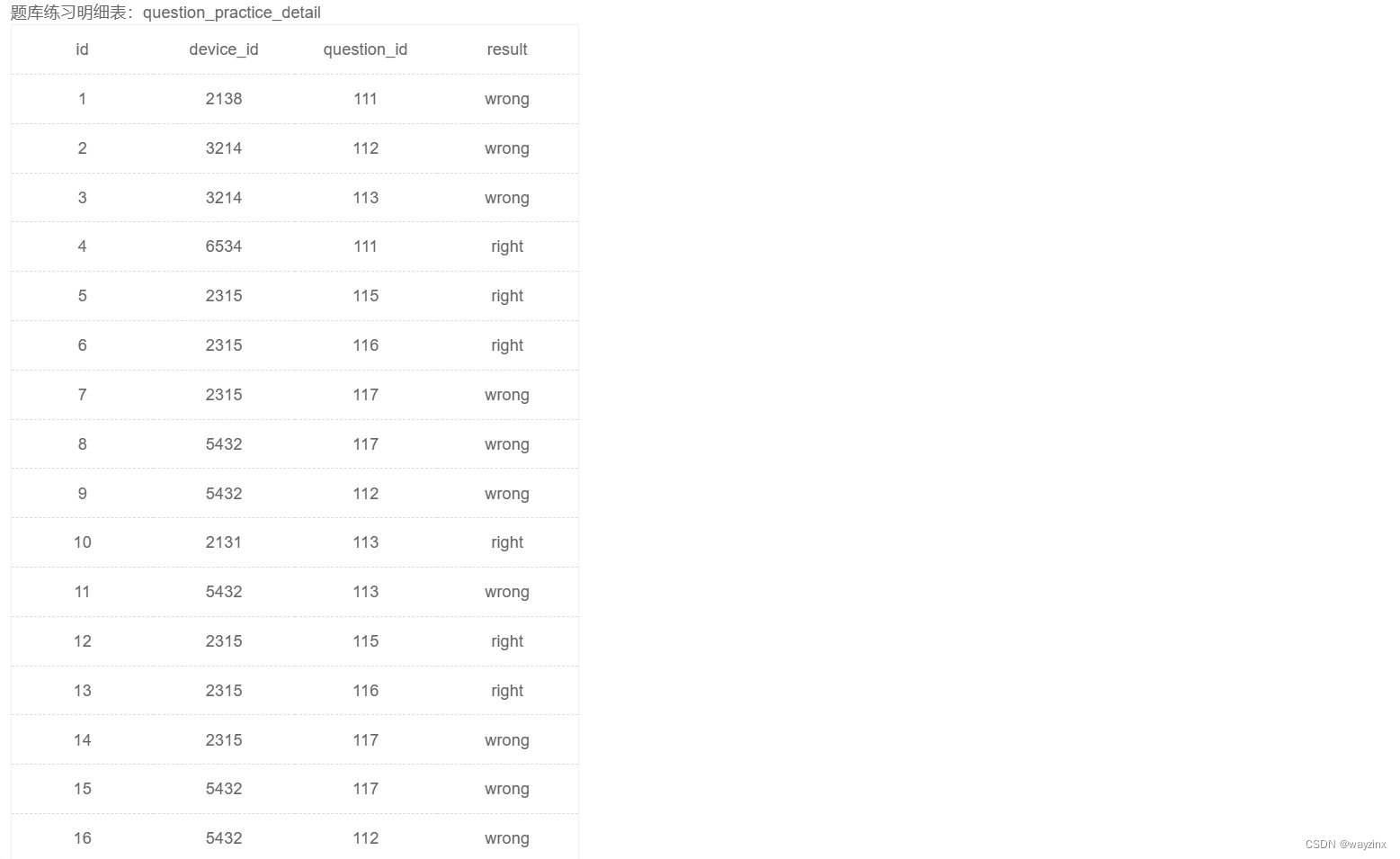


select a.university,
c.difficult_level,
count(b.question_id) / count(distinct b.device_id) as avg_answer_cnt
from question_practice_detail as b
left join user_profile as a
on a.device_id = b.device_id
left join question_detail as c
on b.question_id = c.question_id
group by a.university, c.difficult_level24.统计每个用户的平均刷题数
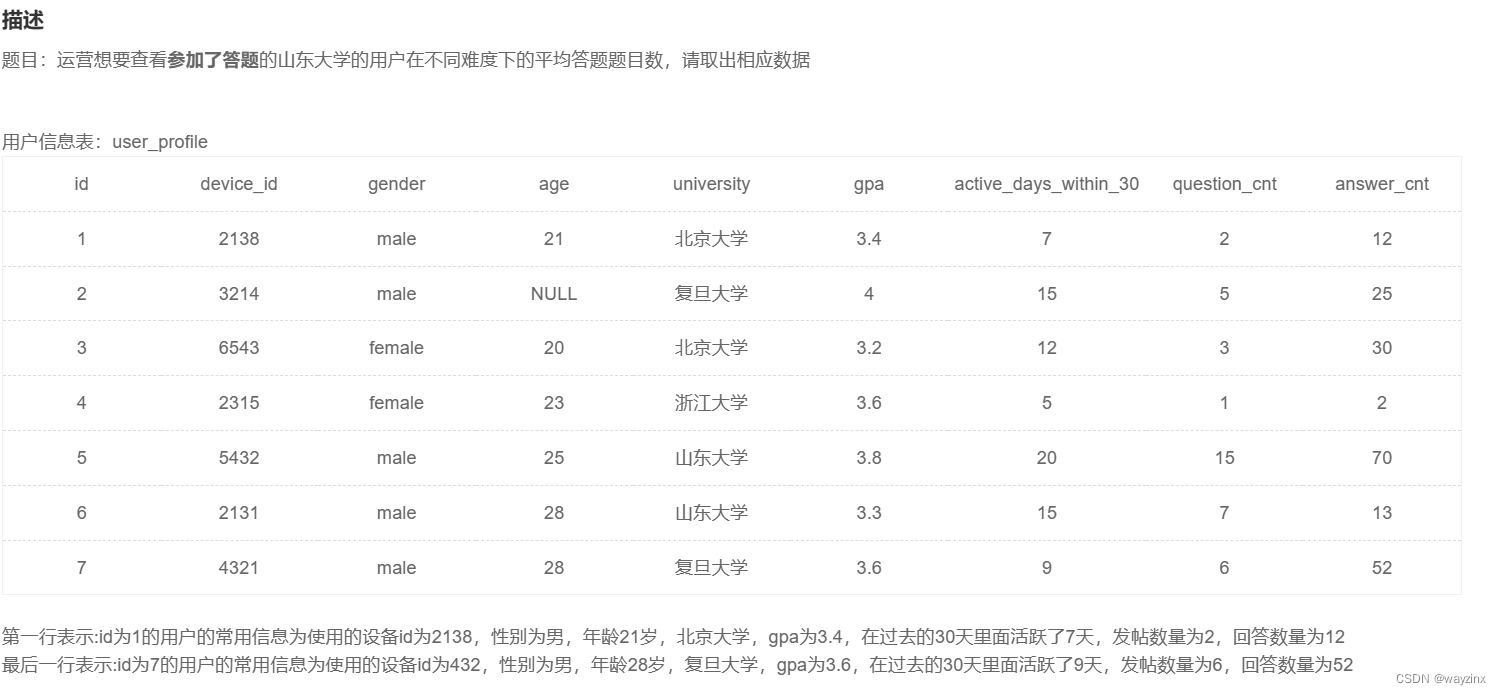



select university, difficult_level, count(b.question_id)/count(distinct b.device_id) as avg_answer_cnt
from question_practice_detail as b,
user_profile as a,
question_detail as c
