搜索引擎-基于向量数据库搭建自己的搜索引擎
推荐 原创前言【基于chatbot】
厌倦了商业搜索引擎搜索引擎没完没了的广告,很多时候,只是需要精准高效地检索信息,而不是和商业广告“斗智斗勇”。以前主要是借助爬虫工具,而随着技术的进步,现在有了更多更方便的解决方案,向量数据库就是其中之一【chatGPT也需要它的支撑】。
环境搭建【工作环境为windows10,数据库环境为centos7】
1. 安装python3.9【具体参考以下文章】
2. 安装git【网上教程太多了,就不写了。有需要的可以留言】
3. 安装docker和docker-compose【网上教程太多了,就不写了。有需要的可以留言】
4. 安装milvus
在centos系统中,执行以下命令
wget https://github.com/milvus-io/milvus/releases/download/v2.2.11/milvus-standalone-docker-compose.yml -O docker-compose.yml启动向量数据库
sudo docker-compose up -d 【-d是后台启动,第一次启动可以不加,有报错的话直接在命令行能看到】ip和端口号,根据自己的实际情况做调整
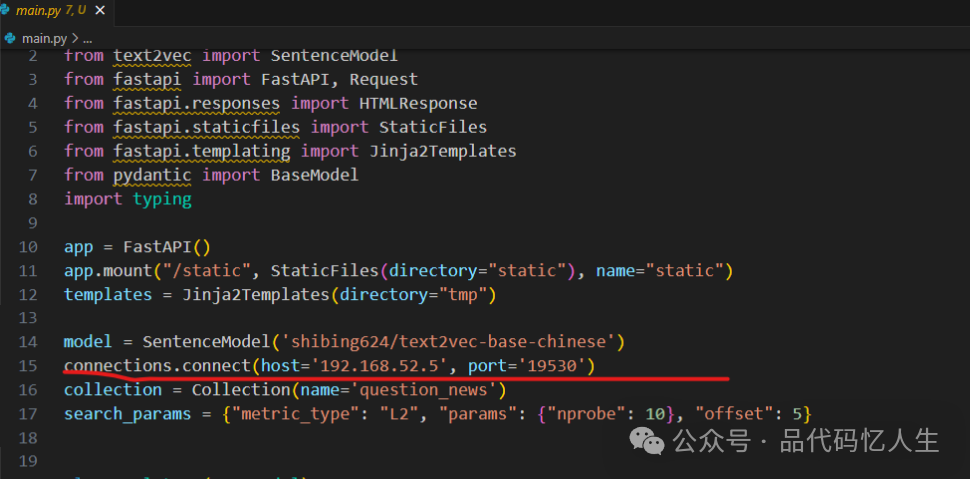
下载代码
git clone https://github.com/gitksqc/chatbot.git安装python虚拟环境
python -m venv venvtest安装模块
# 配置国内镜像pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple# 命令行进入到代码所在目录pip install -r requirements.txt
准备数据集【可以自己用爬虫做数据集】
# 我这里选的是新闻数据集做测试,可以根据自己情况选择https://www.kaggle.com/datasets/ceshine/yet-another-chinese-news-dataset
下载模型
# 需要合理的上网工具,将模型及配置文件拷贝到项目根目录下的shibing624/text2vec-base-chinese目录中https://huggingface.co/shibing624/text2vec-base-chinese
导入数据
# 将下载的新闻数据集拷贝到项目根目录下news_collection.csv# 在项目根目录下执行insert.py脚本,等待执行结束python insert.py
运行项目
# 激活虚拟环境.\venvtest\Scripts\Activate.ps1# 启动服务uvicorn main:app --reload
搜索
-
打开浏览器 访问http://127.0.0.1:8000【端口号可以自己在代码中设置】
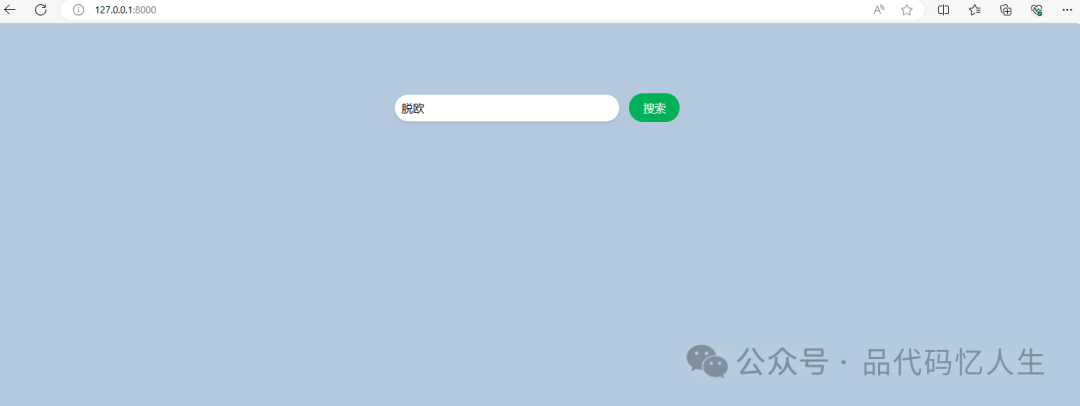
-
输入要搜索的文字,点击搜索【页面没有做排版,主要演示功能】
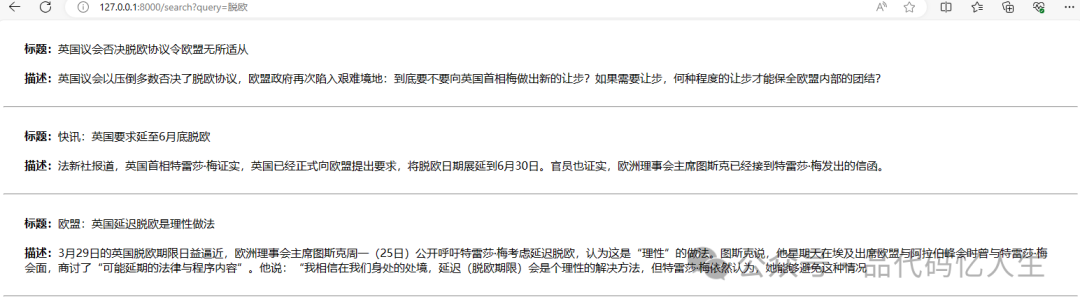
