编程技术-Linux文件系统
推荐 原创引言
在此之前我们谈论重定向等问题都是指被打开的文件,现在我们来学习一下未被打开的文件,以及它们是怎么在系统中进行存储的。
未被打开的文件是存储在磁盘上的,可能现在也有一些是在固态硬盘上的(SSD),我们暂时不考虑,只谈论磁盘。
磁盘
 磁盘
磁盘
磁面:磁面上有甚多凹凸不平的点,也就是二进制序列,用来存储数据
磁头:一个磁面对应一个磁头,磁头通过光电信号来读写磁盘上的数据(二进制序列)
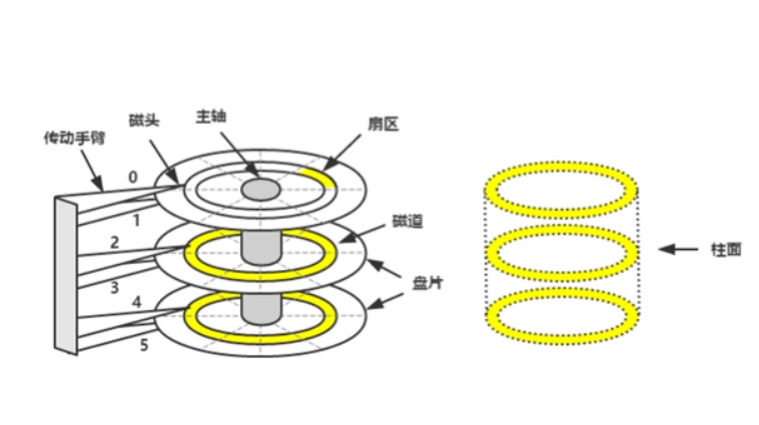
磁面是在盘片上的,一个盘片上可能两面都是磁面,都用来存储数据,也可能只有一面用来存储数据,比如我们常见的光碟,就只有一面,我们这里以一个盘面上有两个磁面来进行学习
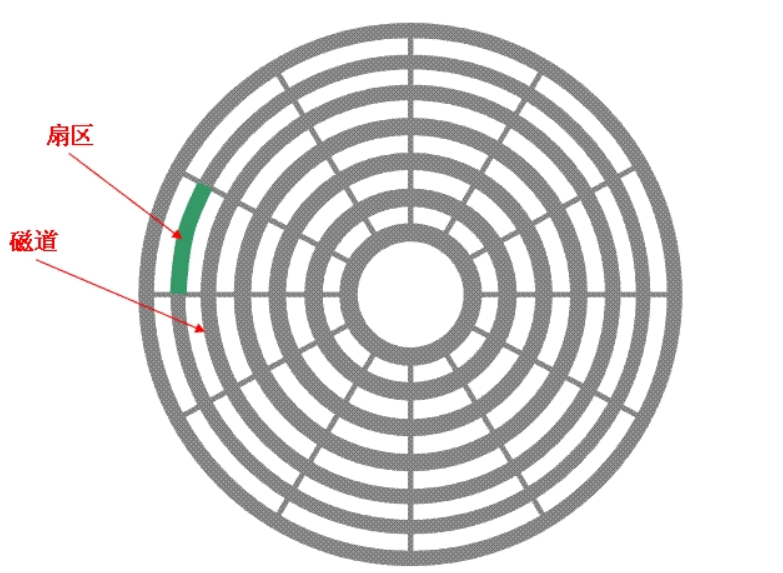
一个磁面上有很多的磁道,多个磁道之间是同心圆的关系,一个磁道又会被分为很多个扇区。
那么系统是怎么存取数据的呢?