where a.university = '山东大学'
and b.device_id = a.device_id
and b.question_id = c.question_id
group by c.difficult_level25.查找山东大学或者性别为男生的信息
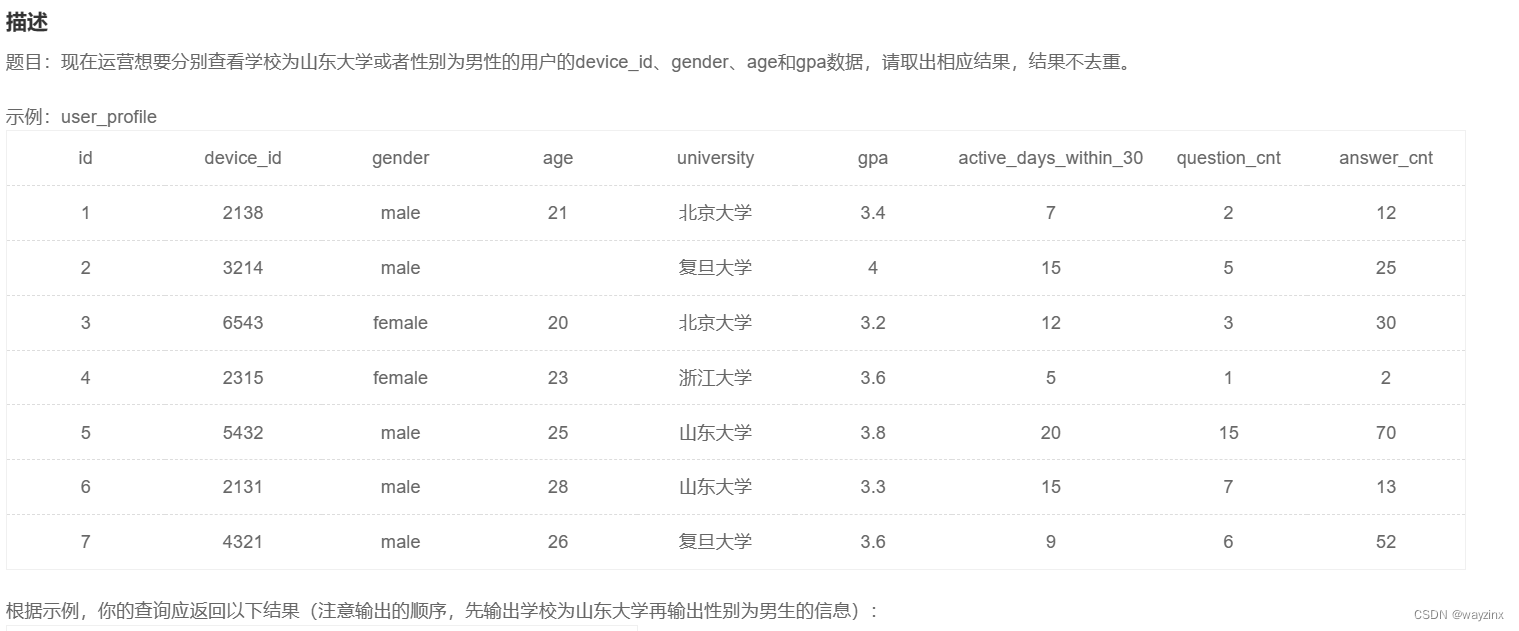
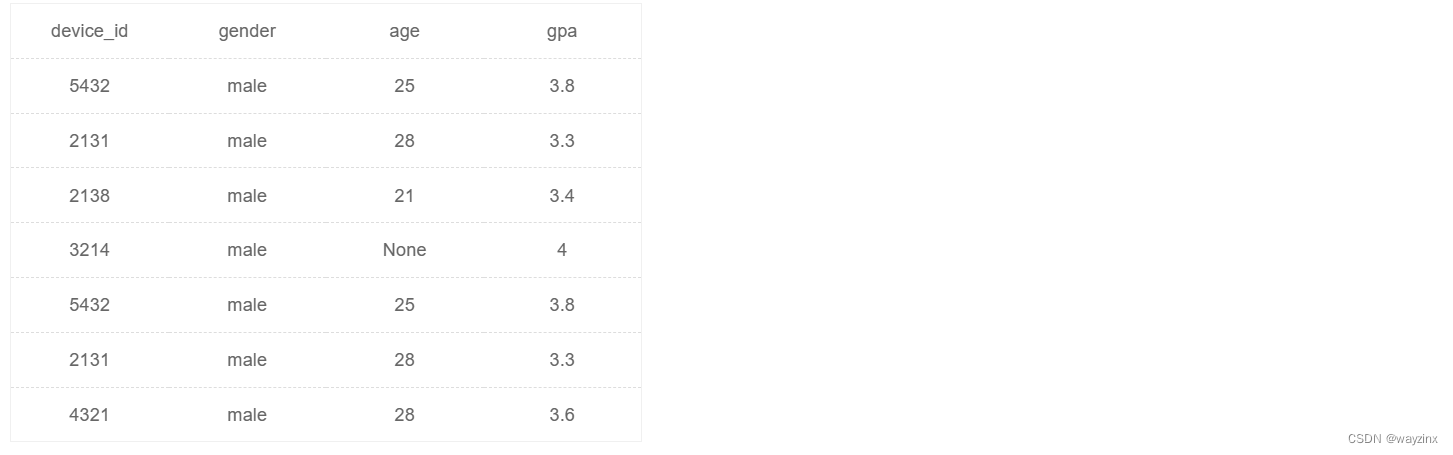
select device_id, gender, age, gpa
from user_profile
where university = '山东大学'
union all
select device_id, gender, age, gpa
from user_profile
where gender = 'male'26.计算25以上和以下的用户数量
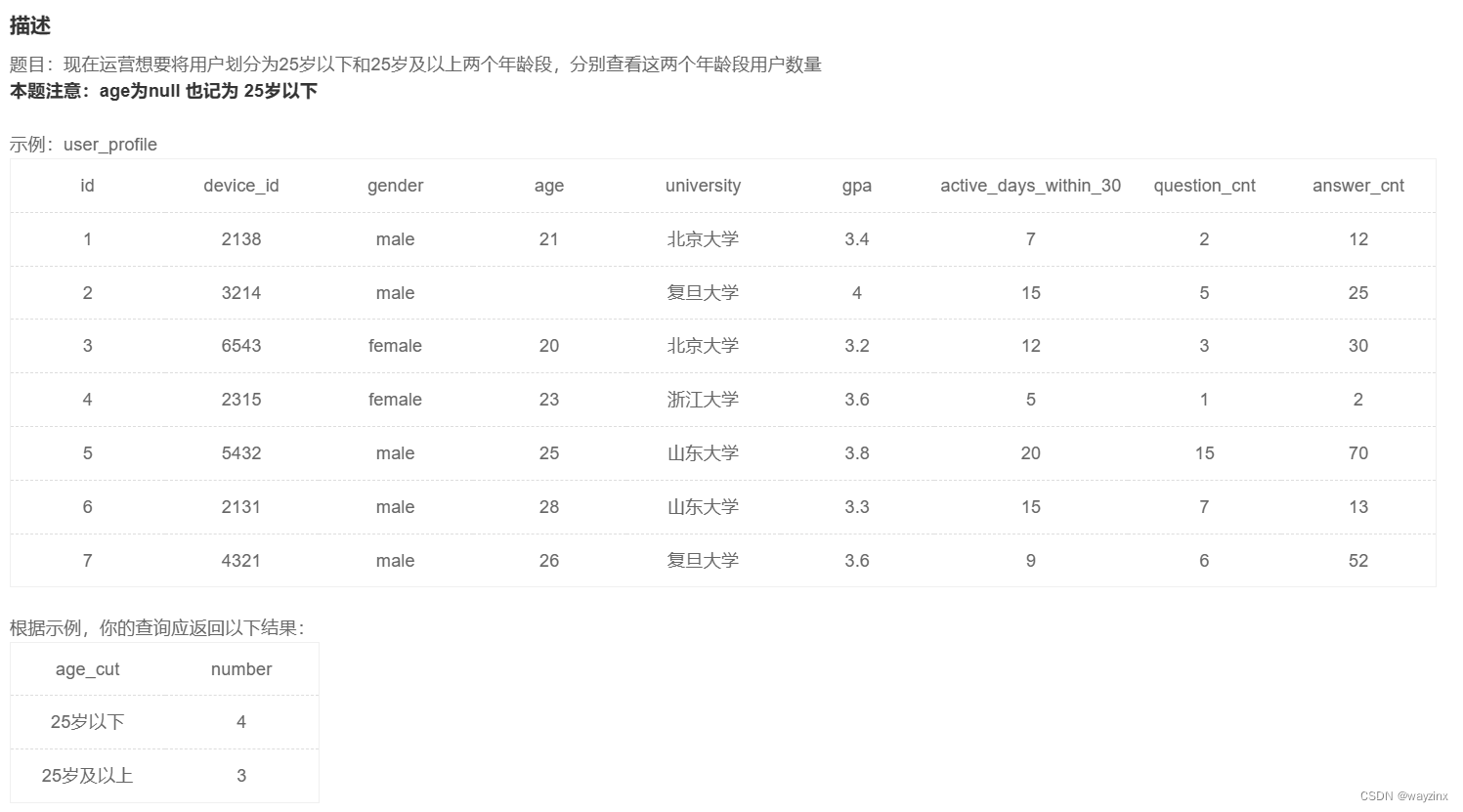
select
case
when age <25 or age is null then '25岁以下'
when age >= 25 then '25岁及以上'
end age_cut,count(*) as number
from user_profile
group by age_cut27.查看不同年龄段的用户明细