到此就结束了,有问题可以留言或私信。
更多【搜索引擎-基于向量数据库搭建自己的搜索引擎】相关视频教程:www.yxfzedu.com
相关文章推荐
- 网络-网络安全与TikTok:年轻一代的数字素养 - 其他
- 安全-安全防御——四、防火墙理论知识 - 其他
- 网络-网络安全和隐私保护技术 - 其他
- 安全-webgoat-Security Logging Failures安全日志记录失败 - 其他
- 笔记-【动手学深度学习】课程笔记 05-07 线性代数、矩阵计算和自动求导 - 其他
- 安全-水利部加快推进小型水库除险加固,大坝安全监测是重点 - 其他
- 微服务-Java版分布式微服务云开发架构 Spring Cloud+Spring Boot+Mybatis 电子招标采购系统功能清单 - 其他
- 开发语言-怎么学编程效率高,编程练习网站编程软件下载,中文编程开发语言工具下载 - 其他
- 安全-iPortal如何灵活设置用户名及密码的安全规则 - 其他
- 集成测试-如何使用 Loadgen 来简化 HTTP API 请求的集成测试 - 其他
- yolo-基于YOLOv8与DeepSORT实现多目标跟踪——算法与源码解析 - 其他
- 编程技术-【机器学习】Kmeans聚类算法 - 其他
- 集成学习-【Python机器学习】零基础掌握RandomForestRegressor集成学习 - 其他
- java-LeetCode //C - 373. Find K Pairs with Smallest Sums - 其他
- 集成学习-【Python机器学习】零基础掌握StackingClassifier集成学习 - 其他
- 编程技术-如何提高企业竞争力?CRM管理系统告诉你 - 其他
- java-Java - Hutool 获取 HttpRequest:Header、Body、ParamMap 等利器 - 其他
- c++-C++特殊类与单例模式 - 其他
- 编辑器-vscode git提交 - 其他
- 前端-WebGL的技术难点分析 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- Pwn-[writeup]CTFHUB-LargeBin Attack|House of Storm
- 软件逆向-与AI沟通学习恶意软件分析技术V1.0
- Pwn-一条新的glibc IO_FILE利用链:__printf_buffer_as_file_overflow利用分析
- 软件逆向- 调试httpd通过fork+execute调用的cgibin程序
- Pwn-[writeup]CTFHUB-UnsortedBin Attack
- Pwn-[writeup]CTFHUB-FastBin Attack
- Pwn-[writeup]CTFHUB-ret2dl_resolve
- Android安全-某设备登记APP趣味破解
- Pwn-[writeup]CTFHUB-ret2VDSO
- Android安全-某东 APP 逆向分析+ Unidbg 算法模拟