先概括大逻辑,再详细阐述细节:
首先圆盘不停地转动,磁头也在不停地左右摆动,先确定在哪一个盘面上,也就是确定哪一个磁头(一个盘面对应一个磁头),然后再确定在哪一个磁道,最后确定在哪一个扇区。
文件系统
文件系统是怎么划分的
我们经常听说分区,那么什么是分区呢?举一个例子,我们的电脑一般被分为了C盘和D盘,其实这就是分区,分区是为了方便我们的管理。比如一个大小为500G的磁盘,如果我们直接去管理,一定是不容易的,因此系统就在理论上对把他们分成多个区域,可能大小不一,比如100G,150G,200G,50G,这样分完之后我们就容易去管理了,每个区域内的被称为文件系统,文件系统又会由多个部分组成,比如开机信息相关的Boot Block和多个
Block group(),每个Block group()组里又会被划分为多个区域。
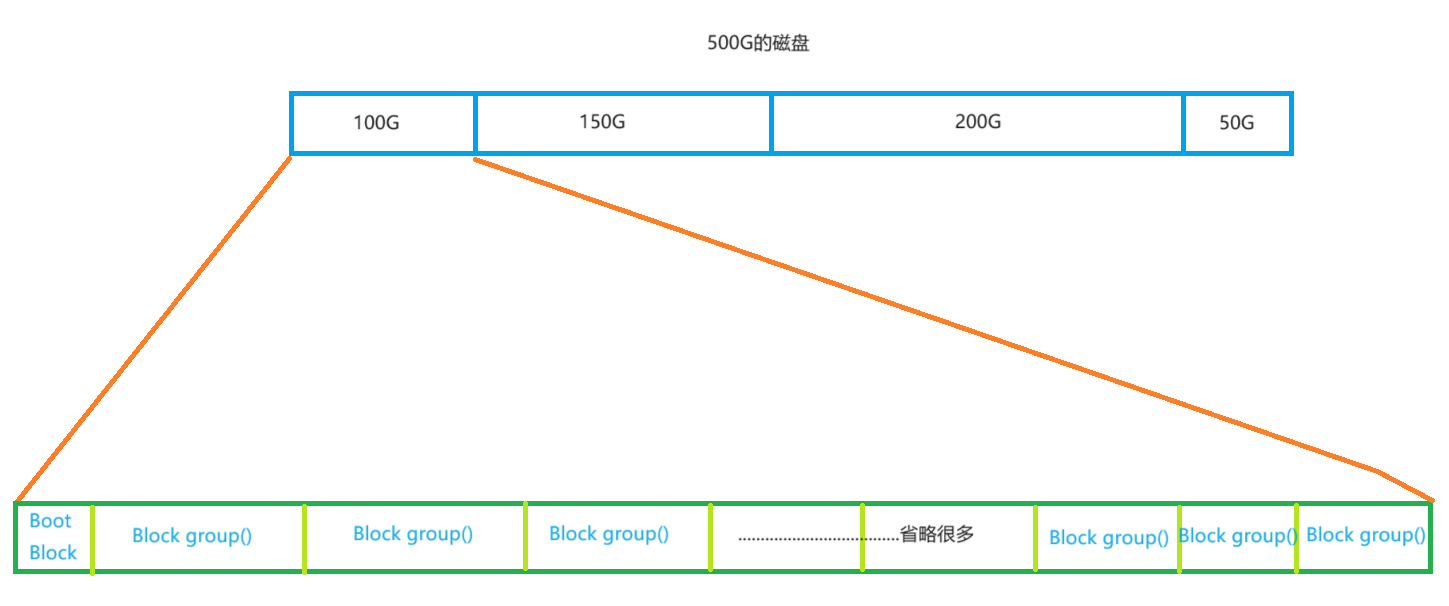
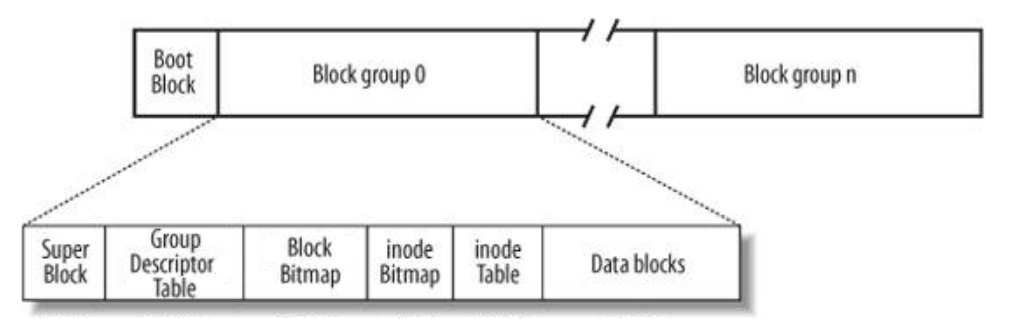
上图就是磁盘文件系统图(内核内存映像肯定会有所不同),磁盘是典型的块设备,硬盘分区被划分为一个个的block。一个block的大小是在格式化的时候确定的,并且不可以被修改。
每个分组(一个block group)中存的都是什么
我们可能听说过在磁盘上文件和属性是分开存的,那么在磁盘上是怎么分开存,又是怎么让对应属性和对应文件联系起来的呢?因此我们需要详细介绍一下磁盘文件的系统图。

Block Group()会被细分为多个块,每个块存储的内容不同。
其中最重要的就是inode,一个文件对应一个inode,inode Table表中存储的是很多个inode结构体编号 struct inode{…},结构体里面存的是inode编号对应文件的属性,比如修改时间,所属组,权限,文件类型,引用计数,
int blocks[num]等。其中block[num]数组索引是分级的,比如当num等于15的时候,前12个存放的是一级索引,也就是存的数据块的编号里面放的就是数据,后面两个是二级索引,意思就是他存的数据块编号里面存的不是数据,仍然是多个数据块编号,最后一个放三级索引,就是二级索引里面存的也是多个数据块编号而不是数据,这样做的目的就是为了能够存储更多的数据,而不被写死导致最多只能存放15个块数据
Data blocks中会被划分成很多个大小相同的数据块,用来存放文件的数据,这个数据块的大小一般是512,1024,2048KB,一个文件可能对应一个或多个数据块
一个inode结构体一般占用的空间是128KB,在inode Table表里面会有上万个inode编号,我们怎么知道这个编号里面有没有被占用,用来存放文件属性,存放的是否合法呢?因此我们这里通过inode Bitmap位图让比特位的位置和inode编号映射,去表示对应编号存放的属性是否合法的。
相应的我们怎么知道数据块中的内容是否是有效地呢?