select device_id,gender,
case
when age >=20 and age <=24 then '20-24岁'
when age >24 then '25岁及以上'
else '其他'
end age_cut
from user_profile
28.计算用户8月每天的练题数量
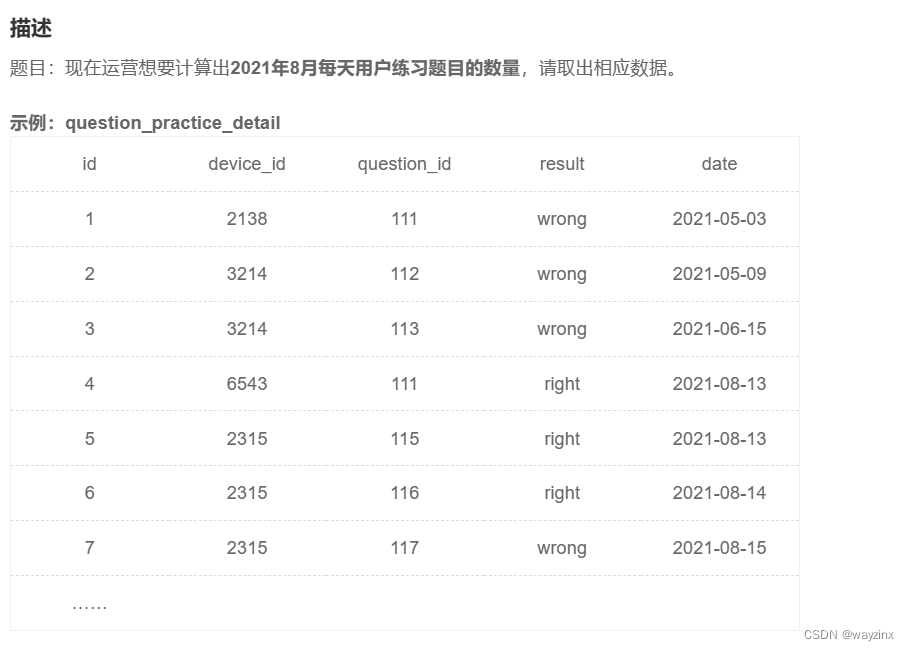

select day(date) as day, count(question_id) as question_cnt
from question_practice_detail
where year(date) = 2021
and month(date) = 8
group by date29.计算用户的平均次日留存率
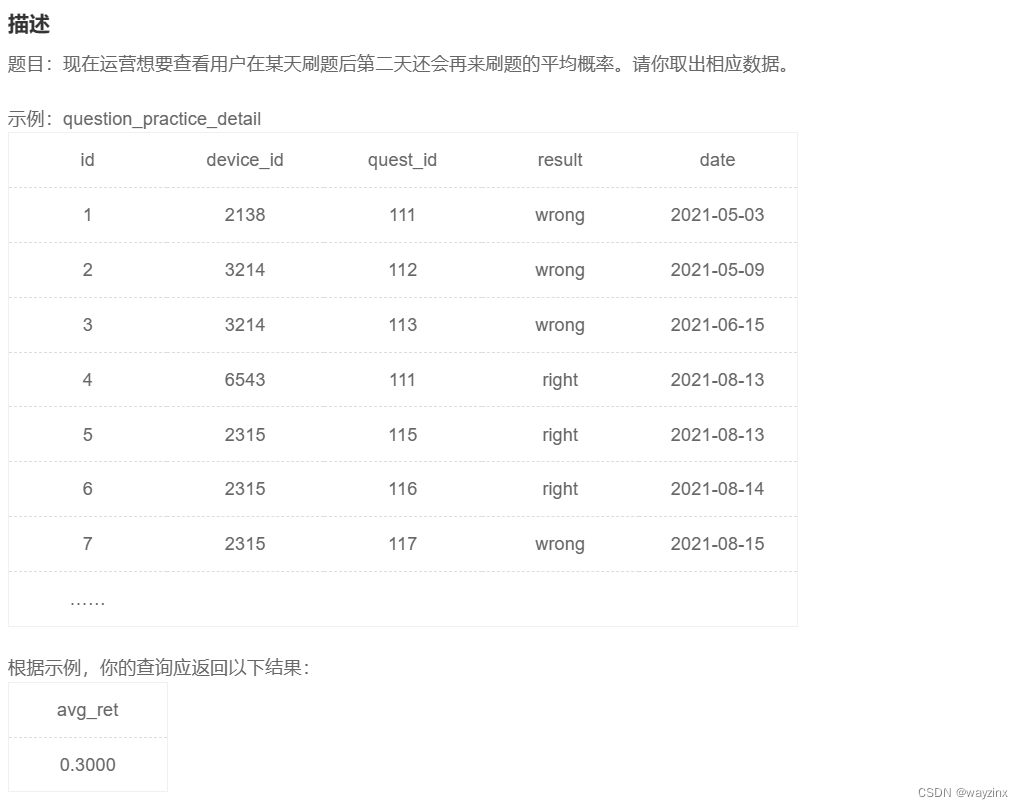
SELECT COUNT(distinct q2.device_id,q2.date)/count(DISTINCT q1.device_id,q1.date) as avg_ret
from question_practice_detail as q1 left outer join question_practice_detail as q2
on q1.device_id=q2.device_id and DATEDIFF(q2.date,q1.date)=130.统计每种性别的人数

select substring_index(profile,',',-1) as gender,
count(*) as number
from user_submit
group by gender31.提取博客URL中的用户名

SELECT device_id,SUBSTRING_INDEX(blog_url,"/",-1) as username
FROM user_submit 32.截取出年龄

select substring_index(substring_index(profile,',',3),',',-1) as age,count(device_id) as number
from user_submit
group by age33.找出每个学校GPA最低的同学
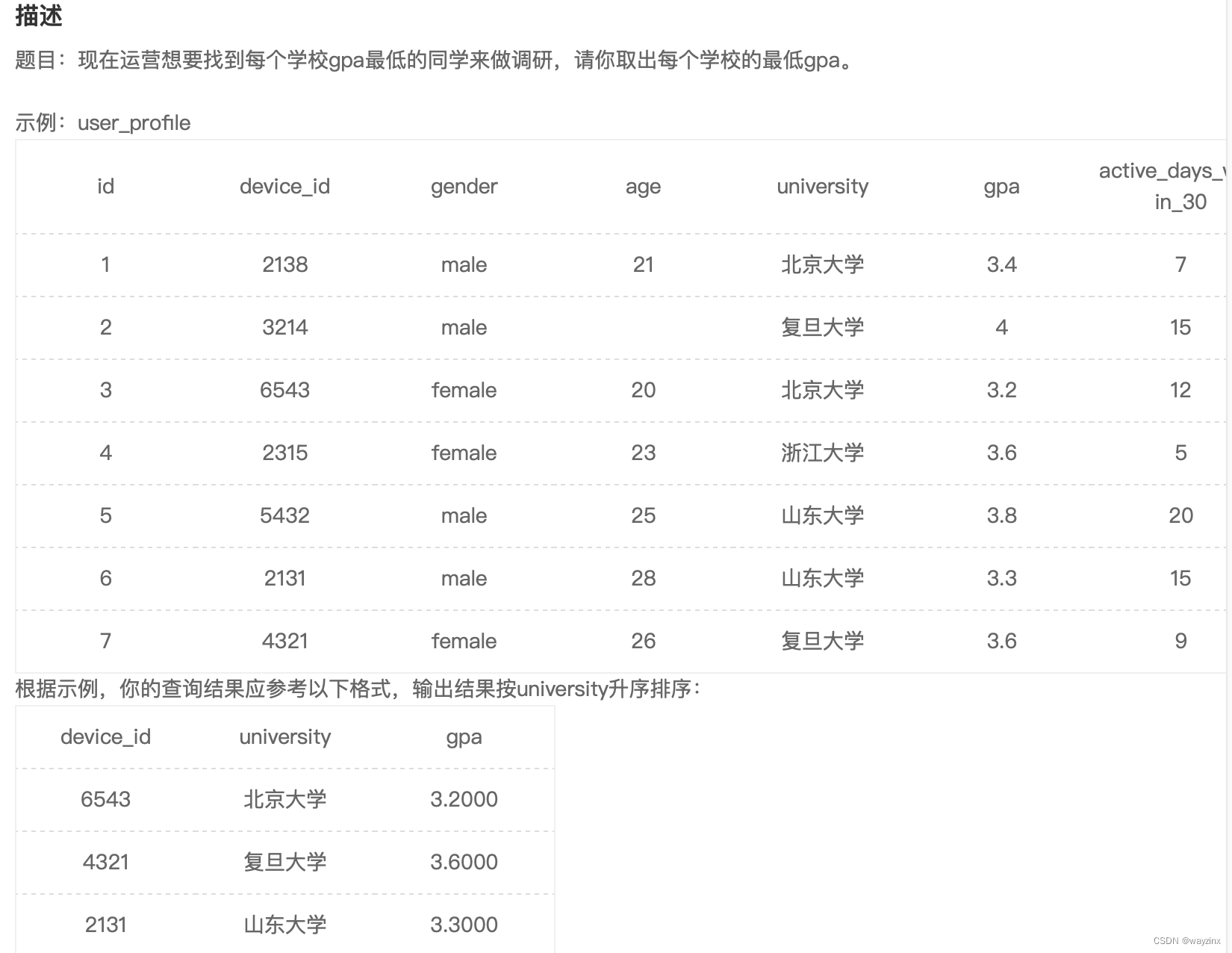
select a.device_id, a.university, a.gpa
from user_profile as a
right join (
select university , min(gpa) as gpa
from user_profile