因此我们可以通过Block Bitmap位图让比特位的位置合块号映射起来,去表示对应的数据块是否被使用。
Group Descriptor Table(GDT):块组描述符,用来记录这个分组里面被使用和未被使用的数据块个数,以及有多少个inode编号等信息。
Super Block:超级块,相对于块组描述符,它里面包含的是整个分区的基本信息,而不是某一个分组中的基本信息,其中存储的信息包括这个分区被分成了多少个组,每个组的大小,每个组inode数量,每个组里面block数量,每个组的其实inode,文件系统的类型与名称等。
目录文件
在inode里面,保存的是文件属性,但是不包括文件名,因为如果inode里面包括文件名的话,我们在查找一个文件时,是先通过文件名找到inode还是通过inode找到文件名呢?这就会导致逻辑上不符合常理,那么操作系统是怎么找到我们对应的文件的呢?文件名又是保存在哪里的呢?
我们常说Linux下一切皆文件,自然目录也是文件

我们可以看到目录文件也是有属性的,又因为文件 = 内容 + 属性,那么目录文件里面有内容吗,有的话,存的是什么?
当查找一个文件时,我们本质上是通过该文件的inode进行查找的,而不是通过文件名,文件名被保存在目录下,目录文件的数据块中保存的是文件的文件名和对应文件的inode的映射关系。
因此我们要找一个文件,只要通过目录找到目录对应数据块中,该文件名对应的inode就可以了,那么现在又有一个问题,既然目录也是文件,那么它也有自己的inode,我们又怎么找到目录对应的inode呢?
我们在使用命令时或访问文件时,其实是在当前路径下执行的,因此我们只需要根据相对路径或者绝对路径,一路向上递归,最终就会找到根目录,根目录对应的文件名就是,它对应的inode在操作系统中是已知的,因此我们再通过跟目录的inode,找到它对应的数据块,再一路向下递归,找到当前文件的文件名对应的inode就可以了。因此也可以帮我们解释为什么我们在访问任何文件时都需要带路径
上面这样做比较耗时,因此Linux下会对常用路径通过dentry缓存进行存储,方便我们在访问文件时,不用再读盘了,提高效率。
软链接:
生成软链接文件的指令:
ln -s 源文件 生成的链接文件
选项-s,是指单词soft,软的
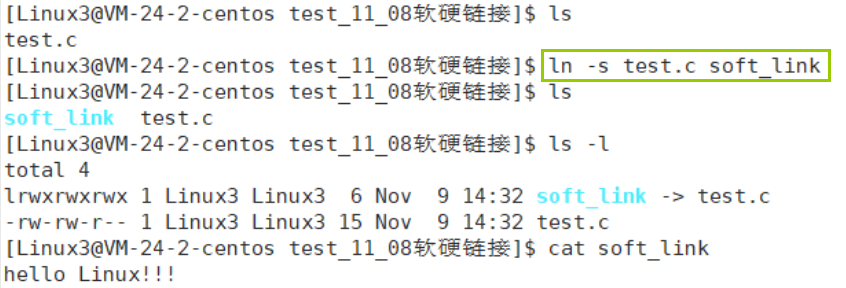
生成的软链接文件指向源文件,软链接文件保存的是源文件的路径,如果源文件被删除,那么当前链接文件就不可再被执行

软链接应用场景
软链接文件是通过inode引用,文件保存的源文件路径,来访问源文件,因此我们可以把一些不在当前路径下的文件,通过软链接来使用其它路径下的文件
硬链接
生成硬链接文件的指令:
ln 源文件 生成的硬链接文件
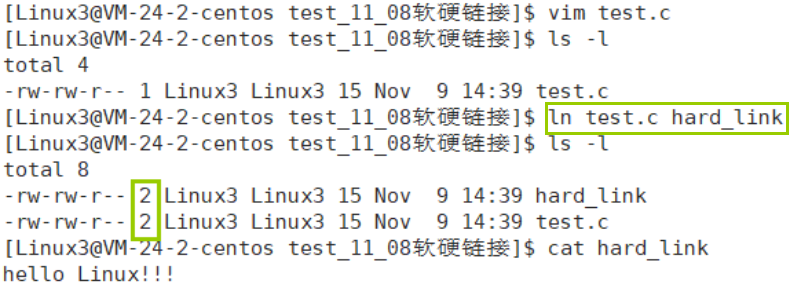
我们发现test.c文件,使用者前面的数字由1变成了2,这个数是硬链接数,通俗来讲就是现在有几个文件正在共用这个inode,当我们删除一个这个inode对应的文件,只有当硬链接数变为0时,这个文件才会被彻底删除。
硬链接应用场景
我们先来看一个现象:

这里有一个疑问,为什么我们新创建的test目录,它的硬链接数会是2?