group by university
) as b
on a.university = b.university
and b.gpa = a.gpa
order by a.university34.统计复旦用户8月练题情况
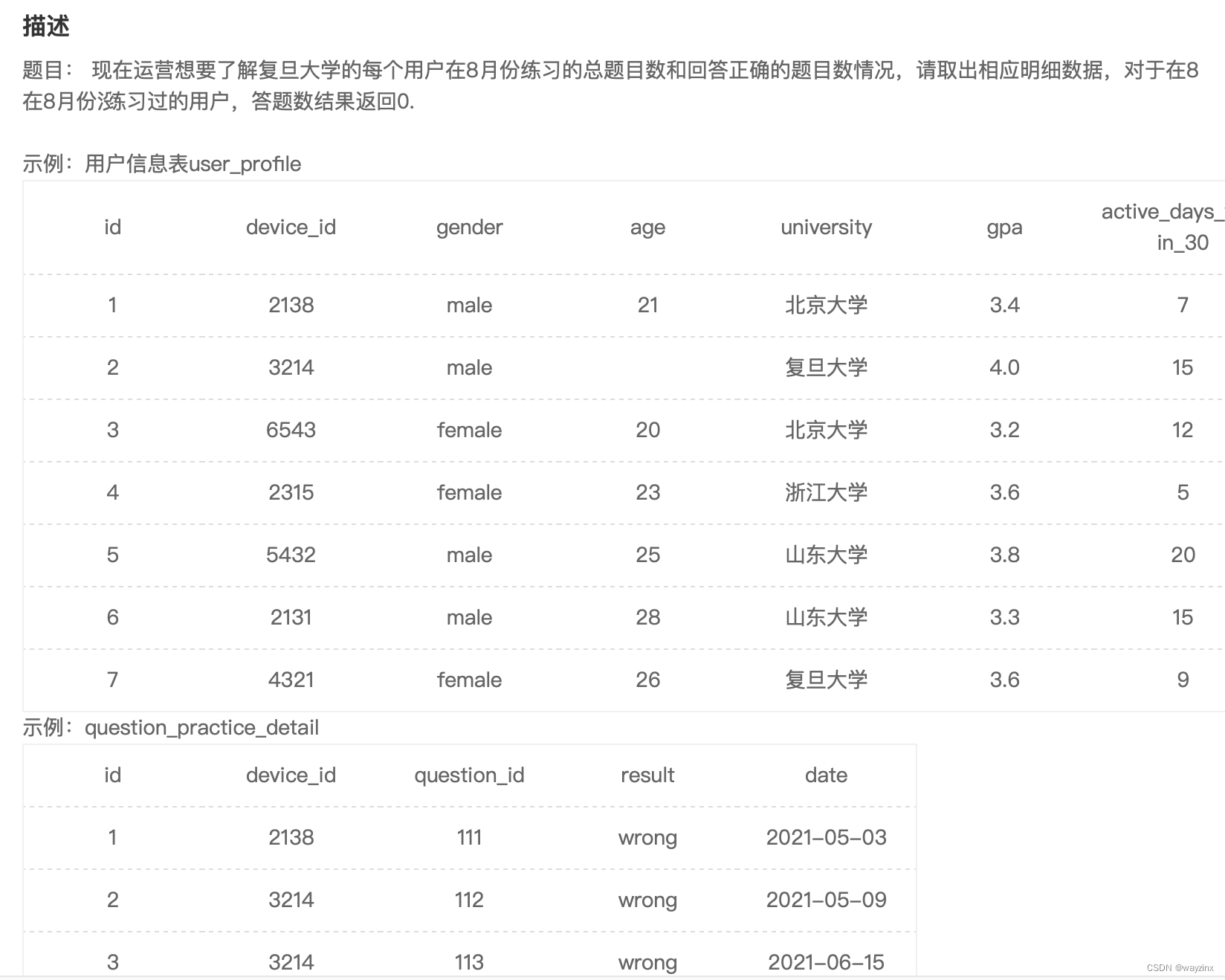
select
a.device_id,
university,
count(b.question_id) as question_cnt,
sum(if(b.result = 'right',1,0)) as right_question_cnt
from
user_profile as a
left join
question_practice_detail as b
on
a.device_id = b.device_id and month(b.date) = 8
where
university = '复旦大学'
group by
a.device_id35.浙大不同难度题目的正确率
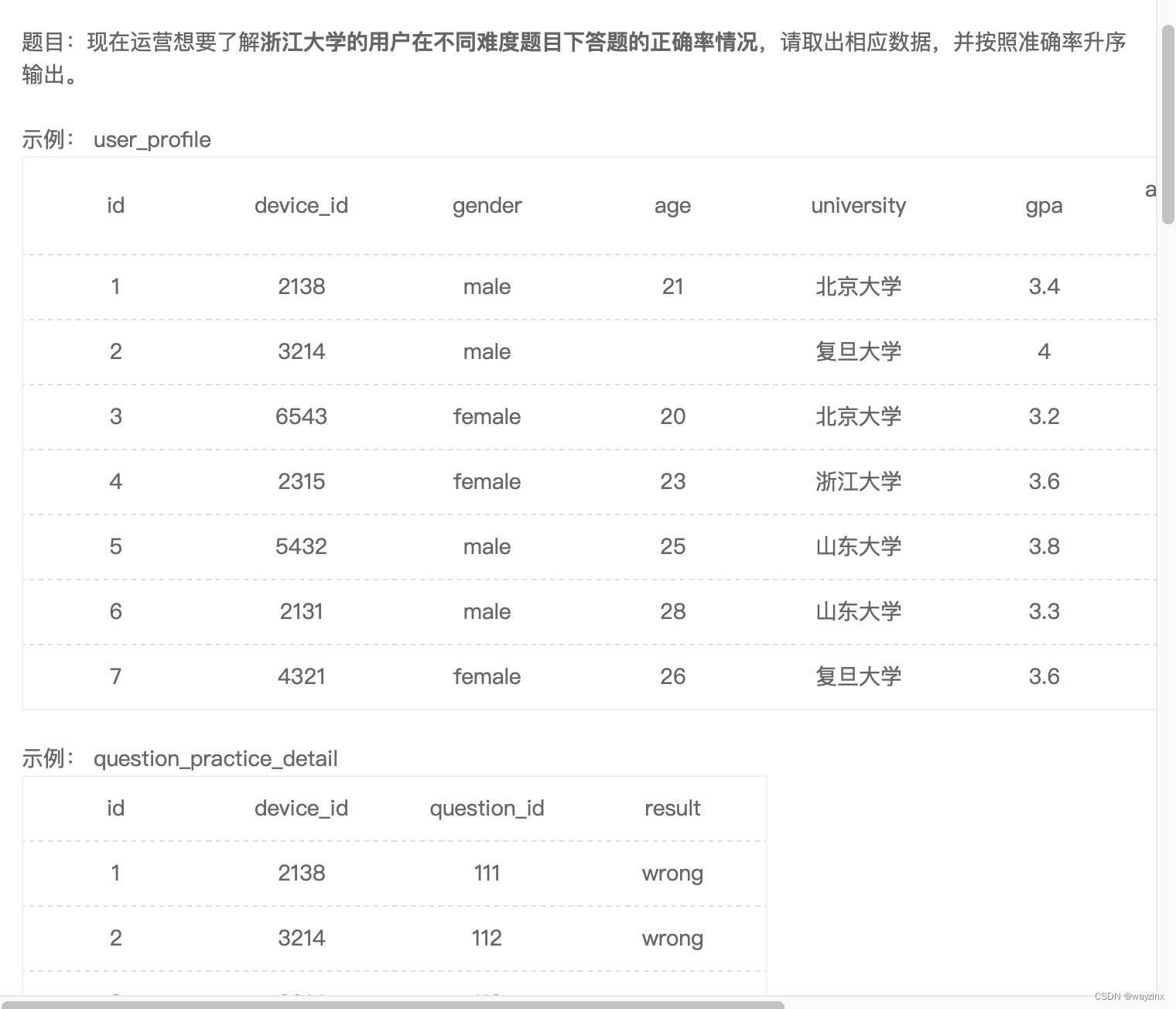
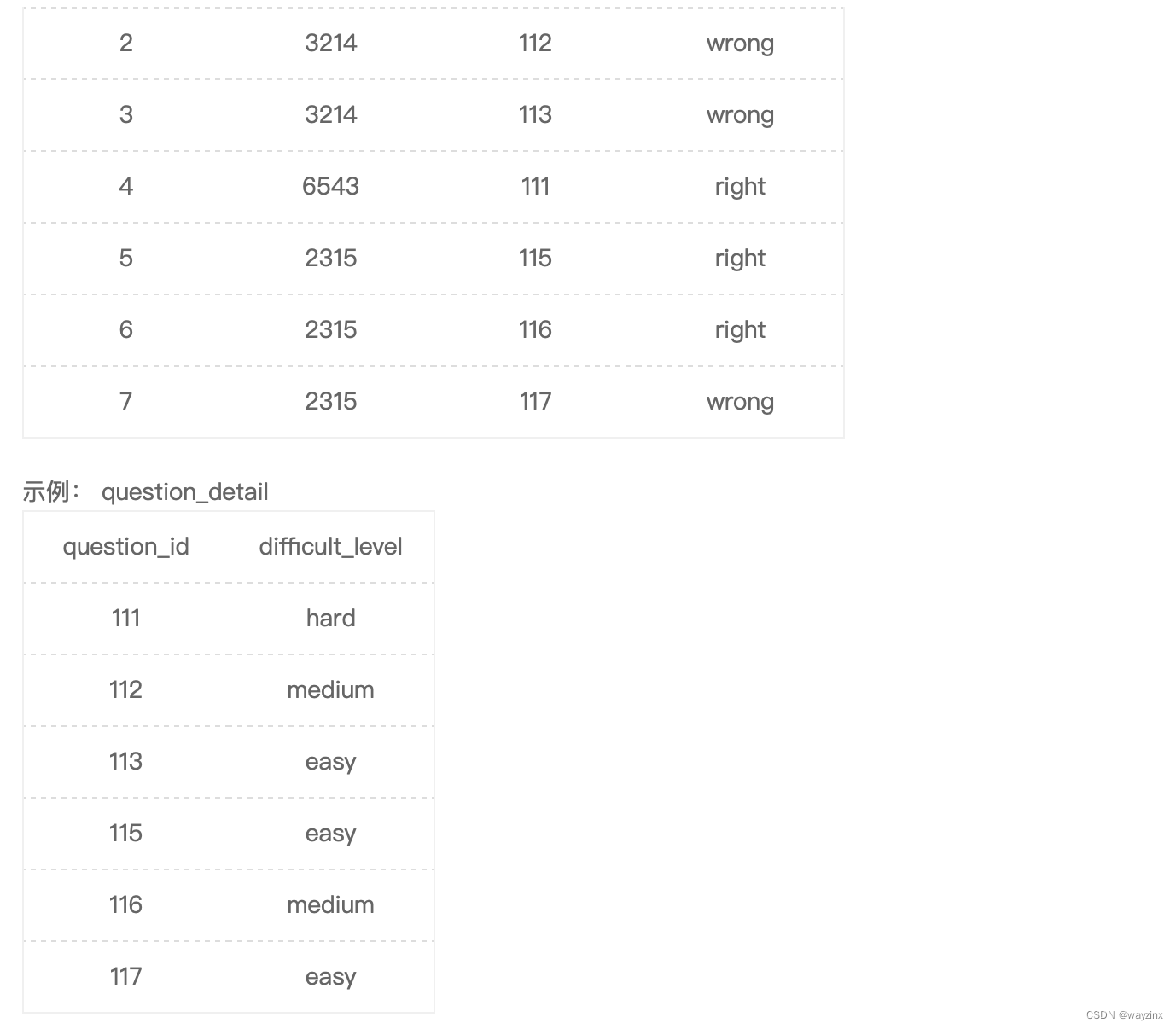
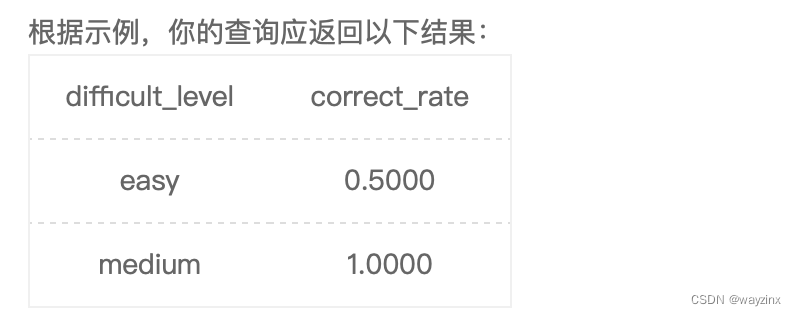
select c.difficult_level,
avg(if(b.result = 'right',1,0)) as correct_rate
from
user_profile as a
inner join
question_practice_detail as b
on
a.device_id = b.device_id
inner join
question_detail as c
on
b.question_id = c.question_id
where
university = '浙江大学'
group by
c.difficult_level
order by
correct_rate36.查找后排序
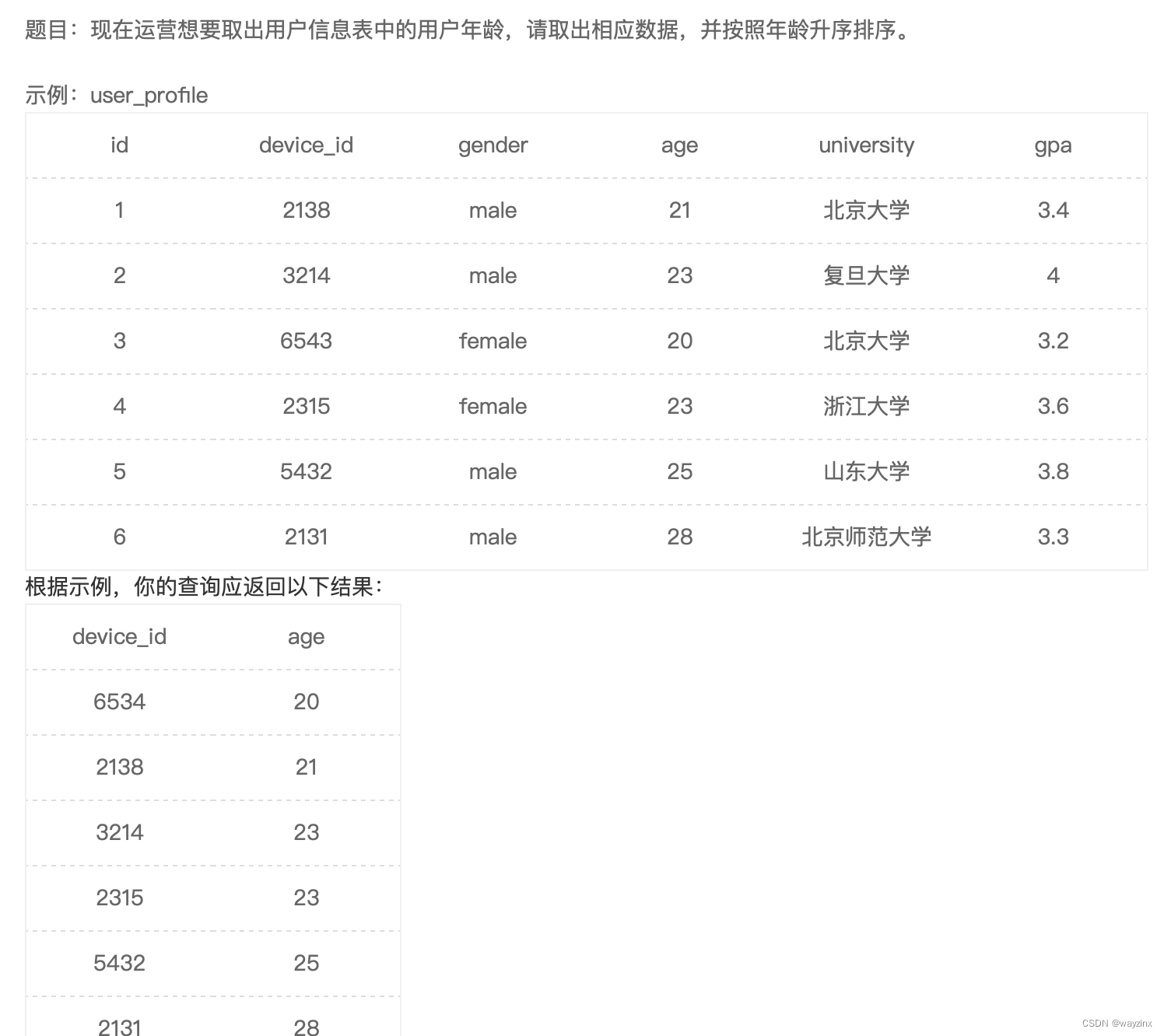
select device_id,age
from user_profile
order by age37.查找后多列排序
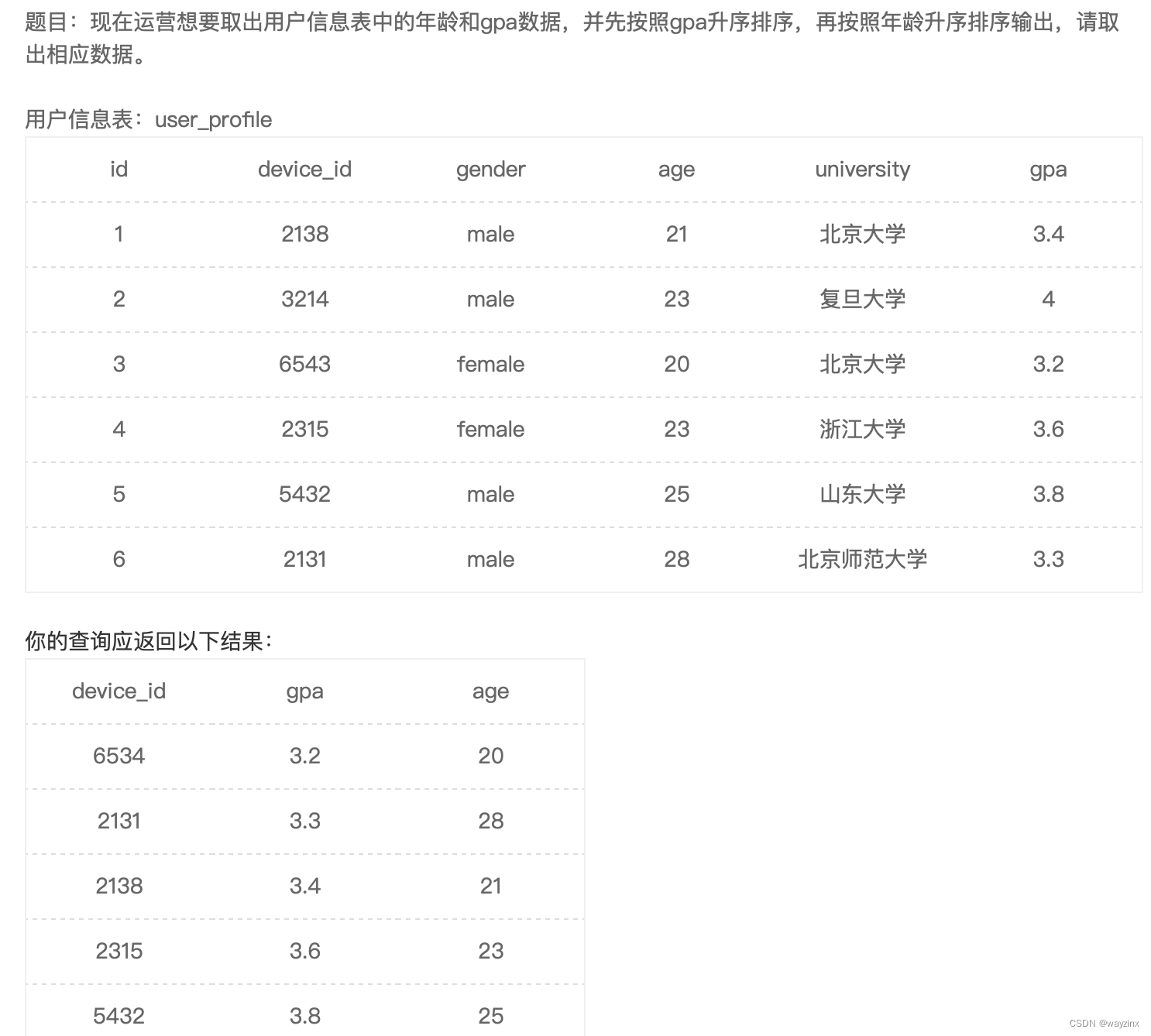
select device_id,gpa,age
from user_profile
order by gpa,age38.查找后降序排列
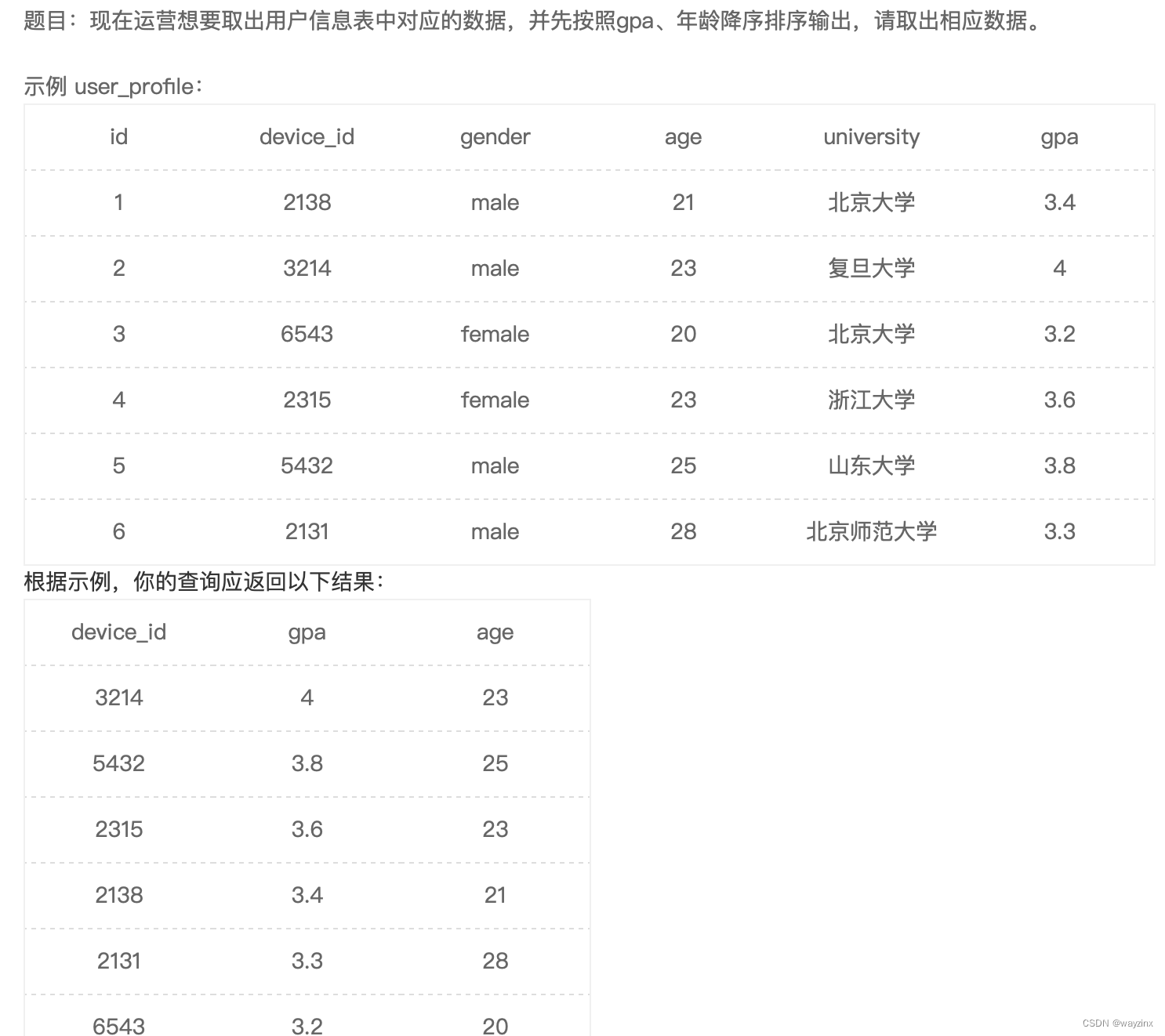
select device_id,gpa,age
from user_profile