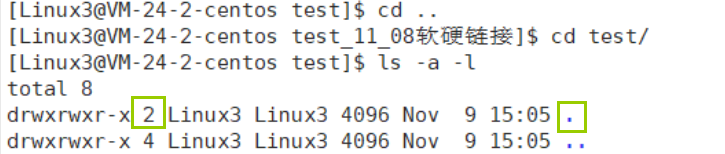
我们知道. ./是指上级目录,./是指当前目录,同时我们也可以看到.文件的硬链接数是2,其实这个.文件是当前目录的硬链接文件,而. .文件是上级目录的硬链接文件
为什么不允许对目录使用硬链接呢?
因为它是通过文件名别名引用来引用源文件的,如果可以对它做硬链接,就会导致我们在查询当前文件inode时,向上递归的过程形成死循环,那么为什么隐藏文件.也是目录的软链接就不会形成死循环呢?因为操作系统在对文件名进行扫描时,不会对隐藏文件进行扫描
硬链接和软链接的区别
硬链接文件,与源文件inode相同,源文件被删除,该链接文件仍可以被执行
软链接文件,会生成新的inode,源文件被删除,该链接文件不可再被执行
硬链接是通过inode引用,引用另一个文件,软链接是通过文件名引用去引用另一个文件

软链接是一个独立的文件,有独立的inode,也有独立的数据块,它的数据块里面存的是指向的文件的路径。
建立硬链接本质上就是在特定目录的数据块中新增文件名和指向的文件的inode编号的映射关系。硬链接不是一个独立的文件,因为他没有自己的inode。
更多【编程技术-Linux文件系统】相关视频教程:www.yxfzedu.com
相关文章推荐
- r语言-gpt支持json格式的数据返回(response_format: ‘json_object‘) - 其他
- pdf-pdf.js不分页渲染(渲染完整内容) - 其他
- 自动驾驶-自动驾驶学习笔记(八)——路线规划 - 其他
- pdf-Word转PDF简单示例,分别在windows和centos中完成转换 - 其他
- spring boot-java 企业工程管理系统软件源码+Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis - 其他
- python-利用 Google Artifact Repository 构建maven jar 存储仓库 - 其他
- python-PyCharm因安装了illuminated Cloud插件导致加载项目失败 - 其他
- list-list复制出新的list后修改元素,也更改了旧的list? - 其他
- 语言模型-论文导读 | 融合大规模语言模型与知识图谱的推理方法 - 其他
- spring-springboot引入外部jar,package打包报错找不到程序包XXX - 其他
- c++-C++之list的用法介绍 - 其他
- spring-Spring Boot(二) - 其他
- 宠物-基于STM32+微信小程序设计的智能宠物喂养系统_2023升级版 - 其他
- conda-conda添加清华镜像源 - 其他
- python-win11下安装odoo17(conda python11) - 其他
- arm开发-【OpenCV(3)】linux arm aarch 是 opencv 交叉编译与使用 - 其他
- python-linux 安装 mini conda,linux下安装 Miniconda - 其他
- 机器学习-Pytorch实战教程(一)-神经网络与模型训练 - 其他
- conda-macOS使用conda初体会 - 其他
- 编程技术-C#使用时序数据库 InfluxDB - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 软件逆向- 如何分析一个stripped ELF?这款IDA插件来帮忙
- Android安全- Android Kernel 源码环境
- CTF对抗-KCTF2022秋季赛 第二题 盗贼作乱 题解
- 软件逆向-这是一个 Frida V(伪)EH 示例(更新 x64 执行异常代码)
- Android安全- ARM64 内核 Hook 研究 (一)
- Android安全-对Inline Hook,Got Hook和SVC Hook一些检测的浅谈
- Pwn-tcache bin利用总结
- CTF对抗-2022祥云杯CTF babyparser
- Android安全-【从源码过反调试】中间篇-给安卓12内核增加个syscall
- CTF对抗- 2022 KCTF 第五题 灾荒蔓延 98k Writeup