order by gpa desc,age desc39.21年8月份练题总数
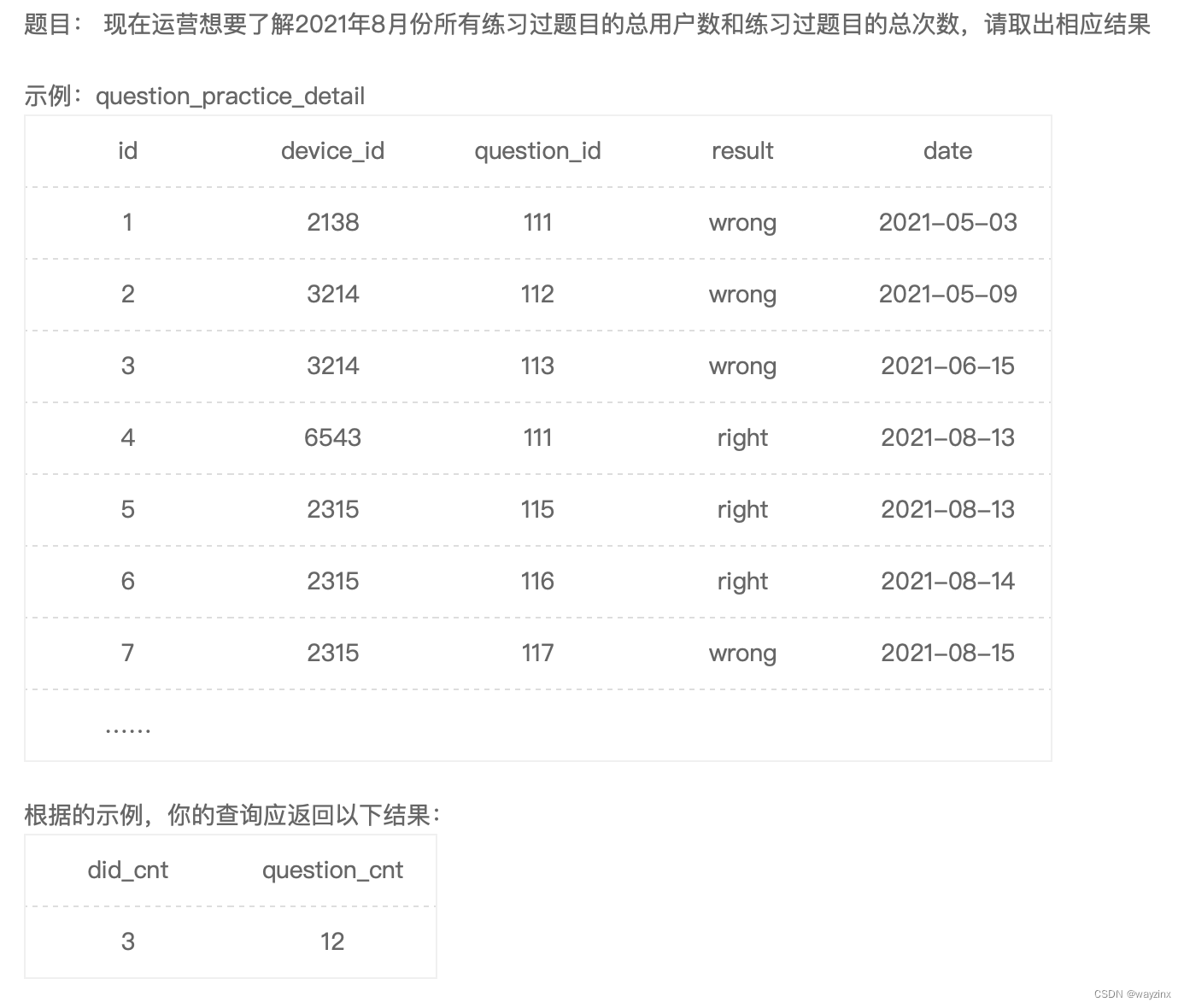
select count(distinct device_id) as did_cnt , count(question_id) as question_cnt
from question_practice_detail
where date like "2021-08%"40.
更多【jvm-SQL语句学习+牛客基础39SQL】相关视频教程:www.yxfzedu.com
相关文章推荐
- 安全-安全防御——四、防火墙理论知识 - 其他
- 网络-网络安全和隐私保护技术 - 其他
- 安全-webgoat-Security Logging Failures安全日志记录失败 - 其他
- 笔记-【动手学深度学习】课程笔记 05-07 线性代数、矩阵计算和自动求导 - 其他
- 安全-水利部加快推进小型水库除险加固,大坝安全监测是重点 - 其他
- 微服务-Java版分布式微服务云开发架构 Spring Cloud+Spring Boot+Mybatis 电子招标采购系统功能清单 - 其他
- 开发语言-怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载 - 其他
- 安全-iPortal如何灵活设置用户名及密码的安全规则 - 其他
- 集成测试-如何使用 Loadgen 来简化 HTTP API 请求的集成测试 - 其他
- yolo-基于YOLOv8与DeepSORT实现多目标跟踪——算法与源码解析 - 其他
- 编程技术-【机器学习】Kmeans聚类算法 - 其他
- 集成学习-【Python机器学习】零基础掌握RandomForestRegressor集成学习 - 其他
- java-LeetCode //C - 373. Find K Pairs with Smallest Sums - 其他
- 集成学习-【Python机器学习】零基础掌握StackingClassifier集成学习 - 其他
- 编程技术-如何提高企业竞争力?CRM管理系统告诉你 - 其他
- java-Java - Hutool 获取 HttpRequest:Header、Body、ParamMap 等利器 - 其他
- c++-C++特殊类与单例模式 - 其他
- 编辑器-vscode git提交 - 其他
- 前端-WebGL的技术难点分析 - 其他
- c++-【c++之设计模式】组合使用:抽象工厂模式与单例模式 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
